




数字人技术简介
数字人技术在影视剧与动画制作、数字娱乐、元宇宙、电子商务等众多领域得以广泛应用,其可以通过虚拟角色的形象和动作展现特定的角色属性,从而丰富内容情节、满足场景需求等等。
数字人技术传统上包括了虚拟角色脸部肖像的编辑和生成,以及虚拟人体的动画制作。随着生成式人工智能崛起,利用文本提示输入大模型生成三维数字人的方法也开始流行。在生成式人工智能帮助下,数字人的制作和应用门槛显著下降,应用前景更加广阔。但利用 AI 赋能数字人建模和动画也有很多技术问题需要处理,同时需要克服很多挑战。本次分享将从数字人脸肖像编辑和生成、文生三维肖像与数字人体动画三个维度展开。

人脸肖像编辑和生成
视频直播等服务流行后,用户对头像美颜的需求大增,相关研究也随之兴起。对此,团队在 2021 年的一项工作提出了对视频中人脸肖像的胖瘦调整方法。
论文:Parametric Reshaping of Portraits in Videos,ACM Multimedia 2021
该方法分为人脸模型鲁棒重建和结果重塑两个部分。第一部分估计人脸多帧之间的变化,并联合多帧重建精确人脸几何模型。之后对 3D 模型进行准确调整,确保帧间一致性,最后通过内容感知网格变形生成结果,同时尽量减少背景失真。该方法可以对原始视频中肖像胖瘦做宽区间、较为自然地调整。对于头发遮挡、手部遮挡等情况,该方法也有较好的适应性,但存在麦克风遮挡人脸时会出现麦克风变形的局限。
另一项与视频美颜相关的工作是双下巴去除。
论文:Coarse-to-Fine: Facial Structure Editing of Portrait Images via Latent Space Claasifications,SIGGRAPH 2021
该方法可以自动、自然地去除视频中人脸的双下巴。该方法的核心是在 stylegan 的隐空间中寻找一个“理想”的分离边界,可以在保留人脸特征不变的同时去除双下巴。
下一项工作是视频肖像去头发,从而实现发型更换,或者为三维重建提供无头发遮挡的头部模型。
论文:HairMapper: Removing Hair from Portraits Using GANs,CVPR 2022
该工作的挑战性在于缺乏真实人类头部图像有/无头发的配对数据。对此,团队开发了一种新的分离图像中头发边界的方法,以及男性秃头图像的构建方法,用来生成有发和秃头的训练配对数据。由于女性秃顶情况极少,因此处理女性图像时,会将女性肖像转化为男性,再生成对应的秃头图像后变回女性。
有了成对数据后,就可以训练出能够生成自然秃顶图像的模型,生成效果比同类方法更加稳定。
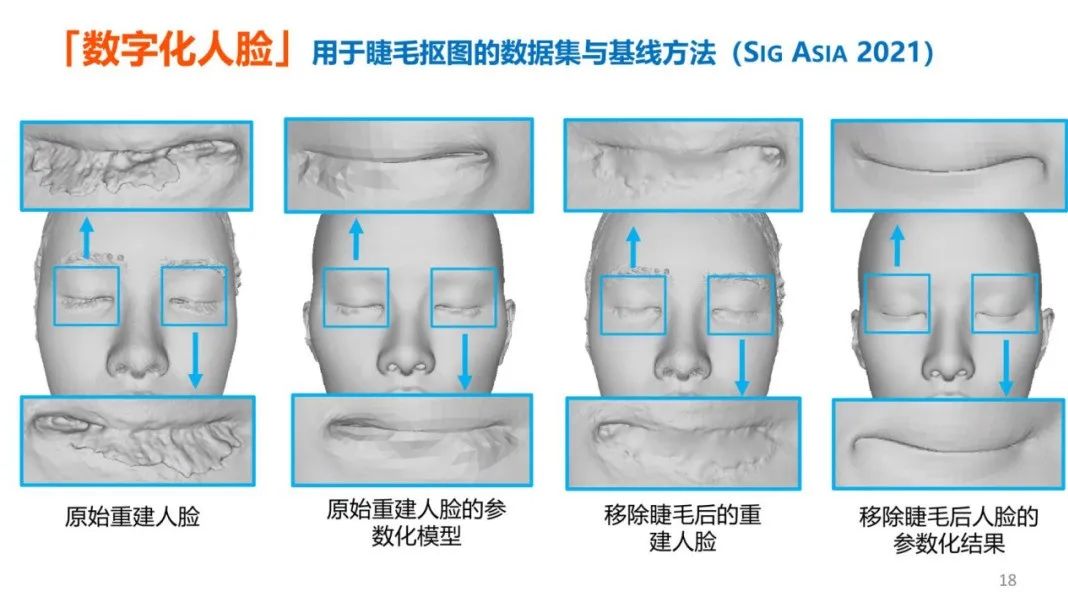
下一项工作与睫毛抠图相关。在人脸高清重建过程中,脸部毛发会对重建引入不可忽视的噪声干扰,需要有方法将睫毛从原始图像中抠出。对此,团队创建了世界上第一个睫毛抠图数据集 EyelashNet。基于这个数据集训练了一个睫毛抠图网络,该网络可以从单张图像中估算出高质量的睫毛蒙版。
论文:EyelashNet: A Dataset and A Baseline Method of Eyelash Matting,SIG ASIA 2021
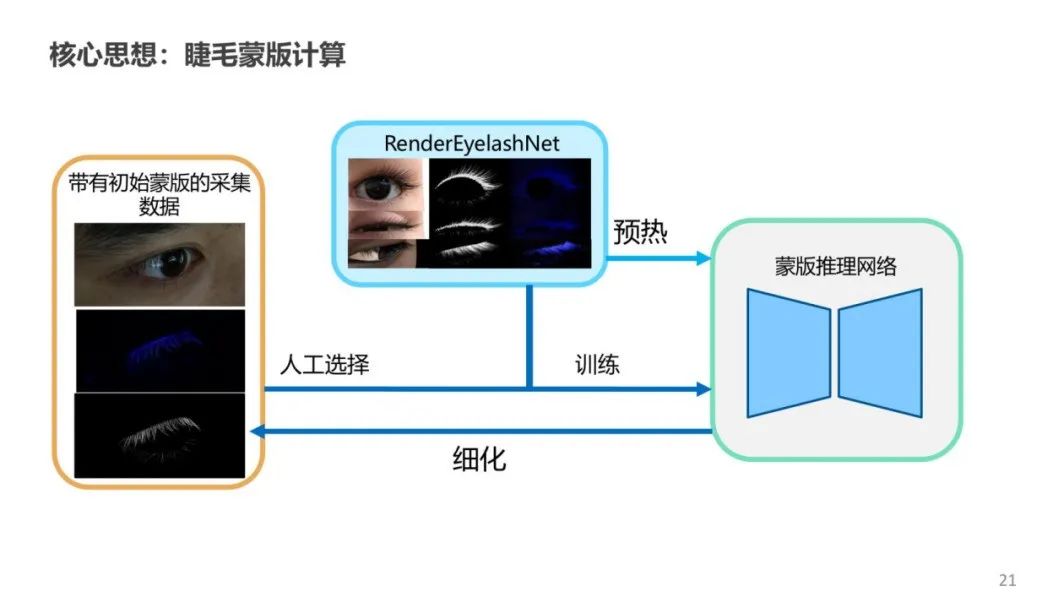
该方法的难点在于,睫毛图像的背景如眼睑、眼皮等无法被分离或替换,且睫毛一直在运动难以静止,导致很难采集多个严格对齐且颜色不同的睫毛图像来估计蒙版。于是,团队引入了合成数据来构建数据集,并用合成数据来预热睫毛抠图网络,之后再用少量真实数据来迭代优化,使推断网络适应真实的睫毛数据。训练后的网络就可以得到高质量的睫毛 Alpha 通道。
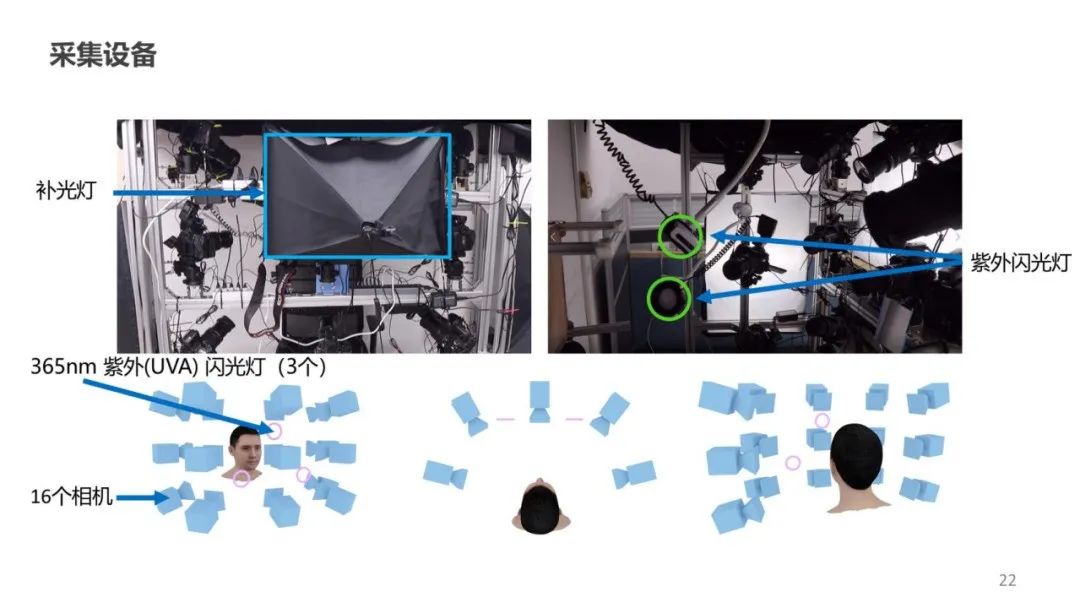
采集真实的睫毛数据时,需要使用一套多视角的捕捉系统。该系统有多个同步环绕相机和一组紫外闪光灯,闪光灯开启时可以照出睫毛轮廓,关闭时获得对照图像。
经过对比发现,该方法生成的睫毛蒙版是业内最接近真值的,优于RenderEyelashNet的结果(这说明合成睫毛数据和渐进式训练策略的重要性),并且比 SOTA 的方法有显著改善。
该方法还可以处理不同的光照、肤色、脸型等,即使对较为模糊的图像区域也有精确的结果。通过该方法可以重建出更加精确的脸部模型,使数字人的眼部特征更接近真实。它也可以应用在视频美颜中的睫毛美化(换色、加长)需求上。

文生三维肖像
通过文本生成逼真的三维肖像是生成式人工智能的一个重要的应用领域。金小刚团队在 2024 年提出了一项工作,使用金字塔结构的三维表示和 GAN 先验生成文本引导的高质量三维肖像。
论文:Portrait3D: Text-Guided High-Quality 3D Portrait Generation Using Pyramid Representation and GANs Prior,SIGGRAPH 2024
原有的生成方法是通过文本生成的几何模型提供生成的起点,再通过扩散模型提供外观信息。但这种方法会导致生成的纹理不一致或不真实,并且会让生成的图像过度饱和与平滑。
该方法则是基于一个名为 3DPortraitGAN 的生成器,它可以学习肖像的几何与纹理分布,生成一个初始的三维肖像结果,并将这个结果作为三维肖像生成的先验起点。
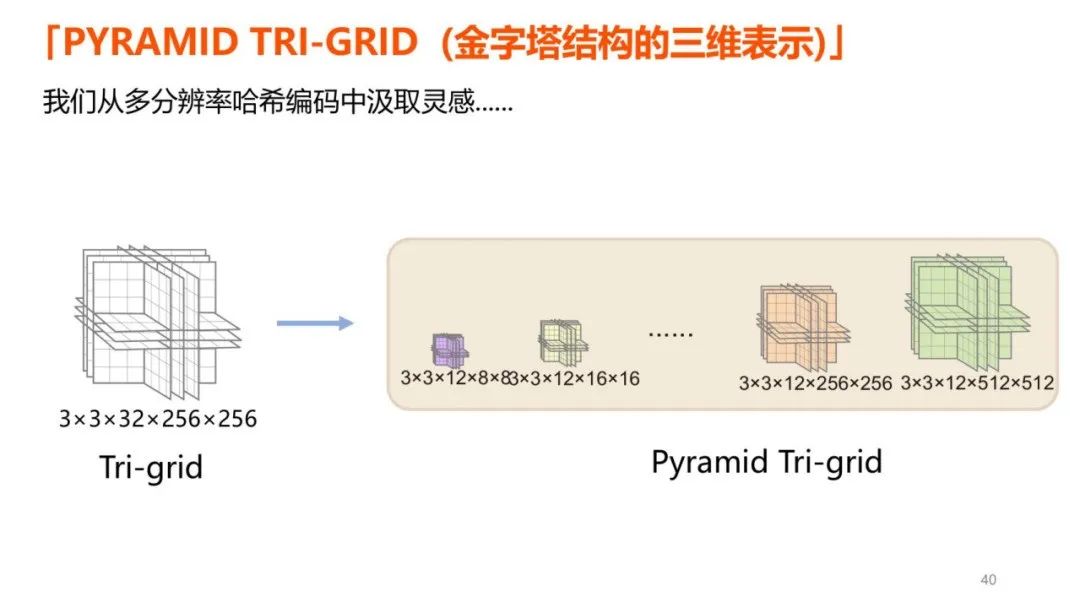
3DPortraitGAN 一开始使用了名为 Tri-grid 的三维表示,它可以存储肖像的颜色与外形特征。但直接使用这种表示会导致生成的结果有网格状伪影,这是由编码的高频信息引起的。实验发现,将编码数值调低,或采用多分辨率哈希编码都可以有效减少伪影,后者则可以在分辨率与噪声之间达到更好的平衡。
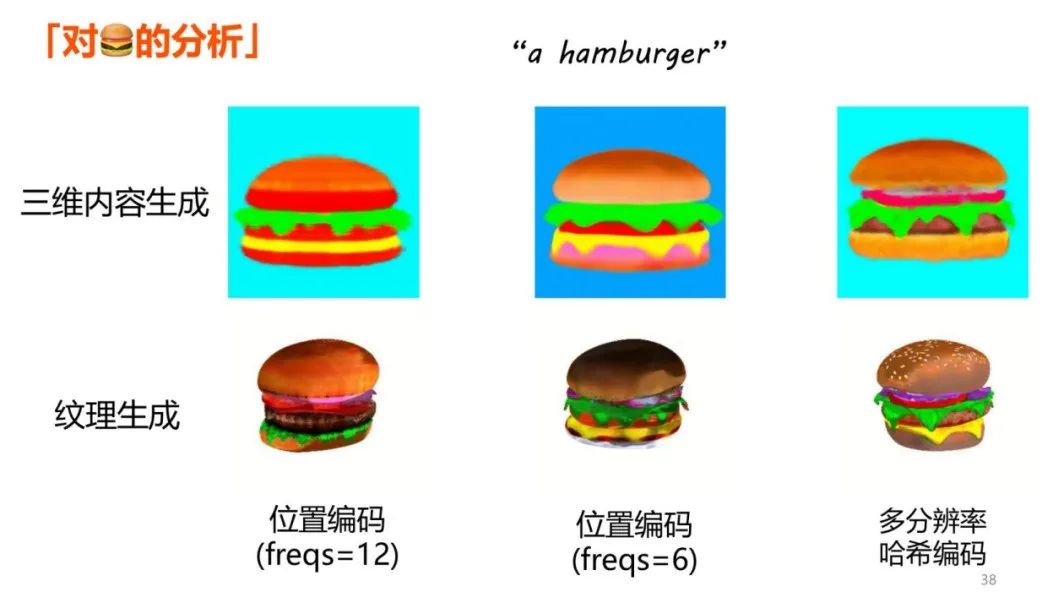
从多分辨率哈希编码中汲取灵感,就有了金字塔结构的三维表示。它由多个不同分辨率的 Tri--grid 组成。将它作为 3DPortraitGAN 的基础三维表示,就可以提供更平滑逼真的结果,同时显著减少噪声。
为了进一步改善结果,下图为肖像生成的流程:
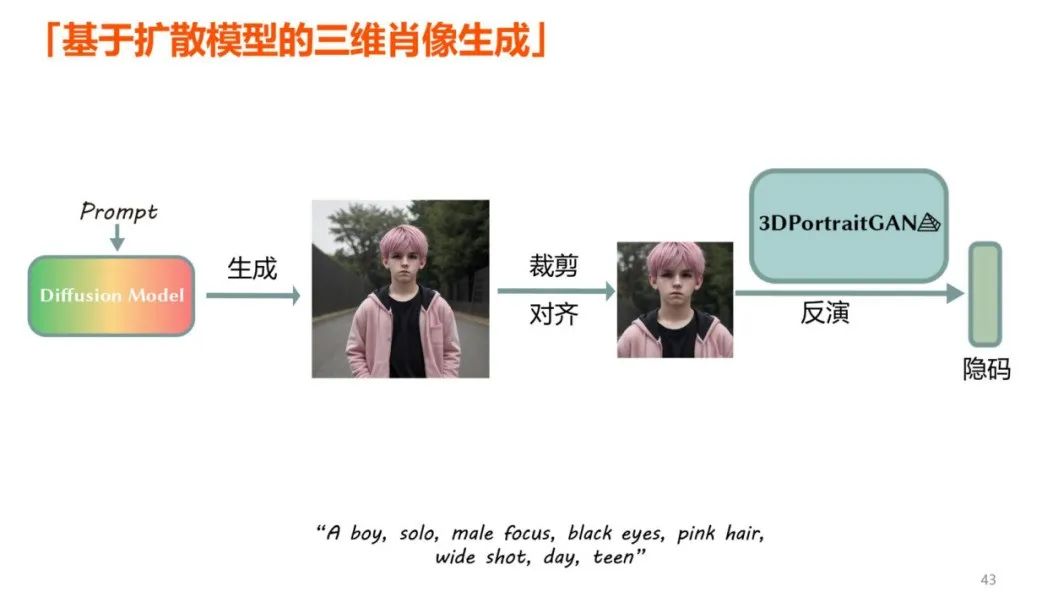
图中人像为 AI 生成
首先生成裁剪对齐后的图像隐码,然后输入 3DPortraitGAN 生成金字塔三维表示作为后续的起点。之后再使用分数蒸馏采样,将生成结果提炼到金字塔三维结构中。
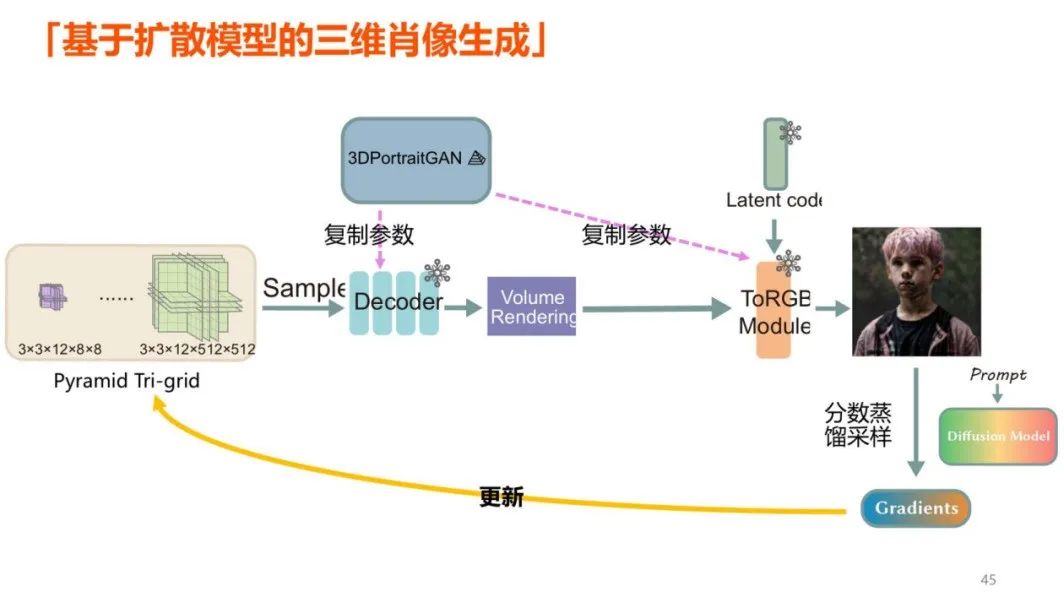
这样的流程可以生成几何和纹理信息较为准确的三维肖像,但结果仍会存在伪影等不足。要改进结果,需要用金字塔三维表示生成 21 张渲染视图,然后通过扩散模型细化图像,消除伪影,再用细化后的图像来优化金字塔三维表示,从而生成较好的结果。
最终,该方法可以对各种提示词生成较为真实,符合提示词描述的三维肖像结果,涵盖不同的性别、年龄、种族、肤色、化妆、服饰等类型。

图中人像为 AI 生成
与其他流行方法对比,该方法表现出了更好的性能,生成的三维肖像更加逼真,没有多面歧义,几何形状更接近真实人脸。

人体动画
要生成虚拟人的身体动画,常用的方法是通过动作捕捉技术。而团队提出了一种方法,即利用人体骨骼关节运动的特征研发了一个高精度的人体运动神经求解器。
论文:A Locality-Based Neural Solver for Optical Motion Capture,SIGGRAPH ASIA 2023
该求解器设计了一个图神经网络,将动作捕捉标记点与人体关节视为不同类型的节点,用图卷积提取标记点与关节的局部特征。在处理标记点录制被遮挡,或动作较大的情况下,相邻的标记点之间有强关联性,较远的标记点关系较弱。利用这一特征,就可以较为准确地估算标记点位。
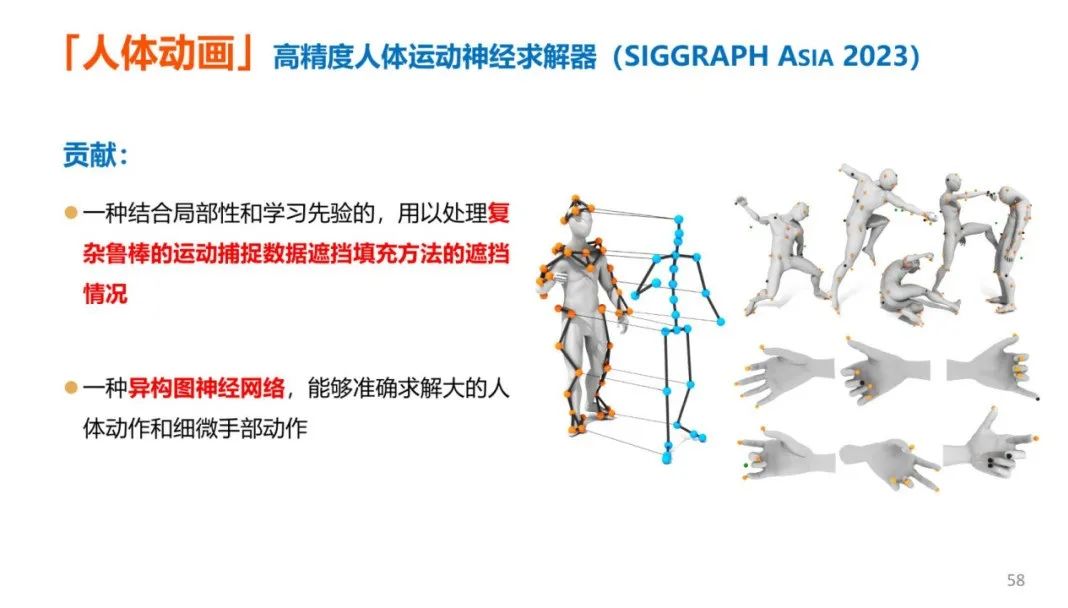
该方法不仅能够较好地处理遮挡情况,还能准确求解大跨度人体动作和细微手部动作。与其它流行方法相比,该方法处理遮挡情况时的精度提升了20%左右,重建误差缩减了30%。
生成人体动画时,运动补间是一个很重要的步骤。下一项工作就涉及实时可控的运动间补。该问题的定义是输入稀疏的关键帧和间隔时间,由计算机实时生成中间动画。传统的间补方法包括运动规划问题求解、数据驱动方法和基于神经网络的方法,但它们各有自己的缺陷。

团队提出的方法则在运动控制、质量和实时性方面达到了较好的平衡。
论文:Real-time Controllable Motion Transition for Characters,SIGGRAPH 2022
该方法提出了一种高性能的补间框架,不需要后处理。同时提出了一种自然运动的流形模型,可以基于给定的条件减少姿态变换的歧义,保证运动质量。
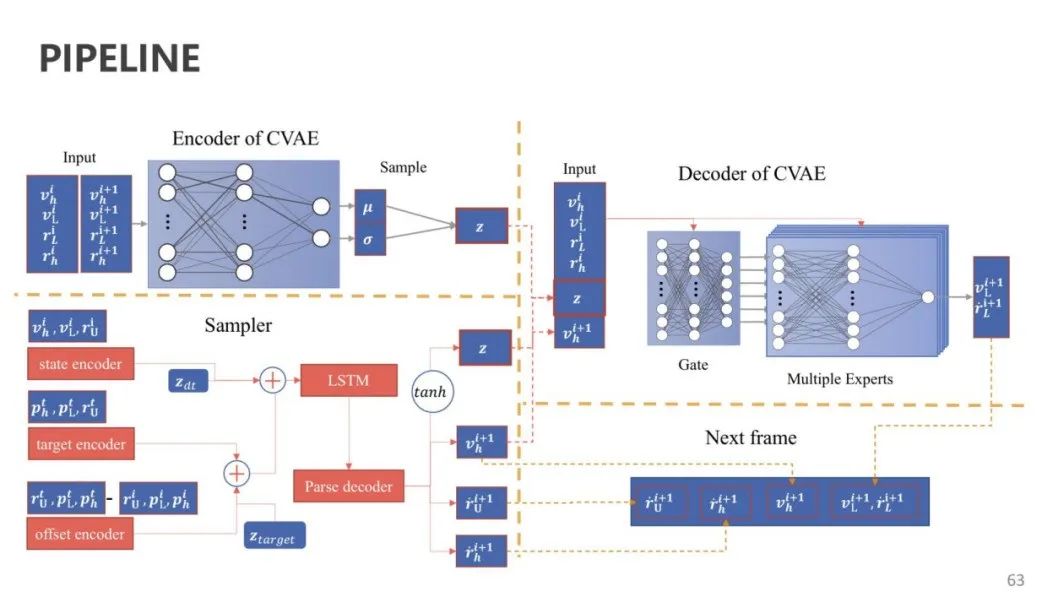
经过测试发现,该方法可以在一个连续动作去掉中间数十帧信息后,利用少量起始和目标信息重建丢失的信息。它可以自动选择合适的人体动作进行补间,且对动作大幅减速后也能很好地重建。
如果改变目标帧中人体的原始位置,将它移动到更远,该方法也可以用不同的方式补足中间帧。例如,自动选择让人体大步或小步移动到目标位置,且移动动作和原始动作保持相同的步调。当目标位置调整为与原始位置相反的方向,该方法也能生成自然的补间,不会像传统方法一样出现人体滑步这样的虚假动作。
上述工作的进一步拓展是实时风格化的运动补间。
论文:RSMT: Real-time Stylized Motion Transition for CHaracters,SIGGRAPH 2023
前述方法无法模拟不同人类个体风格化的行走效果,新方法弥补了这一缺陷,且已开源。

这一工作的难点在于生成方法需要同时满足生成速度(实时性)、动作质量、风格多样性与控制约束等多方面的条件。此前的工作通常只能满足其中一两个条件,或者依赖后处理,或只能处理特定数据。
对于上述难点,团队的解决方法是将问题分成两个部分:一个能够生成高质量多样性动作的流形空间,和一个能够满足时间、空间、风格约束的采样器。并提出了一个全新的在线实时生成风格动画间补的方案。在动作生成领域中,该方法能够结合风格和可控性。同时,还提出了一个在动作控制能力和风格化能力上具有强大泛化能力的模型。新方法可以很好地兼顾上述多个方面的要求。
与风格化动作相关的另一项工作是风格迁移动画。人体动画风格迁移在计算机图形和动画领域应用广泛,这里的风格迁移包括了两个步骤,第一步是从内容中分离动画角色的动作风格,第二步是将这种风格迁移到另一个动作上,从而创造出高质量、指定风格的动画内容。风格迁移方法可以降低动作捕捉与后处理成本。
常见的风格迁移方法将运动解耦成风格和内容来实现风格控制,但容易在解耦过程中出现歧义。为此,团队提出了一种通过控制 contact 减少歧义的方法。
论文:Decoupling Contact for Fine-Grained Motion Style Transfer,SIGGRAPH ASIA 2024
这里的 contact 是指动画角色的脚部与地面接触的信息,包括接触时长、接触位置、运动频率等。经过实验发现,接触信息与运动风格和内容都紧密相关,对运动质量、风格迁移都很重要。
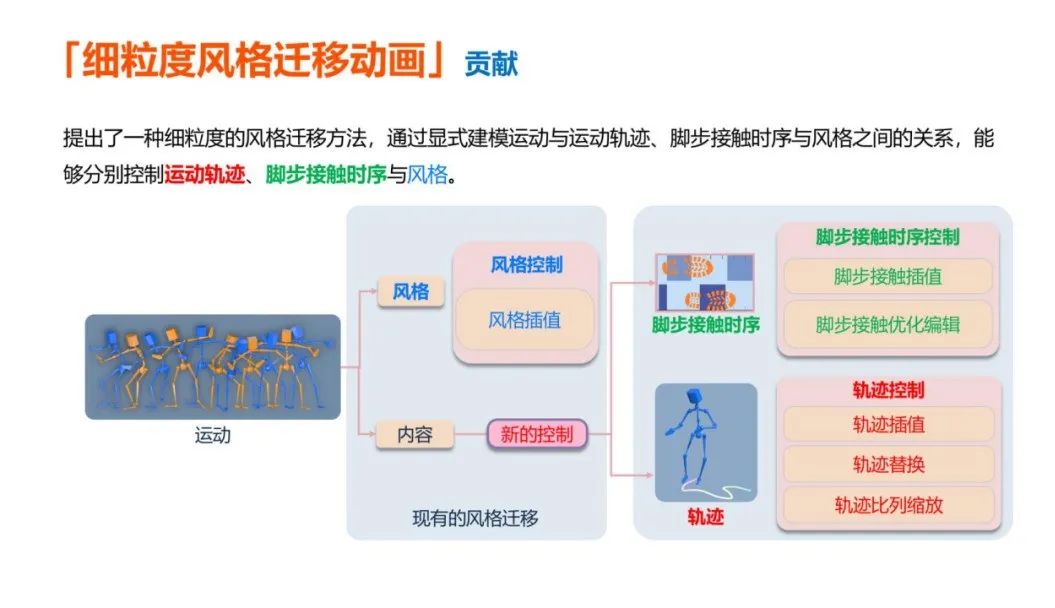
除了提出细粒度的风格迁移方法外,还提出了基于 Transformer 架构的运动流形,能够更好地控制 contact。运动流形还可以同细粒度风格迁移结合,提升运动质量与可控性。
这种方法可适用于复杂轨迹的插值,还可以直接通过缩放髋关节的速度大小来改变运动轨迹,同时保持运动风格与脚步接触时序。此外,该方法也可以通过对脚步接触轨迹的插值来精确控制脚步接触时序。生成动画的风格表现力也可以通过数值来控制,不同的风格可以通过不同的权重糅合在同一个动作动画中。结合上述控制,就可以生成较为精确的特定类型动作动画。例如,使用老人的动作风格、较慢的移动速度、较小的脚步间隔就可以生成与真实老人相像的动作动画。
通过这种方法可以生成自然、高质量的多种类型的动作动画,其水平接近动作捕捉的结果,成本还可以得到大幅下降。
【达摩链接】生态系列内容
“达摩链接”生态系列讲座作为连接达摩院与学术界、产业界的社区活动,通过组织内外部的沙龙、讲座等形式,旨在促进前沿技术的分享交流,推动技术成果的转化、合作与应用落地。
为了让更多开发者、学术研发人员能够深入了解“达摩链接”生态系列讲座的分享内容,我们现将精彩要点整理成文。本文为分享人观点/研究数据,仅供参考,不代表本账号观点和研究内容。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









