






一、引言
-
分类分析是机器学习和数据挖掘中的核心技术之一,它涉及将数据分配到两个或多个类别或类别中。这种分析对于理解数据模式、预测结果以及支持决策制定至关重要。以下是分类分析的几个重要性方面:
-
决策支持:分类模型可以帮助企业基于历史数据做出更明智的决策,例如,信用评分、风险评估和客户细分。
-
预测分析:在许多领域,如金融市场分析、天气预测和医疗诊断,分类分析被用来预测未来事件的可能性。
-
客户关系管理:通过分类分析,企业可以更好地了解客户偏好,从而提供个性化的服务和产品推荐。
-
欺诈检测:分类模型被广泛用于信用卡欺诈检测、网络安全和保险索赔分析,以识别异常行为和潜在的欺诈行为。
-
自动化处理:在制造业和物流行业,分类分析可以帮助自动化质量控制和优化供应链流程。
-
增强用户体验:在推荐系统中,分类分析可以用于将用户分组,以便提供更加定制化的用户体验。
二、K近邻算法(K-Nearest Neighbors, KNN)
基本原理
K近邻算法(KNN)是一种经典的机器学习算法,用于分类和回归任务。它的基本思想非常简单直观:在特征空间中,一个数据点的类别由其周围邻居的类别决定。对于分类问题,KNN算法通过测量不同特征值之间的距离来预测新数据点的类别。
分类过程
1、距离度量:首先,KNN算法需要一个距离度量来计算数据点之间的相似度。常用的距离度量包括欧氏距离、曼哈顿距离和闵可夫斯基距离。欧氏距离是最常用的度量,它测量两点之间的直线距离。
2、寻找最近邻居:给定一个新的数据点,算法会在训练数据集中寻找与其最近的k个邻居。这些邻居是基于距离度量确定的。
3、投票或平均:对于分类问题,KNN算法通常使用多数投票法来决定新数据点的类别。也就是说,k个最近邻居中出现次数最多的类别将被赋予新数据点。对于回归问题,算法可能会取k个最近邻居的目标值的平均值。
代码示例
这里提供一个使用Python的scikit-learn库实现的K近邻(KNN)算法的简单代码示例。在这个例子中,我们将使用著名的鸢尾花(Iris)数据集来进行分类
- 导入必要的库:
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import classification_report, accuracy_score
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
import numpy as npdatasets:用于加载标准数据集。train_test_split:用于将数据集分割为训练集和测试集。KNeighborsClassifier:KNN分类器。classification_report和accuracy_score:用于评估模型性能。matplotlib.pyplot:用于数据可视化。StandardScaler:用于特征缩放。numpy:用于数据处理。- 加载数据集:
iris = datasets.load_iris()
X = iris.data
y = iris.target- 加载鸢尾花数据集,并将特征赋值给
X,将标签赋值给y。 - 划分训练集和测试集:
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)- 使用
train_test_split将数据集分为训练集和测试集,其中20%作为测试集,80%作为训练集,random_state用于确保结果的可重复性。
创建KNN模型:
knn = KNeighborsClassifier(n_neighbors=3)- 创建一个KNN分类器实例,设置邻居数为3。
训练模型:
knn.fit(X_train, y_train)- 使用训练集数据训练KNN模型。
进行预测:
y_pred = knn.predict(X_test)- 使用训练好的模型对测试集进行预测。
评估模型:
print("Classification Report:")
print(classification_report(y_test, y_pred))
print("Accuracy:", accuracy_score(y_test, y_pred))- 使用
classification_report和accuracy_score评估模型性能,输出分类报告和准确率。
1.KNN算法的优点
精度高:在许多实际应用中,KNN算法能够取得很好的分类效果,尤其是在数据集较大且特征空间不是非常高维时。
对异常值不敏感:由于KNN是基于局部邻域的算法,单个异常点对分类结果的影响有限。
无需训练:KNN不需要在训练阶段构建模型,因此训练过程简单快速。
易于理解和实现:KNN算法的原理直观易懂,且容易实现。
可用于回归和分类:KNN不仅可以用于分类任务,还可以通过取最近邻的平均值来用于回归任务。
2.KNN算法的缺点
计算复杂度高:在预测阶段,KNN需要计算待分类点与所有训练数据点之间的距离,这在大数据集上可能导致较高的计算成本。
空间复杂度高:KNN需要存储整个数据集,这可能导致较高的存储成本。
对不平衡数据敏感:如果数据集中的类别分布不均匀,KNN可能会倾向于预测出现次数较多的类别。
对特征尺度敏感:KNN对特征的尺度非常敏感,因此通常需要进行特征缩放或标准化。
选择最优的K值困难:K值的选择对模型性能有很大影响,但找到最优的K值可能需要大量的实验和验证。
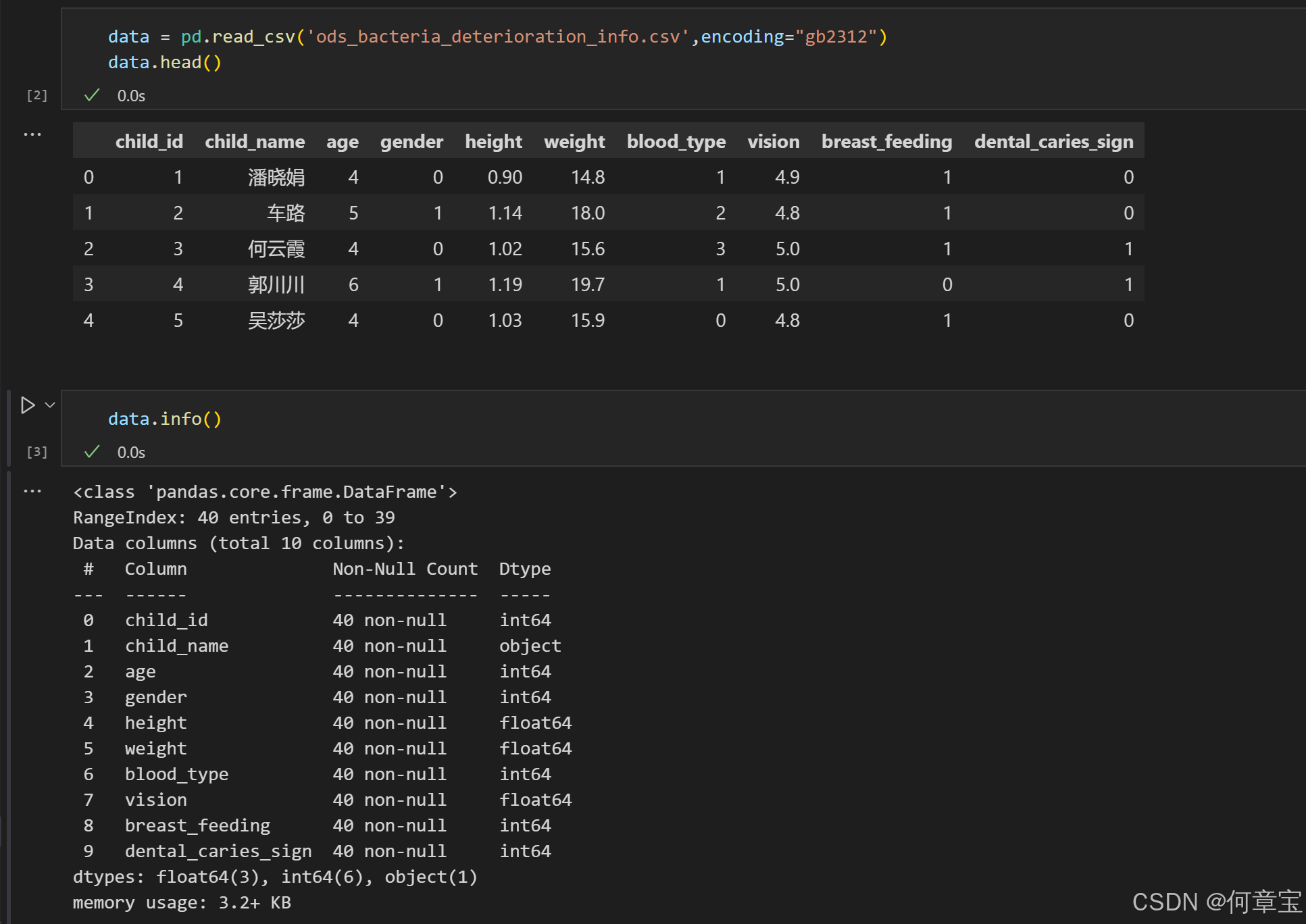
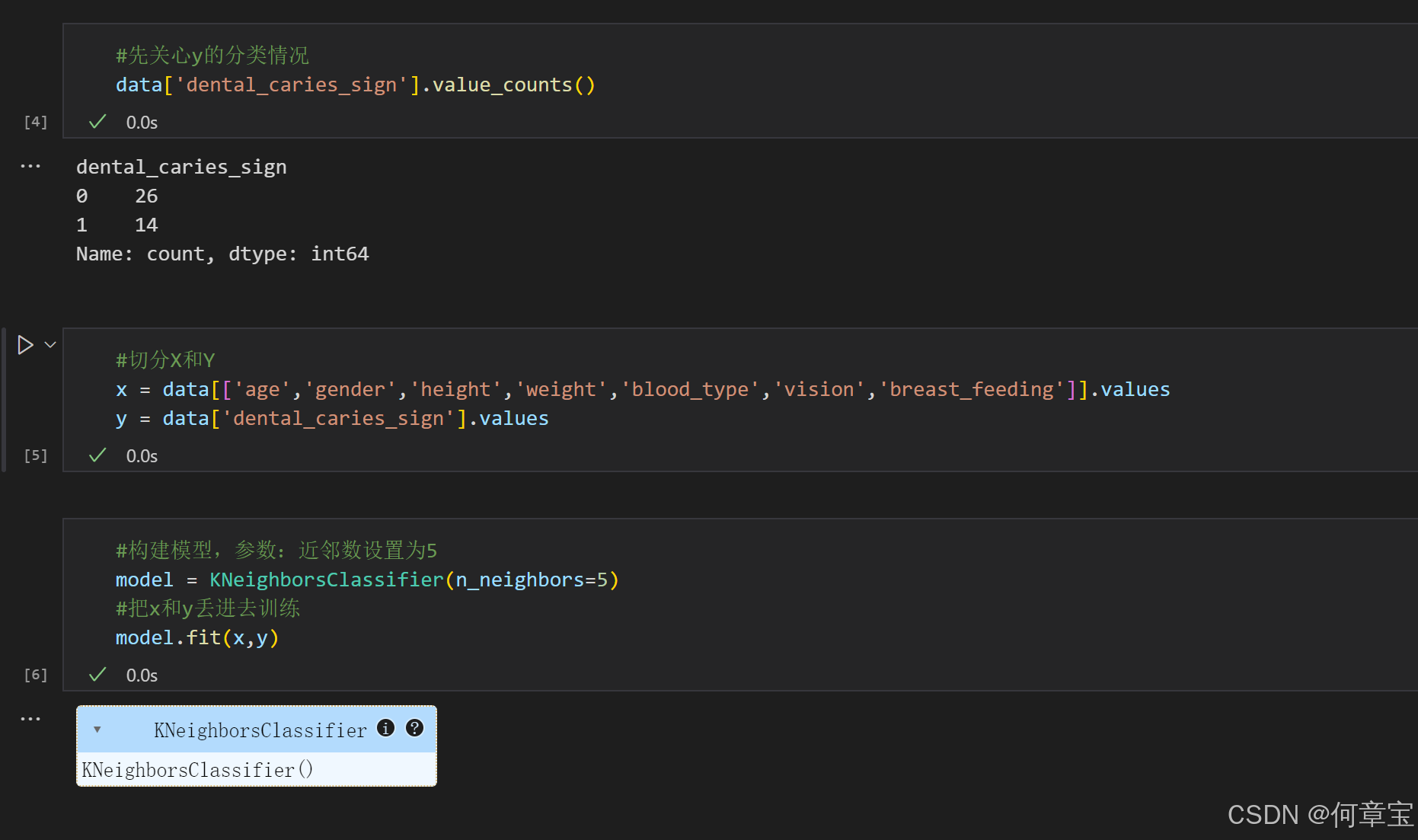
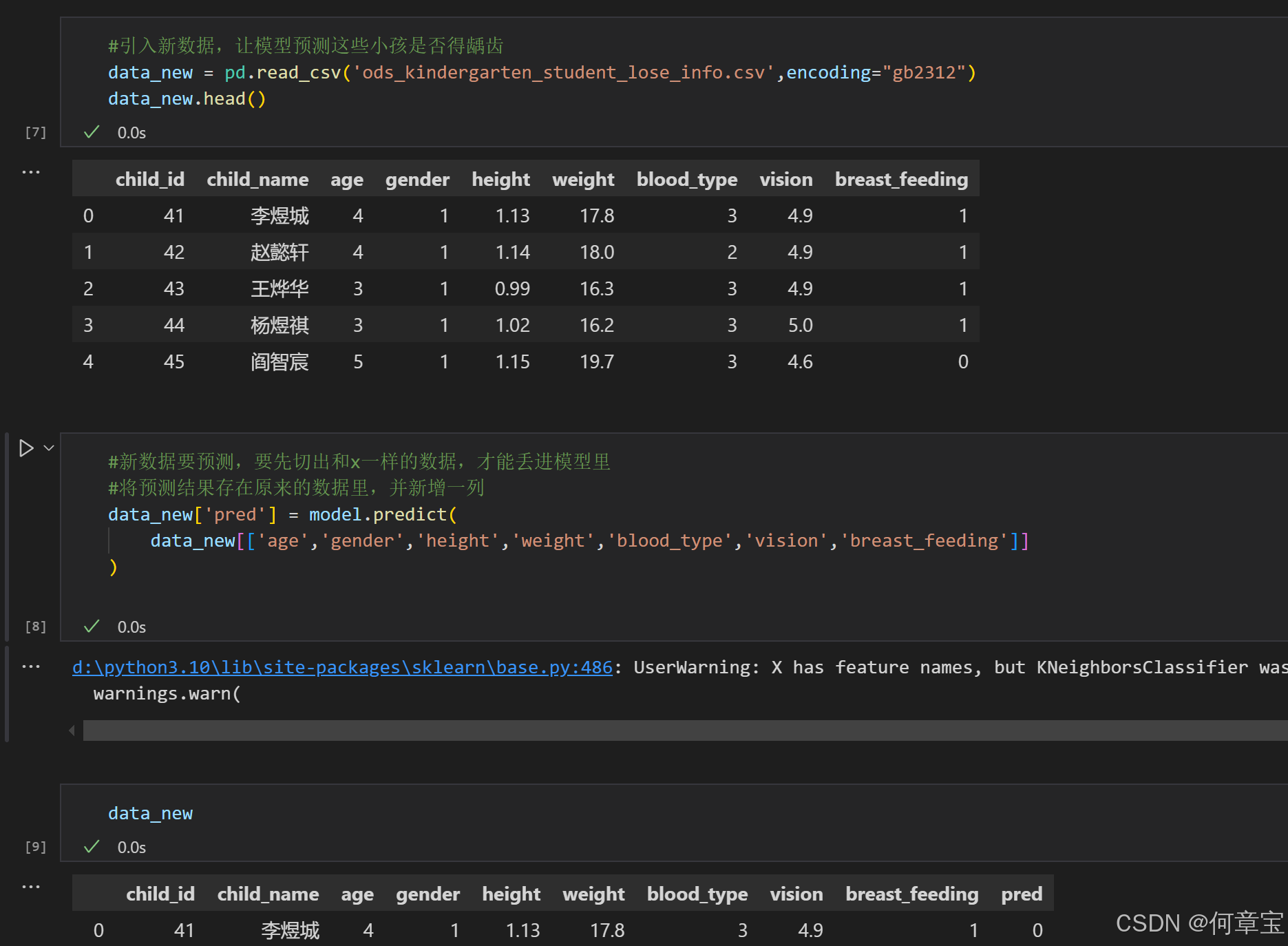
实战演练:
三、决策树(Decision Tree)
基本原理
决策树的基本概念
决策树是一种模仿人类决策过程的分类(或回归)模型。它由节点、分支和叶子组成:
节点(Node):决策树中的每个点代表一个决策规则或属性测试。
分支(Branch):从一个节点延伸出的线表示不同的决策路径,称为分支。
叶子(Leaf):树的末端节点,代表最终的决策或分类结果。
决策树如何工作
决策树通过递归地选择最优的属性作为节点,根据该属性的不同值将数据集分割成子集,直到满足某个停止条件(如所有数据点都属于同一类别,或达到最大深度)。这个过程从根节点开始,向下扩展到叶子节点。
信息增益
信息增益是基于熵的概念,用于度量数据的不纯度。熵越高,数据的不纯度越大。信息增益定义为分割数据集前后熵的差值,即:
信息增益=熵(S)−∑i=1n∣Si∣∣S∣熵(Si)信息增益=熵(S)−∑i=1n∣S∣∣Si∣熵(Si)
其中,SS 是原始数据集,SiSi 是根据属性AA分割后的数据集,nn是分割后的子集数量。
基尼指数
基尼指数是另一种度量数据不纯度的方法,它的值范围从0到1。基尼指数越低,表示数据集的纯度越高。对于一个数据集,基尼指数定义为:
基尼指数=1−∑j=1mpj2基尼指数=1−∑j=1mpj2
其中,mm 是类别的数量,pjpj 是选择第jj个类别的概率。
选择最优分裂点
在构建决策树时,算法会计算每个可能的分裂点(属性和阈值)的信息增益或基尼指数,并选择使信息增益最大或基尼指数最小的分裂点作为最优分裂点。这个过程递归地进行,直到满足停止条件,最终生成决策树。
简而言之,决策树通过选择能够最有效地分割数据集的属性作为节点,递归地构建树结构,以最小化树的不纯度。信息增益和基尼指数是两种常用的方法,用于评估分裂点的质量。
代码示例
# 导入必要的库
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 加载数据集
iris = load_iris()
X = iris.data
y = iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建决策树模型
dt = DecisionTreeClassifier(random_state=42)
# 训练模型
dt.fit(X_train, y_train)
# 进行预测
y_pred = dt.predict(X_test)
# 评估模型
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy}")决策树算法的优点
1. **直观易懂**:结构清晰,类似于人类的决策过程。
2. **处理非线性**:能够自然地处理非线性关系,无需特征转换。
3. **无需特征缩放**:对特征的量纲和范围不敏感。
4. **适应性强**:可以处理数值型和类别型数据,适用于分类和回归问题。
决策树算法的缺点
1. **容易过拟合**:可能导致模型在训练集上表现很好,但在新数据上表现差。
2. **对缺失数据敏感**:需要额外处理缺失值,否则可能影响树的构建。
3. **可能不稳定**:小的变化在数据中可能导致完全不同的树结构。
4. **忽略特征**:可能会忽略一些对预测结果影响不大的特征。
四、随机森林(Random Forest)
基本原理
随机森林是一种集成学习方法,它通过组合多个决策树来提高分类或回归任务的准确性和鲁棒性。每个决策树在训练时都会随机选择样本和特征,这增加了模型的多样性,有助于减少过拟合。
如何提高分类精度
集成多个决策树:随机森林由多个决策树组成,每棵树都在随机选择的数据集上训练。
随机选择样本:每棵树的训练使用随机选择的样本子集(有放回抽样),这称为自助采样(bootstrap sampling)。
随机选择特征:在寻找每个分裂点时,只考虑随机选择的特征子集,而不是所有特征。
投票或平均:对于分类问题,随机森林通过多数投票的方式确定最终的类别;对于回归问题,则计算所有树的预测结果的平均值。
代码示例(由于随机森林是决策树的集成学习方法,代码与决策树类似,但需要使用RandomForestClassifier类)
# 导入必要的库
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 加载数据集
iris = load_iris()
X = iris.data
y = iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建随机森林模型
rf = RandomForestClassifier(n_estimators=100, random_state=42)
# 训练模型
rf.fit(X_train, y_train)
# 进行预测
y_pred = rf.predict(X_test)
# 评估模型
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy}")随机森林和决策树的关系是,随机森林是由多个决策树组成的集成学习模型。每个决策树在随机森林中独立构建,并且在构建过程中引入随机性来提高整体模型的性能和鲁棒性。
关系和区别
- 关系:随机森林是建立在决策树基础上的,它通过组合多个决策树的预测结果来改善分类或回归任务的性能。
- 区别:
- 单一决策树:容易受到训练数据中噪声和异常值的影响,可能导致过拟合。
- 随机森林:通过集成多个决策树来减少过拟合,提高模型的泛化能力。
随机森林算法的优点
- 提高分类精度:随机森林通过集成多个决策树的结果,通常能比单一决策树获得更高的分类精度。
- 减少过拟合:随机选择样本和特征的方法减少了模型对训练数据的依赖,从而降低了过拟合的风险。
- 适用性广:随机森林可以处理分类和回归问题,适用于各种数据类型,并且不需要特征缩放。
- 特征重要性评估:随机森林能够评估各个特征对预测结果的影响程度。
随机森林算法的缺点
- 计算量大:构建和训练大量的决策树可能导致计算量大,尤其是在大数据集上。
- 模型复杂:随机森林模型比单一决策树更复杂,可能更难解释。
- 内存消耗:由于需要存储多棵树,随机森林可能会占用更多的内存空间。
- 可能欠拟合:如果树的数量不够或每棵树过于简单,随机森林可能会出现欠拟合的情况。
五、朴素贝叶斯(Naive Bayes)
基本原理
朴素贝叶斯分类分析是一种基于贝叶斯定理和特征条件独立假设的分类方法。它假设在给定类别的情况下,各个特征之间相互独立,从而简化了计算过程。这种方法常用于文本分类、垃圾邮件检测等领域。
后验概率的计算与分类
朴素贝叶斯分类分析通过以下步骤计算后验概率并进行分类:
计算先验概率:对于每个类别,计算训练数据集中属于该类别的样本所占的比例。
计算条件概率:在特征相互独立的假设下,计算每个特征在每个类别下出现的概率。
应用贝叶斯定理:结合先验概率和条件概率,利用贝叶斯定理计算给定样本属于每个类别的后验概率。
选择最高概率的类别:比较不同类别的后验概率,选择后验概率最大的类别作为样本的分类结果。
总之,朴素贝叶斯分类分析通过计算后验概率,在特征条件独立的假设下,实现了对样本的有效分类。
代码示例
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import accuracy_score
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data # 特征矩阵
y = iris.target # 目标变量(类别标签)
# 将数据集拆分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 创建朴素贝叶斯分类器(高斯朴素贝叶斯)
gnb = GaussianNB()
# 使用训练集训练分类器
gnb.fit(X_train, y_train)
# 使用测试集进行预测
y_pred = gnb.predict(X_test)
# 计算并打印准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"准确率: {accuracy:.2f}")朴素贝叶斯算法的优点
1. **简单高效**:计算和预测速度快,适合处理大规模数据。
2. **适合高维数据**:对特征数量不敏感,表现稳定。
3. **可解释性强**:基于概率论,模型的预测过程容易理解。
朴素贝叶斯算法的缺点
1. **特征独立性假设**:现实中特征往往不独立,这可能影响模型的准确性。
2. **对数据分布有要求**:假设数据遵循特定分布,如高斯分布,实际数据分布不符时性能可能下降。
3. **对类别不平衡敏感**:在类别分布不均匀的数据集中,模型可能偏向于多数类。
六、总结与展望
算法总结
K近邻(KNN):
- 原理:通过特征空间中的距离度量进行分类。
- 优点:直观,实现简单。
- 缺点:计算成本高,对大数据集不友好。
- 适用场景:小规模数据集,特征空间维度较低。
决策树:
- 原理:通过递归划分特征空间构建树模型。
- 优点:易于理解和解释。
- 缺点:容易过拟合,对噪声敏感。
- 适用场景:需要模型解释性的场景。
随机森林:
- 原理:集成多个决策树以提高稳定性和准确性。
- 优点:减少过拟合,提高泛化能力。
- 缺点:模型复杂,计算量大。
- 适用场景:大规模数据集,需要高准确性的场景。
朴素贝叶斯:
- 原理:基于贝叶斯定理,假设特征条件独立。
- 优点:计算简单,适用于高维数据。
- 缺点:特征独立性假设往往不成立。
- 适用场景:文本分类,垃圾邮件检测。
未来趋势
- 算法可解释性:提高模型的透明度和可信度。
- 深度学习集成:结合深度学习提高分类性能。
- 自动化特征工程:减少手动特征处理的工作量。
- 多模态学习:处理和结合来自不同源的数据。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









