






 本文介绍了Python中的matplotlib库和pandas库的基础知识。matplotlib用于数据可视化,包括创建和定制图表,如设置图例、标题和坐标轴标签。pandas是数据分析的核心库,提供了Series和DataFrame两种数据结构,便于数据操作和分析。文章详细展示了如何使用这两个库进行数据处理和绘图,并解释了索引和选择数据的方法。
本文介绍了Python中的matplotlib库和pandas库的基础知识。matplotlib用于数据可视化,包括创建和定制图表,如设置图例、标题和坐标轴标签。pandas是数据分析的核心库,提供了Series和DataFrame两种数据结构,便于数据操作和分析。文章详细展示了如何使用这两个库进行数据处理和绘图,并解释了索引和选择数据的方法。
文章目录
matplotlib基础
matplotlib须知
matplotlib是python最著名的绘图库,它提供了—整套和matlab相似的命令API,十分适合交互式地进行制图。而且也可以方便地将它作为绘图控件,嵌入GUI应用程序中。
其中,matplotlib的pyplot子库提供了和matlab类似的绘图API,方便用户快速绘制2D图标。
matplotlib中的快速绘图的函数库可以通过如下语句载入:
import matplotlib.pyplot as plt
接下来调用figure创建一个绘图对象,并且使他成为当前的绘图对象:
plt.figure(figsize=(8,4))
其中,figsize参数可以指定绘图对象的宽度和高度,单位为英尺;
此外,还有dpi的值,即绘图对象的分辨率,也就是每英寸包含多少个像素,缺省值为80。因此本例子中所创建的图标窗口的宽度为8*80=640像素。
关于figure函数:
①也可以不创建绘图对象直接调用接下来的plot函数直接绘图。
②如果需要同时绘制多幅图标的话,可以是给figure传递一个整数参数指定图标的序号。
③如果所指定序号的绘图对象已经存在的话,将不创建新的对象,而只是让它成为当前绘图对象。
plot函数绘制折线图
相关函数:
①label:给所绘制的曲线一个名字,此名字在图示(legend)中显示
②color:指定曲线的颜色
③linewidth:指定曲线的宽度
④其中‘b–’参数指定的是曲线的颜色和线型
⑤xlabel/ylabel:设置x轴/y轴的文字
⑥title:设置图表的标题
⑦ylim:设置y轴的范围
⑧legend:显示图示
代码如下:
import numpy as np
import matplotlib.pyplot as plt
plt.figure(figsize=(8,4))
x=np.linspace(0,10,100)
y=np.sin(x)
z=np.cos(x**2)
plt.plot(x,y,label='sin(x)',color='red',linewidth=2)
plt.plot(x, z, 'b--', label='cos(x^2)')
plt.xlabel('Time(s)')
plt.ylabel('volt')
plt.title('PyPlot First Example')
plt.ylim(-1.2,1.2)
plt.legend()
plt.show()
第一、二行:numpy和pyplot包的导入。
第三行:创建一张八英寸宽,四英寸高的画布。
第四行:用numpy中的linspace函数创建一个在0~10之间递增的序列并均分为1000份,然后存入变量x中。
第五行:将刚创建好的x变量带入numpy中自带的正弦函数中,得出相应的序列y。
第六行:将变量x的平方带入numpy中自带的余弦函数中,得出相应的序列z。
第七行:向plot函数中分别传入横轴数据、纵轴数据,曲线名称(label),曲线颜色(color),线的粗细(linewidth)
第八行:向plot函数中分别传入横轴数据、纵轴数据,曲线的颜色和样式(b–),以及曲线名称(cos(x^2))。
第九行:横坐标名。
第十行:纵坐标名。
第十一行:图标名。
第十二行:y轴范围大小设置
第十三行:显示图注
第十四行:显示图示
运行结果:
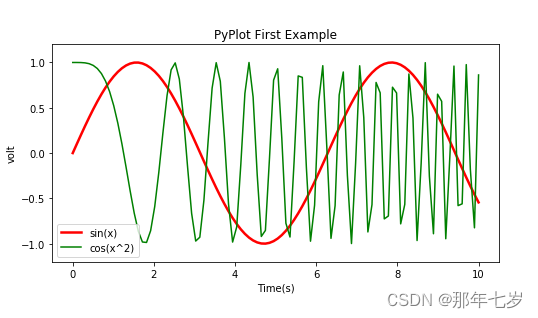
在得到图表后,我们可以通过调用plt.savefig()将当前的figure对象保存成图像文件,图像格式由图像文件的扩展名决定。
plt.savefig('D:\test.jpg',dpi=600)
实际上不需要调用show()显示图表,可以直接用savefig()将图表保存成图像文件,使用这种方法可以很容易编写出批量输出图表的程序。
Pandas基础
Pandas须知
Pandas是Python的一个数据分析包。
Pandas纳入大量库和标准数据类型,提供高效的操作数据集所需的工具。
Pandas提供大量能使我们快速便捷地处理数据的函数和方法。
Pandas是字典形式,基于NumPy创建,让NumPy为中心的应用变得更加简单。
Pandas最核心的就是Series和DataFrame两个数据结构:
| 名称 | 维度 | 说明 |
|---|---|---|
| Series | 1维 | 带有标签的同结构类型数组 |
| DataFrame | 2维 | 表格结构,带有标签,大小可变,且可以包含异构数组 |
注:一个DataFrame中可以包含若干个Series。
Pandas的数据结构
利用Series和DataFrame函数进行列表或字典导入:
import pandas as pd # 引入模块别名
x=pd.Series(list/dictionary)
x=pd.DataFrame(list/dictionary)
Series
Series类似于numpy中的一维数组,除了通吃一维数组可用的函数或方法,而且其可通过索引标签的方式获取数据,还具有索引的自动对齐功能;
有常用的两种方式创建:
①通过列表创建
②通过字典创建
应用实例①,通过列表创建:
import numpy as np # 基于numpy的pandas
import pandas as pd
arr1 = np.arange(10)
s1 = pd.Series(arr1)
print(s1)
运行结果:
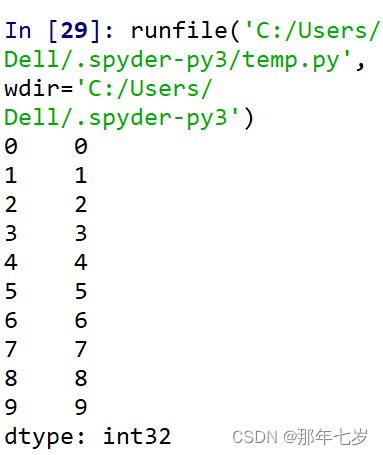
其中左边为索引号,右边为索引值,最下面显示的是数据类型(32位整型)。
应用实例②,通过字典创建:
#import numpy as np
import pandas as pd
dic1={'a':10, 'b':20, 'c':30, 'd':40, 'e':50}
s2 = pd.Series(dic1)
print(s2)
运行结果:
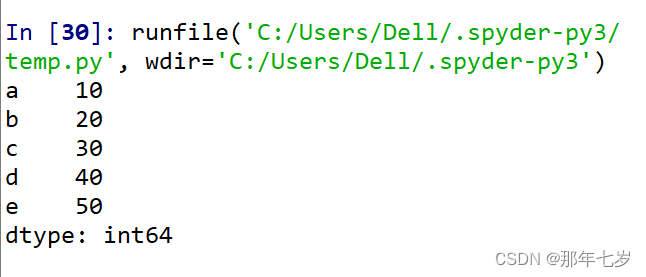
其中左边为关键字,右边为索引值,最下面显示的是数据类型(64位整型)。
DataFrame
DataFrame类似于numpy中的二维数组,同样可以通用numpy数组的函数和方法,而且还具有其他灵活应用。
也是有常用的两种方式创建:
①通过列表创建
②通过字典创建
应用实例①,通过列表创建:
import numpy as np
import pandas as pd
arr2 = np.arange(12).reshape(4,3)
df1 = pd.DataFrame(arr2)
print(df2)
运行截图:
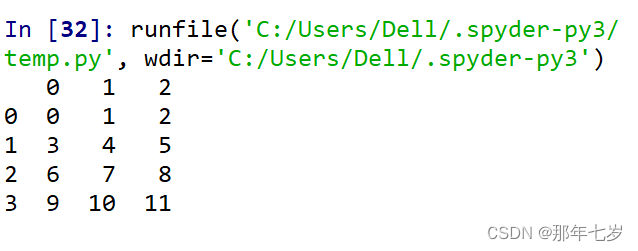
默认的行列索引和列名都是[0,N-1]的形式。
应用实例②,通过字典创建:
#import numpy as np
import pandas as pd
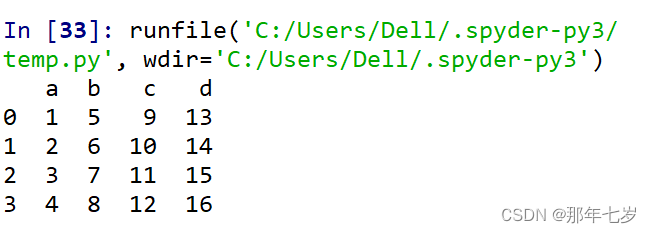
dic2 = {'a':[1,2,3,4], 'b':[5,6,7,8], 'c':[9,10,11,12], 'd':[13,14,15,16]}
df2 = pd.DataFrame(dic2)
print(df2)
运行结果:
应用实例③,在创建DataFrame的时候指定列名和索引。以列表为例:
import numpy as np
import pandas as pd
arr2 = np.arange(12).reshape(4,3)
df1 = pd.DataFrame(arr2)
df1.columns={'colm1', 'colm2', 'colm3'}
print(df1)
运行结果:

注:
①DataFrame的不同列可以是不同的数据类型。
②如果以Series数组来创建DataFrame,每个Series将成为一行,而不是一列。
Pandas索引
序列或数据框的索引有两大用处:
①通过索引值或索引标签获取目标数据。
②通过索引,可以使序列或数据框的计算、操作实现自动化对齐。
一维序列索引——Series
①使用s1[index]索引
import numpy as np
import pandas as pd
arr1 = np.arange(10)
s1 = pd.Series(arr1)
#print(s1,'\n')
print(s1[5],'\n')
#print(s1[0:3])
运行结果:

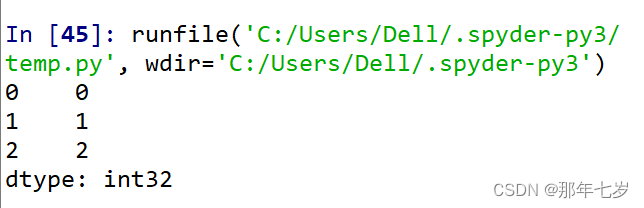
②使用s1[:]切片
import numpy as np
import pandas as pd
arr1 = np.arange(10)
s1 = pd.Series(arr1)
#print(s1,'\n')
#print(s1[5],'\n')
print(s1[0:3])
运行结果:
多维序列索引——DataFrame
①通过标签选择
loc:通过行和列的索引来访问数据,用例如下:
#import numpy as np
import pandas as pd
dic2 = {'a':[1,2,3,4], 'b':[5,6,7,8], 'c':[9,10,11,12], 'd':[13,14,15,16]}
df2 = pd.DataFrame(dic2)
print(df2)
print(df2.loc[0])
运行截图:
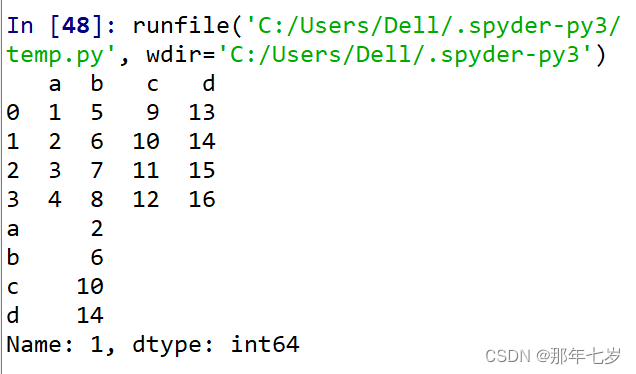
在这里我们就用loc函数取出了字典中标签为‘0’的一行。
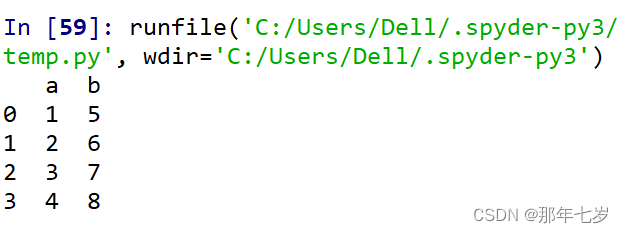
②通过标签来在多个轴上进行选择,如图:

代码如下:
#import numpy as np
import pandas as pd
dic2 = {'a':[1,2,3,4], 'b':[5,6,7,8], 'c':[9,10,11,12], 'd':[13,14,15,16]}
df2 = pd.DataFrame(dic2)
#print(df2)
print(df2.loc[:,['a','b']])
运行结果:
③标签切片,如图:
#import numpy as np
import pandas as pd
dic2 = {'a':[1,2,3,4], 'b':[5,6,7,8], 'c':[9,10,11,12], 'd':[13,14,15,16]}
df2 = pd.DataFrame(dic2)
#print(df2)
print(df2.loc['1':'3',['a','c']])
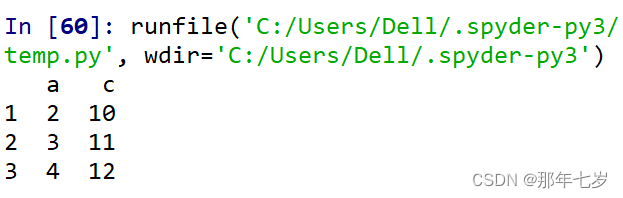
可以看到,在对标签进行切片时,切片结果是闭区间而不是左闭右开区间,这里需要注意。
④通过位置进行选择:
iloc:通过行和列的下标来访问数据
这里我们通过传递数值进行位置选择(选行):
#import numpy as np
import pandas as pd
dic2 = {'a':[1,2,3,4], 'b':[5,6,7,8], 'c':[9,10,11,12], 'd':[13,14,15,16]}
df2 = pd.DataFrame(dic2)
#print(df2)
print(df2.iloc[3])
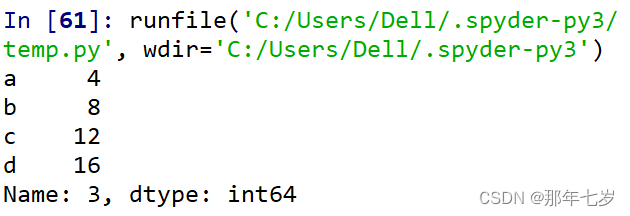
⑤通过数值进行切片
#import numpy as np
import pandas as pd
dic2 = {'a':[1,2,3,4], 'b':[5,6,7,8], 'c':[9,10,11,12], 'd':[13,14,15,16]}
df2 = pd.DataFrame(dic2)
#print(df2)
print(df2.iloc[1:3,0:2])
运行结果:
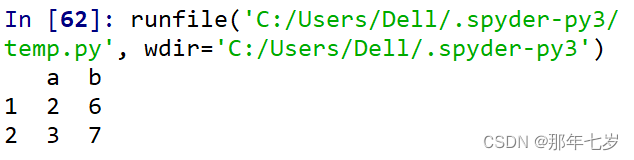
可以看出,当我们在用位置或是说数值进行切片访问的时候(iloc),采取了左闭右开区间的方式,与之前的认知相符合,要和标签切片访问(loc)做好区分。
⑥通过指定一个位置的列表
这里我们通过相邻或者不相邻的几个位置来打印数据,用例如下:
#import numpy as np
import pandas as pd
dic2 = {'a':[1,2,3,4], 'b':[5,6,7,8], 'c':[9,10,11,12], 'd':[13,14,15,16]}
df2 = pd.DataFrame(dic2)
#print(df2)
print(df2.iloc[[0,1,3],[2,3]])
运行截图:
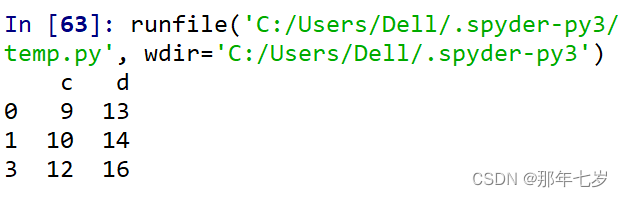
⑦对行进行切片
这里仍然是左闭右开区间:
#import numpy as np
import pandas as pd
dic2 = {'a':[1,2,3,4], 'b':[5,6,7,8], 'c':[9,10,11,12], 'd':[13,14,15,16]}
df2 = pd.DataFrame(dic2)
#print(df2)
print(df2.iloc[1:3,:])
运行截图:
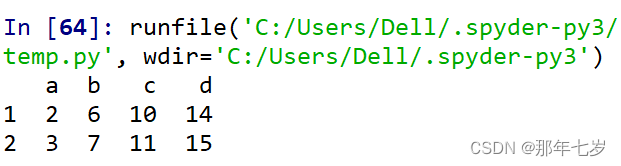
⑧对列进行切片
#import numpy as np
import pandas as pd
dic2 = {'a':[1,2,3,4], 'b':[5,6,7,8], 'c':[9,10,11,12], 'd':[13,14,15,16]}
df2 = pd.DataFrame(dic2)
#print(df2)
print(df2.iloc[:,1:4])
运行截图:
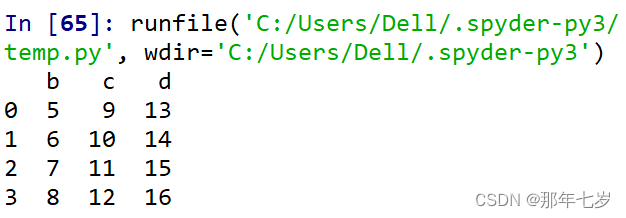
结束语
本篇博客主要介绍了Python中matplotlib的绘图以及pandas基础等内容,Python的入门内容就告一段落了。后面将继续更新Python面向对象编程、机器学习算法等内容,感谢观看。

















 737
737

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









