






1.deepfuse
本工作的贡献如下:•基于CNN的无监督图像融合算法,用于融合曝光堆叠静态图像对。
•一个新的基准数据集,可用于比较各种MEF方法。
•针对各种自然图像的7种最先进算法进行了广泛的实验评估和比较研究。
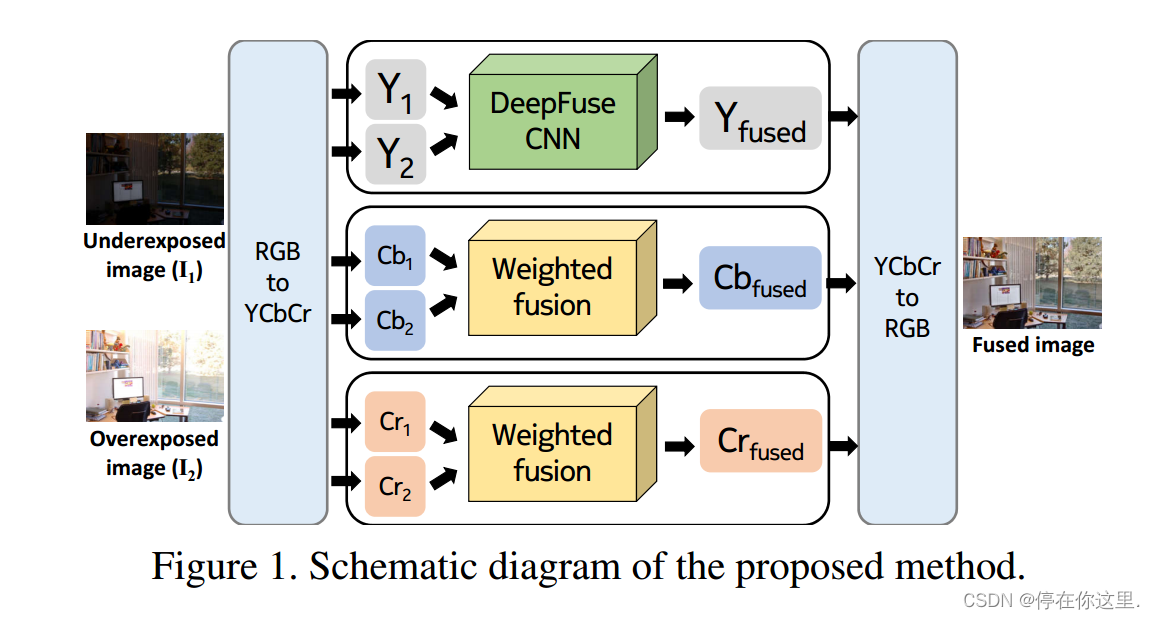
所提方法的总体方案如图所示。
将输入的曝光堆栈转换为YCbCr颜色通道数据。利用CNN对输入图像的亮度通道进行融合。这是由于图像结构细节存在于亮度通道中,亮度变化在亮度通道中比在色度通道中更突出。该网络模型在像素级做图像融合。
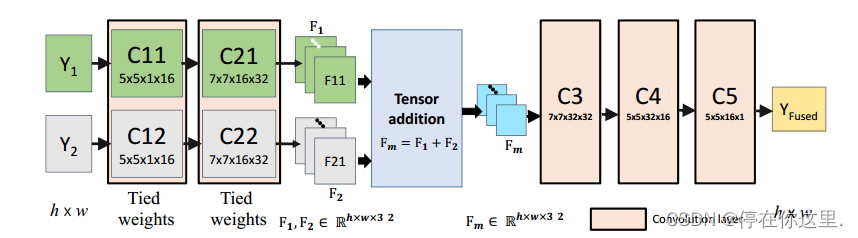 所提出的图像融合网络架构如图所示。该结构由特征提取层、融合层和重构层三部分组成。
所提出的图像融合网络架构如图所示。该结构由特征提取层、融合层和重构层三部分组成。
模型讲解:
将曝光不足和曝光过的图像(Y1和Y2)分别输入到单独的通道(通道1由C11和C21组成,通道2由C12和C22组成)。
第一层(C11和C12)包含5 × 5过滤器,用于提取边缘和角等低级特征。预融合通道权值相近,C11和C12 (C21和C22)权值相同。
这种架构的优点有三个方面:
首先,我们迫使网络学习输入对的相同特征。即F11和F21是相同的特征类型。因此,我们可以简单地通过融合层将各自的特征映射组合起来。也就是说,将图像1的第一个特征图(F11)和图像2的第一个特征图(F21)相加,并将此过程应用于剩余的特征图。此外,添加特征比其他组合特征的选择产生更好的性能(见表1)。

在特征添加中,来自两张图像的相似特征类型被融合在一起。可以选择连接特征,通过这样做,网络必须计算出合并它们的权重。在我们的实验中,我们观察到,通过增加训练迭代次数,增加C3后的过滤器和层数,特征拼接也可以达到类似的结果。这是可以理解的,因为网络需要更多的迭代来计算合适的融合权重。在这种绑定权重设置中,我们强制网络学习对亮度变化不改变的过滤器。这是通过可视化学习过滤器观察到的(见图8)。在捆绑权重的情况下,很少有高激活过滤器具有中心环绕接受野(通常在视网膜中观察到)。这些滤波器已经学会了从邻域中去除均值,从而有效地使特征亮度不变。其次,可学习滤波器的数量减少了一半。
第三,由于网络参数数量少,收敛速度快。通过合并层对C21和C22得到的特征进行融合。熔合层的结果再通过C3、C4和C5卷积恢复为Yfused
损失函数:
表示从输入图像对中在像素位置p处提取的图像patch,
为同一位置p的CNN输出融合图像提取的patch。
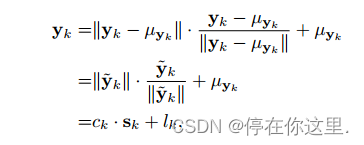
其中为
的平均值,
为2范数。
期望的对比值为:
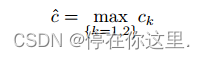
期望的结果的结构:
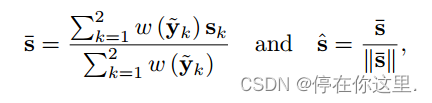
将上述两式结合产生期望结果批次:

使用SSIM框架计算像素p的最终图像质量分数
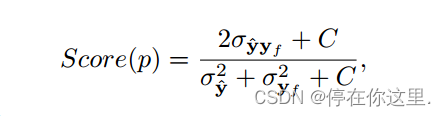
其中为
的协方差,
是
的协方差。
损失函数为
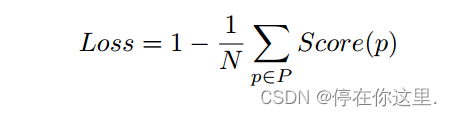
文中遵循Prabhakar等人[18]用于色度通道融合的程序。若x1和x2表示图像对任意像素位置的Cb(或Cr)通道值,则得到融合色度值
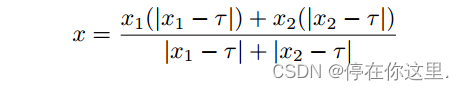
融合色度值是通过对两个色度值进行加权,再减去其本身的值得到的。选择
的值为128。这种方法背后的直觉是给好的颜色分量更多的权重,而给饱和的颜色值更少的权重。将
通道转换为RGB图像,得到最终结果。
阅读感悟:
1.利用相同的权重值的网络模型(C11,C12)(C21,C22)
2.添加特征比其他组合特征的选择产生更好的性能
3.融合方法,是将图像转换为YCbCr格式,然后在Y通道上做融合工作,融合成功后再转换为RGB格式,可能产生不存在的像素值(不好的地方)。
原文地址:DenseFuse: A Fusion Approach to Infrared and Visible Images | IEEE Journals & Magazine | IEEE Xplore


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









