






SQL251:获取employees中的first_name
SQL254:分页查询employees表,每5行一页,返回第2页的数据
SQL256:使用含有关键字exists查找未分配具体部门的员工的所有信息。
SQL259:统计salary的累计和running_total
SQL260:给出employees表中排名为奇数行的first_name
SQL267:牛客每个人最近的登录日期(三) :主要考察次日留存率的计算
SQL251:获取employees中的first_name
-- 方法一:right从右边截取
select first_name
from employees
order by right(first_name,2);
-- 方法二:substr,设置起始值为-2,从倒数第二个字符开始截取,截取对应长度
select first_name
from employees
order by substr(first_name,-2,2);SQL252:按照dept_no进行汇总
-- group_concat聚合函数:一般与group by搭配,且默认分隔符为逗号
select dept_no
,group_concat(emp_no) as employees
from dept_emp
group by dept_no;SQL253:平均工资
-- 方法一:排序窗口函数
select avg(salary) as avg_salary
from (
select salary
,rank() over(order by salary desc) dn -- 最高薪水
,rank() over(order by salary) an -- 最低薪水
from salaries
where to_date = '9999-01-01'
) a
where dn > 1 and an >1; -- 同时过滤最高和最低薪水
-- 方法二:利用聚合函数计算,确定分子和分母,有弊端,如果存在多个最高和最低则数据不对
select (sum(salary)-max(salary)-min(salary))/(count(emp_no)-2) as avg_salary
from salaries
where to_date='9999-01-01';SQL254:分页查询employees表,每5行一页,返回第2页的数据

-- 未要求按某个字段排序,这里不做排序处理了
select *
from employees
limit 5,5;SQL256:使用含有关键字exists查找未分配具体部门的员工的所有信息。
select emp.*
from employees emp
where not exists (
select 1
from dept_emp dep
where emp.emp_no = dep.emp_no
);SQL258:获取有奖金的员工相关信息。
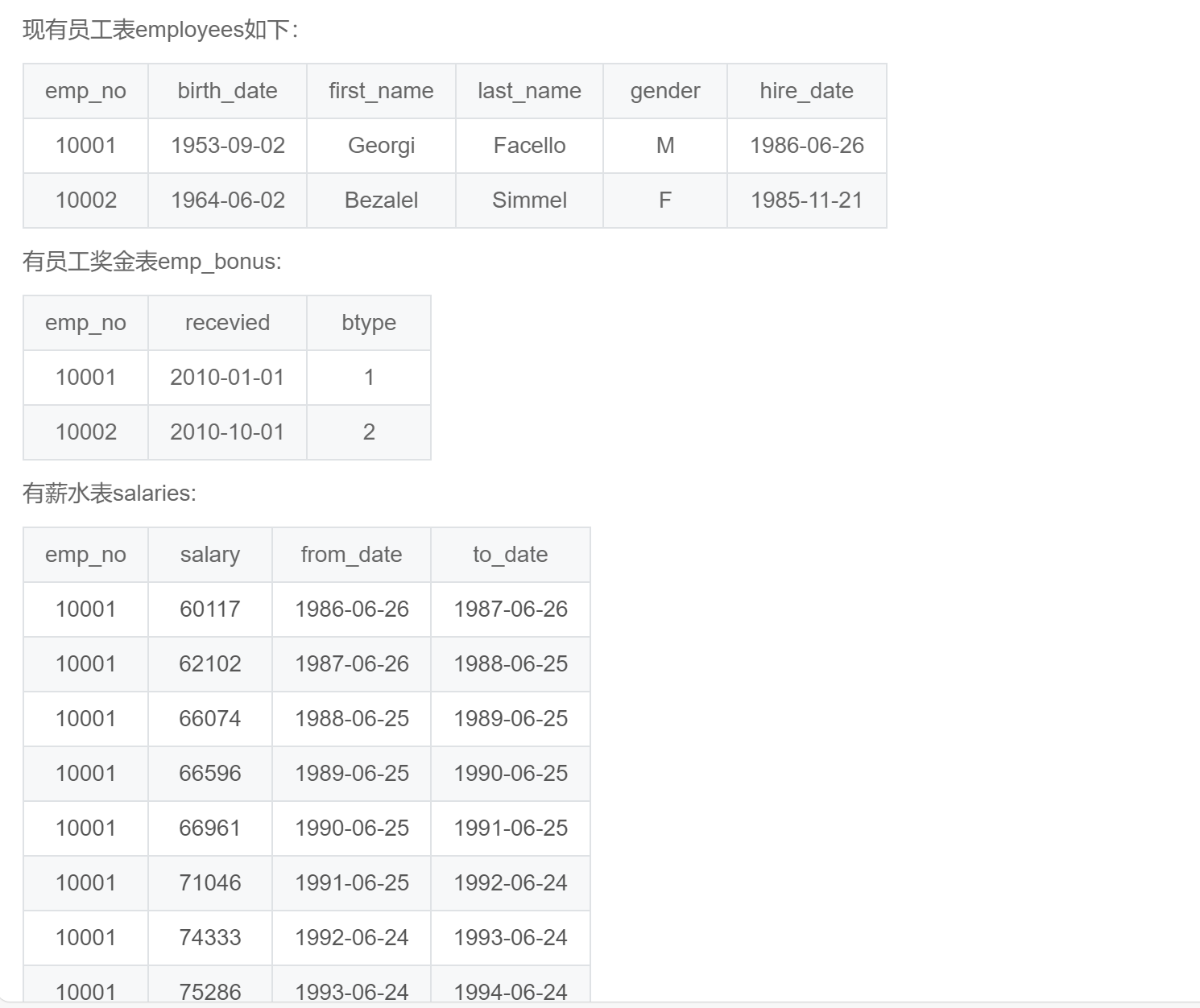
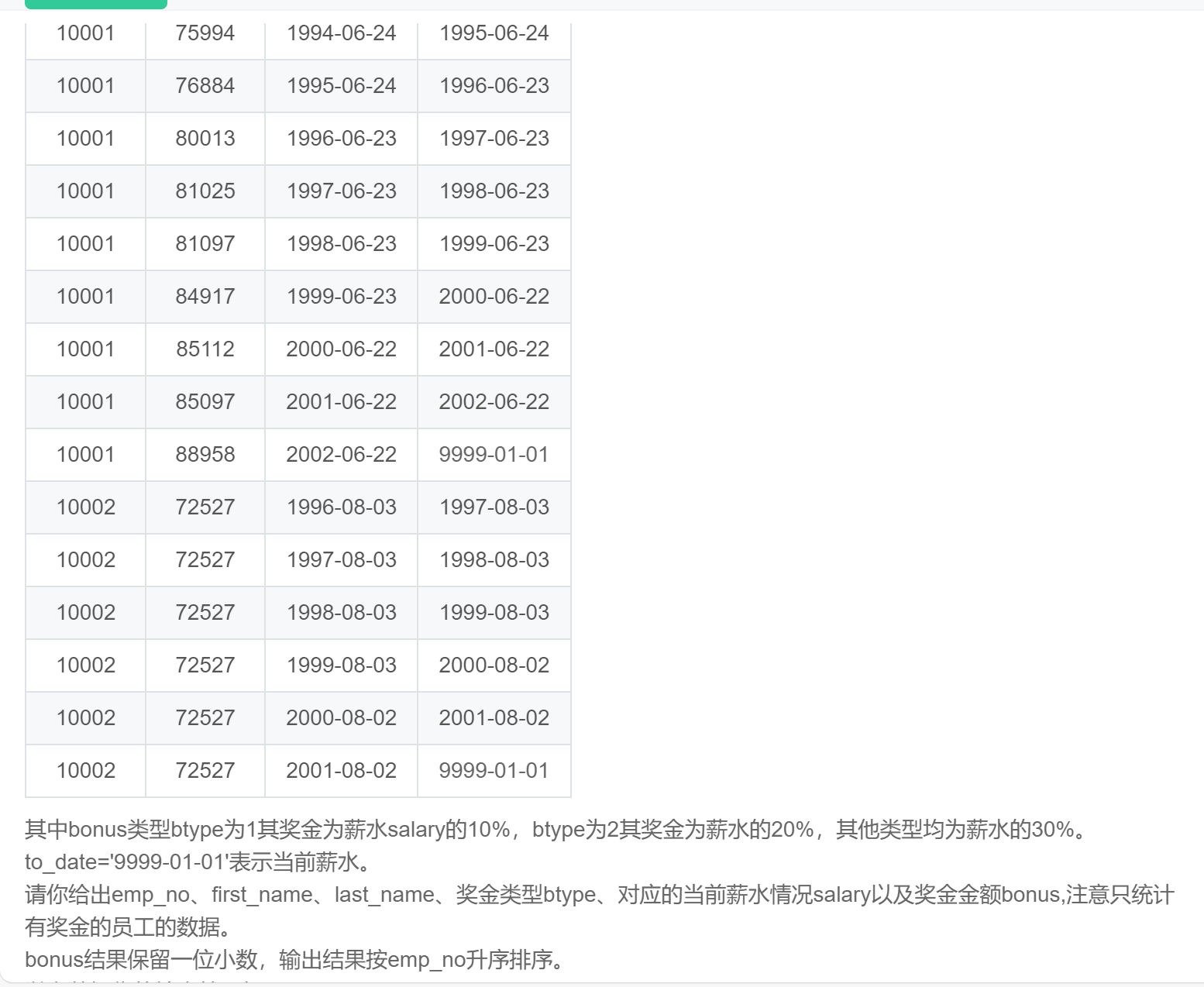
select emp.emp_no
,first_name
,last_name
,btype
,salary
,case when btype = 1 then 0.1*salary
when btype = 2 then 0.2*salary
else 0.3*salary
end as bonus
from employees emp
inner join emp_bonus bon
on emp.emp_no = bon.emp_no
inner join salaries s
on emp.emp_no = s.emp_no
and to_date='9999-01-01';SQL259:统计salary的累计和running_total
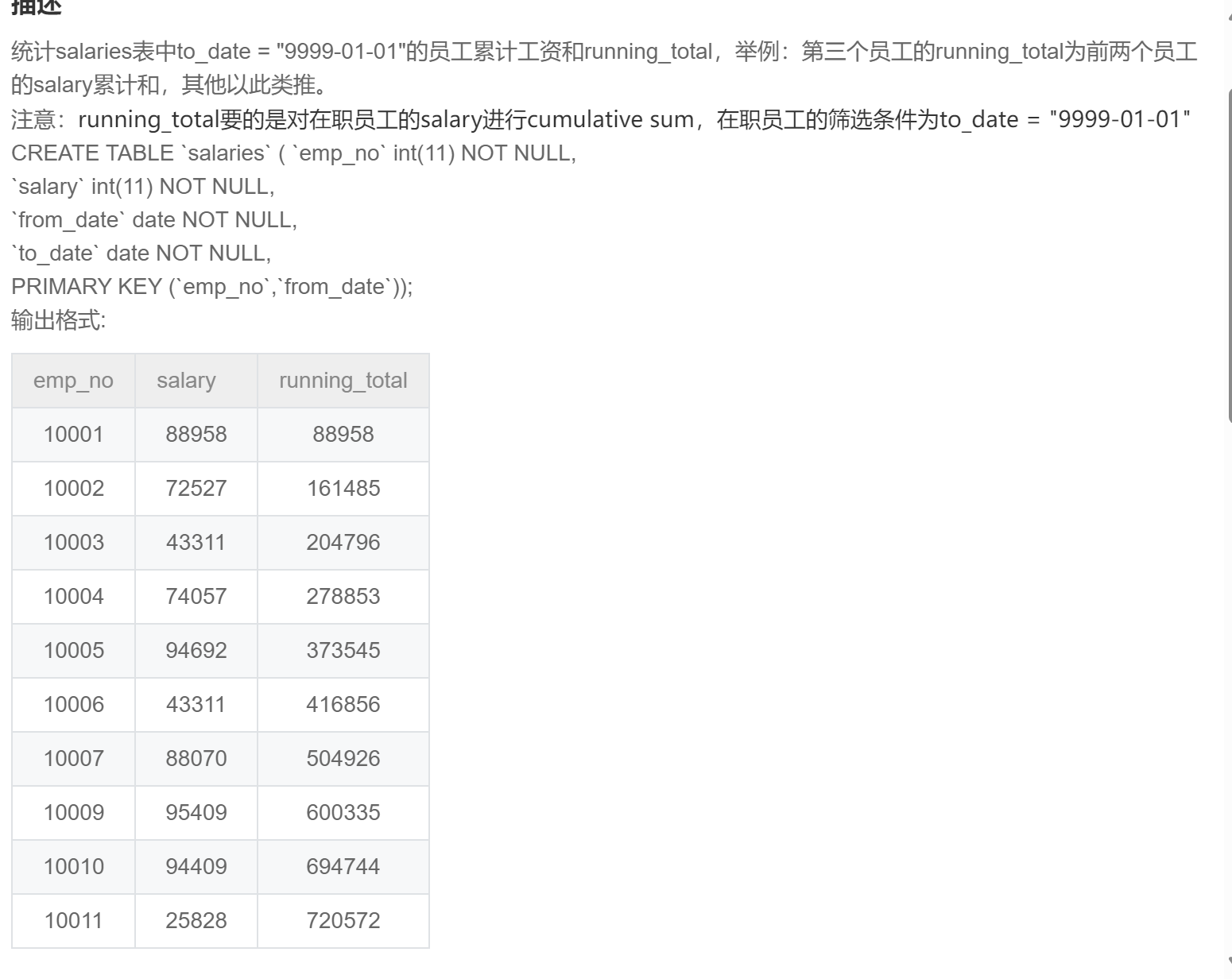
-- 考察聚合窗口函数的累加求和使用
select emp_no
,salary
,sum(salary) over(order by emp_no) as running_total
from salaries
where to_date = '9999-01-01';SQL260:给出employees表中排名为奇数行的first_name
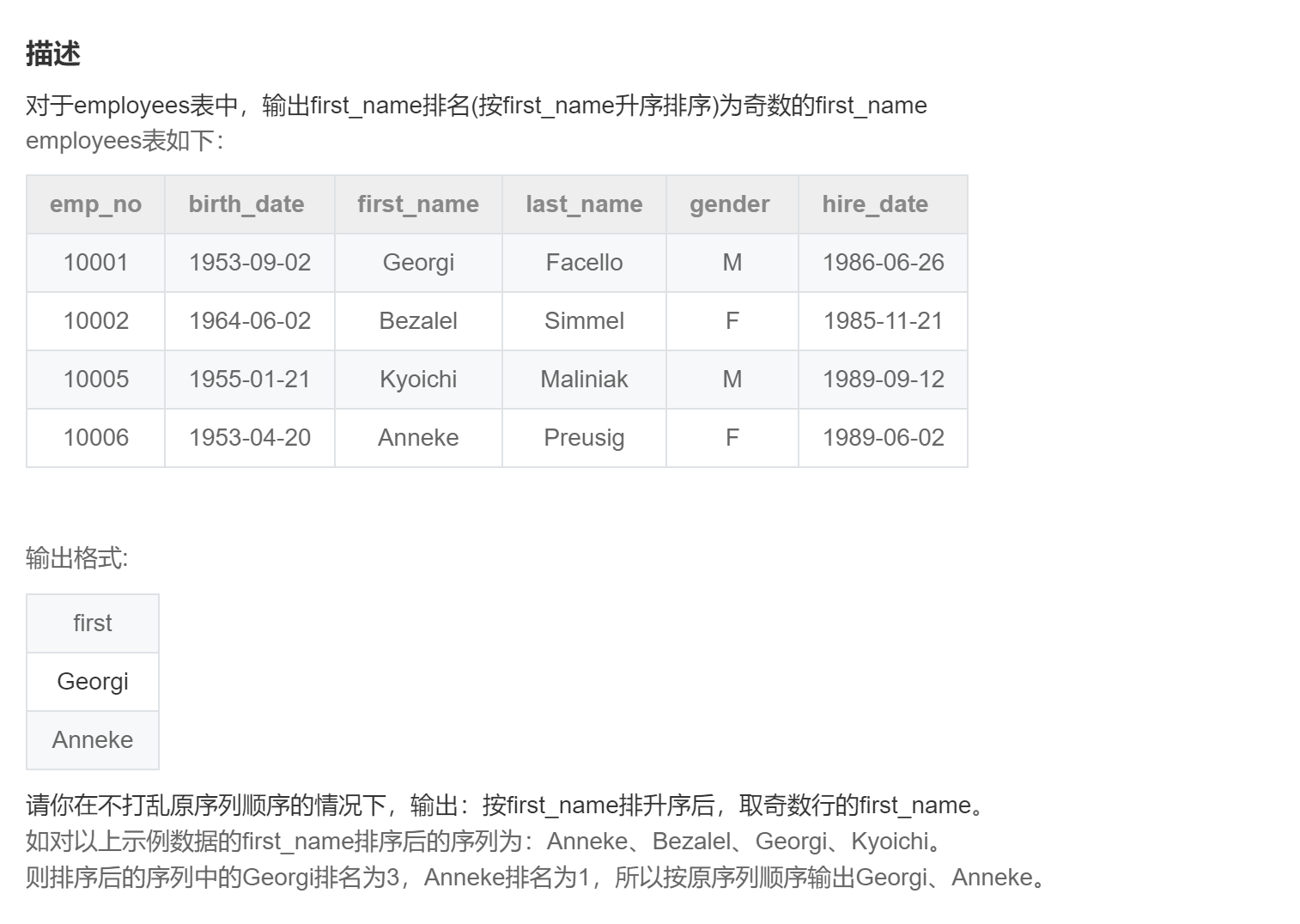
-- 方法一:利用排序开窗函数
select e1.first_name
from employees e1
inner join
(
select first_name
,row_number() over(order by first_name) as rn
from employees
) e2
on e1.first_name = e2.first_name
where rn % 2 = 1;
-- 方法二:利用聚合开窗函数累加计数的特点
select first_name
from (
select first_name -- 保持原有排序
,count(emp_no) over(order by first_name) cnt -- 按照题目要求排序获取奇数数据
from employees
order by emp_no
) a
where cnt % 2 = 1;SQL261:出现三次以上相同积分的情况

select number
from grade
group by number
having count(id) >= 3;SQL262:刷题通过的题目排名
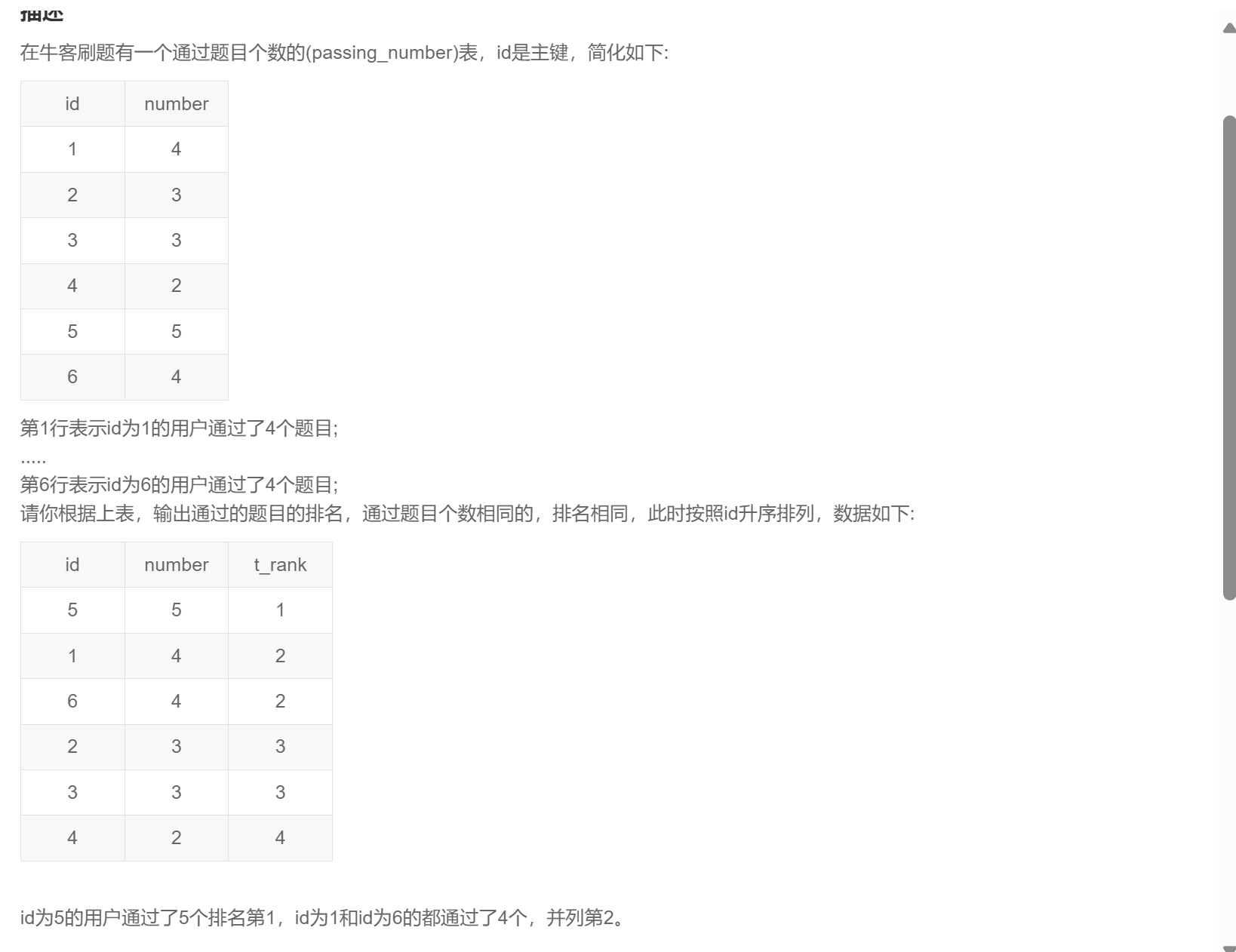
select id
,number
,dense_rank() over(order by number desc) as t_rank
from passing_number
order by t_rank,id;SQL263:找到每个人的任务

select p.id
,name
,content
from person p
left join task t
on p.id = t.person_id
order by p.id;SQL264:异常的邮件概率
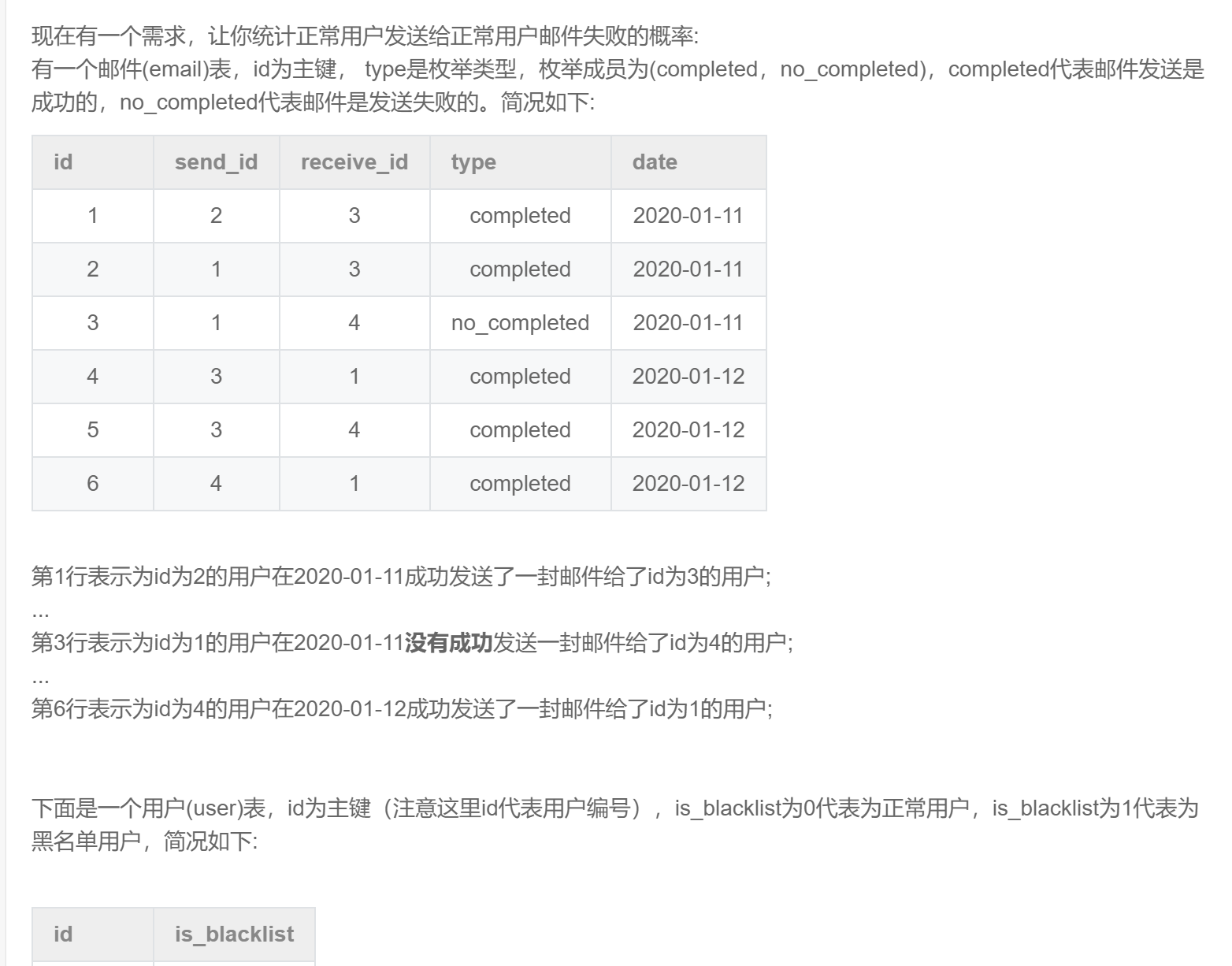

select date
,round(count(case when type = 'no_completed' then 0 else null end)
/ count(type),3) -- 失败记录数/当天记录总数
from email
where send_id in (select id from user where is_blacklist = 0) -- 获取发送方正常用户
and receive_id in (select id from user where is_blacklist = 0) -- 获取接收方正常用户
group by date
order by date;SQL265:牛客每个人最近的登录日期(一)
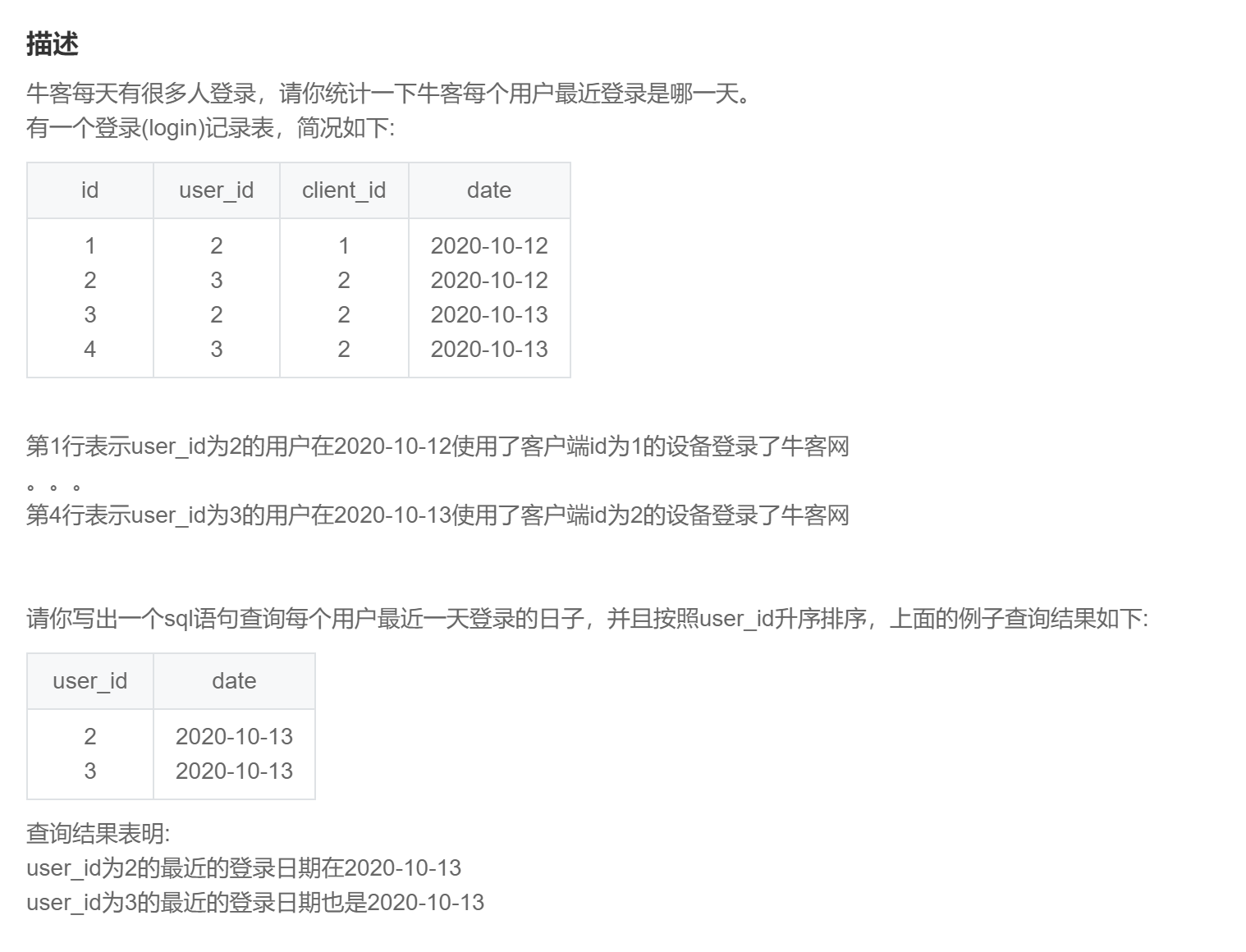
-- 这里仅写聚合函数的用法,窗口函数不再赘述,相较而言在这里不如聚合函数
select user_id
,max(date) as date
from login
group by user_id
order by user_id;SQL266:牛客每个人最近的登录日期(二)

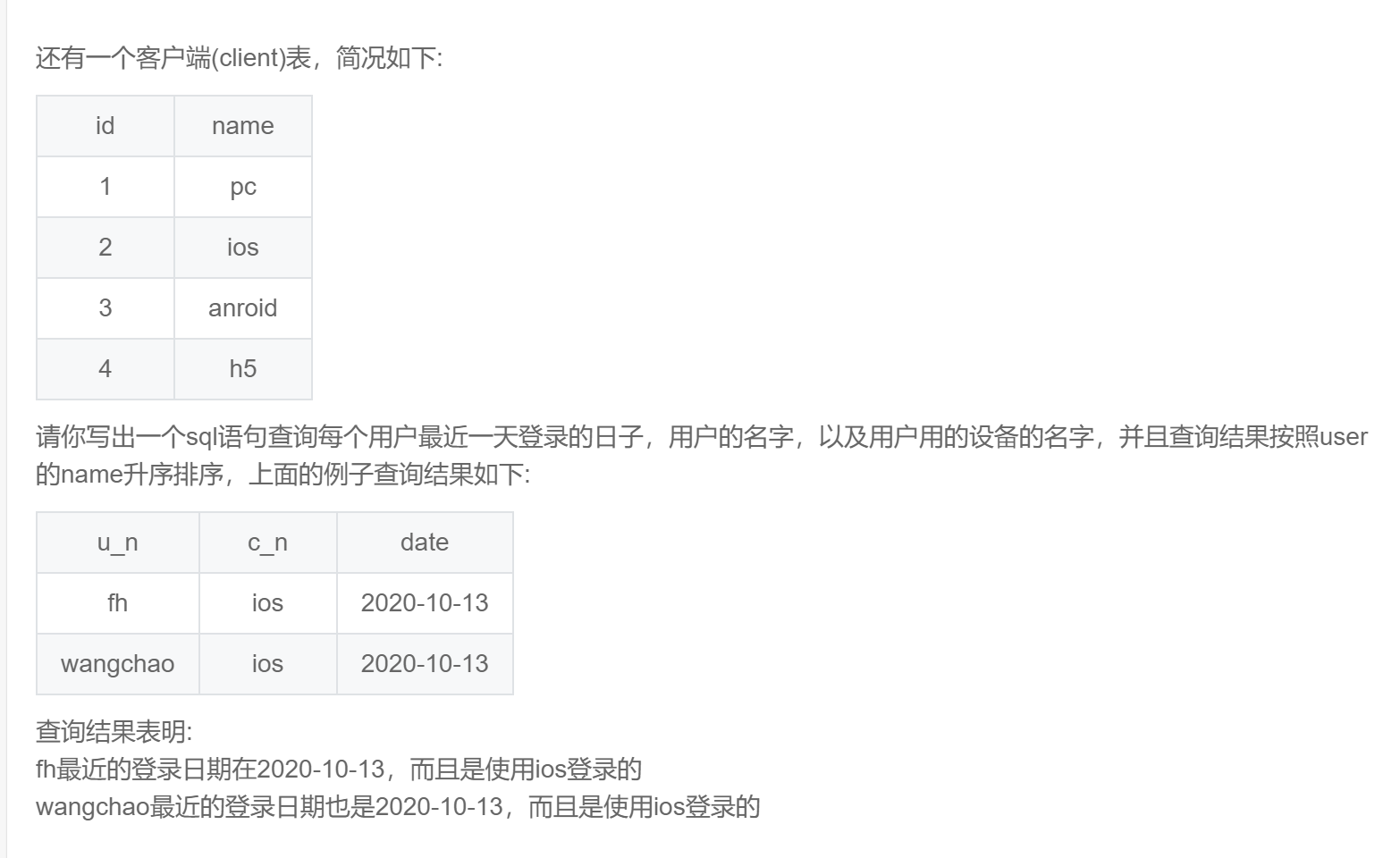
with temp as (
select user_id
,client_id
,date
,row_number() over(partition by user_id order by date desc) as rn
from login
)
select u.name as u_n
,c.name as c_n
,date
from temp l
inner join user u
on l.user_id = u.id -- 获取用户名称
inner join client c
on l.client_id = c.id -- 获取用户设备名称
and l.rn = 1
order by u.name;SQL267:牛客每个人最近的登录日期(三) :主要考察次日留存率的计算
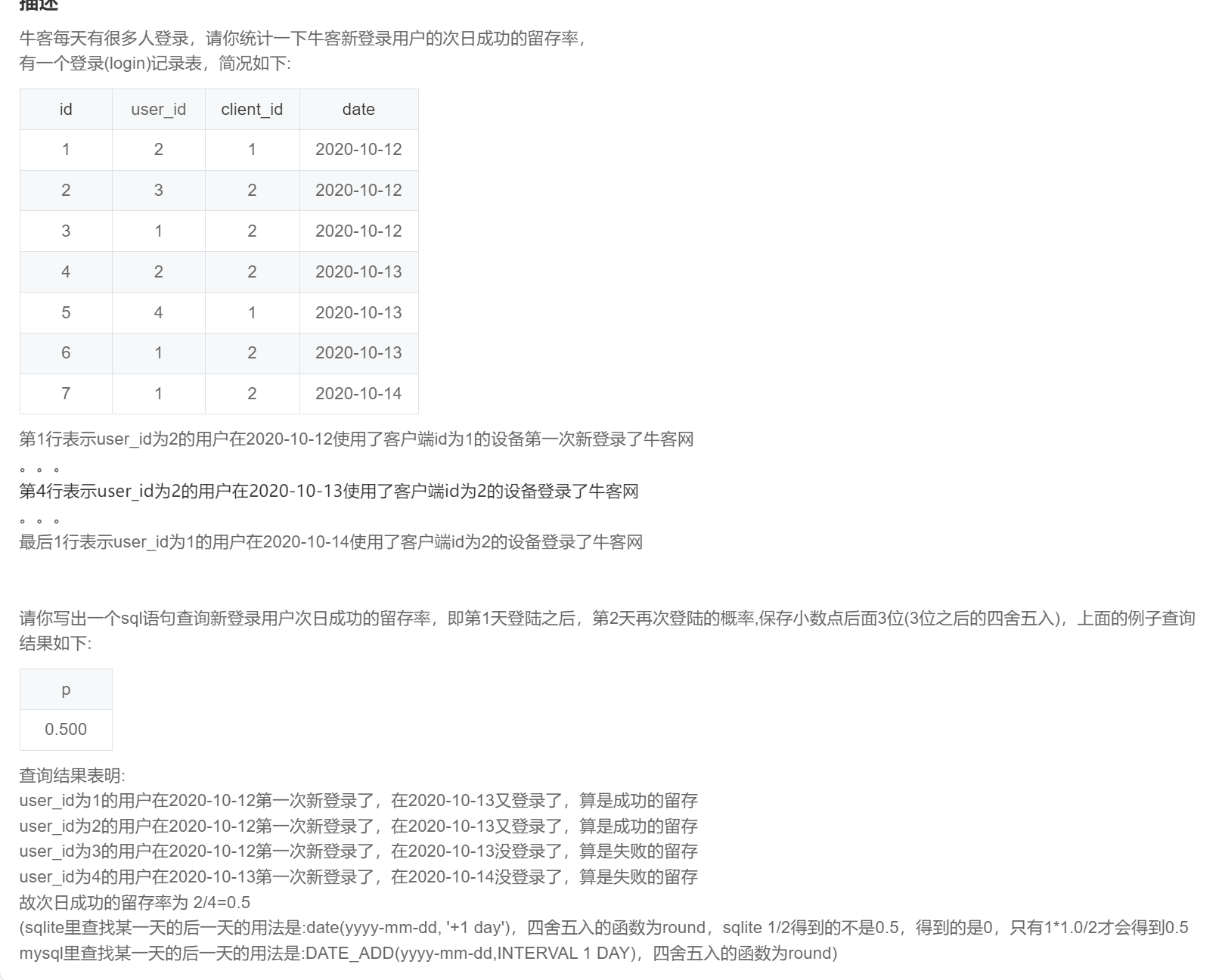
-- 方法一:利用 lead() over() 位移窗口函数构造一列存储后一天的日期数据
-- lead(字段,偏移量,返回值)主要是访问当前行之后指定偏移量的数据,默认偏移量为1,
-- 当没有后一行的数据时且返回值未指定则默认返回为 null
with temp as (
select user_id
,date
,lead(date) over(partition by user_id order by date) as next_date
from login
)
select round(count(distinct case when next_date is not null -- 获取次日登录的用户数
and next_date = date_add(date,interval 1 day) then user_id else null end)
/ count(distinct user_id),3) as p -- 获取当前表中的所有用户数
from temp;
-- 方法二:连接
select
round(count(case when l2.date = date_add(l1.date,interval 1 day) then 0
else null end)/count(distinct l1.user_id),3) as p
from (
select user_id
,min(date) as date
from login
group by user_id
) l1 -- 获取第一天登录用户及其最早日期
inner join login l2
on l1.user_id = l2.user_id;
SQL268:牛客每个人最近的登录日期(四)
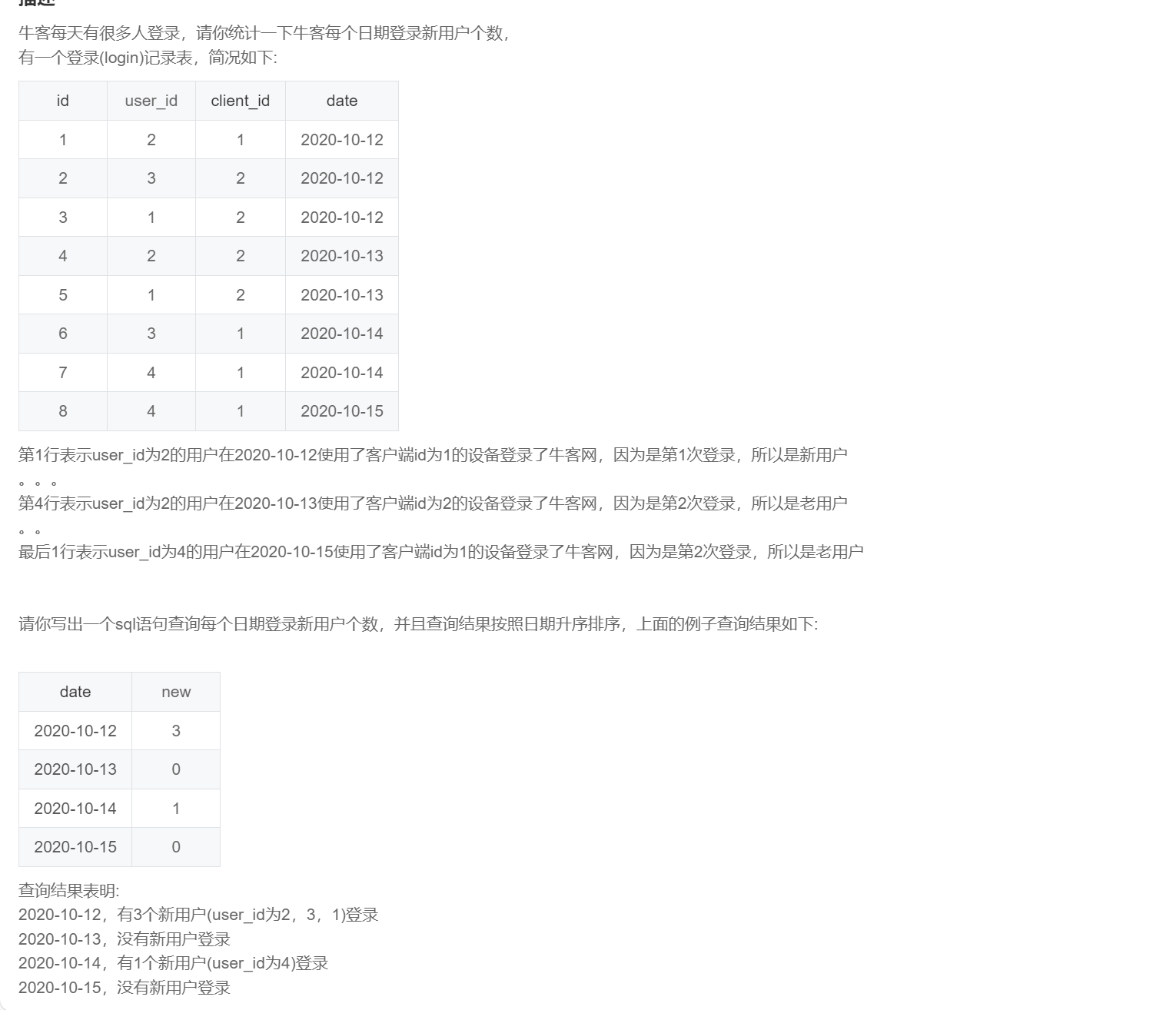
-- 方法一:窗口函数,利用排序获取用户最早登录的序号,统计其对应日期的序号为1的用户即为新用户
select date
,count(case when rn = 1 then 0 else null end) as new
from(
select date
,row_number() over(partition by user_id order by date) as rn
from login
) l
group by date
order by date;
-- 方法二:构造出最早日期表,在最早日期表此用户是否出现过判断是否为新用户
select l2.date as date
,count(case when l1.date = l2.date then 0 else null end) as new
from (
select user_id
,min(date) as date
from login
group by user_id
) l1
left join login l2
on l1.user_id = l2.user_id
group by l2.date
order by l2.date;SQL269:牛客每个人最近的登录日期(五)

with temp as (
select user_id
,date
,row_number() over(partition by user_id order by date) as rn
from login
)
select t.date
-- 考虑分母为0的情况
,case when count(case when rn = 1 then 0 else null end) = 0 then 0.000
else round(count(case when rn = 1 and l.date is not null then 0
else null end)
/ count(case when rn = 1 then 0 else null end),3)
end as p
from temp t
left join login l
on t.user_id = l.user_id
and datediff(l.date,t.date) = 1
group by t.date
order by t.date;SQL270:牛客每个人最近的登录日期(六)
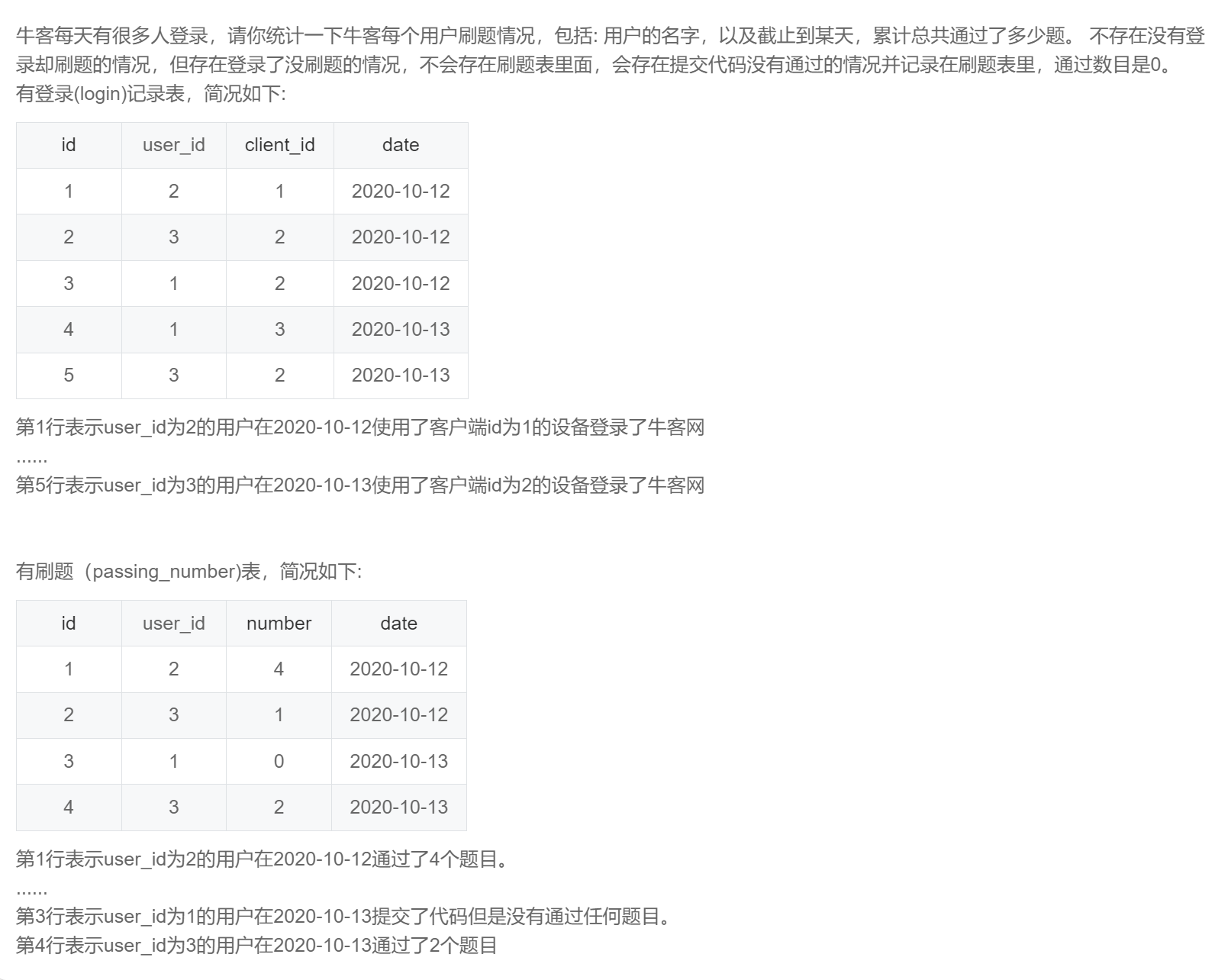
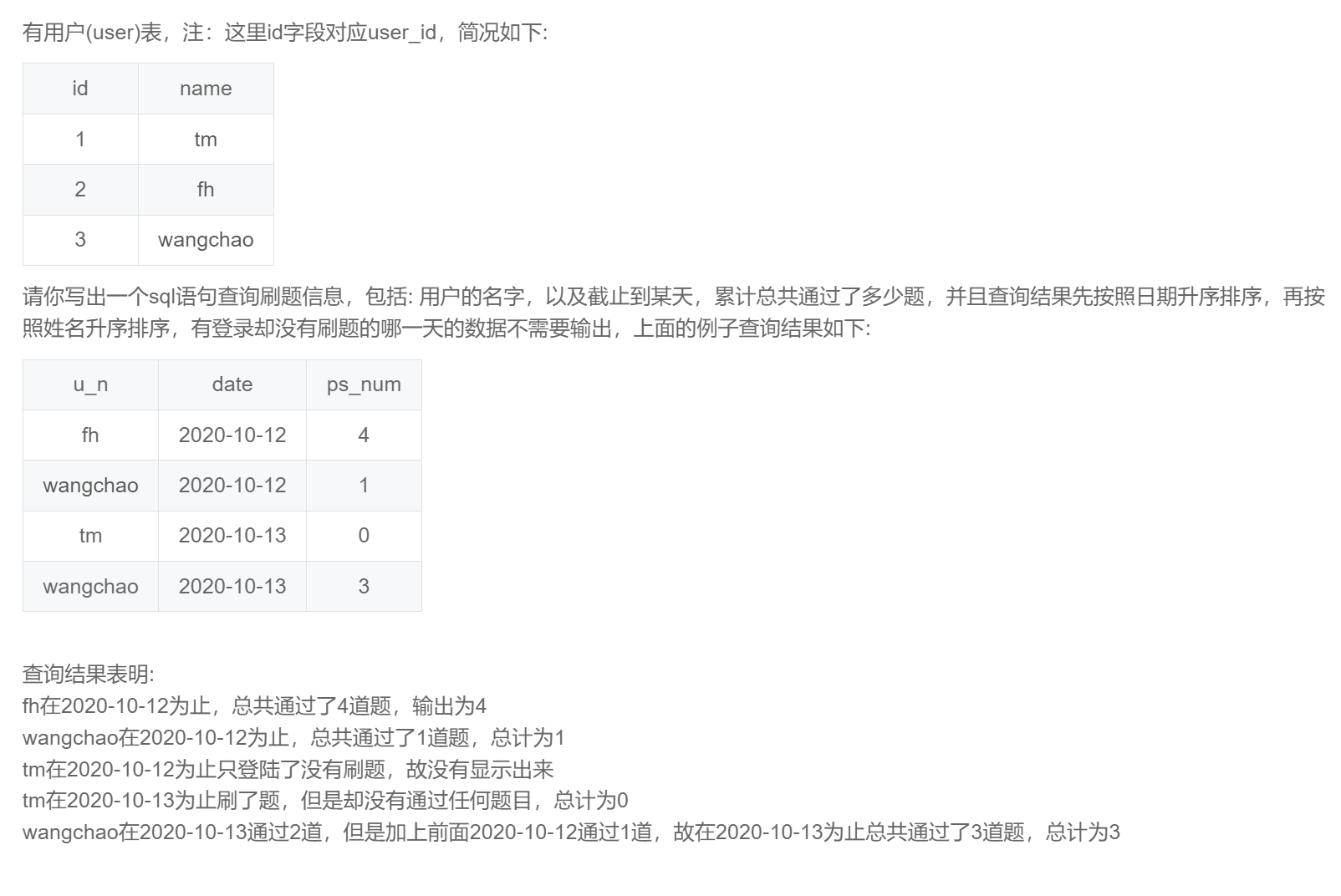
-- 根据题目要求及示例可以看出本题考察的是聚合累加求和窗口函数的的使用
select u.name as u_n
,date
,sum(number) over(partition by user_id order by date) as ps_num
from passing_number pm
inner join user u
on pm.user_id = u.id
order by date,u_n;SQL271:考试分数(一)

select job
,round(avg(score),3) as avg
from grade
group by job
order by avg desc;SQL272:考试分数(二)
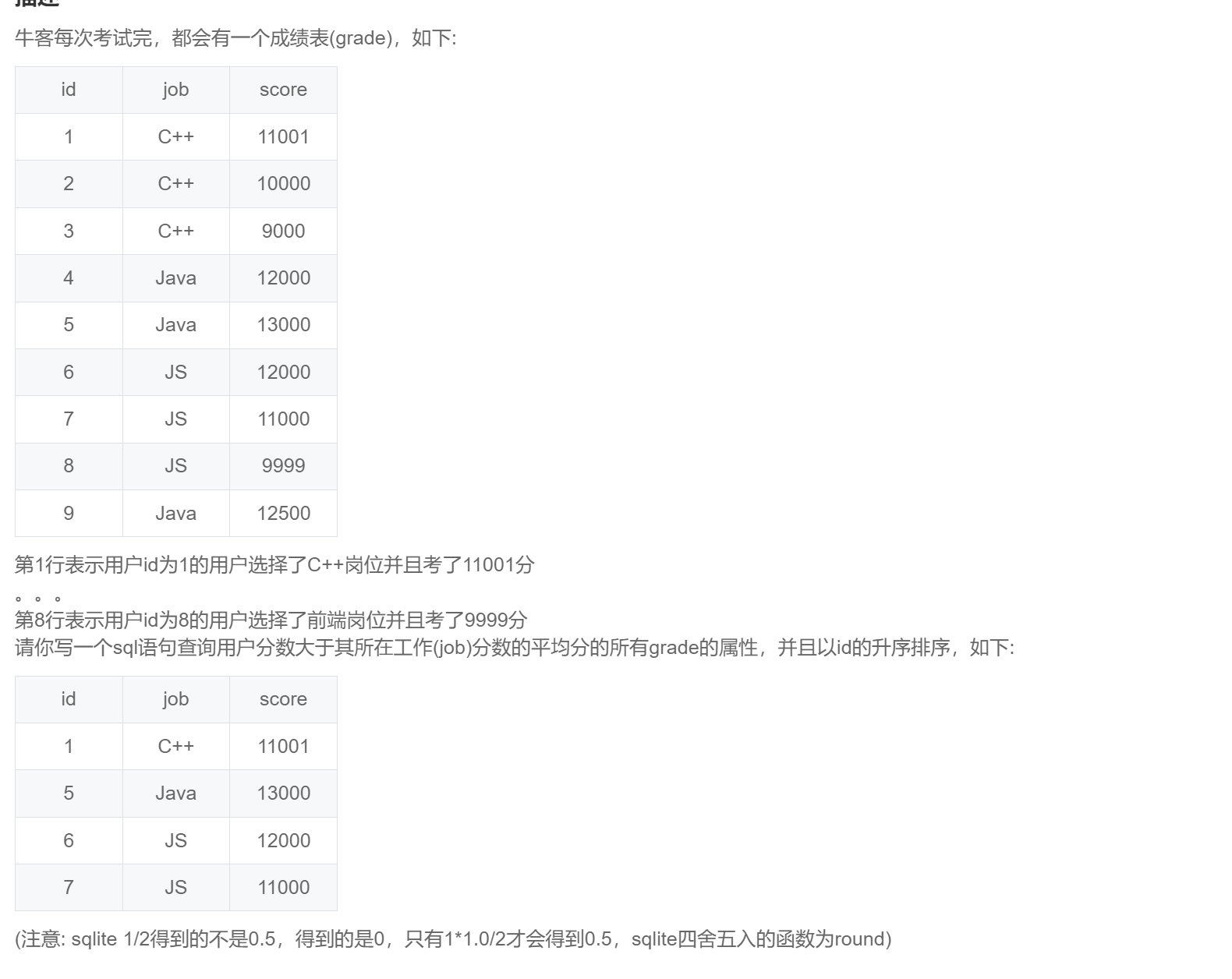
-- 方法一:平均值窗口函数:这里不加 order by 表示仅对同一分组求平均值,加上表示当前行到之前所有行求累计平均值
select id
,job
,score
from (
select *
,avg(score)over(partition by job) as avg
from grade
) a
where score > avg
order by id;
-- 方法二:连接
select g.*
from grade g
inner join
(
select job
,avg(score) avg
from grade
group by job
) a
on g.job = a.job
and g.score > a.avg
order by g.id;SQL273:考试分数(三)
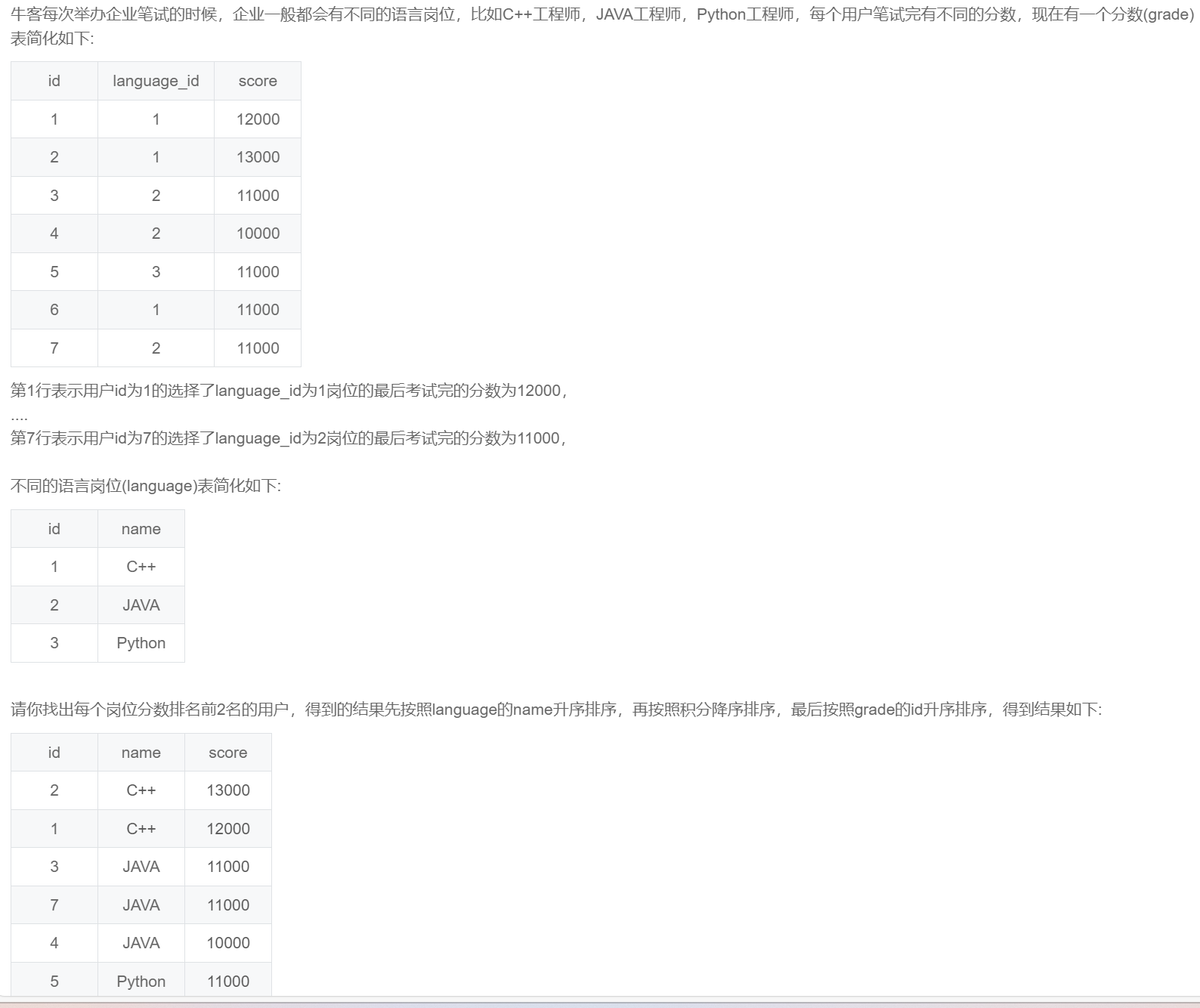
-- 观察示例输出发现java岗位同分数排名并列,且题目要求是前2名,展示了2条同排名+1条单独数据,一起3条数据,所以这里的排序窗口函数只能用 dense_rank
select id
,name
,score
from (
select g.id
,l.name
,score
,dense_rank() over(partition by l.name order by score desc) as dk
from grade g
inner join language l
on g.language_id = l.id
) a
where a.dk <= 2
order by name,score desc,id;SQL274:考试分数(四)
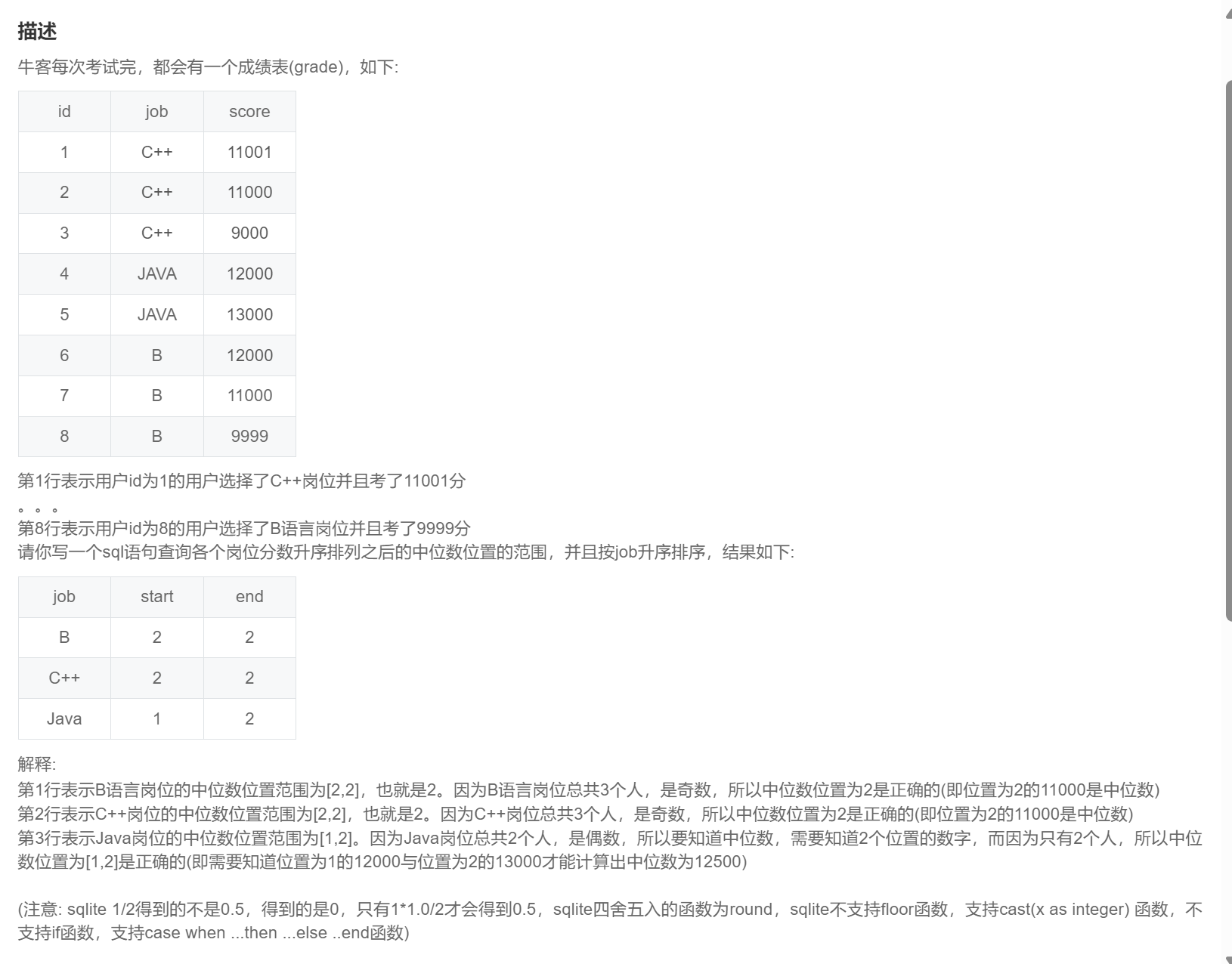
-- ceil向上取整,这里统计的中位数是根据部门人数为奇数和偶数是计算的,实际问题中肯定会存在多个中位数,此时范围将不准确
select job
,round(case when count(id) % 2 = 1 then ceil(count(id)/2)
else count(id) / 2 end) as start
,round(case when count(id) % 2 = 1 then ceil(count(id)/2)
else count(id) / 2 + 1 end,0) as end
from grade
group by job
order by job;SQL275:考试分数(五)
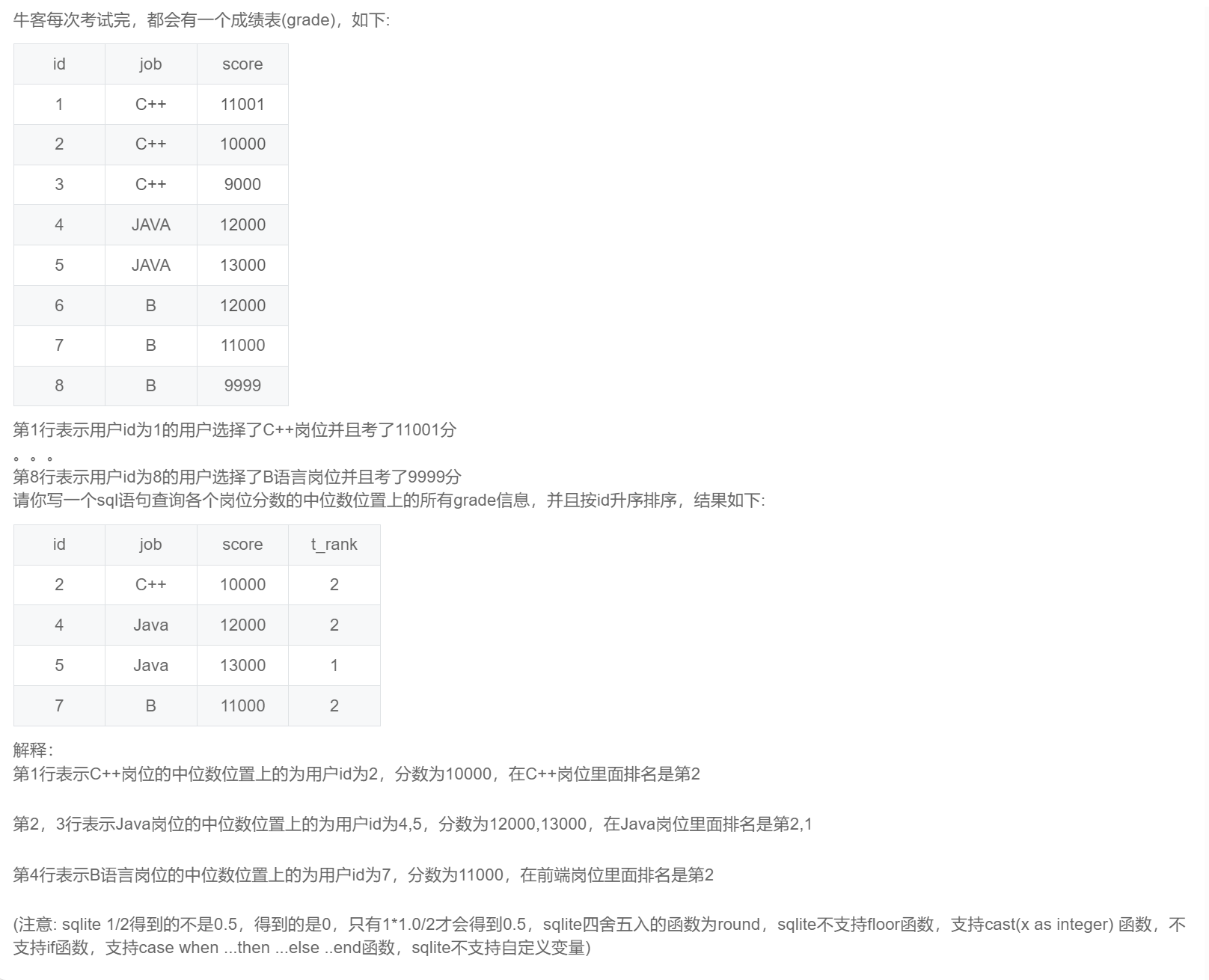
select id
,job
,score
,t_rank
from (
select *
,count(*) over(partition by job) as cnt -- 仅分组统计,用于简化计算
,row_number() over(partition by job order by score desc) as t_rank
from grade
) a
where (cnt % 2 = 1 and t_rank = ceil(cnt / 2)) -- 奇数
or (cnt % 2 = 0 and (t_rank = cnt / 2 or t_rank = cnt / 2 + 1)) -- 偶数
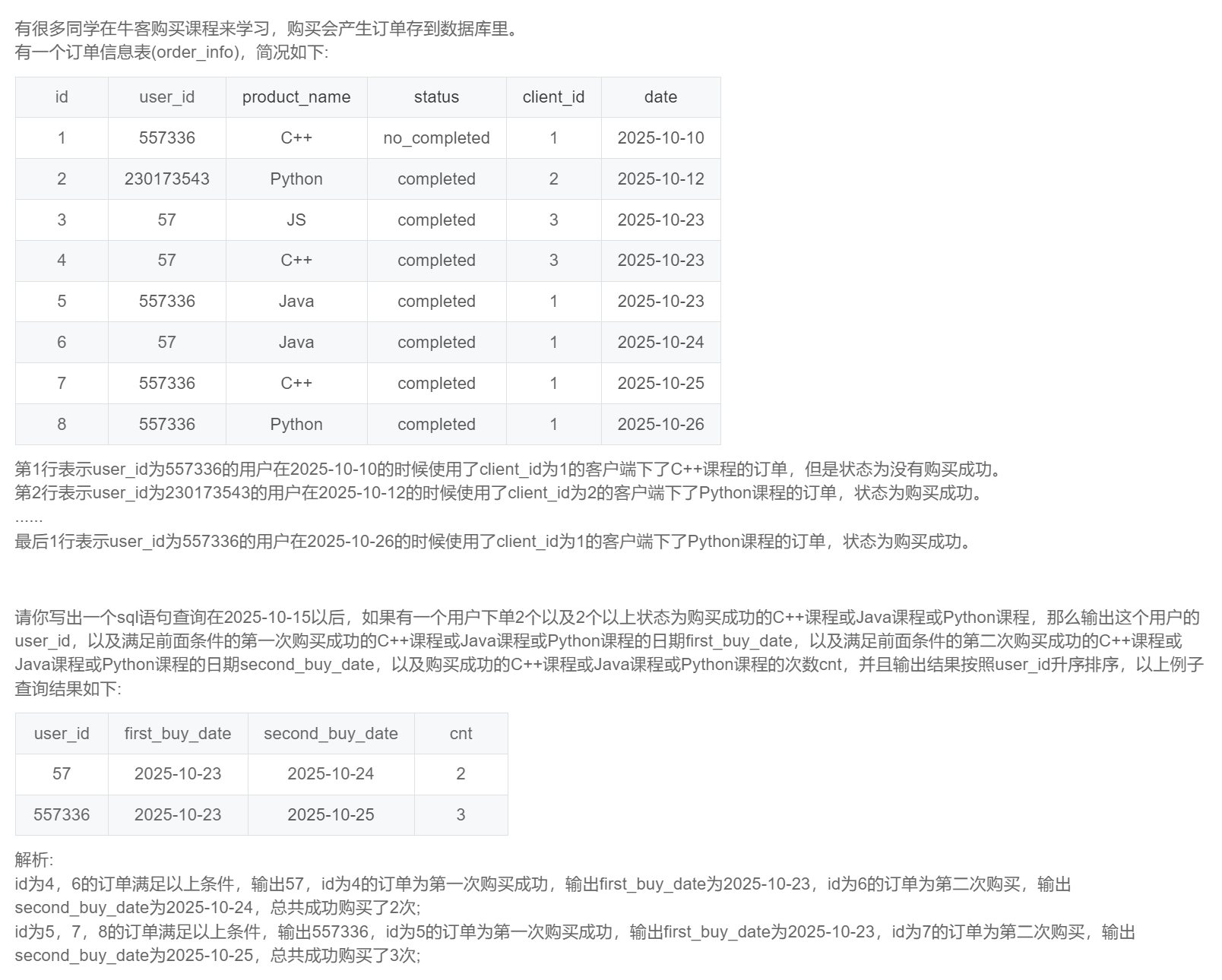
order by id;SQL276:牛客的课程订单分析(一)
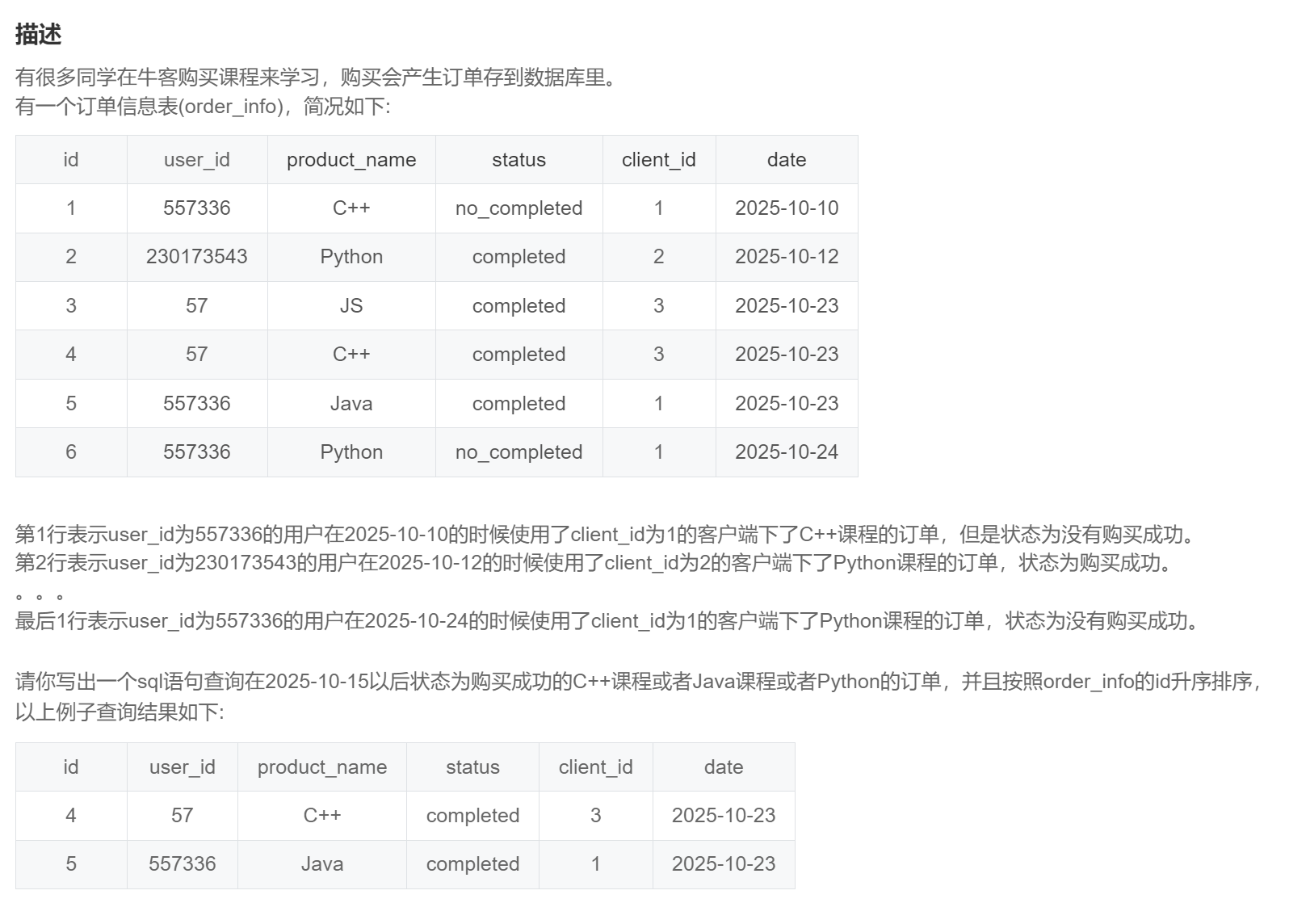
select *
from order_info
where date > '2025-10-15'
and status = 'completed'
and product_name in ('C++','Java','Python');SQL277:牛客的课程订单分析(二)
select user_id
from order_info
where date > '2025-10-15'
and status = 'completed'
and product_name in ('C++','Java','Python')
group by user_id
having count(status) >= 2
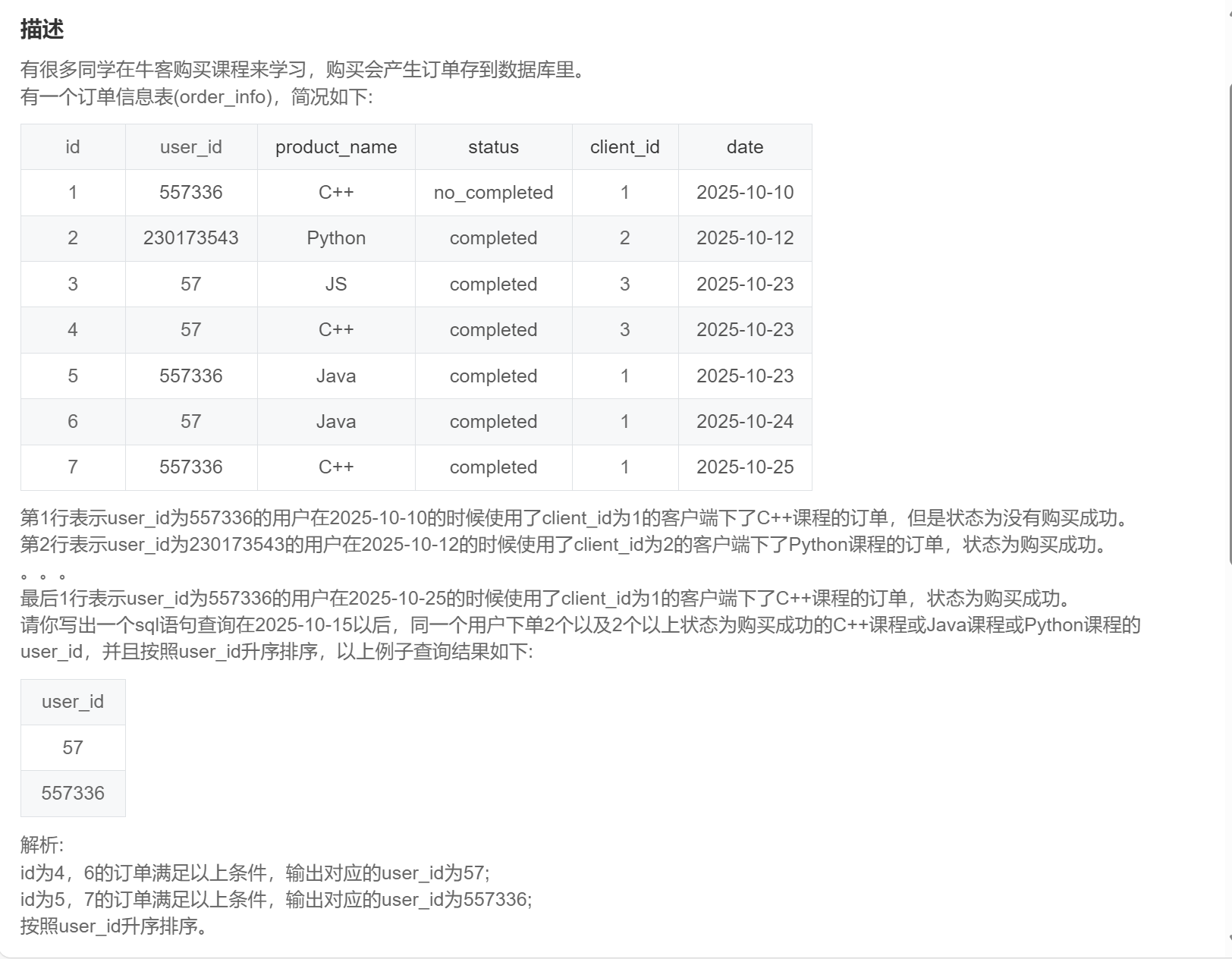
order by user_id;SQL278:牛客的课程订单分析(三)
-- 由于此题需要返回多个字段,所以不能使用having 语句实现,利用窗口函数
select id
,user_id
,product_name
,status
,client_id
,date
from (
select *
,count(*) over(partition by user_id) as cnt -- 同组生成多个相同的数量
from order_info
where date > '2025-10-15'
and status = 'completed'
and product_name in ('C++','Java','Python')
) a
where cnt >= 2
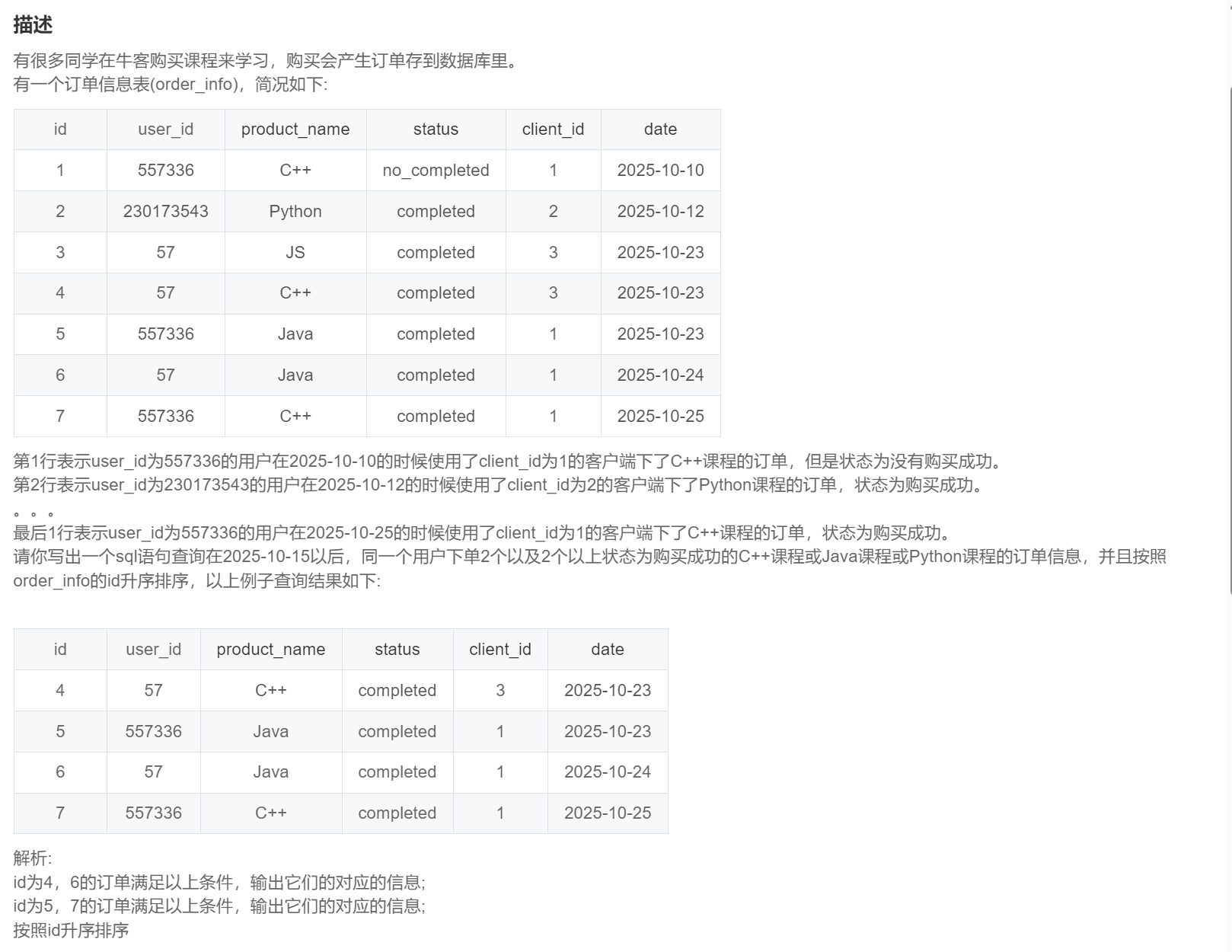
order by id;SQL279:牛客的课程订单分析(四)
select user_id
,date as first_buy_date
,cnt
from (
select *
,count(*) over(partition by user_id) as cnt
,row_number() over(partition by user_id order by date) as rn
from order_info
where date > '2025-10-15'
and status = 'completed'
and product_name in ('C++','Java','Python')
) a
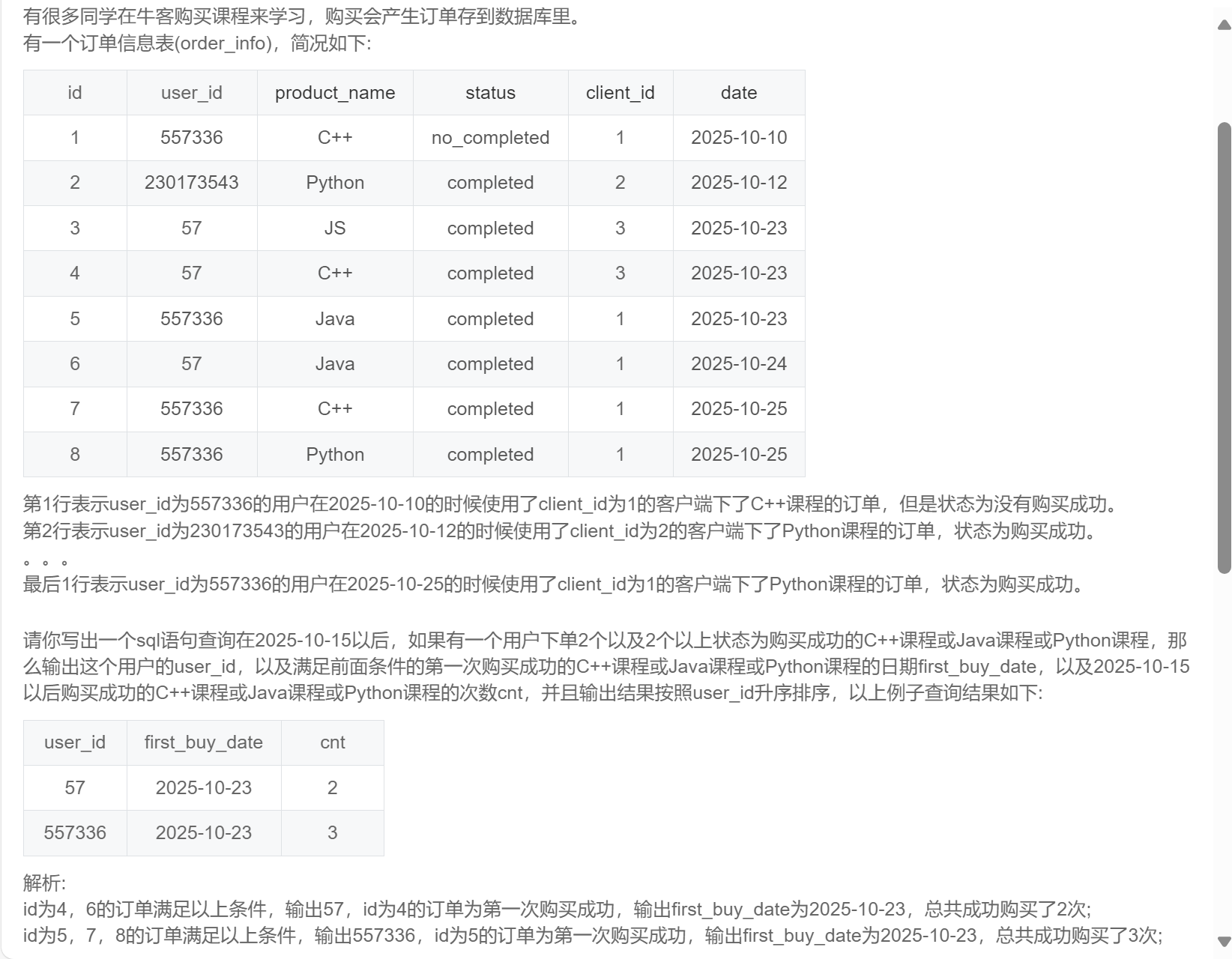
where cnt >= 2 and rn = 1;SQL280:牛客的课程订单分析(五)
-- 相较于上一题,加了一个lead位移函数用于构造第二天的数据
select user_id
,date as first_buy_date
,next_day as second_buy_date
,cnt
from (
select *
,lead(date) over(partition by user_id order by date) as next_day
,row_number() over(partition by user_id order by date) as rn
,count(*) over(partition by user_id) as cnt
from order_info
where date > '2025-10-15'
and status = 'completed'
and product_name in ('C++','Java','Python')
) a
where cnt >= 2 and rn = 1
and next_day is not null -- 不展示第二天为空的数据
order by user_id;SQL281:牛客的课程订单分析(六)
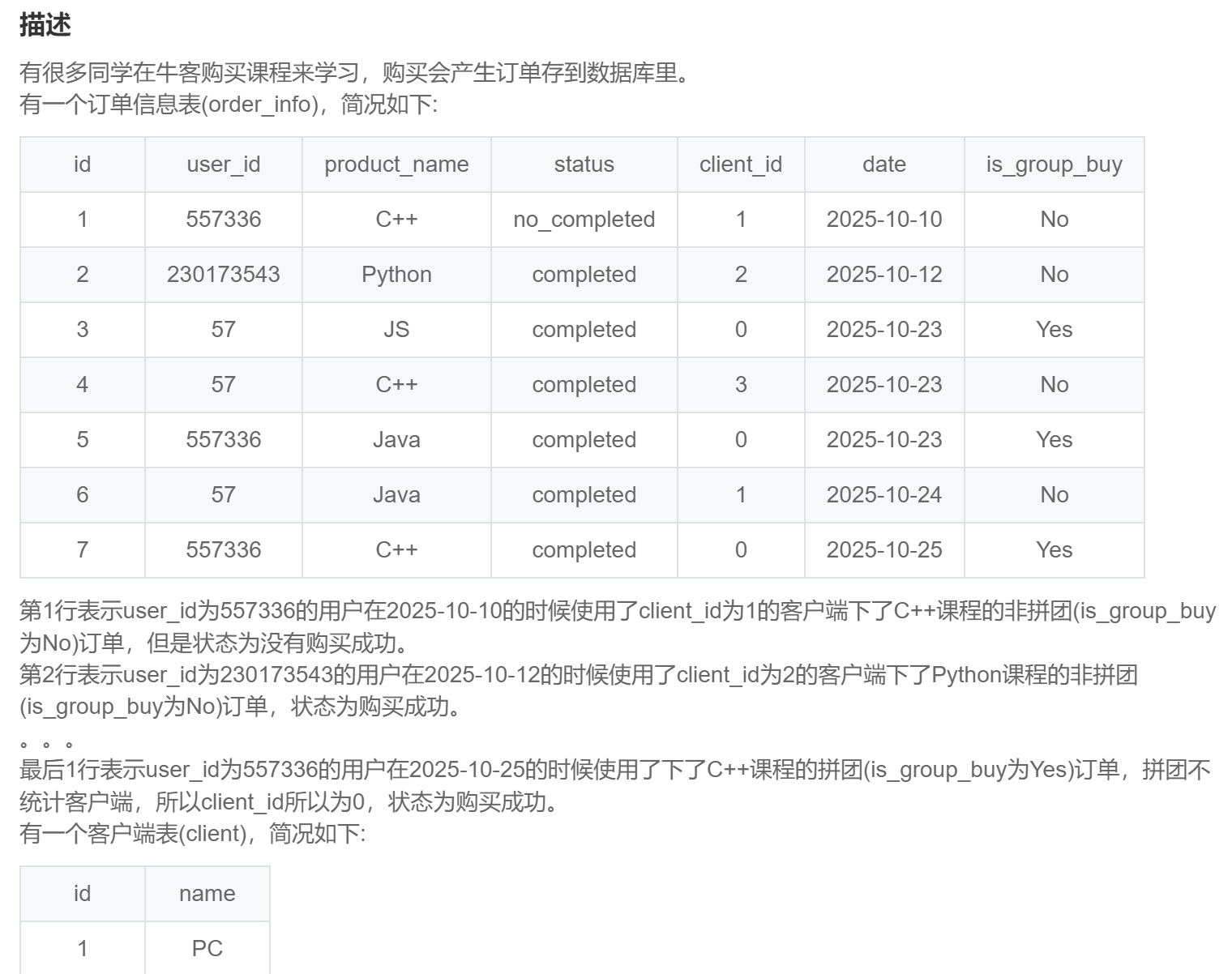

with temp as (
select *
,count(*) over(partition by user_id) as cnt
from order_info
where date > '2025-10-15'
and status = 'completed'
and product_name in ('C++','Java','Python')
)
select t.id
,is_group_buy
,case when is_group_buy = 'No' then c.name else null end as client_name
from temp t
left join client c
on t.client_id = c.id
where t.cnt >= 2
order by t.id;SQL282:牛客的课程订单分析(七)
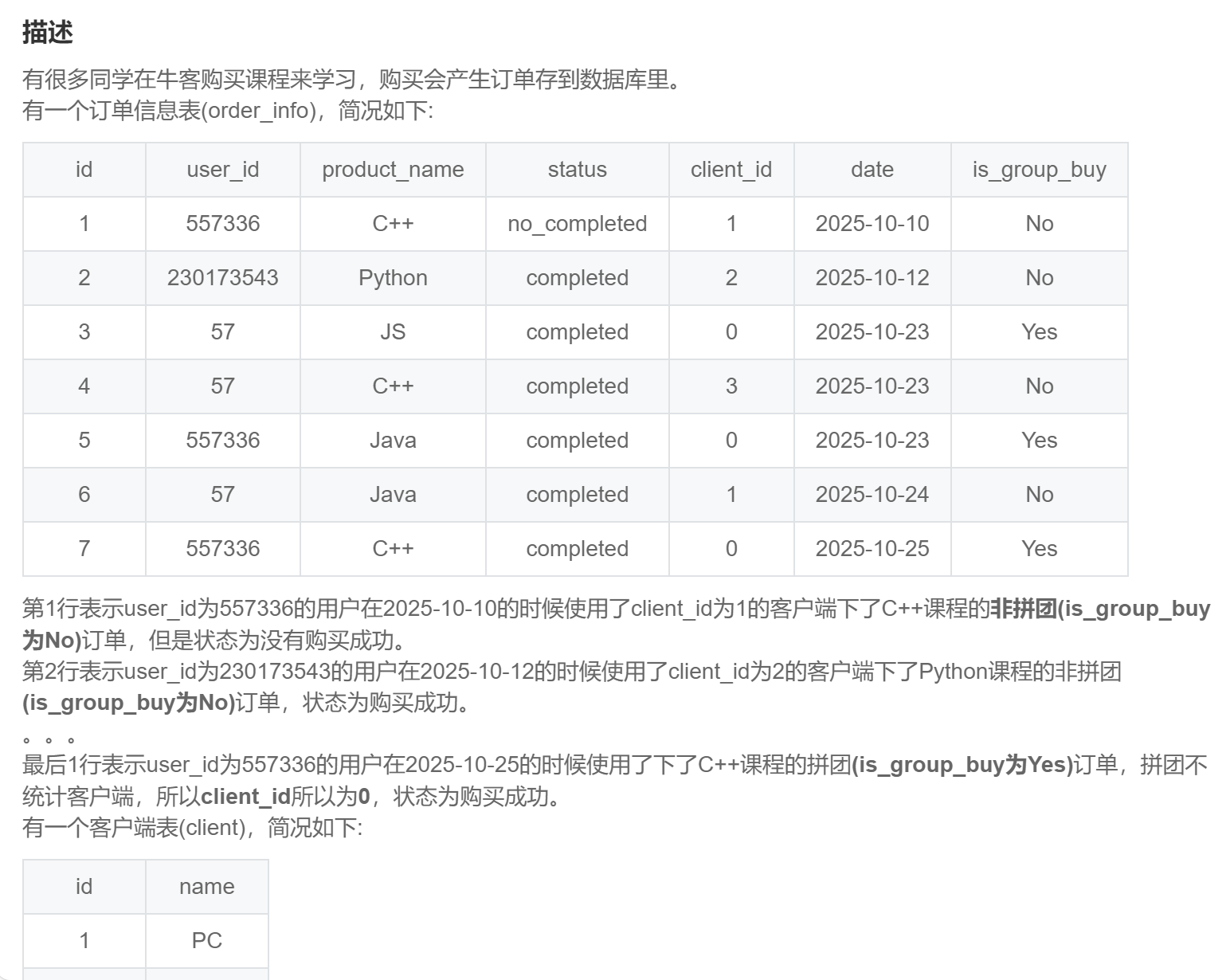
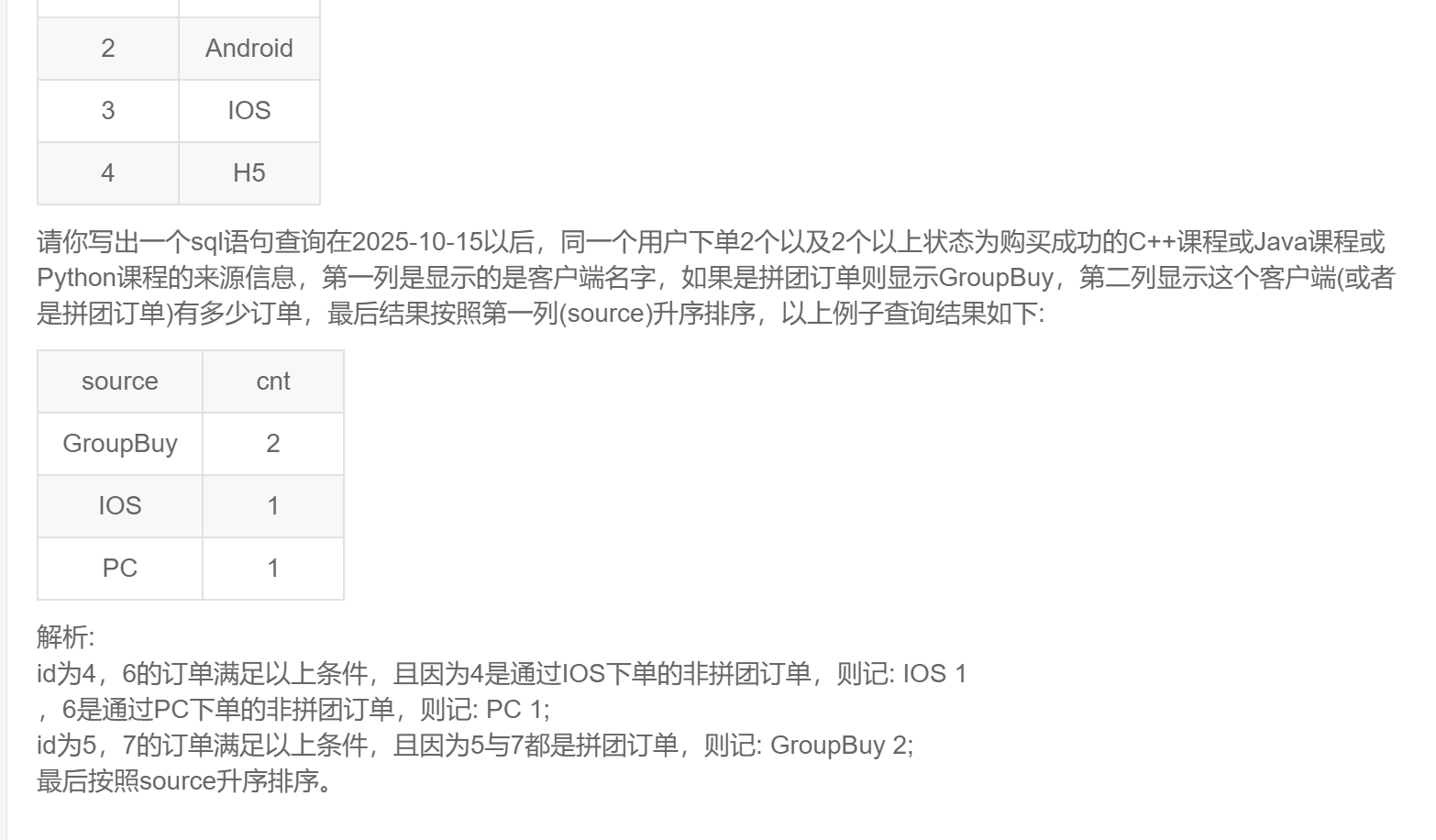
with temp as (
select *
,count(*) over(partition by user_id) as cnt
from order_info
where date > '2025-10-15'
and status = 'completed'
and product_name in ('C++','Java','Python')
)
select case when is_group_buy = 'Yes' then 'GroupBuy' else c.name end as source
,count(*) as cnt
from temp t
left join client c
on t.client_id = c.id
where cnt >= 2
group by case when is_group_buy = 'Yes' then 'GroupBuy' else c.name end
order by source;SQL283:实习广场投递简历分析(一)
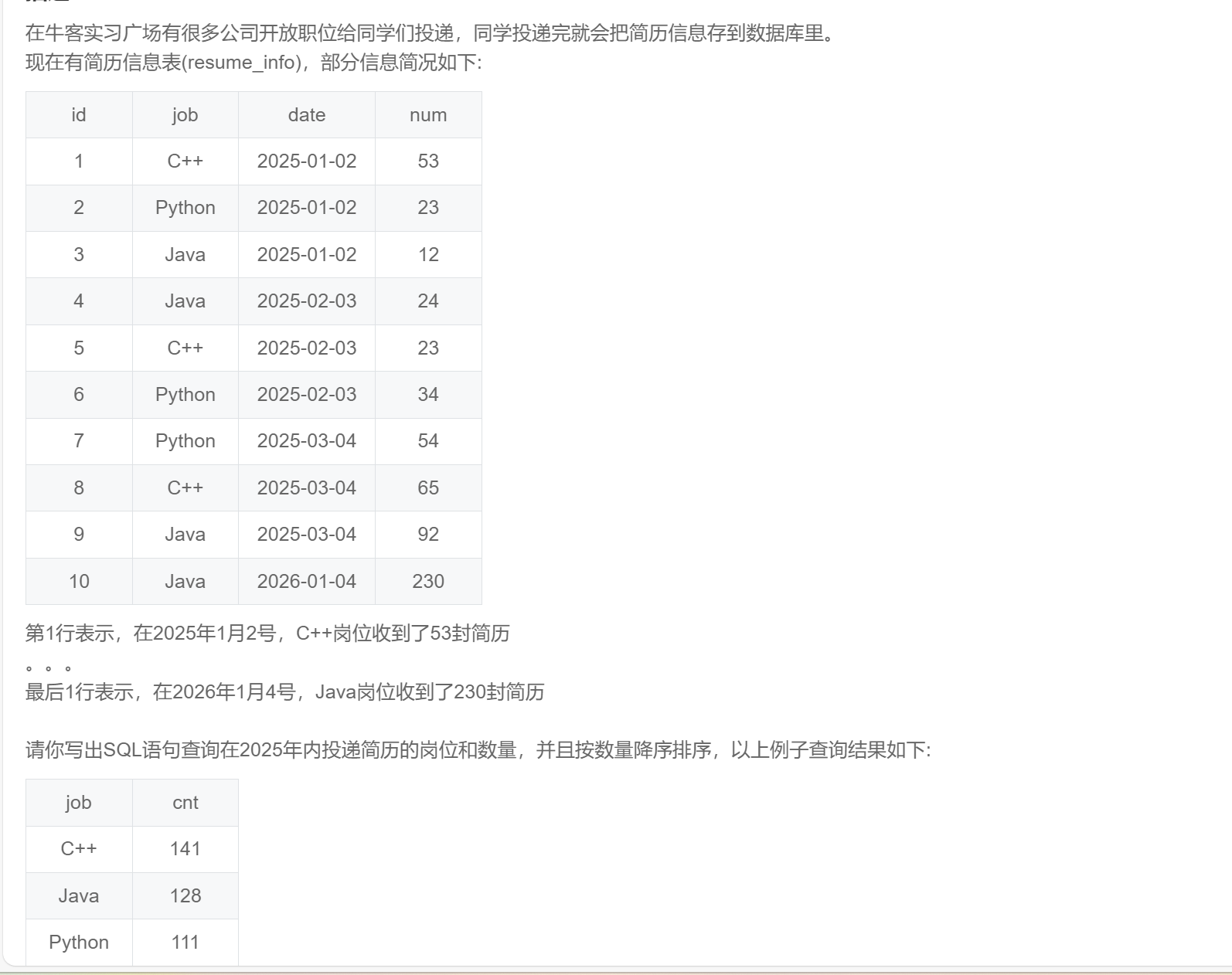
select job
,sum(num) as cnt
from resume_info
where year(date) = '2025'
group by job
order by cnt desc;SQL284:实习广场投递简历分析(二)
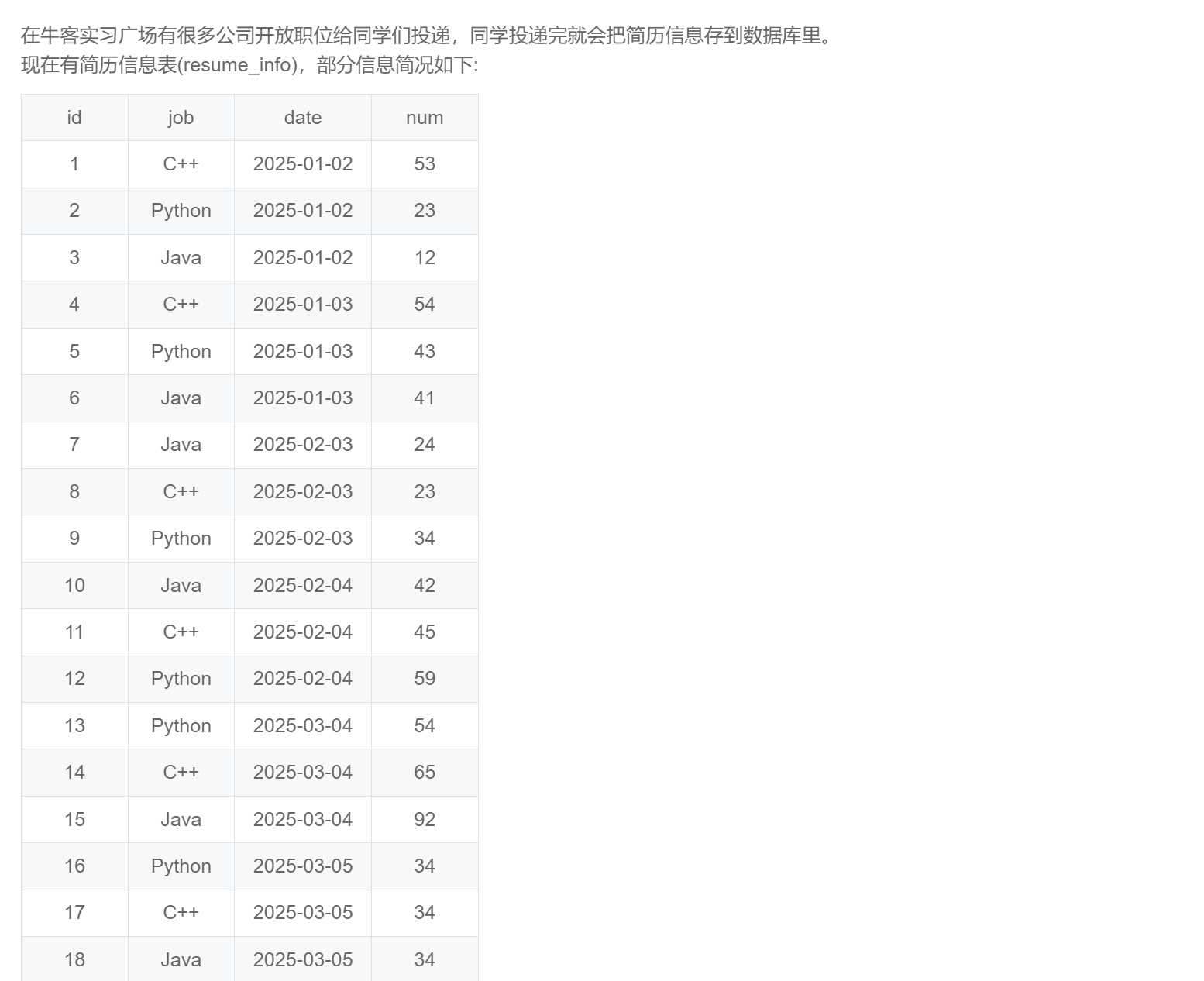
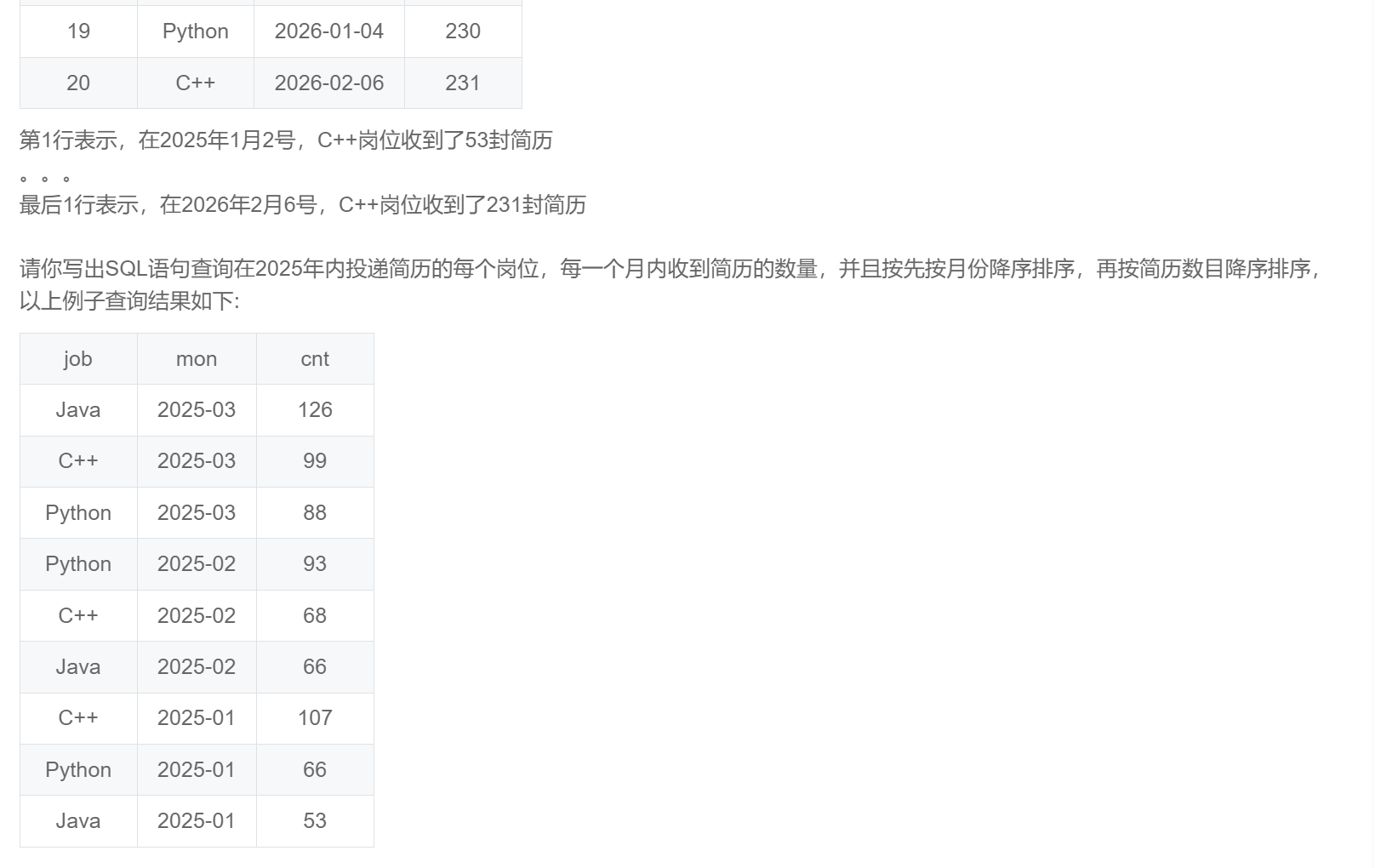
select job
,substr(date,1,7) as mon
,sum(num) as cnt
from resume_info
where year(date) = '2025'
group by job,substr(date,1,7)
order by mon desc,cnt desc;SQL285:实习广场投递简历分析(三)
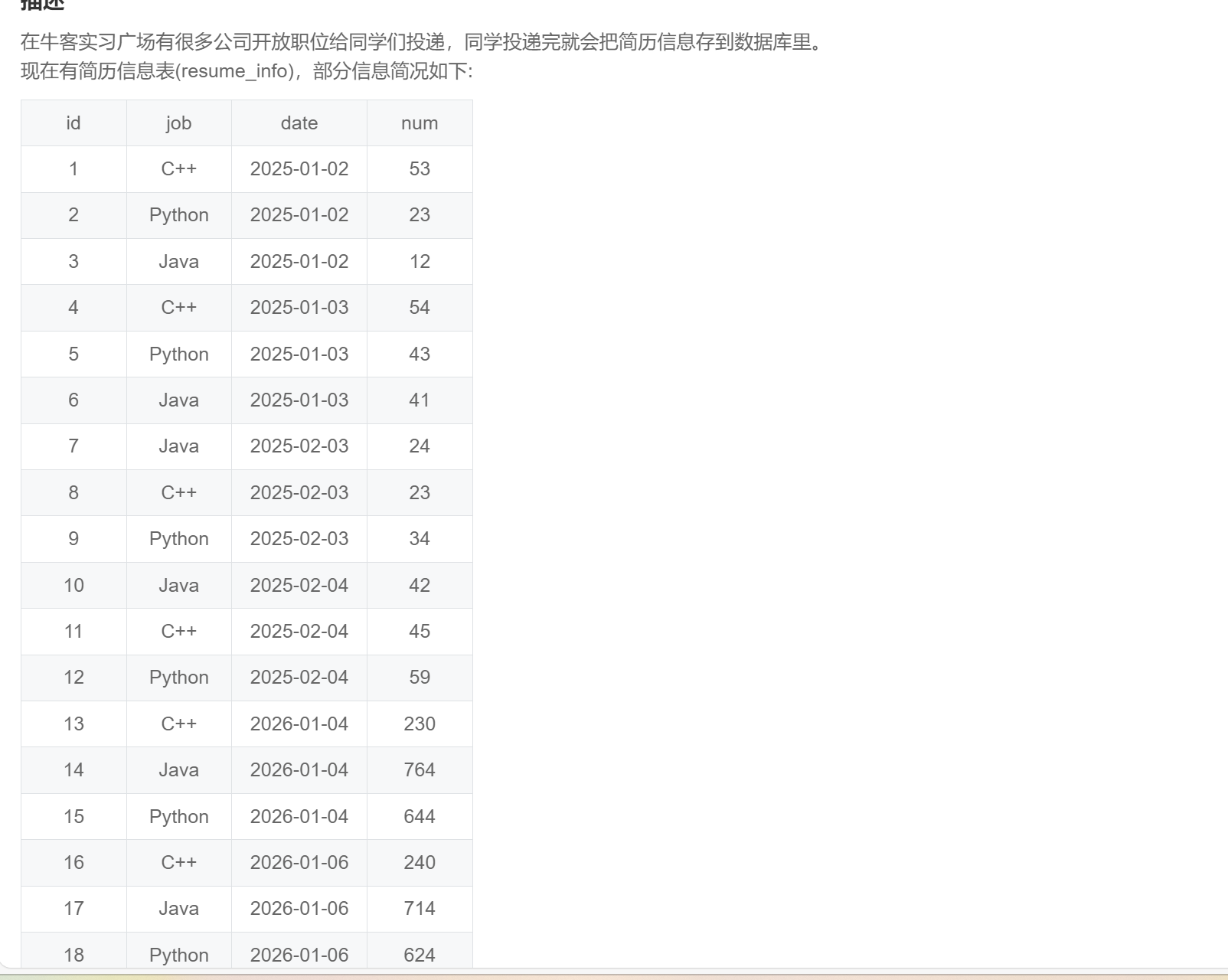
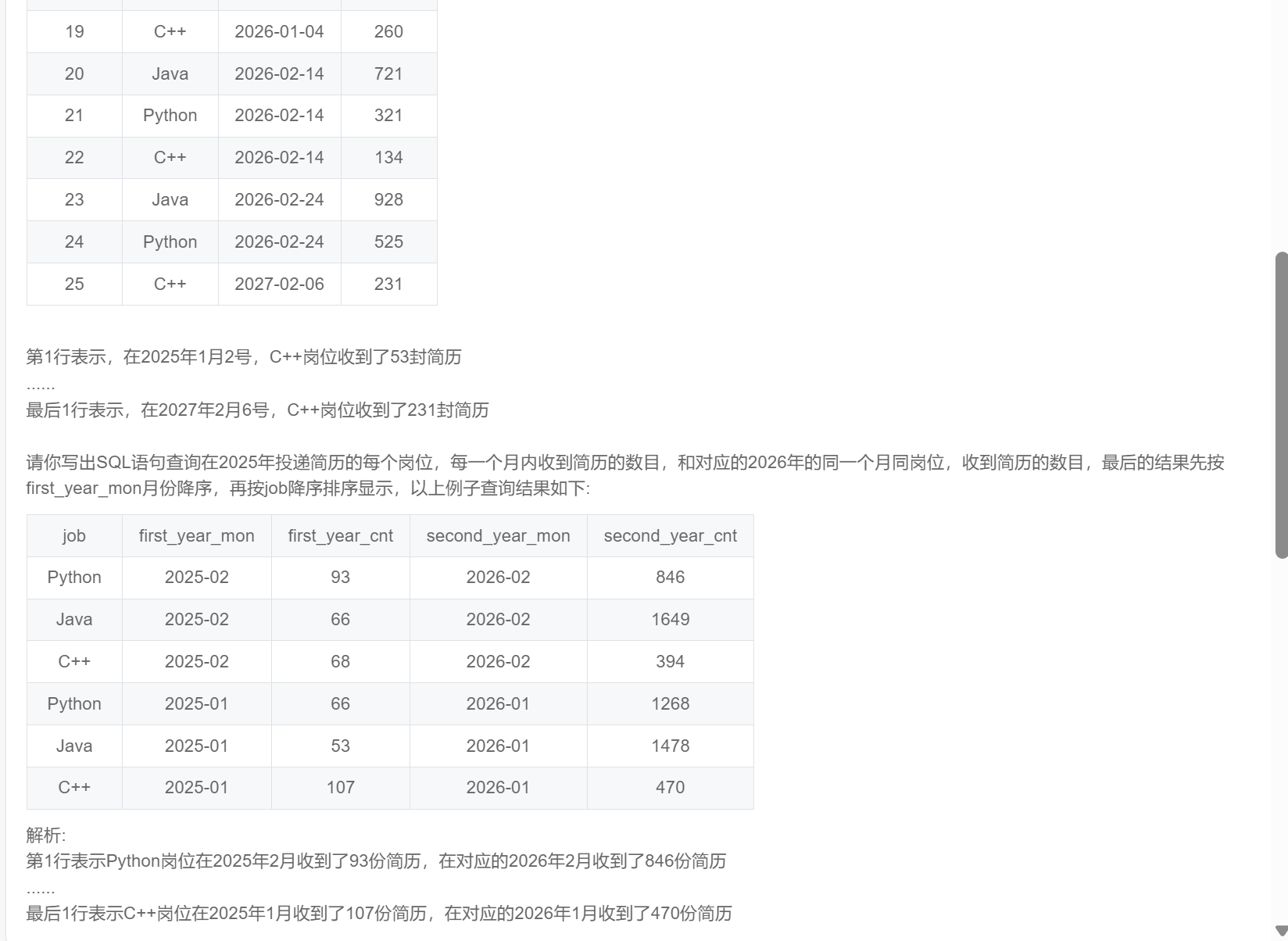
-- 暂时想到这种连接的方法,后续有新方法会更新
select r1.job
,first_year_mon
,first_year_cnt
,second_year_mon
,second_year_cnt
from (
select job
,substr(date,1,7) as first_year_mon
,sum(num) as first_year_cnt
from resume_info
where year(date) = '2025'
group by job,substr(date,1,7)
) r1
inner join
(
select job
,substr(date,1,7) as second_year_mon
,sum(num) as second_year_cnt
from resume_info
where year(date) = '2026'
group by job,substr(date,1,7)
) r2
on r1.job = r2.job
and substr(first_year_mon,6,2) = substr(second_year_mon,6,2) -- 连接相同job相同月份
order by first_year_mon desc,job desc;SQL286:最差是第几名(一)

select grade
,sum(number) over(order by grade) as t_rank
from class_grade;SQL287:最差是第几名(二)

select grade
from (
select grade
,sum(number) over(order by grade asc) as ascnum
,sum(number) over(order by grade desc) as descnum
,(select sum(number) from class_grade) as total
from class_grade
) c
where ascnum >= total/2 and descnum >= total/2
order by grade asc;SQL288:获得积分最多的人(一)
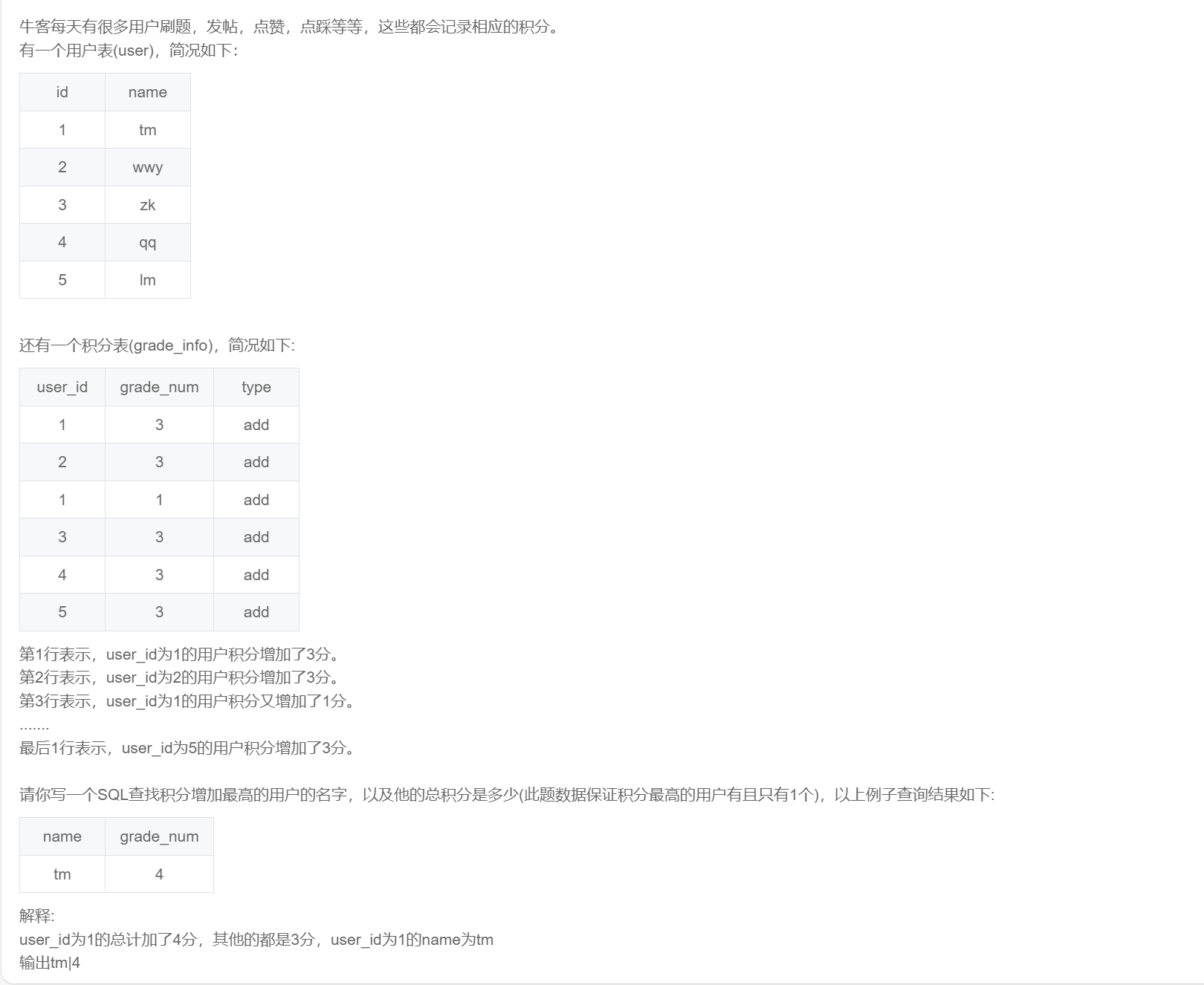
-- 方法一:limit 仅适用于只有一个最高数据
select u.name
,sum(grade_num) over(partition by g.user_id) as grade_num
from grade_info g
inner join user u
on u.id = g.user_id
order by grade_num desc
limit 1;
-- 方法二:窗口函数适用于多个最高数据
select u.name
,g.grade_num
from (
select user_id
,sum(grade_num) as grade_num
,rank() over(order by sum(grade_num) desc) as rk
from grade_info
group by user_id
) g
inner join user u
on u.id = g.user_id
where rk = 1;SQL289:获得积分最多的人(二)

select u.id
,u.name
,g.grade_num
from (
select user_id
,sum(grade_num) as grade_num
,rank() over(order by sum(grade_num) desc) as rk
from grade_info
group by user_id
) g
inner join user u
on u.id = g.user_id
where rk = 1
order by u.id;SQL290:获得积分最多的人(三)
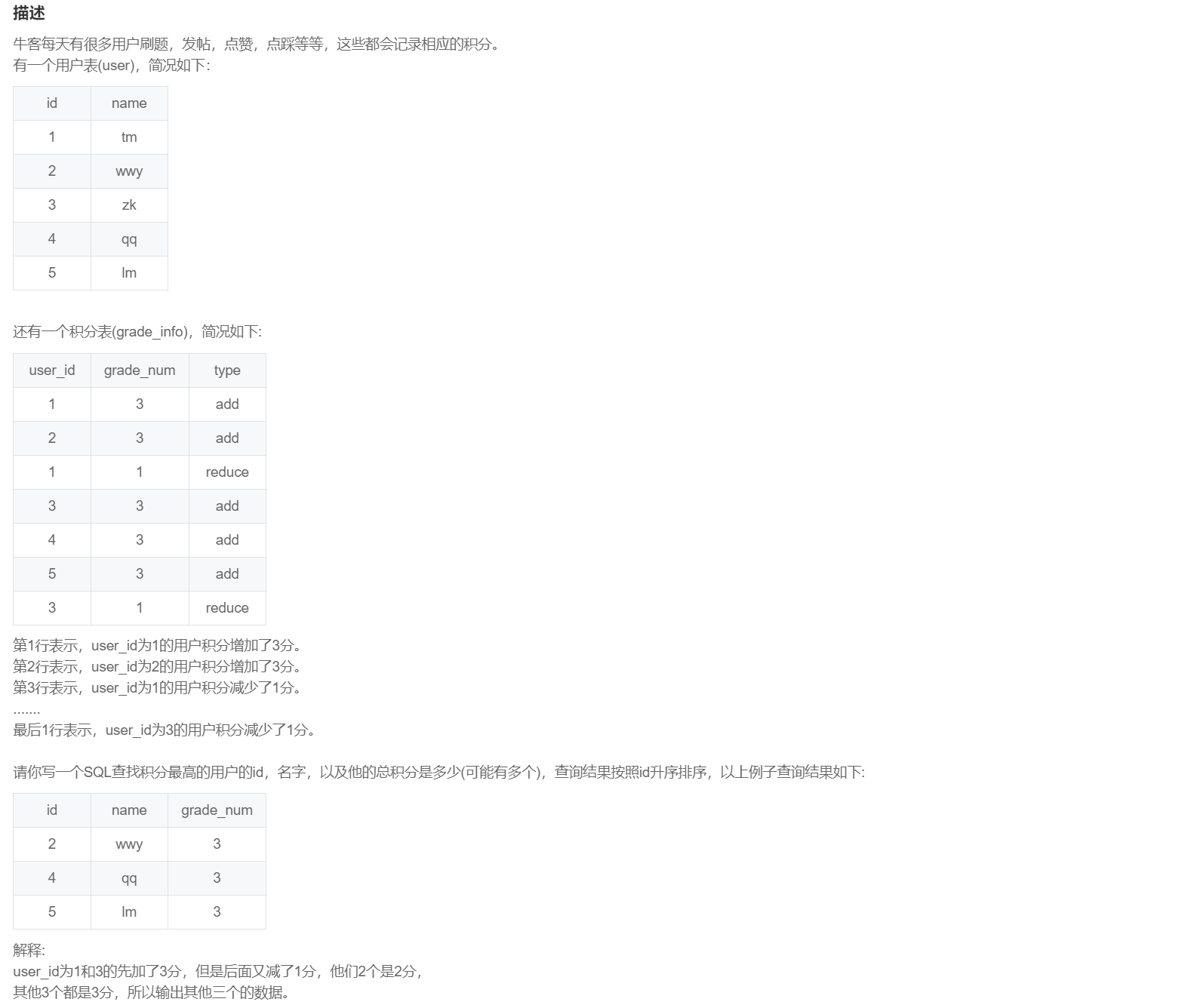
select u.id
,u.name
,g.grade_num
from (
select user_id
-- 根据类型判断一下积分正负再求和即可
,sum(case when type = 'add' then grade_num else -grade_num end) as grade_num
,rank() over(order by sum(case when type = 'add' then grade_num else -grade_num end) desc) as rk
from grade_info
group by user_id
) g
inner join user u
on u.id = g.user_id
where rk = 1
order by u.id;SQL291:商品交易(网易校招笔试真题)

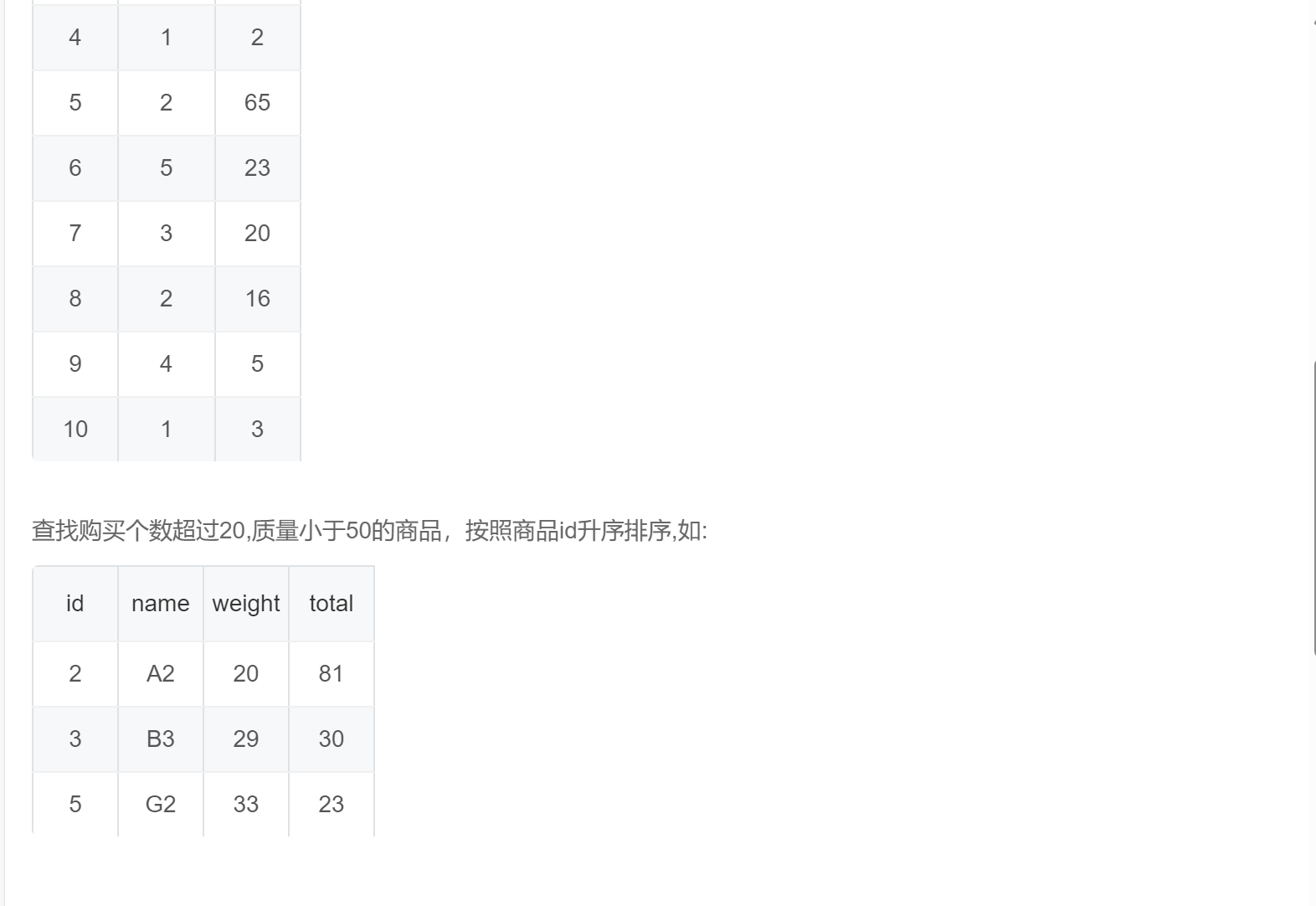
select g.id
,name
,weight
,sum(count) as total
from goods g
inner join trans t
on g.id = t.goods_id
group by g.id,name,weight
having total > 20 and weight < 50
order by g.id;SQL292:网易云音乐推荐(网易校招笔试真题)

select music_name
from (
select distinct m.id
,music_name
from follow f
inner join music_likes m_l -- 与此表关联后 music_id 会有重复,所以要先去重
on f.follower_id = m_l.user_id
inner join music m
on m_l.music_id = m.id
where f.user_id = 1
and music_id not in (select music_id from music_likes where user_id = 1)
) a
order by id;SQL293:今天的刷题量(一)

select name
,count(*) as cnt
from submission s1
inner join subject s2
on s1.subject_id = s2.id
where s1.create_time = curdate() -- 获取系统当前日期
group by name,subject_id
order by cnt desc,subject_id;

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









