







目录
一、limit分页查询
当数据量太多时,为了更快的加载数据内容,可以进行分页处理。
limit分页查询语法:
select 字段名1,字段名2,... from 表名 limit M, N;
# M: 整数,表示从第几条索引开始,计算方式:(当前页-1) * 每页显示条数;
# N: 整数,表示查询多少条数据.
例如,使用命令完成:
(1)从商品信息中开始处查询5条数据;
(2)从商品信息中索引值为5开始,共查询10条数据;
(3)获取当前商品中价格最低的2件商品。
#######################分页查询#########################
# 1.使用库
use db_product1;
# 2.查看所有数据
select * from product;
# 3.查询5条数据
select * from product limit 0,5; # 0是索引
# 4.查询5-10
select * from product limit 5,10; # 取值: 6-15条
# 5.价格最低的2件商品
# 技巧: 复杂的SQL = 多个简单SQL语句组合
# a.仅查询2件商品
select * from product limit 0,2;
# b.要对商品信息通过价格从低到高排序
select * from product order by price asc;
# 综合
select * from product order by price asc limit 0,2;
# select * from product limit 0,2 order by price asc; # 报错:顺序有误
# 6.显示第3页
select * from product limit 10,5; # 0,5 5,5 10,5
select * from product limit 0,15;
二、分组查询
2.1 分组查询group by
分组查询指的是:将查询结果按照指定字段分组,其中,数值相等的可划分为同一组。
分组查询的语法:
select 字段名1,字段名2,... from 表名 group by 分组字段名 [having 分组条件];
例如,使用命令完成:
(1)在人物表person中执行分组查询;
(2)按性别字段进行分组查询;
(3)观察查询结果。
####################分组group by############################
# 1.使用库
use db_product2;
# 2.查询所有数据
select * from person;
# 3.分组
select gender from person group by gender;
2.2 group by + 聚合函数
使用group by + 聚合函数进行分组查询,语法:
select 字段名1,字段名2,聚合函数(...) from 表名 group by 分组字段名;
例如,使用命令完成:
(1)计算平均年龄值;
(2)计算总人物个数;
(3)请统计出不同性别的人平均年龄值;
(4)请统计出不同性别的人总个数。
########################group by + 聚合函数##############################
# 1.使用库
use db_product2;
select * from person;
# 2.平均
select avg(age) from person;
# 3.总个数
select count(*) from person;
select count(id) from person; # 建议count()使用*来查询, 但是也可使用列名来查询
# 4.不同性别的平均年龄
select gender,avg(age) from person group by gender;
# 5.不同性别的总个数
select gender,count(*) from person group by gender;
2.3 group by + having
having用于过滤分组数据,且只能用于group by,语法:
select 字段名1,字段名2,... from 表名 group by 分组字段名 having 分组条件;
例如,使用命令完成:
(1)请统计各个性别下人物的总个数;
(2)请统计各个性别中当性别为Female时,人物的总个数;
(3)请统计各个性别下人物的总个数,且只显示总个数大于2的信息。
#######################having子句####################################
# 1.使用库
use db_product2;
select * from person;
# 2.查询不同性别的总个数
select gender,count(*) from person group by gender;
# 3.性别为Female的人物总个数
select gender,count(*) from person where gender='Female' group by gender;
select gender,count(*) from person group by gender having gender='Female';
# 结论
# a.同: where和having都能完成过滤条件的作用;
# b.异: where和having编写的位置不同; -where是在group by前, having在之后
# 不同:having是最后执行的, 可以在having后放聚合函数# 4.总个数 > 2的信息
select gender,count(*) from person group by gender;
# select gender,count(*) from person where count(*) > 2 group by gender; # where不能直接使用聚合函数做条件
select gender,count(*) from person group by gender having count(*) > 2;
# 扩展
select
*
from (select
gender,
count(*) as ct
from person
group by gender) as temp_person
where ct > 2;
以上便是DQL的操作,不要急于一口吃个胖子,一定要多写多练。
三、SQL增删改查练习题
1.创建一个默认编码的数据库(公司1),以及一个编码为gbk的数据库(公司2),再创建一个编码为utf8的数据库(公司3),并执行:
a.查看有哪些数据库;
b.查看创建数据库(公司2)语句;
c.删除第2个数据库;
d.查看当前使用数据库;
e.切换使用数据库(公司3)等操作。
考察知识点
-
创建数据库
-
删除数据库
-
查看数据库
# 创建数据库
create database hw_company1;
create database hw_company2 charset gbk;
create database if not exists hw_company3 charset utf8;show databases ;
show create database hw_company2;show databases ;
drop database hw_company2;
show databases ;# 在脚本中使用了: use 数据库名; 的那个数据库就是当前的数据库
select database();# 在操作数据前,一定记得确认使用哪个数据库
use sz47hw_company3;
select database();
2.
按照下列要求完成DML操作:
(1)创建一个数据库班级db_hw2,并设置默认编码格式为utf-8;
(2)在库中创建一个student表,字段有编号id、学号number、姓名name、语文成绩chinese、英语成绩english、数学成绩math等;
(3)对于这些字段,要求:编号是整型且是主键并且是自动增长的,学号是字符串。
考察知识点
-
创建数据表
-
字段类型
# 选择数据库
use db_hw3;
# 创建数据表
create table student(
id int primary key auto_increment,
number varchar(20),
name varchar(16),
chinese double,
english double,
math double # modify修改列类型
);
# 查看表结构
desc student;
3.使用命令给student表完成:
(1)在班级db_hw2库中新建一个只有姓名字段的老师表;
(2)查看有哪些数据表,查看student表的创建语句是如何的,查看student表的结构;
(3)永久删除老师表;
(4)给student表名前添加前缀tb_;
(5)修改学号number、姓名name字段名,分别为:stu_no、stu_name;
(6)新增一列是否挂科。
考察知识点
-
删除数据表
-
查看数据表
-
修改数据表
# 使用数据库
use db_hw3;
# 创建老师表
create table teacher(
name varchar(20)
);
# 查看表信息
show tables;
# 查看学生表创建语句
show create table student;
# 查看学生表结构
desc student;
# 删除老师表
show tables ;
drop table teacher;
# 查看表信息
show tables ;
# 修改表名
rename table student to tb_student;
# show tables ;
# 修改列名
desc tb_student;
alter table tb_student change number stu_no varchar(20);
alter table tb_student change name stu_name varchar(16);
desc tb_student;
# 添加一列
desc tb_student;
alter table tb_student add is_fail tinyint; # 0 1
desc tb_student;
4.请使用命令完成:
(1)创建一个数据库班级db_hw2,编码为utf-8;
(2)在库中新建一个员工表,字段信息有:编号、工号、姓名、工作岗位、性别、年龄、学历、薪资、奖金、身份证号、地址等;
(3)使用多种插入数据的方式,分别添加20条数据;
(4)在DataGrip软件中查看所有的数据结果,并截图。
考察知识点
-
创建数据库
-
创建数据表
-
插入数据
# 创建数据库
create database db_hw4 charset utf8;
# 新建数据表
use sz47db_hw4;
create table tb_staff(
id int primary key auto_increment,
sno varchar(20),
name varchar(20),
work_proff varchar(20),
sex varchar(10),
age int,
education varchar(10),
salary double,
bonus double,
id_card varchar(18),
address varchar(40)
);
# 插入数据
insert into
tb_staff(sno, name, work_proff, sex, age, education, salary, bonus, id_card, address)
values
('76200','张三','数据开发工程师','男',24,'本科',18000,0,'411522198009130002','广东深圳'),
('76201','张三','数据开发工程师','男',24,'本科',18000,0,'411522198009130002','广东深圳'),
('76202','张三','数据开发工程师','男',24,'本科',18000,0,'411522198009130002','广东深圳'),
('76203','张三','数据开发工程师','男',24,'本科',18000,0,'411522198009130002','广东深圳'),
('76204','张三','数据开发工程师','男',24,'本科',18000,0,'411522198009130002','广东深圳'),
('76205','张三','数据开发工程师','男',24,'本科',18000,0,'411522198009130002','广东深圳'),
('76206','张三','数据开发工程师','男',24,'本科',18000,0,'411522198009130002','广东深圳'),
('76207','张三','数据开发工程师','男',24,'本科',18000,0,'411522198009130002','广东深圳'),
('76208','张三','数据开发工程师','男',24,'本科',18000,0,'411522198009130002','广东深圳'),
('76209','张三','数据开发工程师','男',24,'本科',18000,0,'411522198009130002','广东深圳'),
('76210','张三','数据开发工程师','男',24,'本科',18000,0,'411522198009130002','广东深圳'),
('76211','张三','数据开发工程师','男',24,'本科',18000,0,'411522198009130002','广东深圳'),
('76212','张三','数据开发工程师','男',24,'本科',18000,0,'411522198009130002','广东深圳'),
('76213','张三','数据开发工程师','男',24,'本科',18000,0,'411522198009130002','广东深圳'),
('76214','张三','数据开发工程师','男',24,'本科',18000,0,'411522198009130002','广东深圳'),
('76215','张三','数据开发工程师','男',24,'本科',18000,0,'411522198009130002','广东深圳'),
('76216','张三','数据开发工程师','男',24,'本科',18000,0,'411522198009130002','广东深圳'),
('76217','张三','数据开发工程师','男',24,'本科',18000,0,'411522198009130002','广东深圳'),
('76218','张三','数据开发工程师','男',24,'本科',18000,0,'411522198009130002','广东深圳'),
('76219','张三','数据开发工程师','男',24,'本科',18000,0,'411522198009130002','广东深圳'),
('762020','张三','数据开发工程师','男',24,'本科',18000,0,'411522198009130002','广东深圳');
# 查看数据
select * from tb_staff;
5. 使用命令完成:
(1)新建一个数据库班级db_hw4,设定编码为utf8;
(2)在该库中,新建一个默认使用innodb引擎的user表,字段信息有编号、用户名、密码、年龄、性别、昵称、邮箱号等;
(3)建表时有这些约束:
a.编号id为主键且自动增长不为空;
b.用户名username不为空且唯一;
c.密码password若不设定则默认为123456;
d.年龄age;
e.性别gender若不设定则默认为男;
f.昵称nickname、邮箱号email不为空;
(4)在满足约束条件的情况下,给user表先单独添加1条数据,然后再一次性添加4条数据;
(5)修改id=1的这条数据的密码为helloboy,且昵称更改为"张大仙的小迷妹";
(6)删除id为5的这条数据。
# 创建库
create database db_hw4 charset utf8;
# 使用库
use db_hw5;
# 创建表/添加约束
create table user(
id int primary key auto_increment not null ,
username varchar(20) unique not null ,
password varchar(20) default '123456',
age int,
# sex 性; gender 性别
gender varchar(10) default '男',
nickname varchar(20),
email varchar(20) not null
) engine = InnoDB default charset utf8;
# 插入数据1-4
insert into user(username, age, nickname, email) values('hello1',24,'helloworld','123456@qq.com');
insert into user(username, password, age, gender, nickname, email) values('hello2','666999',35,'女','python123','amy@163.com');
insert into user(username, password, age, gender, nickname, email) values('hello3','666999',24,'女','python123','amy@163.com');
insert into user(username, password, age, gender, nickname, email) values('hello4','666999',18,'男','python123','amy123@163.com');
insert into user(username, password, age, gender, nickname, email) values('hello5','666999',28,'女','python123','amy345@163.com');
# 修改
update user set password='helloboy',nickname='张大仙的小迷妹' where id=1;
# 删除
delete from user where id=5;
6.使用命令完成:
(1)在数据库班级db_hw4中的user表下完成查询操作;
(2)查询用户表中的所有用户数据信息;
(3)仅查询用户名、昵称、邮箱号这几个字段的数据信息;
(4)查询年龄在20-30之间的所有用户信息;
(5)查询编号为1、3、5的用户信息。
考察知识点
-
简单查询
-
比较查询
-
范围查询
# 使用数据库
use db_hw4;
# 2
select * from user;
# 3
select username,nickname,email from user;
# 4
select * from user;
select * from user where age between 20 and 30;
# 5
select * from user where id in (1,3,5);
7. 请使用命令完成:[对上一次作业的员工表做操作]
(1)给员工表添加一个密码字段;
(2)给员工表的密码字段都设定为123456;
(3)把员工编号为5的员工的工号、性别、学历分别修改为SZ32001、男、大专;
(4)因员工表中编号为11和编号为13已离职,请删除对应的员工数据。
考察知识点
-
修改数据
-
删除数据
# 添加密码字段
alter table tb_staff add password varchar(20);
desc tb_staff;
# 设定值
update tb_staff set password='123456'; # 字符串
# update tb_staff set password=666999; # 默认字符串可以添加整数型,不推荐 [数据不准确]
# 修改数据
update tb_staff set sno='SZ32001',sex='男2',education='大专' where id=5;
# 删除数据
delete from tb_staff where id=11;
delete from tb_staff where id=13;
8.按照下列要求完成DML操作:
(1)创建一个数据库db_hw5,并设置默认编码格式为utf-8;
(2)在该库中创建一个student表,字段有编号、学号、姓名、语文成绩、英语成绩、数学成绩等;
(3)对于这些字段,要求:编号是整型且是主键并且是自动增长的,学号是字符串;
(4)给student表添加10条数据;
(5)修改id为4的这条数据的语文成绩为88,删除id为10的这条数据内容;
(6)查询表内的所有数据信息。
考察知识点
-
创建数据库
-
创建数据表
-
SQL约束
-
插入数据
-
修改数据
-
删除数据
-
快速查询数据
# 创建数据库
create database db_hw5 default character set utf8;use db_hw5;
# 创建数据表+字段+约束
create table student(
id int primary key auto_increment not null,
stuno varchar(20),
name varchar(20),
chinese double,
english double,
math double
);# 添加数据
INSERT INTO student(id, stuno,name, chinese, english, math)
VALUES (1, '20210908001','张王明', 89, 78, 90),
(2, '20210908002', '李进', 67, 53, 95),
(3, '20210908003', '王俊', 87, 78, 77),
(4, '20210908004', '李云云', 80, 98, 92),
(5, '20210908005', '谢来财', 82, 84, 67),
(6, '20210908006', '张进宝', 55, 85, 89),
(7, '20210908007', '黄蓉儿', 79, 86, 90),
(8, '20210908008', '刘小雪', 71, 90, 91),
(9, '20210908009', '夏金章', 89, 91, 96),
(10, '20210908010', '杨洋', 83, 65, 90);# 修改数据
update student set chinese = 88 where id = 4;
# 删除数据
delete from student where id = 10;
# 查询数据
select * from student;
9. 按照下列要求完成DQL的下列操作:
(1)查询表中所有学生的信息;
(2)查询表中所有学生的姓名和对应的英语成绩;
(3)过滤数据表中,语文成绩值的重复数据;
(4)统计每个学生的总分;
(5)在所有学生总分数上加10分特长分;
(6)查询英语成绩大于90分的同学;
(7)查询总分大于200分的所有同学;
(8)查询英语分数在 80-90之间的同学;
(9)查询英语分数不在 80-90之间的同学;
(10)查询数学分数为89,90,91的同学;
(11)查询所有姓李的学生英语成绩;
(12)查询数学分80并且语文分80的同学;
(13)查询英语80或者总分200的同学
考察知识点
-
简单查询
-
where条件查询
# 切换使用数据库
use db_hw5;# 查询表中所有学生的信息;
select * from student;# 查询表中所有学生的姓名和对应的英语成绩;
select name,english from student;# 过滤数据表中,语文成绩值的重复数据;
select distinct chinese from student;# 统计每个学生的总分;
select name,(chinese+english+math) from student;# 在所有学生总分数上加10分特长分;
select name,(chinese+english+math)+10 from student;# 查询英语成绩大于90分的同学;
select name from student where english > 90;# 查询总分大于200分的所有同学;
select name from student where (chinese+english+math)>200;# 查询英语分数在 80-90之间的同学;
select name from student where english between 80 and 90;# 查询英语分数不在 80-90之间的同学;
select name from student where english not between 80 and 90;# 查询数学分数为89,90,91的同学;
select * from student where math in (89,90,91);# 查询所有姓李的学生英语成绩;
select name,english from student where name like '%李%';# 查询数学分80并且语文分80的同学;
select * from student where math = 80 and chinese = 80;# 查询英语80或者总分200的同学。
select * from student where english = 80 or (chinese+english+math)=200;
10. 我们知道,一本书籍要关联出版社,此时多本书可以出自同一个出版社,一个出版社也可以出版多本书。
(1)根据书籍与出版社的关系,设计【书籍-出版社】一对多的关联表;
(2)试着给数据表添加对应的数据值;
(3)查询出清华大学出版社出版的所有图书信息;
(4)查询出《MySQL从入门到精通》书籍的出版社信息。
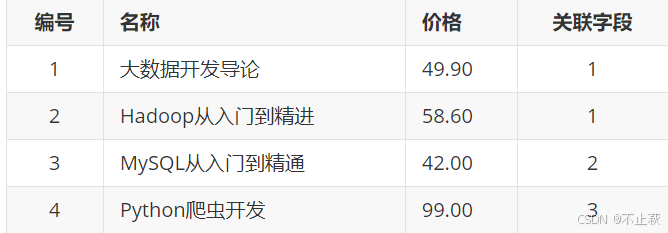
书籍
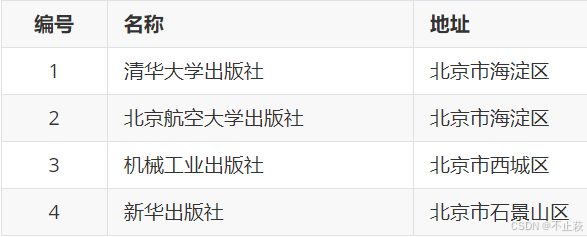
出版社
考察知识点
-
一对多关系
-
子查询
# 创建数据库
create database if not exists db_hw6 charset utf8;
# 使用库
use db_hw6;# 创建表:出版社表
create table tb_press(
pid int primary key auto_increment,
pname varchar(20),
paddress varchar(40)
) engine = InnoDB default charset utf8;# 创建表:书籍表
create table tb_book(
bid int primary key auto_increment,
bname varchar(20),
bprice double,
press_id int,
foreign key(press_id) references tb_press(pid)
) engine = InnoDB default charset utf8;# 查看表结构
desc tb_press;
desc tb_book;# 添加数据
insert into tb_press(pname, paddress) values ('清华大学出版社','北京市海淀区');
insert into tb_press(pname, paddress) values ('北京航空大学出版社','北京市海淀区');
insert into tb_press(pname, paddress) values ('机械工业出版社','北京市西城区');
insert into tb_press(pname, paddress) values ('新华出版社','北京市石景山区');insert into tb_book(bname, bprice, press_id) values ('大数据开发导论',49.90,1);
insert into tb_book(bname, bprice, press_id) values ('Hadoop从入门到精进',58.60,1);
insert into tb_book(bname, bprice, press_id) values ('MySQL从入门到精通',42.00,2);
insert into tb_book(bname, bprice, press_id) values ('Python爬虫开发',99.00,3);# 查询出清华大学出版社出版的所有图书信息
select *
from
tb_book
where
press_id = (
select
pid
from
tb_press
where
pname = '清华大学出版社'
);
# 查询出《MySQL从入门到精通》书籍的出版社信息
select
*
from tb_press
where pid = (
select
press_id
from tb_book
where bname = 'MySQL从入门到精通'
);


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









