







 本文详细介绍了如何在两节点环境中部署Spark,包括安装Java和Spark,配置相关文件,编写并运行Spark代码,以及构建和提交Jar包到Spark集群。重点展示了如何读取HDFS数据、处理中间值计算等Spark操作。
本文详细介绍了如何在两节点环境中部署Spark,包括安装Java和Spark,配置相关文件,编写并运行Spark代码,以及构建和提交Jar包到Spark集群。重点展示了如何读取HDFS数据、处理中间值计算等Spark操作。
|
|
|
|
目录
- Spark双节点部署
1.1、安装Java
因为Spark需要在Java环境才能运行,所以需要在所有节点上安装Java。首先,准备一份JDK,然后使用软件Xftp进行上传到目录/opt下。然后进入控制台输入以下命令解压JDK到/usr/local目录下。
注意 :这里的所有步骤都是在虚拟机内进行的。镜像为 Centos 7。其中xshell和xftp都是对虚拟机的系统进行相关操作的工具。它们的详细介绍请参考我的前篇文章
| tar zxvf jdk-8u341-linux-x64.tar.gz -C /usr/local/ |
1.2、下载Spark安装包
首先,进入到spark官网,去下载该安装包,如图所示。
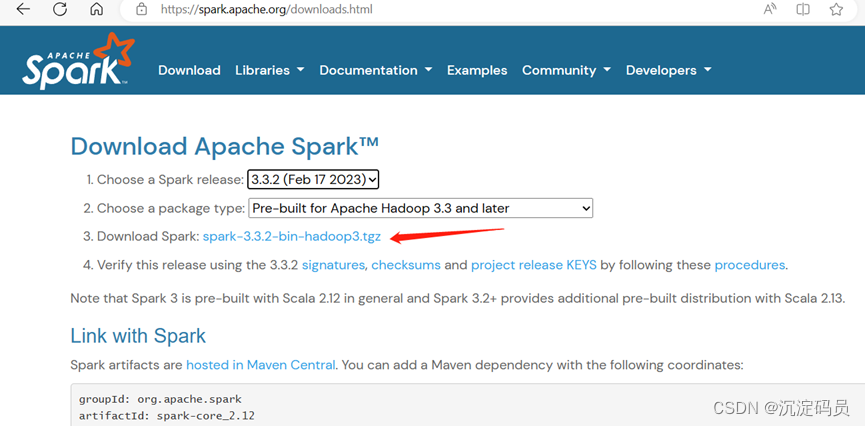
下载好后,同Java一样使用Xftp上传到Linux终端的/opt下。
使用命令解压到/usr/local下。注意搭建双节的Spark集群,两个包的解压路径必须一致。
| tar zxvf spark-3.3.2-bin-hadoop3-scala2.13_2.tgz -C /usr/local/ |
然后开始配置相关的Spark的文件。
1.3、Spark文件配置
在完成JDK和Spark包解压完成之后方可进行此步操作。以下操作在主节点master和从节点node中都要去配置
1.3.1、修正配置文件名称
首先进入spark的安装目录 usr/local 下,使用以下命令修改Spark的安装目录的名称。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1050
1050

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











