






🥂(❁´◡`❁)您的点赞👍➕评论📝➕收藏⭐➕关注👀是作者创作的最大动力🤞
💖📕🎉🔥 支持我:点赞👍+收藏⭐️+留言📝+关注👀欢迎留言讨论
🔥🔥🔥(源码获取 + 调试运行 + 问题答疑)🔥🔥🔥 有兴趣可以联系我
🔥🔥🔥 文末有往期免费源码,直接领取获取(无删减,无套路)
我们常常在当下感到时间慢,觉得未来遥远,但一旦回头看,时间已经悄然流逝。对于未来,尽管如此,也应该保持一种从容的态度,相信未来仍有许多可能性等待着我们。
🔥🔥🔥(免费,无删减,无套路):java swing管理系统源码 程序 代码 图形界面(11套)」
链接:https://pan.quark.cn/s/784a0d377810
提取码:见文章末尾
🔥🔥🔥(免费,无删减,无套路): Python源代码+开发文档说明(23套)」
链接:https://pan.quark.cn/s/1d351abbd11c
提取码:见文章末尾
🔥🔥🔥(免费,无删减,无套路):计算机专业精选源码+论文(26套)」
链接:https://pan.quark.cn/s/8682a41d0097
提取码:见文章末尾
🔥🔥🔥(免费,无删减,无套路):Java web项目源码整合开发ssm(30套)
链接:https://pan.quark.cn/s/1c6e0826cbfd
提取码:见文章末尾
🔥🔥🔥(免费,无删减,无套路):「在线考试系统源码(含搭建教程)」
链接:https://pan.quark.cn/s/96c4f00fdb43
提取码:见文章末尾
Fork/Join框架与工作窃取:Java并行计算的智慧引擎
-
《Java高性能并行计算:深入剖析Fork/Join框架与工作窃取算法》
-
《解密Fork/Join框架:如何让多核CPU利用率突破90%》
-
《工作窃取算法:为什么它是现代并行计算的“隐形引擎”》
-
《从分而治之到负载均衡:全面解析Fork/Join的设计哲学》
-
《实战Fork/Join:如何优雅地处理亿级数据计算任务》
引言:当计算遇到多核时代
在当今多核处理器普及的时代,如何充分利用CPU的每一个核心成为了性能优化的关键课题。传统的线程池模型在处理大量可分解任务时,常常面临负载不均、线程闲置等问题。正是在这样的背景下,Java 7引入了Fork/Join框架——一个专为可并行化的计算密集型任务设计的并行执行框架。
想象这样一个场景:你需要对一张1000万像素的图片进行复杂的滤镜处理,或者对一个包含百万条记录的数据集进行统计分析。这些任务都有一个共同特点:它们可以被递归地分解成更小的子任务,并且各个子任务之间相对独立。这正是Fork/Join框架大展身手的舞台。
Fork/Join框架的核心设计哲学
分而治之:古老的智慧,现代的实践
分而治之(Divide and Conquer)是计算机科学中最经典的算法设计范式之一。Fork/Join框架将这一思想发挥到了极致:
-
Fork(分解):将一个大任务递归地分解成足够小的子任务
-
并行执行:各个子任务在多核上同时执行
-
Join(合并):将子任务的结果合并成最终结果
// 典型的使用模式
if (任务足够小) {
直接计算任务
} else {
将任务拆分为两个子任务
调用子任务的fork()方法
调用子任务的join()方法获取结果
合并子任务结果
}这种递归分解的策略使得任务能够自然地适应可用的处理器资源:任务被分解得越细,可并行化的程度就越高,但同时也带来了更多的任务调度开销。Fork/Join框架通过精巧的设计在这两者之间找到了平衡点。
计算密集型 vs I/O密集型
理解Fork/Join的适用场景至关重要。框架主要针对计算密集型任务设计,这类任务的特点是:
-
CPU计算时间占主导
-
任务可分解且子任务间依赖较少
-
需要处理大量数据或复杂计算
相比之下,I/O密集型任务(如网络请求、文件读写)由于大部分时间在等待I/O操作,使用传统的线程池可能更为合适。选择错误的并发模型反而会导致性能下降。
工作窃取算法:平衡的艺术
算法原理深度解析
工作窃取(Work-Stealing)是Fork/Join框架的灵魂所在。它的核心思想异常简单却极其有效:让空闲的线程主动从繁忙线程的任务队列中"窃取"任务来执行。
让我们深入这一机制的工作原理:
-
每个线程都有自己的双端队列(Deque)
-
当线程生成新任务时,将任务推入自己队列的头部
-
当线程执行任务时,从自己队列的头部取出任务(后进先出)
-
-
窃取发生在队列的尾部
-
空闲线程从其他线程队列的尾部窃取任务
-
这种设计减少了线程间的竞争冲突
-
-
动态负载平衡
-
无需中央调度器
-
系统自动根据线程忙碌程度调整负载
-
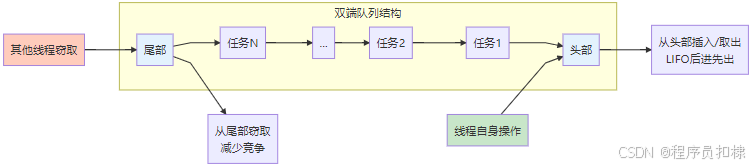
为什么使用双端队列?为什么从尾部窃取?
这是理解工作窃取算法的关键所在。这个设计选择背后蕴含着深刻的工程智慧:
双端队列的必要性:
-
生产者-消费者分离:每个线程既是自己队列的生产者(生成子任务),也是消费者(执行任务)
-
局部性原理:线程优先处理自己生成的任务,这些任务往往共享数据,提高了缓存命中率
-
减少竞争:大部分时间线程只操作自己队列的一端,减少了线程间的同步开销
从尾部窃取的智慧:
-
减少竞争冲突:
-
线程自己从头部取任务,其他线程从尾部窃取
-
操作队列的两端减少了锁竞争,提高了并发度
-
-
任务粒度考虑:
-
大任务通常先被分解,分解出的子任务放入队列
-
较早的任务(队列尾部)通常是较大的任务,窃取大任务能更有效地利用窃取者的计算资源
-
-
数据局部性优化:
-
线程自己执行的任务(从头部取)通常是最近创建的,可能与当前处理的数据有更好的局部性
-
被窃取的任务(从尾部取)通常是较早创建的,与其他线程当前处理的数据关联较小
-
工作窃取的优势与挑战
优势:
-
自动负载均衡:无需人工干预即可实现近乎完美的负载分配
-
高CPU利用率:显著减少了线程空闲时间
-
可扩展性:随着核心数增加,性能线性提升
挑战:
-
任务粒度控制:任务过小导致调度开销大,过大则并行度不足
-
递归开销:深度递归可能带来性能问题
-
内存占用:大量任务对象可能增加内存压力
Fork/Join框架的实战应用
性能关键的阈值选择
在实际使用中,选择合适的任务分解阈值至关重要。这个阈值决定了任务何时应该继续分解,何时应该直接计算:
// 自适应阈值选择策略
private static final int THRESHOLD = 1000; // 需要根据实际情况调整
protected void compute() {
if (任务大小 <= THRESHOLD) {
直接计算;
} else {
分解任务并fork();
}
}确定最优阈值的方法:
-
基准测试:对不同阈值进行性能测试
-
任务特性考虑:考虑任务的计算密度和数据大小
-
硬件适应性:根据CPU核心数调整阈值
避免常见陷阱
-
避免过度分解:
-
任务过小会增加调度开销
-
经验法则:每个任务至少执行1000-10000次基本操作
-
-
正确处理递归:
-
确保递归有明确的终止条件
-
考虑使用迭代方式重写深度递归
-
-
结果合并优化:
-
尽量减少结果合并的开销
-
考虑使用可变结果对象避免创建过多临时对象
-
与传统线程池的对比
理解Fork/Join框架与传统线程池的差异有助于做出正确的技术选择:
| 特性 | Fork/Join框架 | 传统线程池 |
|---|---|---|
| 设计目标 | 计算密集型、可分解任务 | 通用任务执行 |
| 负载均衡 | 自动工作窃取 | 需要手动平衡 |
| 任务调度 | 每个线程有自己的任务队列 | 中央任务队列 |
| 适用场景 | 递归任务、分治算法 | I/O密集型、独立任务 |
| 线程管理 | 固定数量(通常等于核心数) | 可动态调整 |
现代扩展与最佳实践
Java 8+的增强
Java 8引入了并行流(Parallel Streams),底层正是基于Fork/Join框架:
// 使用并行流简化并行计算
long result = dataList.parallelStream()
.filter(item -> item.isValid())
.mapToLong(item -> item.process())
.sum();最佳实践指南
-
任务独立性:确保子任务之间尽可能独立
-
避免阻塞操作:在任务中避免I/O等待或锁竞争
-
合理使用同步:尽量减少join()前的同步操作
-
监控与调优:使用JMX监控ForkJoinPool状态
-
错误处理:妥善处理任务执行中的异常
性能调优实战
诊断工具与技术
-
JMX监控:
jconsole 或 jvisualvm监控ForkJoinPool的活跃线程数、任务队列深度等指标
-
性能分析:
-
使用async-profiler分析任务执行热点
-
监控CPU利用率是否均衡
-
-
参数调优:
// 自定义ForkJoinPool ForkJoinPool customPool = new ForkJoinPool( Runtime.getRuntime().availableProcessors(), ForkJoinPool.defaultForkJoinWorkerThreadFactory, null, // 异常处理器 true // 异步模式 );
实战案例:大规模数据处理
考虑一个实际案例:处理10亿条日志记录,统计各类事件的数量。
传统方法可能面临内存溢出和性能瓶颈,而使用Fork/Join框架:
-
将10亿条记录分解成1000个100万条的子任务
-
每个子任务独立统计
-
最后合并统计结果
这种方法不仅内存友好,还能充分利用多核CPU,将处理时间从数小时缩短到数分钟。
未来展望
随着处理器核心数的不断增加,工作窃取算法的价值将愈加凸显。未来的发展方向可能包括:
-
异构计算支持:适应CPU+GPU混合计算环境
-
智能任务调度:基于机器学习预测任务执行时间
-
能耗感知调度:在性能和能耗间寻找平衡
-
分布式扩展:将工作窃取理念扩展到分布式环境
结论
Fork/Join框架与工作窃取算法代表了并行计算领域的重要进步。通过巧妙地将分而治之算法与动态负载平衡相结合,它为计算密集型任务提供了一种优雅高效的解决方案。
理解其核心原理——特别是双端队列的设计和从尾部窃取的智慧——不仅有助于更好地使用这一框架,还能启发我们在设计其他并发系统时的思考。在日益多核化的计算世界中,掌握这些技术将成为每个高级开发者的必备技能。
记住,技术的价值不仅在于使用,更在于理解其背后的思想。Fork/Join框架教会我们的,不仅是如何编写并行代码,更是如何设计能够自动适应环境、平衡负载的智能系统。这正是计算机科学的魅力所在:用简单的规则构建复杂而高效的系统。
图1:Fork/Join框架工作原理
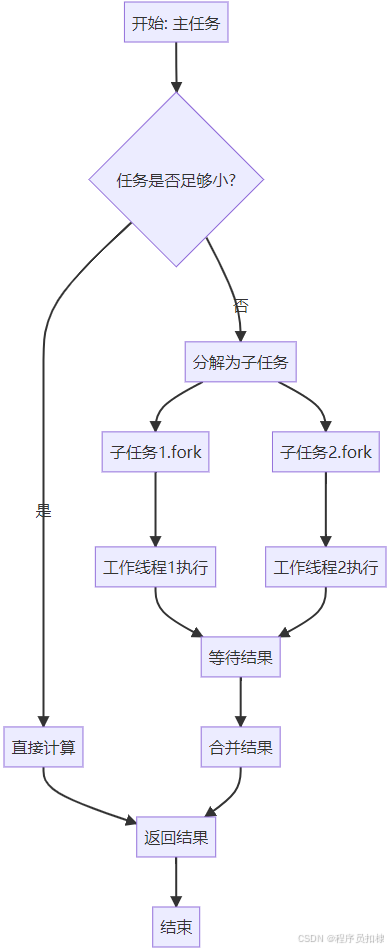
图2:工作窃取算法示意图
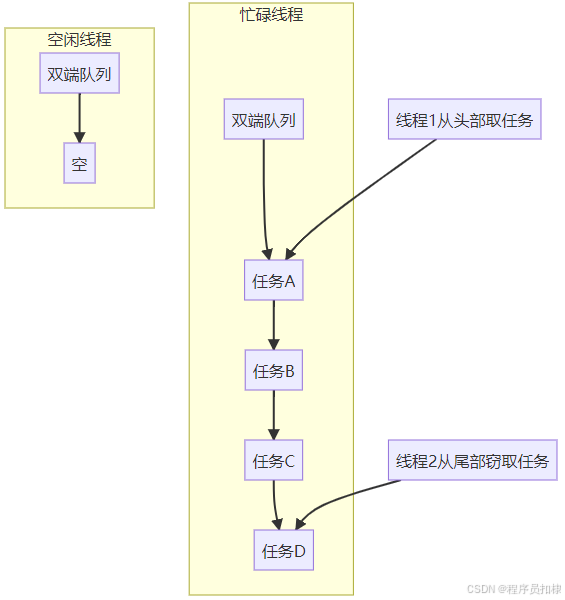
图3:双端队列操作对比
往期免费源码对应视频:
免费获取--SpringBoot+Vue宠物商城网站系统
🥂(❁´◡`❁)您的点赞👍➕评论📝➕收藏⭐➕关注👀是作者创作的最大动力🤞
💖📕🎉🔥 支持我:点赞👍+收藏⭐️+留言📝+关注👀欢迎留言讨论
🔥🔥🔥(源码 + 调试运行 + 问题答疑)
🔥🔥🔥 有兴趣可以联系我
💖学习知识需费心,
📕整理归纳更费神。
🎉源码免费人人喜,
🔥码农福利等你领!💖常来我家多看看,
📕网址:扣棣编程,
🎉感谢支持常陪伴,
🔥点赞关注别忘记!💖山高路远坑又深,
📕大军纵横任驰奔,
🎉谁敢横刀立马行?
🔥唯有点赞+关注成!
⬇⬇⬇⬇⬇⬇⬇⬇⬇⬇点击此处获取源码⬇⬇⬇⬇⬇⬇⬇⬇⬇


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









