







 本文探讨了在高性能计算网络中,如何通过优化网络拓扑和路由算法来减少网络拥塞,特别是针对深度学习场景。文章介绍了Fattree拓扑结构,以及Mellanox的MLNXSM路由算法在实际应用中的问题,并分享了幻方AI自研的负载均衡路由策略,以提升网络使用效率。
本文探讨了在高性能计算网络中,如何通过优化网络拓扑和路由算法来减少网络拥塞,特别是针对深度学习场景。文章介绍了Fattree拓扑结构,以及Mellanox的MLNXSM路由算法在实际应用中的问题,并分享了幻方AI自研的负载均衡路由策略,以提升网络使用效率。
揭秘萤火高性能计算网络下的路由算法
对于深度学习开发者和研究者们来说,高性能的算力是助力其研究成功的重要武器。对于影响深度学习训练快慢的因素,人们常常容易忽略网络传输在训练提速中的重要作用。特别是在大规模集群,分布式训练的场景中,网络的拥塞可能直接导致超算算力的失效,就像空有一段段双向8车道的快速路,但如果道路规划凌乱,高速路也只能沦为大型停车场。
本期文章针对网络这个话题,分享一点幻方 AI 就这个方向上的思考和优化。
先聊聊网络拓扑
在幻方萤火平台中,大规模机器学习训练任务对通信和数据读取的性能要求非常高,所以我们使用了目前高性能计算中常用的 Infiniband 来构建节点之间的互联。Infiniband 的网线和交换机如何排布,这就是我们需要考虑的第一个问题——网络拓扑。
网络拓扑的构建有点像修路,不但要保证任意两个节点之间都能互相访问,还要让从各个节点发出的数据包都能尽可能畅通无阻地到达目的地。
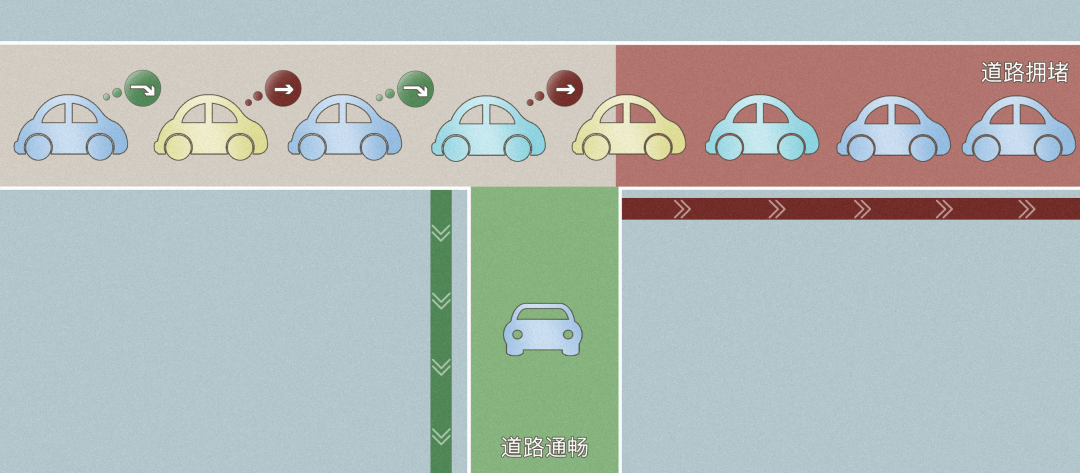
与畅通无阻相反的概念就是拥塞。这里用一个生活中塞车的例子来理解拥塞,假设现在所有车辆都具有相同的最高时速,并且会按照能跑到的最大速度去开。
1.某个路口有三条车道,源源不断地有车进来但只有一条车道可以出去。如果三条车道的车都遵守交替通行的规则,那么这三条车道的通行效率就只有 1/3。这就是发生了拥塞;
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2589
2589

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











