






 本文详细解释了哈希表的工作原理,重点讲解了HashMap的底层实现,包括哈希函数的应用、哈希碰撞的解决策略(使用单向链表),以及put和get方法的实现过程。作者还强调了自定义类在HashMap中的使用时重写equals()和hashCode()方法的重要性。
本文详细解释了哈希表的工作原理,重点讲解了HashMap的底层实现,包括哈希函数的应用、哈希碰撞的解决策略(使用单向链表),以及put和get方法的实现过程。作者还强调了自定义类在HashMap中的使用时重写equals()和hashCode()方法的重要性。
目录
题外话
又水了两天,怪我,在宿舍确实没什么状态,是时候调整调整了
正题
今天直接讲解HashMap底层实现
哈希表
哈希表又称散列表
是数组和单向链表的结合体
如下图
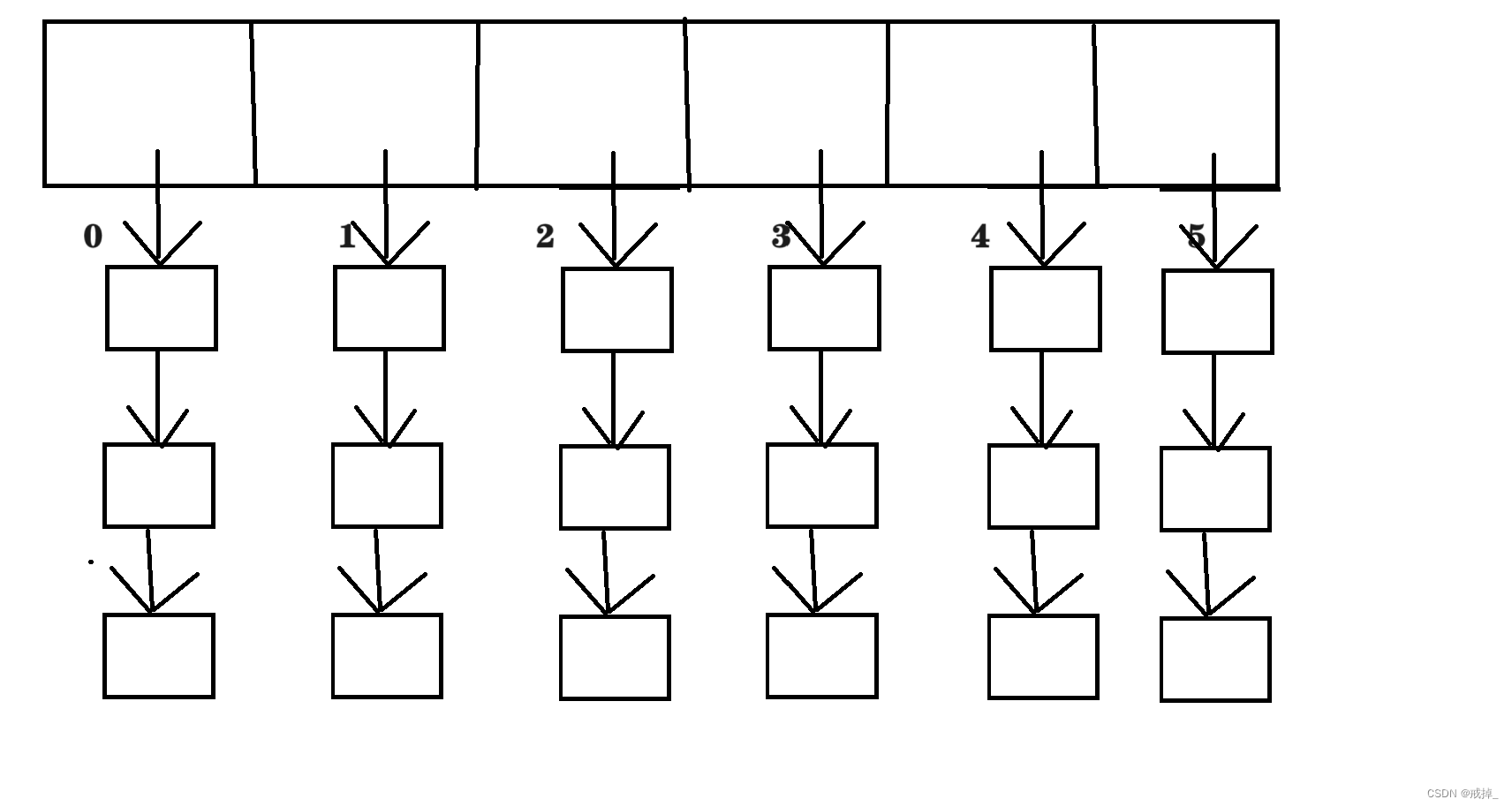
而哈希表存放元素机制是靠哈希函数解析关键字,使其转变为哈希值
然后再由这个哈希值和整个数组长度求模运算,放入求模算出对应的数组下标中
哈希碰撞
输入两个不同的值,经过哈希函数解析之后,哈希值模完数组长度是一样的
如下图:
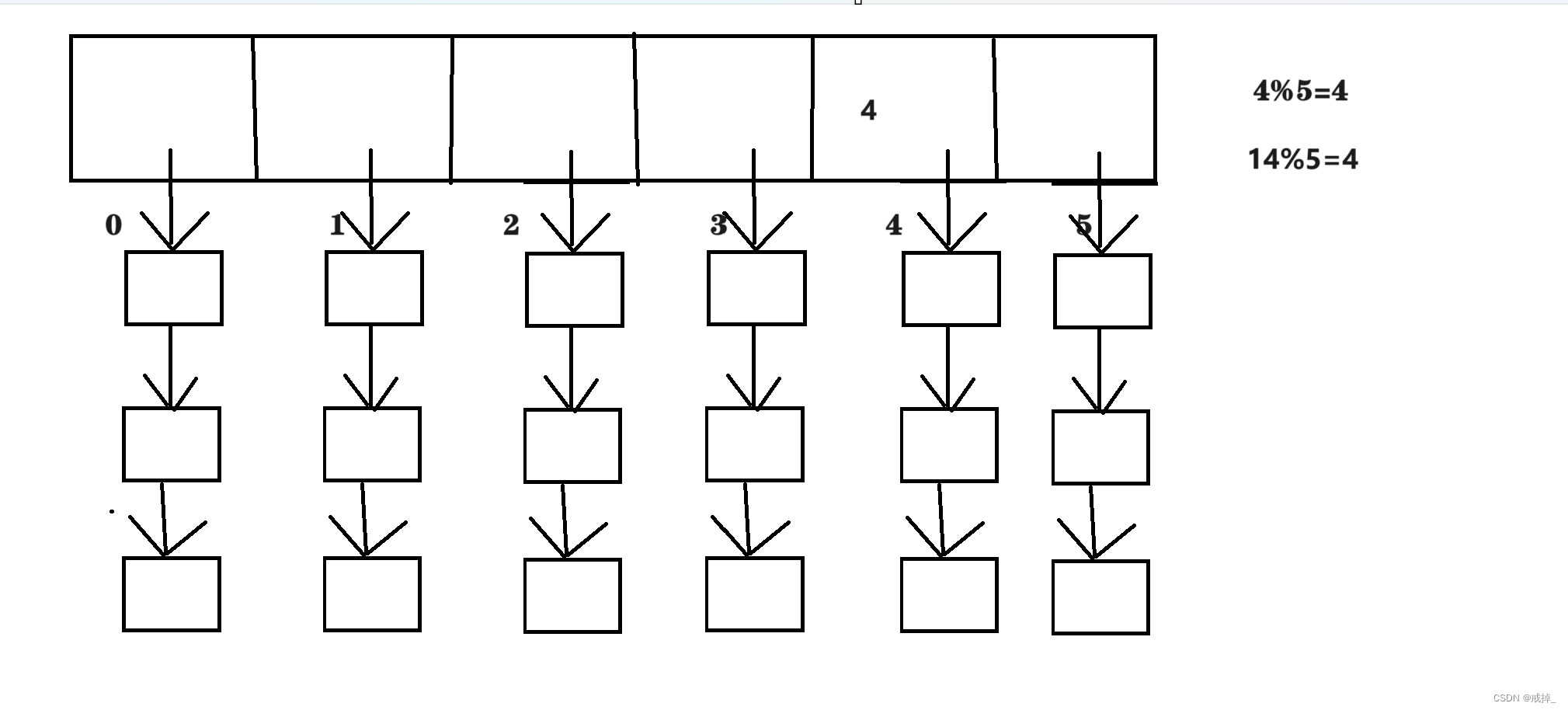
当出现哈希碰撞时,我们就需要利用单向链表,将其放入同一下标的链表当中,这样也就解决了哈希碰撞
而且单向链表的插入和修改操作时间复杂度很小,只需要修改结点next域即可
大家可以想象一下,如果对数组进行增删时,我们普遍需要让数组一些元素往后移或者往前移,时间复杂度更高
HashMap底层实现
下面我们分两组代码让大家明白HashMap底层如何实现,我们这里先将key和value默认为int类型
public class HashMapBottom{
class Node
{
/*
创建key,value和next
*/
int key;
int value;
Node next;
//提供构造方法
public Node(int key, int value) {
this.key = key;
this.value = value;
}
/**
*构造一个结点对象
* @param key 键
* @param value 值
* @param next 指向下一个结点
*/
}
//负载因子为0.75
private final float loadFactor=0.75f;
/*
哈希表
*/
private Node[] table;
/*
记录哈希表元素数量
*/
private int size;
/*
初始化容量
*/
public HashMapBottom()
{
this.table=new Node[16];
}
public int size()
{
return size;
}
public void put(int key,int value)
{
//获取key模数组长度
int index=key%table.length;
//将index放入数组中,cur获取当前数组元素
Node cur=table[index];
//如果cur获得元素不为空
while (cur!=null)
{
//判断cur取出元素是否和key相等,相等则说明重复了
if (cur.key==key)
{
//如果相等则更新cur的value值
cur.value=value;
return;
}
//如果cur.key等于key,说明没有重复,插入到后面位置
cur=cur.next;
}
//如果cur为空,则创建结点存放当前元素
Node node=new Node(key,value);
node.next=table[index];
table[index]=node;
size++;
if (doloadFactor()>loadFactor)
{
resize();
}
}
private void resize()
{
//将table数组进行二倍扩容
Node[] newTable=new Node[2*table.length];
for (int i=0;i<table.length;i++)
{
//将table数组中元素拿出
Node cur=table[i];
//如果取出元素不为空
while (cur!=null)
{
//先将cur下一个结点放入tmp中
Node tmp=cur.next;
//将cur.key模newTable.length算出新的值
int newIndex=cur.key%newTable.length;
//将cur放入扩容数组中
newTable[newIndex]=cur;
//将之前cur保存的下一个结点传入cur继续循环
cur=tmp;
}
}
//全部放入扩容数组中之后,将扩容数组给到之前的数组
table=newTable;
}
private float doloadFactor()
{
return size*1.0f/table.length;
}
public int get(int key)
{
//先找到key在数组的下标
int index=key%table.length;
//将数组下标元素赋值cur
Node cur=table[index];
//当cur不为空
while (cur!=null)
{
//如果cur.key==key说明找到了,返回cur的value即可
if (cur.key==key)
{
return cur.value;
}
//如果不等于则进入下一个结点继续找
cur=cur.next;
}
//如果遍历完成全部结点则返回-1
return -1;
}
}
我们如果使用的是基本数据类型包装类,或者String类的话
里面是重写过HashCode()和equals()方法的,所以我们使用的时候不需要过于担心
但是当我们自己创建类例如Student或者User之类的类
我们一定要重写HashCode()和equals()方法
比如我们在HashMap创建对象中调用put方法,添加了Student类,我们如果不重写上面两个方法
我们就没法比较,也没法哈希碰撞,如果put两个key值一样的元素,没有重写方法,就会将这两个元素全部放入HashMap中
下面让我们稍微实现一下带泛型的底层代码
public class HashMapBottom02<K,V> {
//创建key和value还有next
class Node<K,V>{
K key;
V value;
Node<K,V> next;
public Node(K key,V value)
{
this.key=key;
this.value=value;
}
}
Node<K,V>[] table;
private int size;
private static final float loadFactor=0.75f;
public HashMapBottom02()
{
table=new Node[16];
}
public void put(K key,V value) {
int hash=key.hashCode();
//获取key模数组长度
int index = hash % table.length;
//将index放入数组中,cur获取当前数组元素
Node<K,V> cur = table[index];
//如果cur获得元素不为空
while (cur != null) {
//判断cur取出元素是否和key相等,相等则说明重复了,这里比较一定要用equals,不然比较的是地址,而不是数值大小
if (cur.key.equals(key) ) {
//如果相等则更新cur的value值
cur.value = value;
return;
}
//如果cur.key等于key,说明没有重复,插入到后面位置
cur = cur.next;
}
//如果cur为空,则创建结点存放当前元素
Node<K,V> node = new Node(key, value);
node.next = table[index];
table[index] = node;
size++;
}
public V get(K key)
{
int hash=key.hashCode();
int index=hash%table.length;
Node<K,V> cur=table[index];
//当cur不为空
while (cur!=null)
{
//如果cur.key==key说明找到了,返回cur的value即可
if (cur.key.equals(key))
{
return cur.value;
}
//如果不等于则进入下一个结点继续找
cur=cur.next;
}
//如果遍历完成全部结点则返回-1
return null;
}
}
小结
明天直接更新算法题,最近堕落了,赶紧调整下状态
麻烦喜欢的家人们三连一下(点赞关注收藏!!!)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









