







目录
1.2.1 站内搜索(垂直搜索):数据量小,简单搜索,可以使用数据库。
1.2.2 互联网搜索,肯定不会使用数据库搜索。数据量太大。PB级。
1. ES搜索引擎: 大数据的搜索。 【1】导入到ES中 【2】搜索
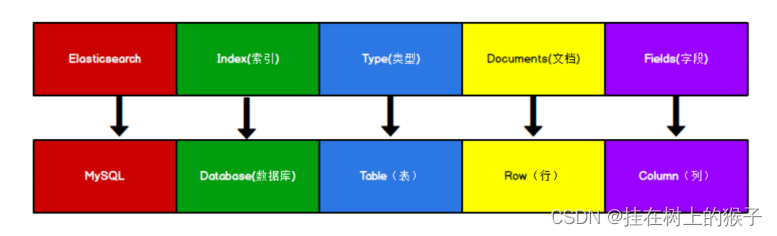
2. ES常见的概念: 索引 类型【7.0删除】 文档 字段
3. ES提供了很多RestFul风格的接口。
所谓restFul风格就是针对不同的操作具有不同的请求方式。比如:添加POST,修改PUT,查询GET,删除Delete。而且传递参数都在地址栏传递。
4. 对索引的操作.创建 删除 查询所有索引
5. 对文档的操作 crud
1. Elasticsearch概述
1.1 搜索是什么
1 互联网搜索:谷歌、百度、各种新闻首页2 站内搜索(垂直搜索):企业 OA 查询订单、人员、部门,电商网站内 部搜索商品(淘宝、京东)场景。
1.2 数据库做搜索弊端
1.2.1 站内搜索(垂直搜索):数据量小,简单搜索,可以使用数据库。
存储问题。电商网站商品上亿条时,涉及到单表数据过大必须拆分表,数据库磁盘占用过大必须分库( mycat )。性能问题:解决上面问题后,查询 “ 笔记本电脑 ” 等关键词时,上亿条数据的商品名字段逐行扫描,性能跟不上。不能分词。如搜索 “ 笔记本电脑 ” ,只能搜索完全和关键词一样的数据,那么数据量小时,搜索 “ 笔记电脑 ” , “ 电脑 ” 数据要不要给用户。
1.2.2 互联网搜索,肯定不会使用数据库搜索。数据量太大。PB级。
搜索也是一款数据库,搜索可以进行分词搜索 --- 搜索速度非常快
1.3 常见的搜索引擎
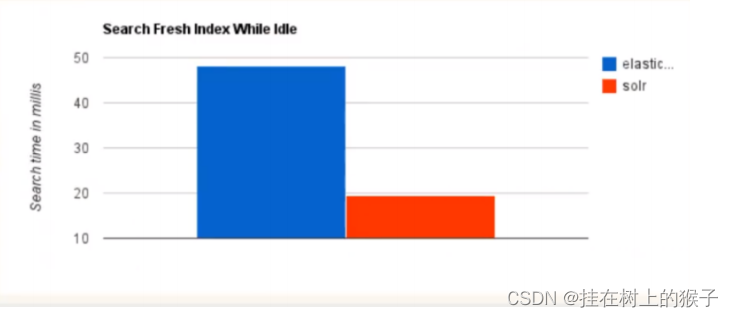 2. 当实时建立索引时,Solr会产生io阻塞,查询性能较差, ElasticSearch具有明显的优势
2. 当实时建立索引时,Solr会产生io阻塞,查询性能较差, ElasticSearch具有明显的优势
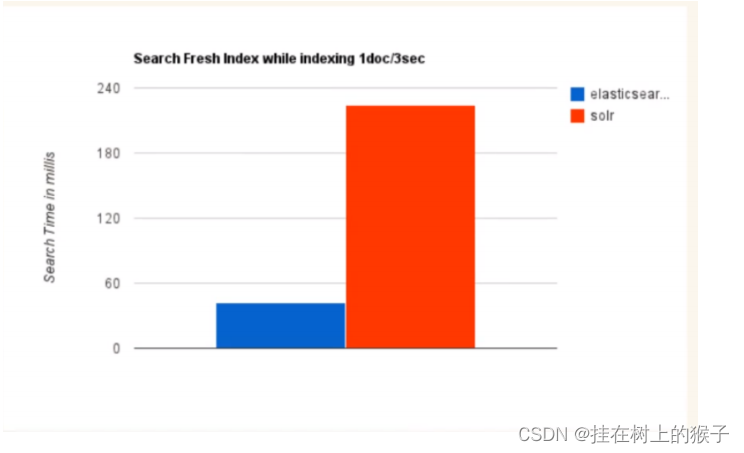
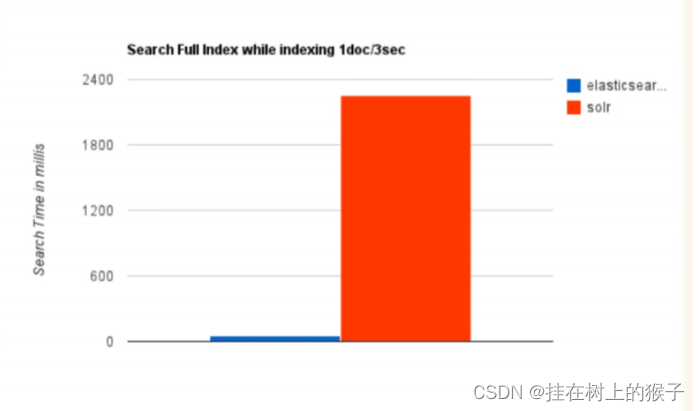
总结
1 、 es 基本是开箱即用 ( 解压就可以用 !) , 非常简单。 Solr 安装略微复杂一丢丢!2 、 Solr 利用 Zookeeper 进行分布式管理 , 而 Elasticsearch<mark>自身带有分布式协调管理功能 </mark> 。3 、 Solr 支持更多格式的数据 , 比如 JSON, XML, CSV , 而 Elasticsearch仅支持 json 文件格式。4 、 Solr 官方提供的功能更多 , 而 Elasticsearch 本身更注重于核心功能,高级功能多有第三方插件提供,例如图形化界面需要kibana 友好支撑5.Solr 查询快 , 但更新索引时慢 ( 即插入删除慢 ) ,用于电商等查询多的应用;ES 建立索引快 ( 即查询慢 ) ,即实时性查询快,用于 facebook 新浪等 搜索。Solr 是传统搜索应用的有力解决方案,但 Elasticsearch 更适用于新兴的实时搜索应用。6 、 Solr 比较成熟,有一个更大,更成熟的用户、开发和贡献者社区,而Elasticsearch 相对开发维护者较少 , 更新太快 , 学习使用成本较高。
1.4 Elasticsearch 是什么
The Elastic Stack, 包括 Elasticsearch 【搜索,分析】、 Kibana 【可视化】、 Beats 和 Logstash 【数据的搜集】(也称为 ELK Stack )。能够安全可靠地获取任何来源、任何格式的数据,然后实时地对数据进行搜索、分析和可视化。
1.5 Elasticsearch的使用场景
国外:
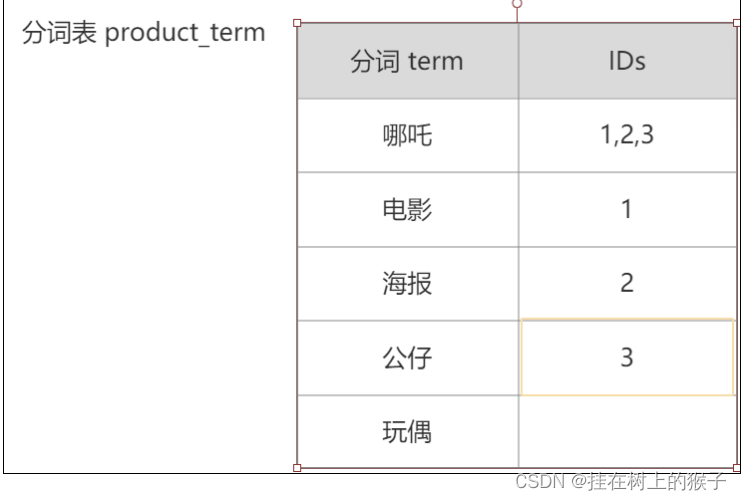
1.6 倒排索引
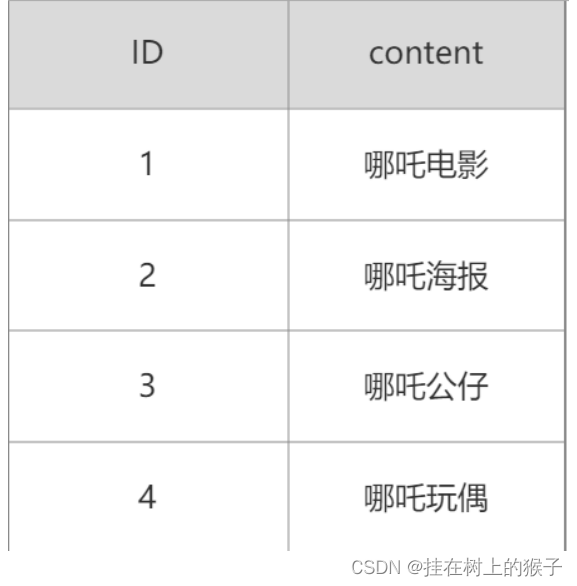
分词表
2. ES的安装
{
"name": "DESKTOP-D9UJ3OL",
"cluster_name": "elasticsearch",
"cluster_uuid": "pxOvyOI3SwO0WTvkGZbmaA",
"version": {
"number": "7.8.1",
"build_flavor": "default",
"build_type": "zip",
"build_hash": "b5ca9c58fb664ca8bf9e4057fc229b3396bf3a89",
"build_date": "2020-07-21T16:40:44.668009Z",
"build_snapshot": false,
"lucene_version": "8.5.1",
"minimum_wire_compatibility_version": "6.8.0",
"minimum_index_compatibility_version": "6.0.0-beta1"
},
"tagline": "You Know, for Search"
}
3. Windows安装Kibana
4. ES中常见的概念
5. ES常用API接口
5.1 基本操作
5.1.1 创建一个索引
PUT /索引名称/类型名称/1
{
数据
}
创建索引并往索引中添加一条文档
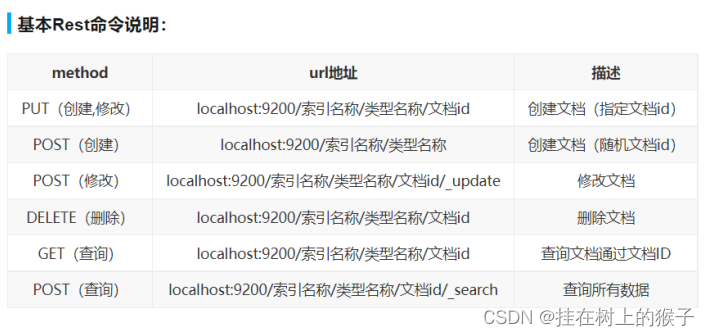
(1)创建索引并添加数据
PUT / test1 / type1 / 1{"name" : " 流柚 " ,"age" : 18}
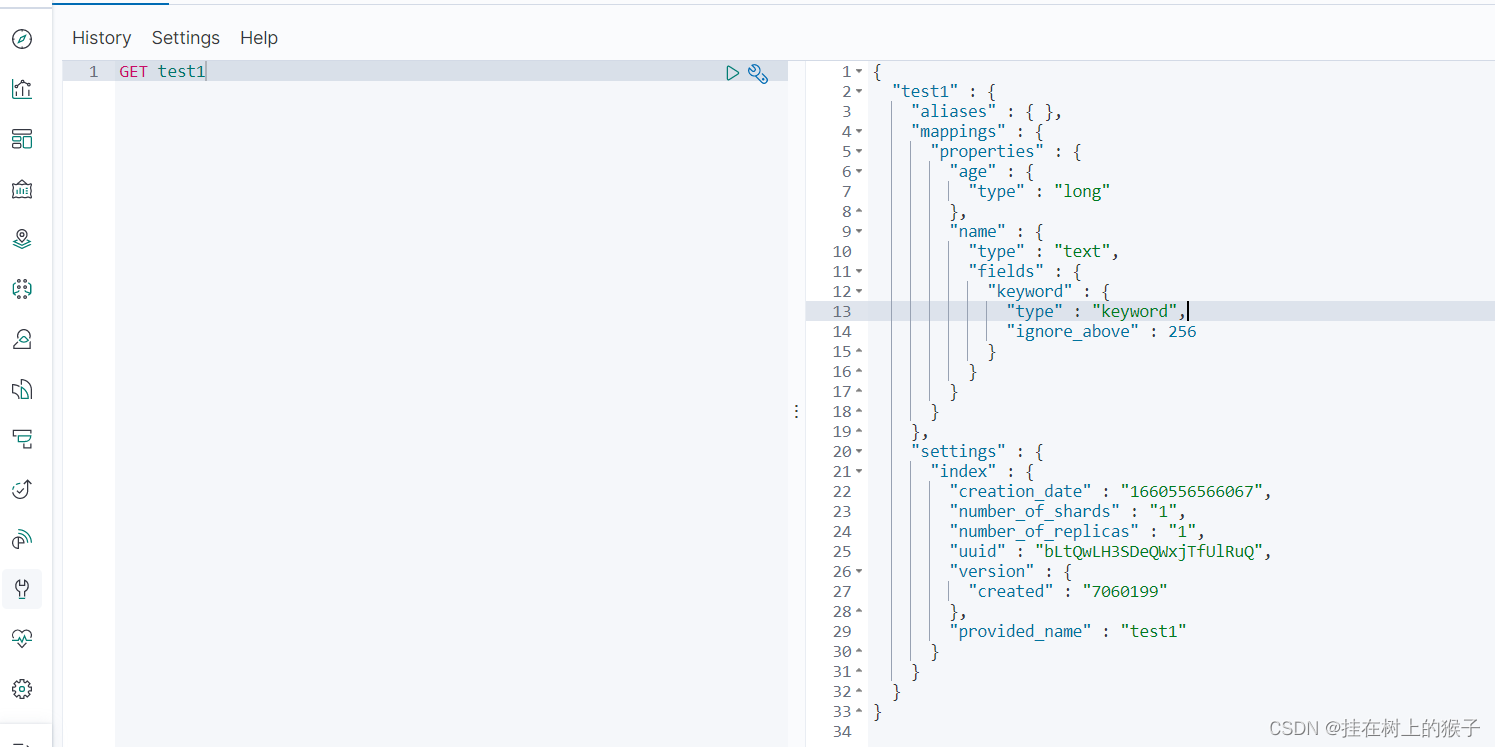
- 字符串类型
- text :支持分词,全文检索 , 支持模糊、精确查询 , 不支持聚合 , 排序操作;text 类型的最大支持的字符长度无限制 , 适合大字段存储;- keyword :不进行分词,直接索引、支持模糊、支持精确匹配,支持聚合、排序操作。keyword 类型的最大支持的长度为 ——32766 个 UTF-8类型的字符, 可以通过设置 ignore_above 指定自持字符长度,超过给定长度后的数据将不被索引,无法通过term 精确匹配检索返回结果。
-
数值型
- 日期类型
- te布尔类型
- 二进制类型
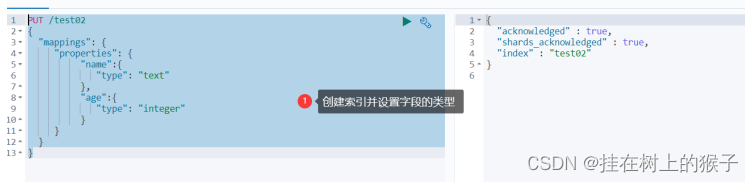
(2)指定字段的类型(使用PUT)创建索引---但是不添加数据。
类似于建库(建立索引和字段对应类型),也可看做规则的建立
PUT /test02
{
"mappings":{
"properties": {
"name":{
"type": "text"
},
"age":{
"type": "integer"
}
}
}
}
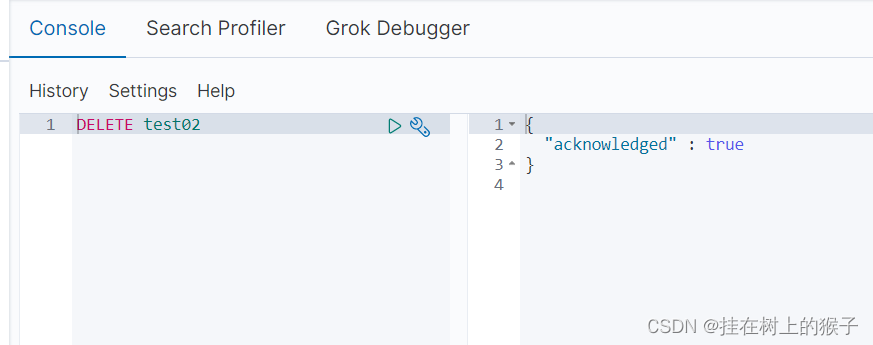
5.1.2 删除索引
DELETE /索引名
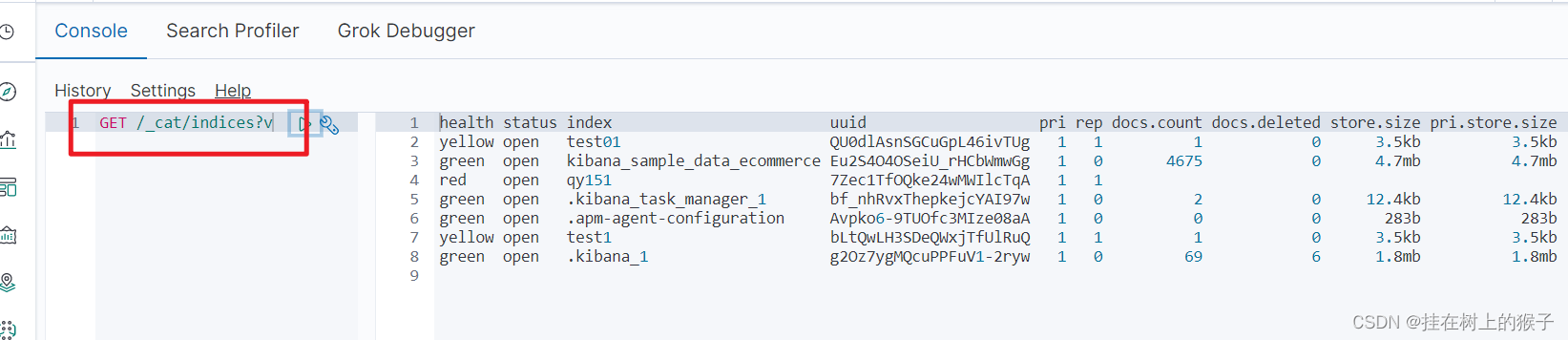
5.1.3 查询有哪些索引
GET /_cat/indices?vyellow单机模式
green集群模式
red单机也宕机了
5.1.4 查询索引的结构
(1) GET /索引名
(2) 获取默认类型
PUT /test03/_doc/1
{
"name": "流柚",
"age": 18,
"birth": "1999-01-10"
}
GET test03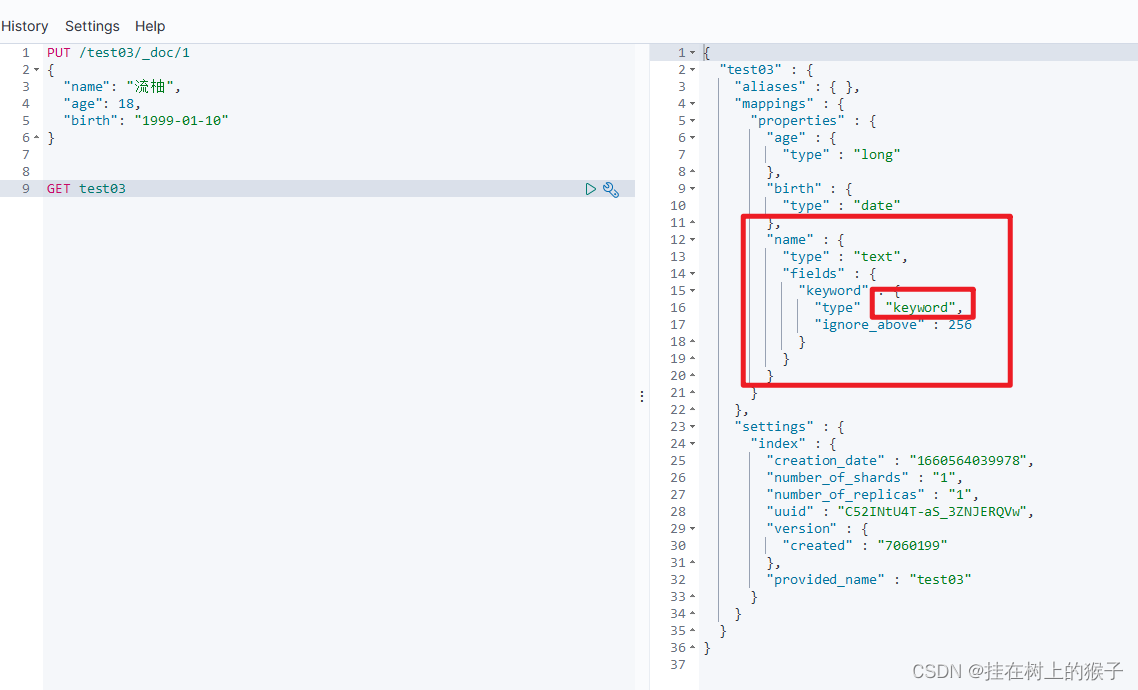
如果自己的文档字段没有被指定,那么ElasticSearch就会给我们默认配置字段类型
GET _cat/indicesGET _cat/aliasesGET _cat/allocationGET _cat/countGET _cat/fielddataGET _cat/healthGET _cat/indicesGET _cat/masterGET _cat/nodeattrsGET _cat/nodesGET _cat/pending_tasksGET _cat/pluginsGET _cat/recoveryGET _cat/repositoriesGET _cat/segmentsGET _cat/shardsGET _cat/snapshots 18 GET _cat/tasksGET _cat/templatesGET _cat/thread_pool
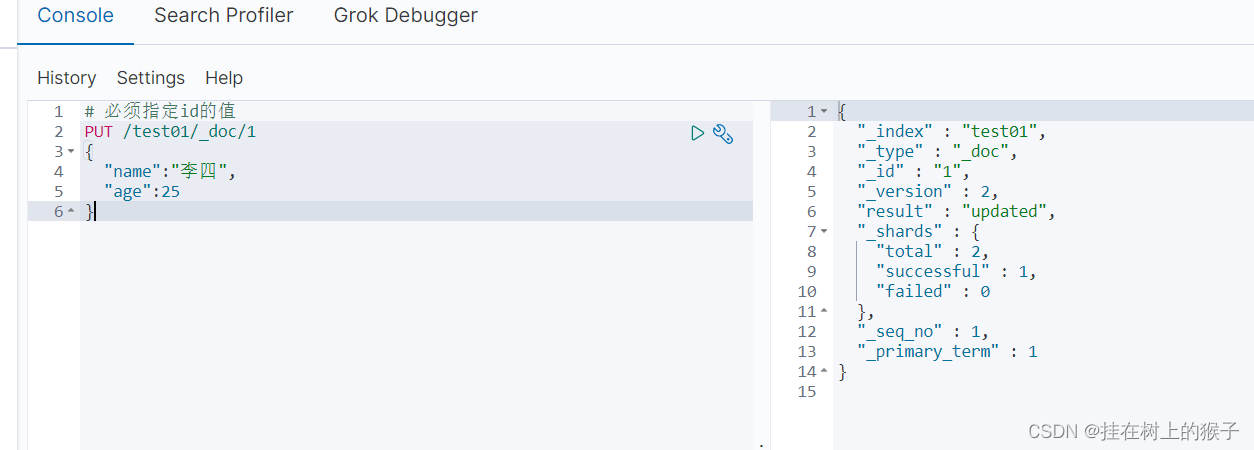
5.1.5 添加文档
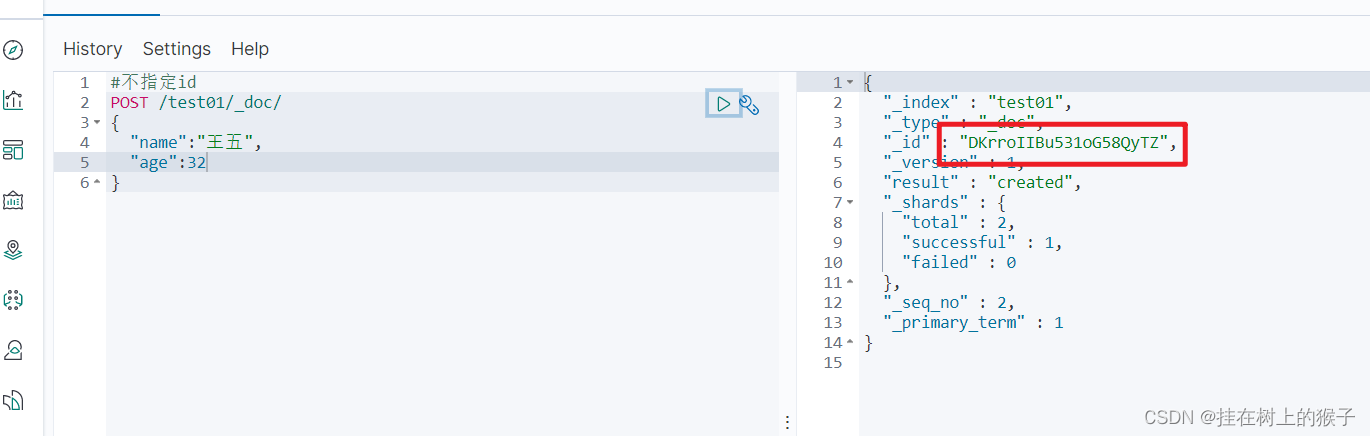
# 必须指定id的值
PUT /test01/_doc/1
{
"name":"李四",
"age":25
}
5.1.6 查询文档
查询的提交方式必须为GET
#GET /索引名称/类型名称/id值
GET /test01/_doc/1
5.1.7 删除文档
提交方式DELETE提交方式
根据不同的操作具有不同的提交方式restful风格
DELETE /test01/_doc/1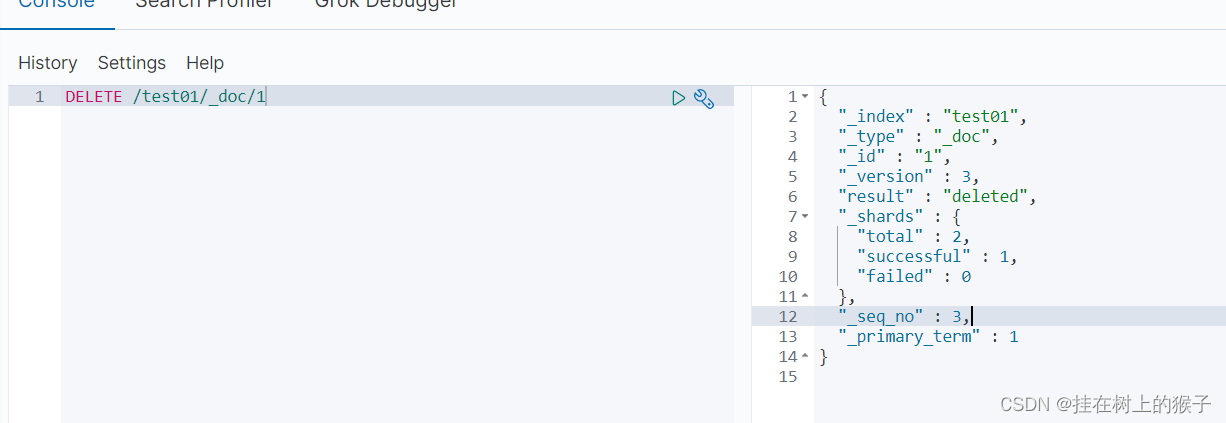
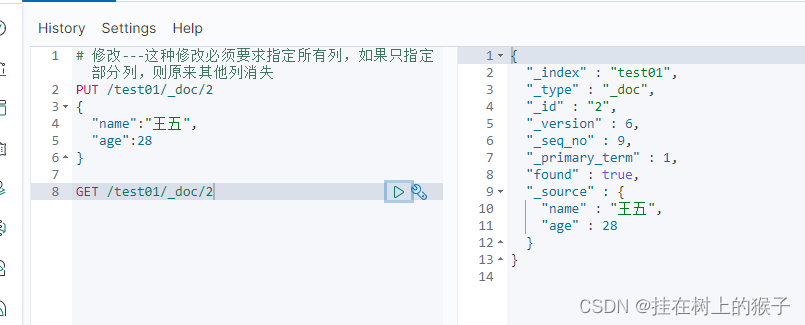
5.1.8 修改文档
# 修改---这种修改必须要求指定所有列,如果只指定部分列,则原来其他列消失
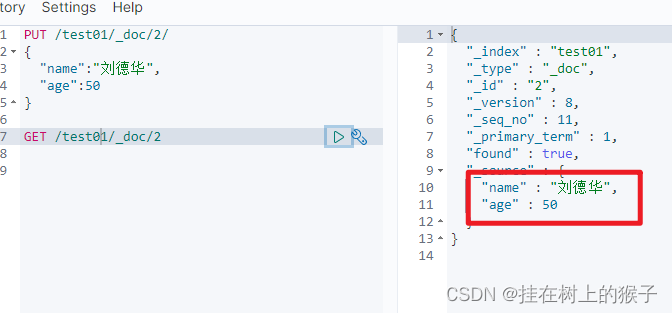
PUT /test01/_doc/2
{
"name":"王五",
"age":28
}
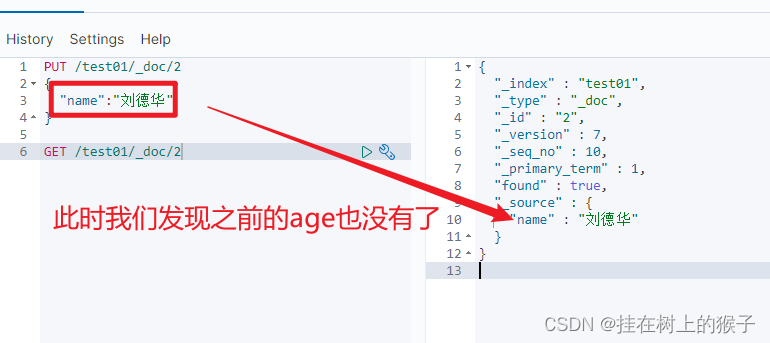
PUT /test01/_doc/2
{
"name":"刘德华"
}
# 只修改部分列
POST /test01/_doc/1/_update
{
"doc":{
"name":"刘德华",
"age":22
}
}
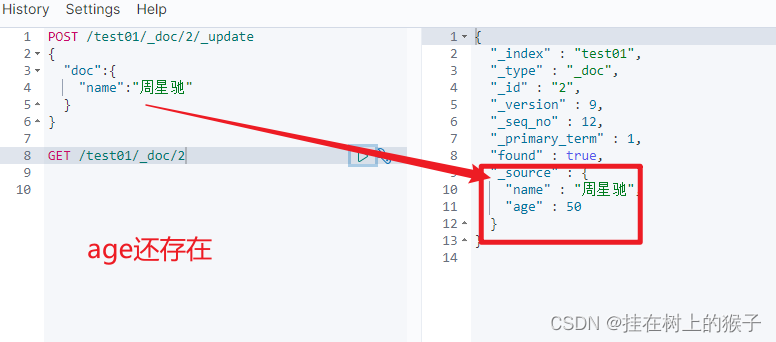
可以看到只修改了指定的列值,其他列依然存在
6. 根据其他条件查询
6.1 查询所有文档
类似于 select * from 表名
GET /test01/_search
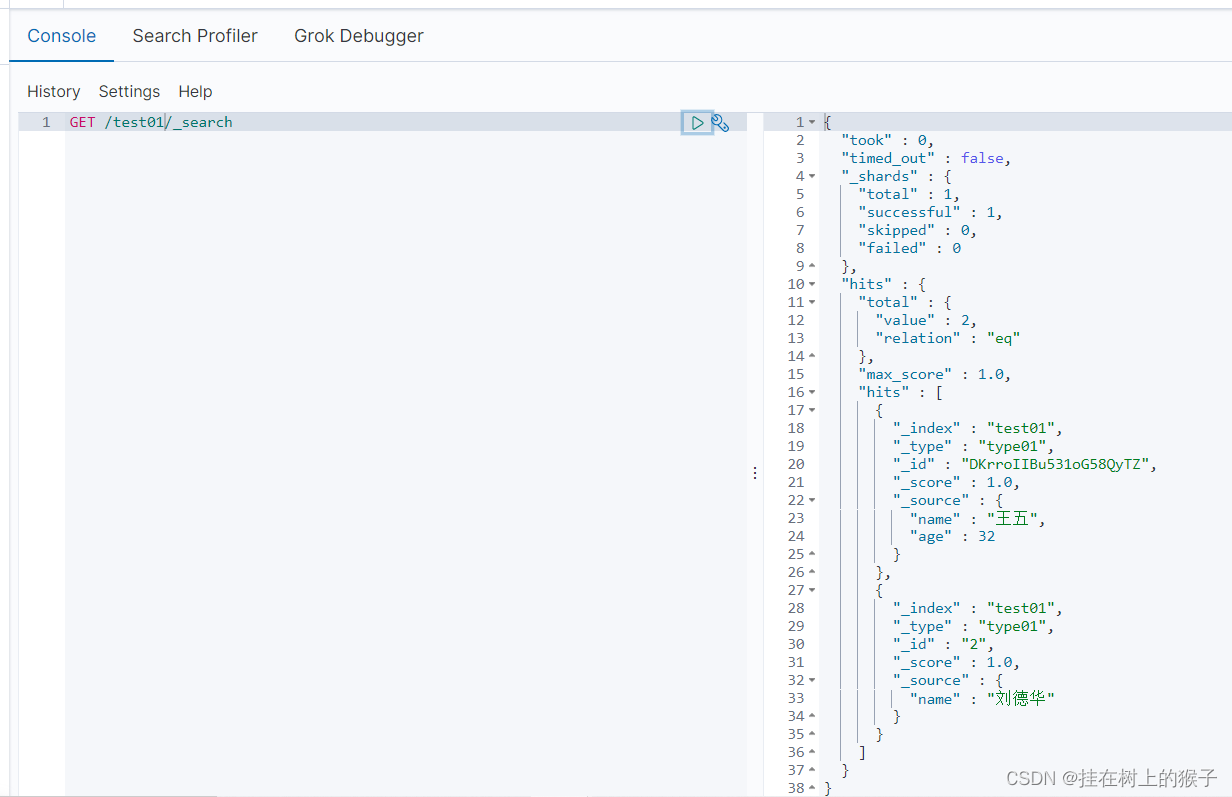
6.2 根据条件搜索(简单查询)
类似于 select * from 表名 where 列名=值
GET /索引名称/类型名称/_search?q=字段名:值
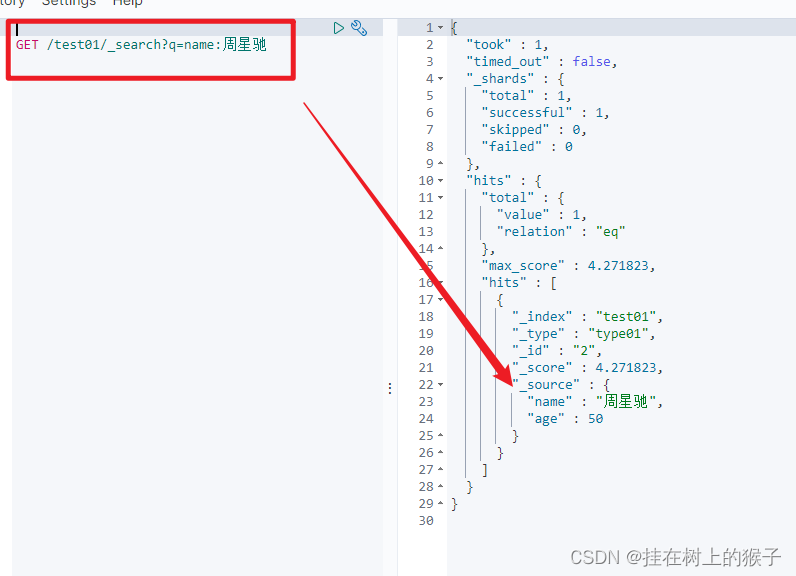
6.3 查询的条件封装成json数据(复杂查询)
PUT /user/_doc/1
{
"name":"张三",
"age":18,
"desc": ["有趣","幽默","开朗"]
}
PUT /user/_doc/2
{
"name":"李四",
"age":18,
"desc":["严谨","冷漠"]
}
PUT /user/_doc/3
{
"name":"王五",
"age":3,
"desc":["美丽","年轻","苗条"]
}类似于 select * from 表名 where 列名=值
(1)查询所有列
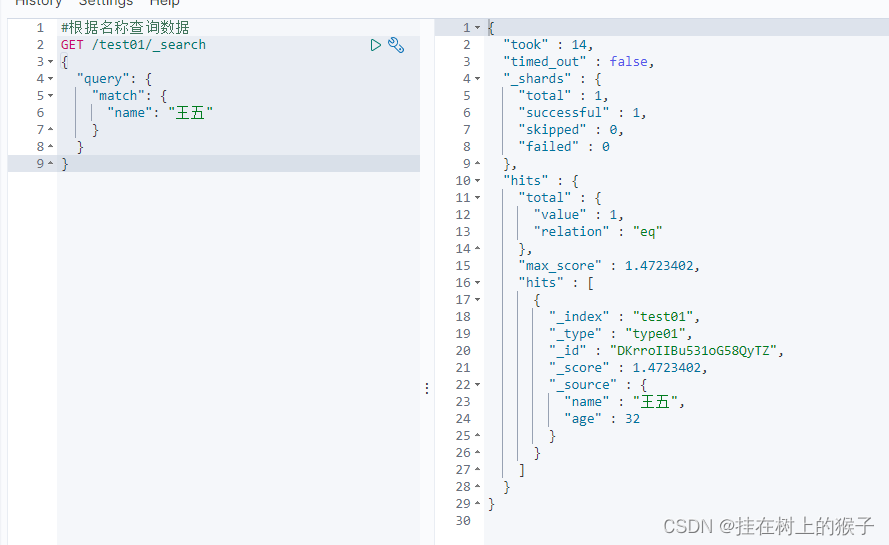
#根据名称查询数据
GET /test01/_search
{
"query": {
"match": {
"name": "王五"
}
}
}
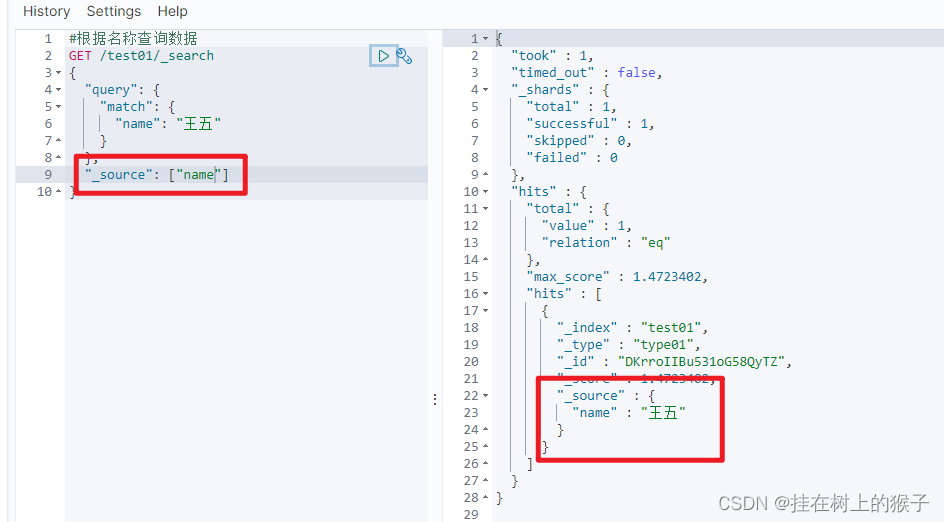
(2)查询部分列
select name from 表名 where 列名=值
#根据名称查询数据
GET /test01/_search
{
"query": {
"match": {
"name": "王五"
}
},
"_source": ["name"]
}
(3)分页查询
select * from 表名 where limit 0,5
select * from 表名 where limit 5,5
select * from 表名 where limit 10,
#根据名称查询数据
GET /test01/_search
{
"query": {
"match": {
"name": "王"
}
},
"_source": ["name"],
"from":0,
"size":2
}
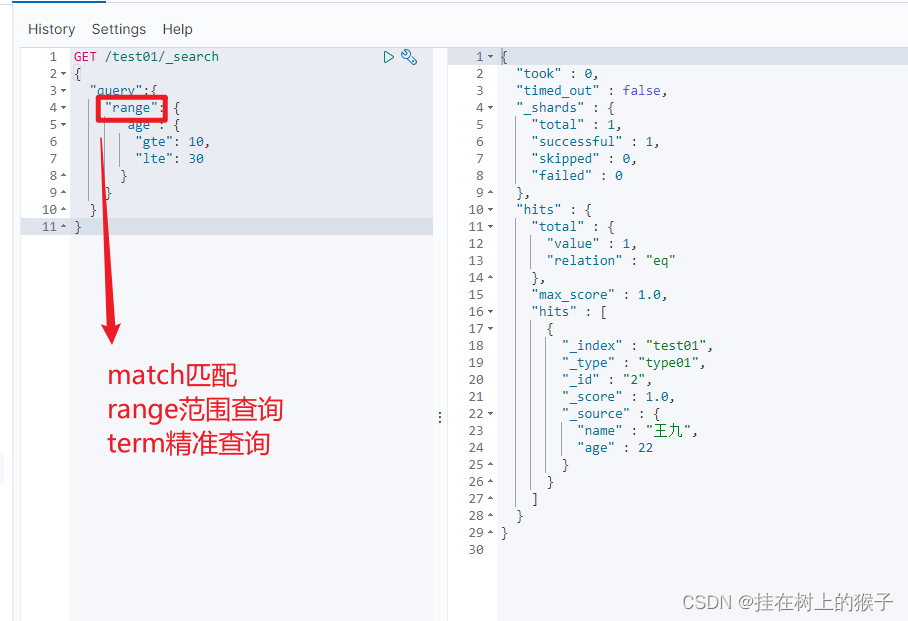
(4)范围查询
match匹配
range范围查询
term精准查询
GET /test01/_search
{
"query":{
"range": {
"age": {
"gte": 10,
"lte": 30
}
}
}
}
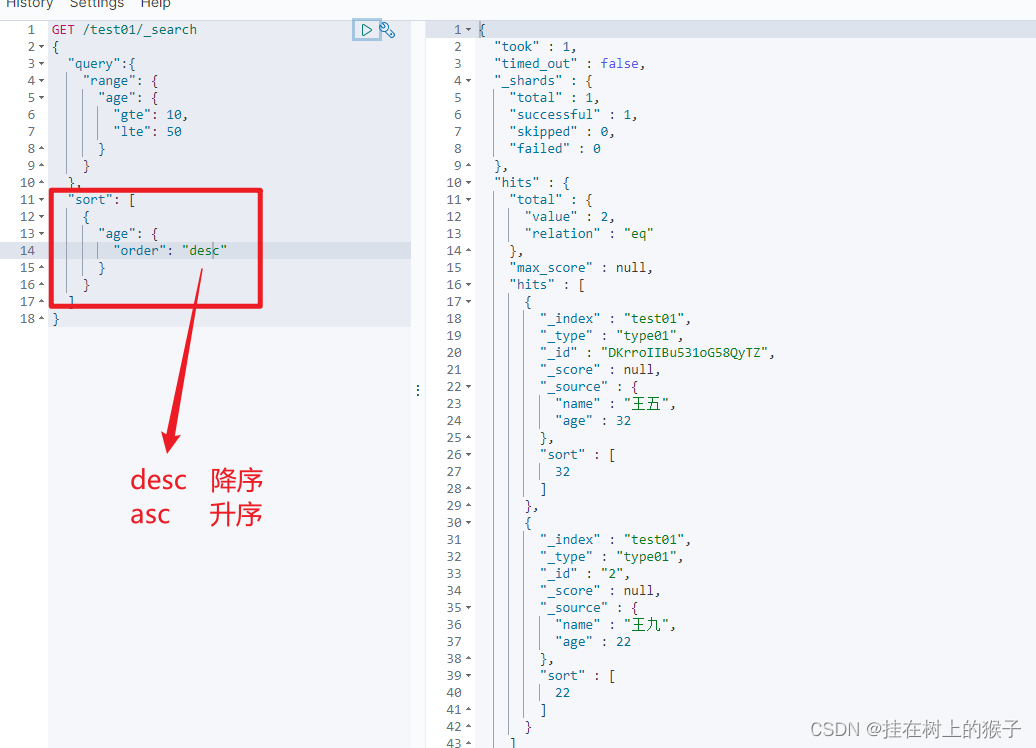
(5)排序
GET /test01/_search
{
"query":{
"range": {
"age": {
"gte": 10,
"lte": 50
}
}
},
"sort": [
{
"age": {
"order": "desc"
}
}
]
}
总结:
match:匹配(会使用分词器解析(先分析文档,然后进行查询))_source:过滤字段sort:排序from、size 分页
PUT /user/_doc/1
{
"name":"张三",
"age":18,
"desc": ["有趣","幽默","开朗"]
}
PUT /user/_doc/2
{
"name":"李四",
"age":18,
"desc":["严谨","冷漠"]
}
PUT /user/_doc/3
{
"name":"王五",
"age":3,
"desc":["美丽","年轻","苗条"]
}
POST /user/_doc/
{
"name":"张无忌",
"age": 22,
"desc":["武功盖世","天下无敌"]
}_doc都是可以省略的
GET /user/_search
{
"query": {
"match":{
"name":"张"
}
},
"_source": ["name","desc"],
"sort": [
{
"age": {
"order": "asc"
}
}
],
"from": 0,
"size": 1
}
POST /user/_doc/
{
"name":"张无忌",
"age": 22,
"desc":["武功盖世","天下无敌"]
}
GET /user/_doc/_search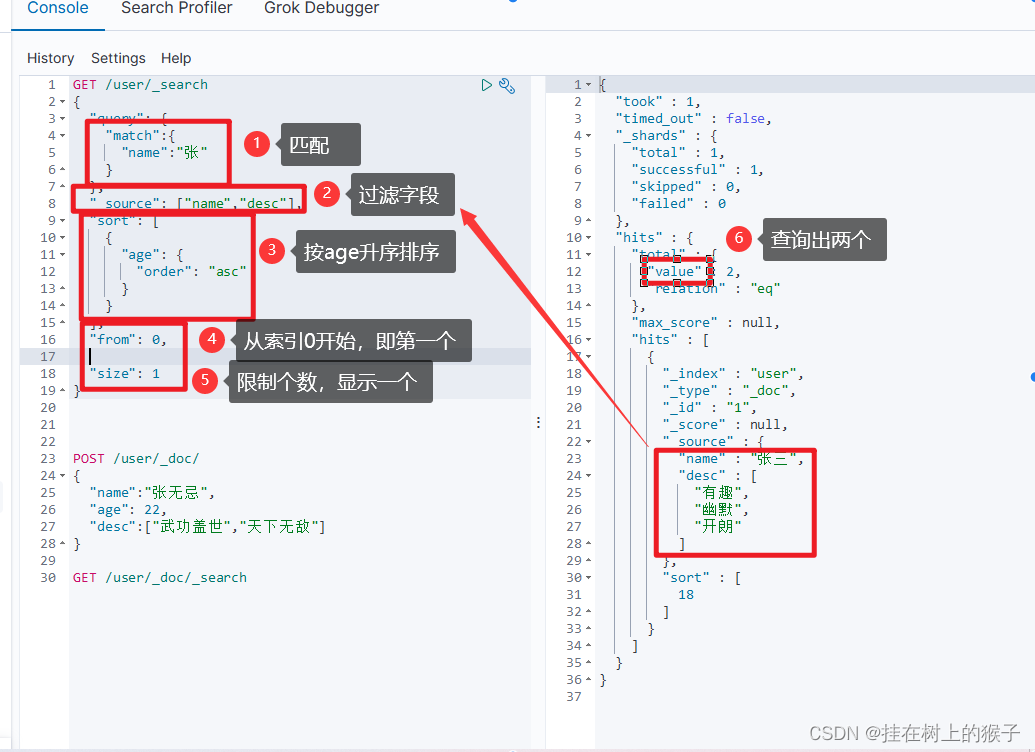
7. 多条件查询(bool)
-
must_not 相当于 not (... and ...)
- must 相当于 and
-
should 相当于 or
-
filter 过滤
select * from 表名 where 列=值 and 列=值.......
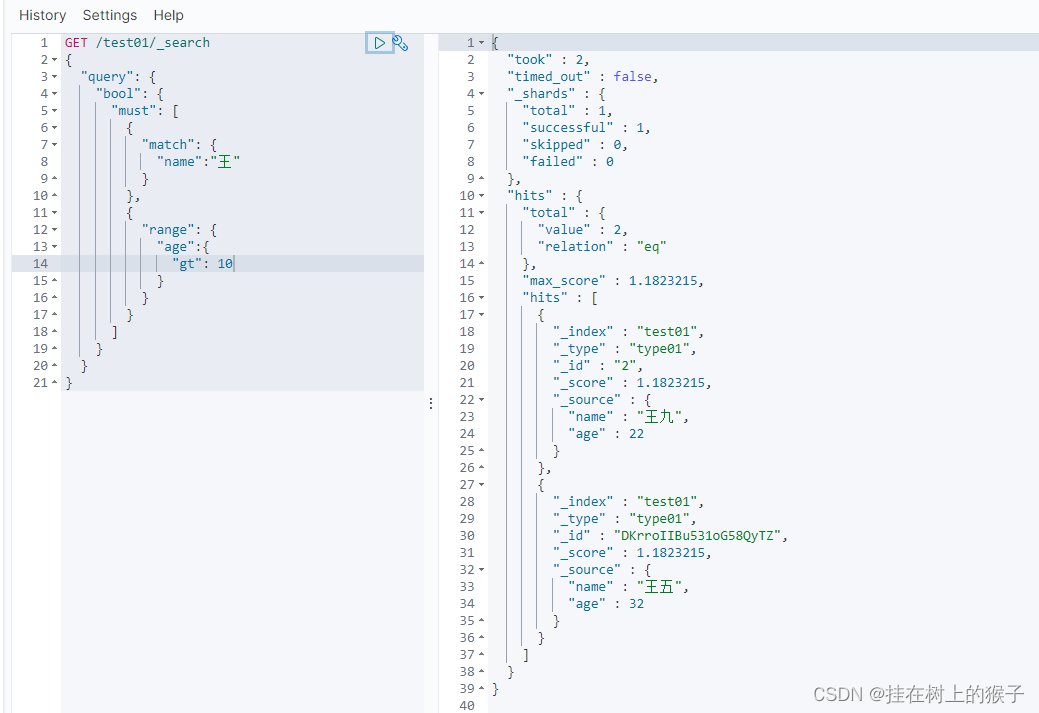
(1)must====等价于and
GET /test01/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name":"王"
}
},
{
"range": {
"age":{
"gt": 10
}
}
}
]
}
}
}
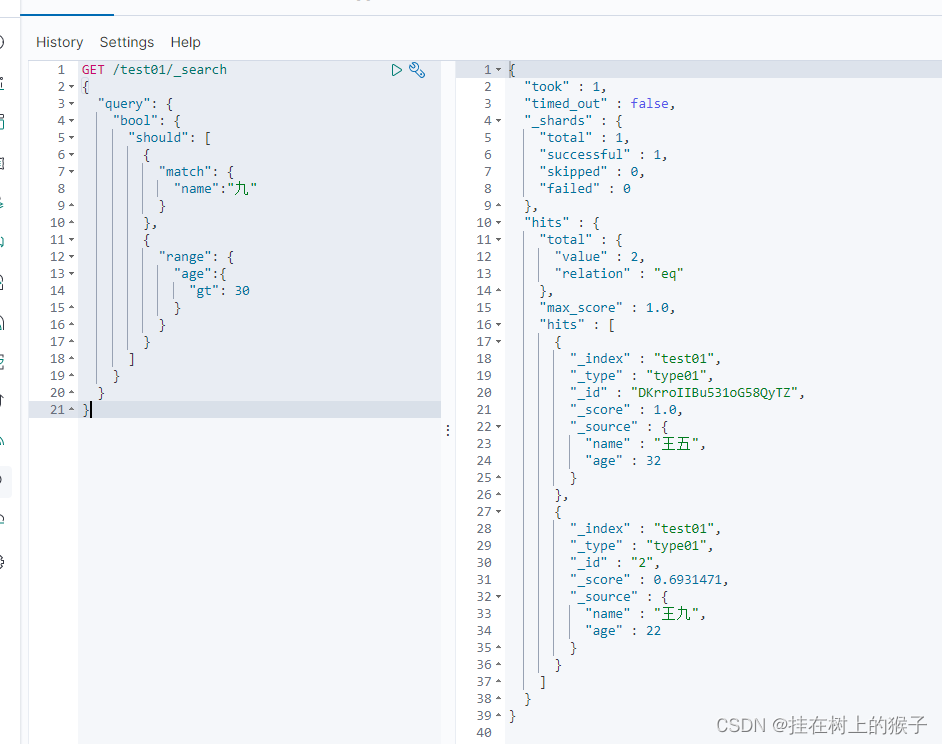
select * from 表名 where 列=值 or 列=值........
(2) should
GET /test01/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"name":"九"
}
},
{
"range": {
"age":{
"gt": 30
}
}
}
]
}
}
}
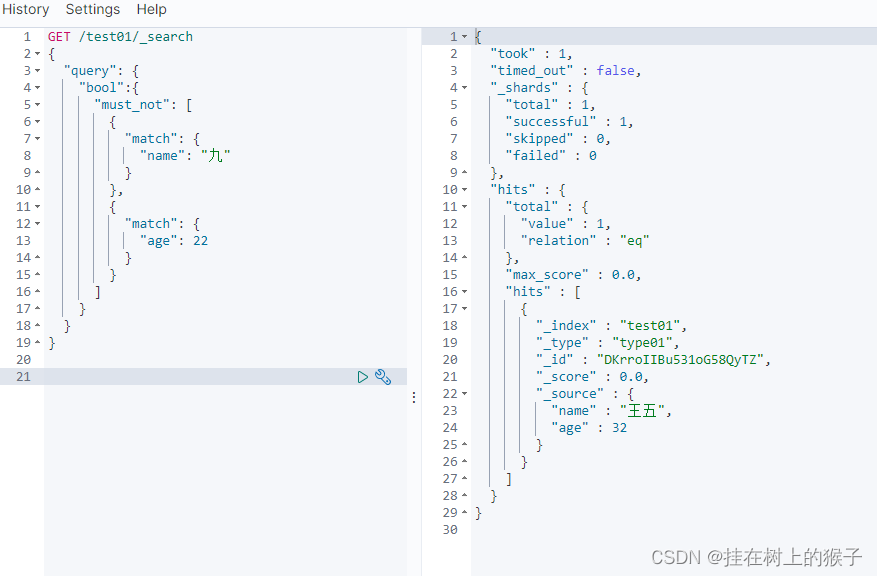
select * from 表名 where 列!=18
(3)must_not 等价于,and取反
GET /test01/_search
{
"query": {
"bool":{
"must_not": [
{
"match": {
"name": "九"
}
},
{
"match": {
"age": 22
}
}
]
}
}
}
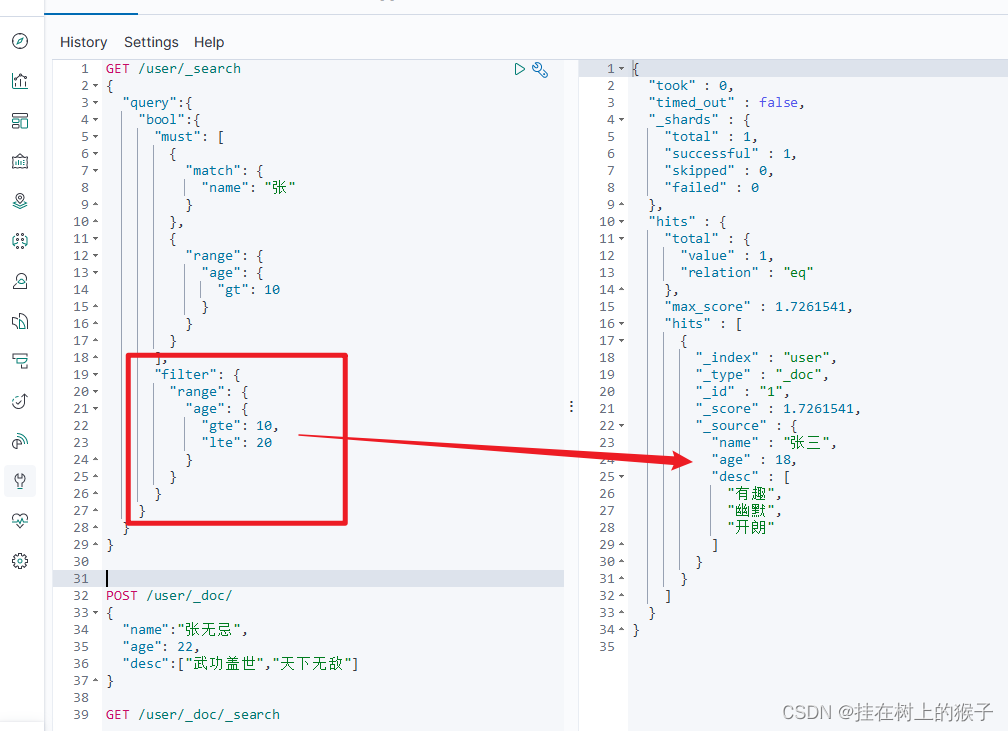
(4)filter过滤
GET /user/_search
{
"query":{
"bool":{
"must": [
{
"match": {
"name": "张"
}
},
{
"range": {
"age": {
"gt": 10
}
}
}
],
"filter": {
"range": {
"age": {
"gte": 10,
"lte": 20
}
}
}
}
}
}
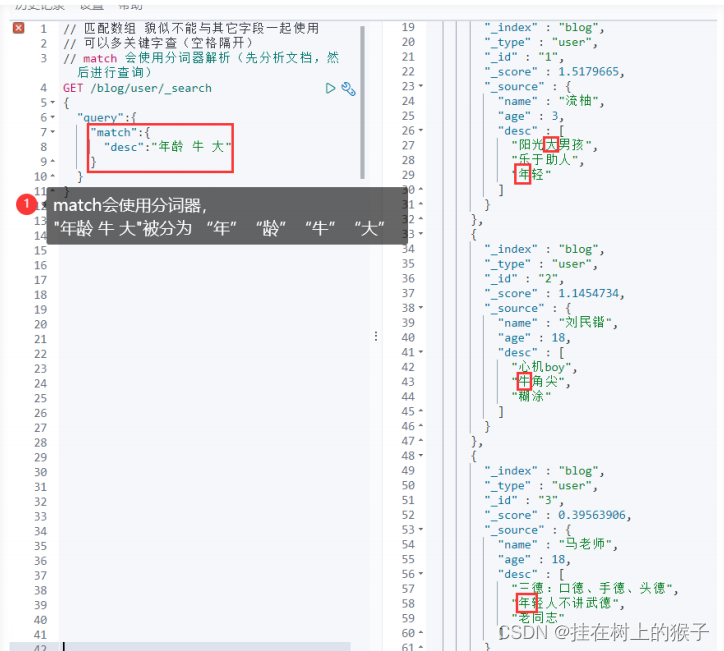
- 貌似不能与其它字段一起使用
// 匹配数组 貌似不能与其它字段一起使用
// 可以多关键字查(空格隔开)
// match 会使用分词器解析(先分析文档,然后进行查询)
GET /blog/user/_search
{
"query":{
"match":{
"desc":"年龄 牛 大"
}
}
}
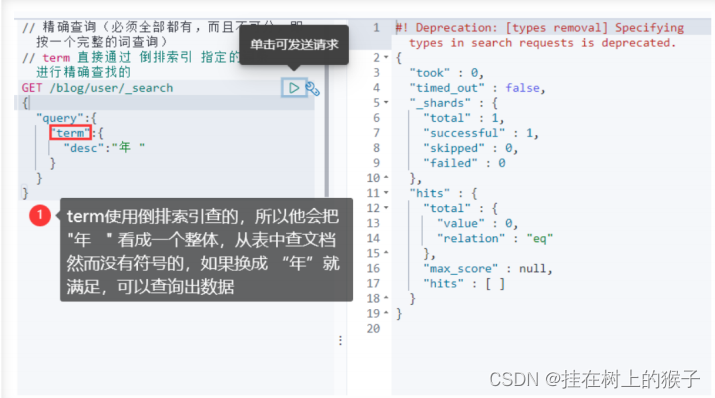
④精确查询
// 精确查询(必须全部都有,而且不可分,即按一个完整的词查询)
// term 直接通过 倒排索引 指定的词条 进行精确查找的
GET /blog/user/_search
{
"query":{
"term":{
"desc":"年 "
}
}
}
- text:
- 支持分词,全文检索、支持模糊、精确查询,不支持聚合,排序操作;
- text类型的最大支持的字符长度无限制,适合大字段存储;
- keyword:
- 不进行分词,直接索引、支持模糊、支持精确匹配,支持聚合、排序操作。
- keyword类型的最大支持的长度为——32766个UTF-8类型的字符, 可以通过设置ignore_above指定自持字符长度,超过给定长度后的
- 数据将不被索引,无法通过term精确匹配检索返回结果。
Text和Keyword类型的区别
text: 它会为该字段的内容进行拆词操作,并放入倒排索引表中
keyword: 它不会进行拆词操作
使用match匹配查询---对匹配的关键字进行拆词操作,并和倒排索引表中对应。
使用term精准匹配---它不会对关键字进行拆词操作,而且把关键字作为一个整体和倒排索引表进行匹配
#测试keyword和text是否支持分词
#设置索引类型
PUT /test
{
"mappings": {
"properties": {
"text":{
"type":"text"
},
"keyword":{
"type":"keyword"
}
}
}
}
#设置字段数据
PUT /test/_doc/1
{
"text":"测试text和keyword是否支持分词",
"keyword":"测试text和keyword是否支持分词"
}
#text支持分词
#keyword不支持分词
GET /test/_doc/_search
{
"query":{
"match":{
"text":"测试"
}
}
} #可以查到
GET /test/_doc/_search
{
"query":{
"match":{
"keyword":"测试"
}
}
} #查不到,必须是 "测试keyword和text是否支持分词" 才能查到
GET _analyze
{
"analyzer": "keyword",
"text": ["测试liu"]
} #不会分词,即测试liu
GET _analyze
{
"analyzer": "standard",
"text": ["测试liu"]
} #分为测 试 liu
⑥高亮查询
#高亮查询
GET /user/_search
{
"query":{
"match":{
"name":"张"
}
},
"highlight": {
"fields": {
"name":{}
}
}
}
#自定义前缀和后缀
#高亮查询
GET /user/_search
{
"query":{
"match":{
"name":"张"
}
},
"highlight": {
"pre_tags": "<p class='key' style='color:red'>",
"post_tags": "</p>",
"fields": {
"name":{}
}
}
} 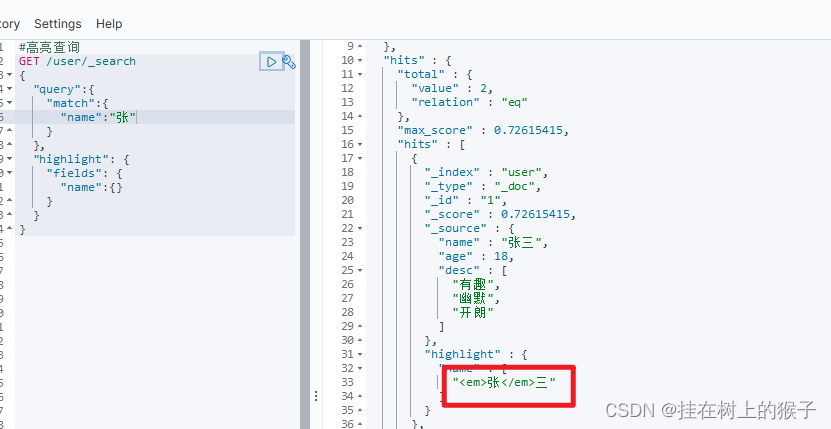
自定义前缀和后缀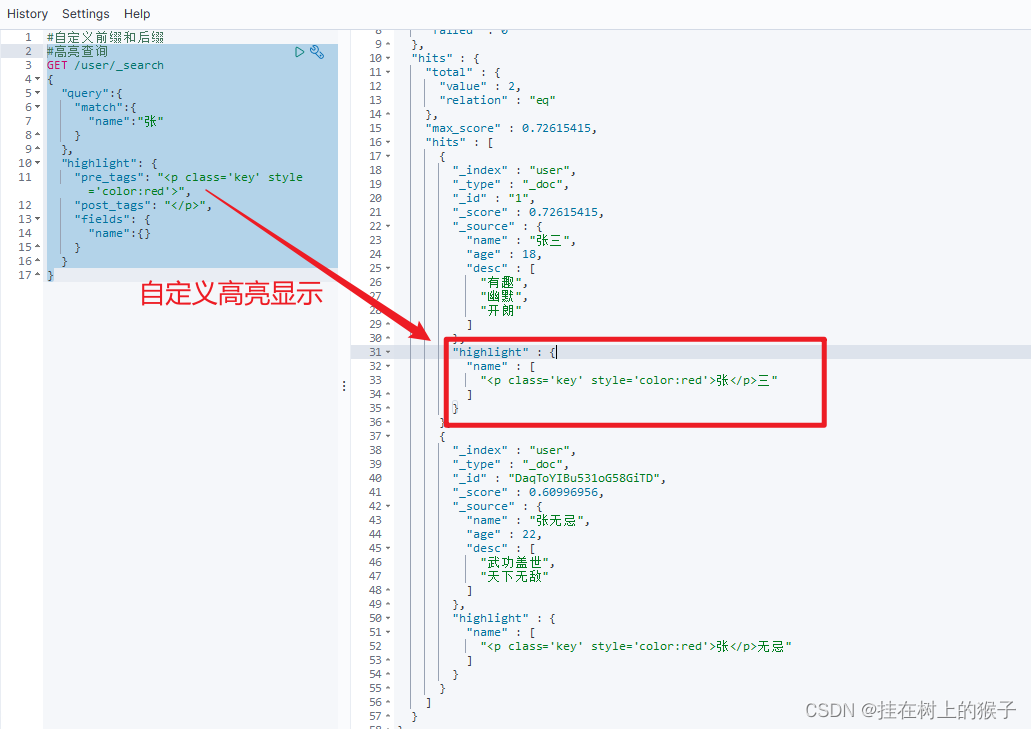


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









