







决策树是一种直观、易于理解的监督学习方法,广泛用于分类和回归任务。其基本思想类似于人们在做决策时依次筛选特征、根据条件判断的过程。本文将从决策树的基本原理开始,详细讲解如何构建、剪枝与调优决策树模型,并通过Python代码进行实例讲解,让你轻松上手!
首先再明确几个概念:
监督学习:是一种机器学习方法,在这种方法中,我们拥有带标签的训练数据。也就是说,每个训练样本都有输入数据和对应的正确输出(标签)。模型通过学习这些输入与输出之间的映射关系,从而在遇到新数据时能够预测或判断其对应的输出。
分类:是一种监督学习任务,其目标是将数据样本分配到预定义的类别中。分类问题的输出通常是离散的类别标签,例如“猫”、“狗”、“鸟”或者“垃圾邮件”、“正常邮件”。
回归:是一种监督学习任务,其目标是预测连续数值。与分类不同,回归问题的输出不是离散的类别,而是连续的数值,比如房价、温度、股票价格等。
目录
一、决策树初体验:生活中的树形决策
想象你站在水果摊前挑选西瓜,你的决策过程可能是这样的:
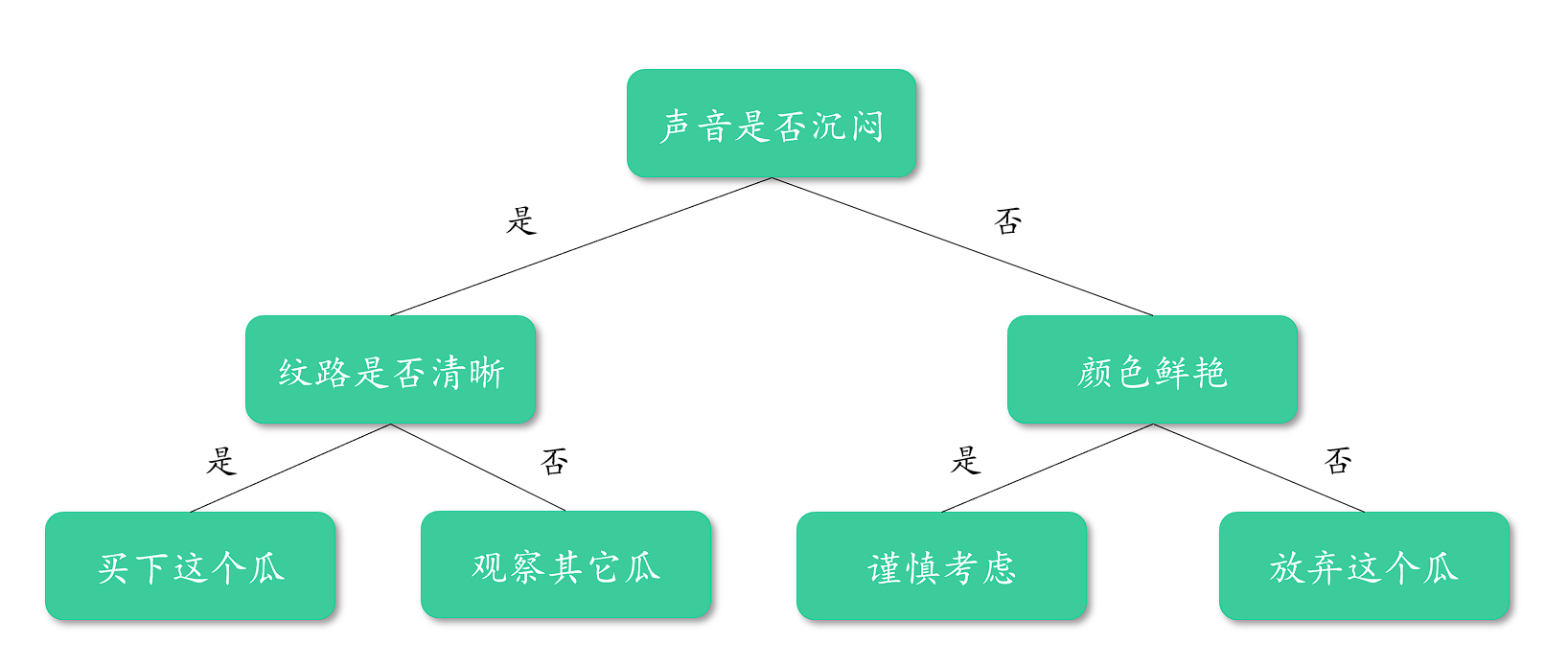
这正是决策树的核心思想!通过一系列特征判断,最终得出结论。在机器学习中,决策树通过递归地将数据分割成更纯净的子集来完成分类或回归任务。
二、决策树基本原理
决策树是一种树形结构,每个内部节点代表一个特征的判断条件,每个分支代表一个判断结果,每个叶子节点则对应最终的类别或回归值。主要步骤包括:
-
特征选择: 根据某种评价指标(例如信息增益、基尼系数)选择最优分裂特征。
-
节点划分: 分割数据集,对数据集按照所选特征的不同取值进行划分。
-
终止条件: 递归建树,当所有样本属于同一类别,或达到预设树深度、样本数阈值时停止分裂。
-
剪枝: 为防止过拟合,采用预剪枝或后剪枝对树进行修剪。
这种结构不仅具有良好的解释性,而且在许多实际场景中效果优异。
三、构造决策树的核心思想
在构建决策树时,如何选择分裂节点非常关键。常用的方法包括下面3个
3.1 信息增益(Information Gain)
简单来说,可以把信息增益想象成“问问题后,困惑减少了多少”。用来衡量使用某一特征进行划分后系统的不确定性降低了多少。
在决策树中,每个节点都面临着“如何分开数据”的问题。
当你选择一个特征来分割数据时,就像问了一个问题:“这个特征是不是某个特定值?”
信息增益就是衡量这个问题回答后,我们对数据不确定性的减少程度。
数值越大,说明这个问题(特征)能让我们更清晰地把数据分开,也就是能让决策更明朗。
信息增益计算,需要使用信息熵:
3.2 基尼指数(Gini Impurity)
基尼指数就像是在衡量“混合程度”。表示随机选取一个样本,其类别与实际类别不一致的概率,值越小越纯。
想象你有一个装满不同颜色小球的盒子。如果盒子里全是同一种颜色,那么随机抽一个球,你几乎肯定能猜中颜色;反之,如果颜色混得很均匀,那么你的猜测就容易错。
基尼指数用来表示一个节点中样本的混乱程度,数值越低,说明节点中大部分样本属于同一类(纯度越高);数值越高,说明样本分布越混乱。
在构造决策树时,我们希望每次分裂后,每个子节点中的数据尽可能“纯”,也就是让基尼指数越小越好。
基尼指数计算公式:
3.3 增益率(Gain Ratio)
增益率可以看作是对信息增益的“公平调整”。通过对信息增益做了归一化处理,防止倾向于取值较多的特征。
问题在于,信息增益有时会偏爱那些取值很多的特征,因为这类特征在分割数据时可以让数据看起来“分得很细”,从而计算出较高的信息增益。但实际上,这些特征可能并不真正有助于做出正确的决策。
增益率的做法就是:在计算完信息增益后,再将其除以该特征本身固有的信息量(也就是该特征的“分裂情况”),以此来抵消取值很多所带来的优势。
增益率对信息增益进行归一化调整,其公式为:
其中,分裂信息(Split Information)的计算公式为:
这样一来,增益率能更公正地评价每个特征,帮助我们选择既能大幅降低困惑,又不偏向于取值特别多的特征作为分裂节点。
在实际操作中,根据数据特点选择合适的指标至关重要。
四、决策树python代码示例
为了便于讲解,下面我们以一个简单的数据集为例。假设有如下特征和目标变量:
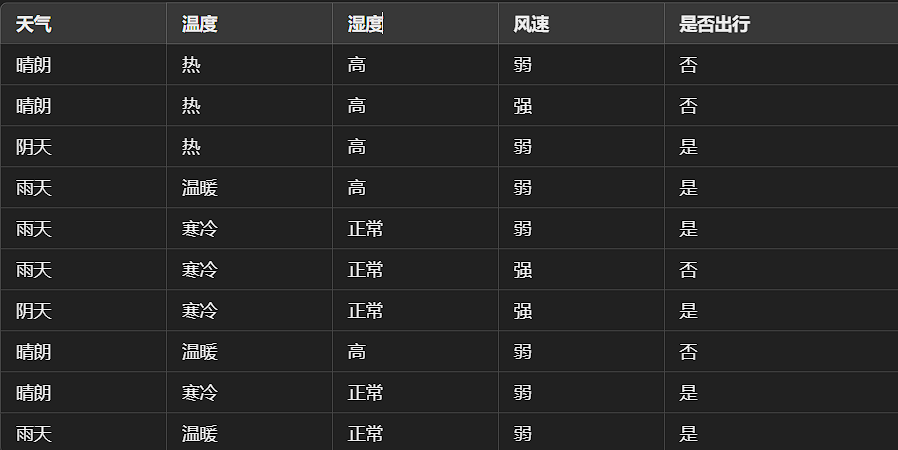
这样的数据集非常适合用于演示如何根据不同特征构造决策树。
下面我们通过Python代码来实现一个简单的决策树分类器。这里使用了 scikit-learn 库中的 DecisionTreeClassifier,并结合示例数据进行讲解。
# 导入必要的库
import numpy as np
import pandas as pd
from sklearn.tree import DecisionTreeClassifier, export_graphviz
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report
import graphviz
# 构造示例数据集
data = {
'天气': ['晴朗', '晴朗', '阴天', '雨天', '雨天', '雨天', '阴天', '晴朗', '晴朗', '雨天'],
'温度': ['热', '热', '热', '温暖', '寒冷', '寒冷', '寒冷', '温暖', '寒冷', '温暖'],
'湿度': ['高', '高', '高', '高', '正常', '正常', '正常', '高', '正常', '正常'],
'风速': ['弱', '强', '弱', '弱', '弱', '强', '强', '弱', '弱', '弱'],
'是否出行': ['否', '否', '是', '是', '是', '否', '是', '否', '是', '是']
}
df = pd.DataFrame(data)
# 打印原始数据集
print("原始数据集:")
print(df)
# 初始化编码器字典
encoders = {}
# 对每一列数据进行标签编码并保存映射关系
print("\n特征编码映射:")
for col in df.columns:
le = LabelEncoder()
df[col] = le.fit_transform(df[col])
encoders[col] = dict(zip(le.classes_, le.transform(le.classes_)))
print(f"{col}: {encoders[col]}")
# 分割特征和目标变量
X = df.drop('是否出行', axis=1)
y = df['是否出行']
# 分割训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
# 构建决策树模型(添加防过拟合参数)
clf = DecisionTreeClassifier(
criterion='entropy',
max_depth=3, # 限制树的最大深度
min_samples_split=2, # 节点最少需要2个样本才分裂
random_state=42
)
clf.fit(X_train, y_train)
# 在训练集和测试集上进行预测
y_train_pred = clf.predict(X_train)
y_test_pred = clf.predict(X_test)
# 打印评估结果
print("\n训练集评估:")
print(classification_report(y_train, y_train_pred, target_names=['否', '是']))
print("训练集准确率: {:.2f}".format(accuracy_score(y_train, y_train_pred)))
print("\n测试集评估:")
print(classification_report(y_test, y_test_pred, target_names=['否', '是']))
print("测试集准确率: {:.2f}".format(accuracy_score(y_test, y_test_pred)))
# 导出决策树(添加特征阈值解释)
dot_data = export_graphviz(
clf,
out_file=None,
feature_names=X.columns,
class_names=['否', '是'],
filled=True,
rounded=True,
special_characters=True,
proportion=True, # 显示比例代替样本数
impurity=False # 隐藏不纯度值
)
# 添加阈值解释说明
dot_data = dot_data.replace('<= 0.5', '= 晴朗')\
.replace('<= 1.5', '= 阴天/雨天')\
.replace('temperature <= 0.5', '温度 = 热')
# 生成并保存决策树图像
graph = graphviz.Source(dot_data)
graph.render("optimized_decision_tree", format="png", cleanup=True)
print("\n决策树已保存为 optimized_decision_tree.png")
# 显示决策树图像
graph在这段代码中,我们将 8 个数据做训练集, 2 个数据做测试集,得到准确率如下
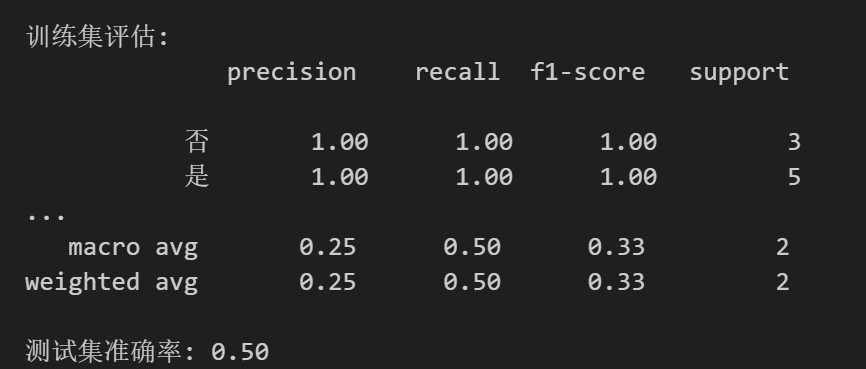
训练集准确率为 1 ,测试集准确率 0.5,也就是测试集一对一错
决策树可视化结果如下
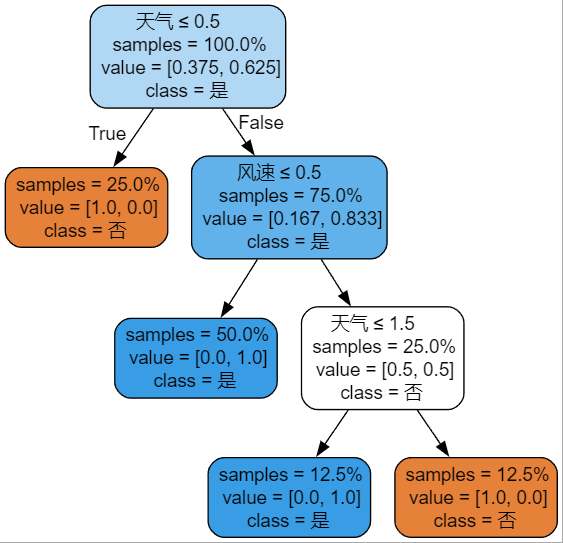
根节点:天气=晴朗
-
分裂条件:天气是否为晴朗(
天气 ≤ 0.5)。 -
样本分布:
-
训练集8个样本中,天气晴朗的样本占 25%(2个),其余天气占 75%(6个)。
-
-
分类结果:
-
天气晴朗时,100%样本分类为“否”(不出行)。
-
非晴朗天气时,83.3%样本分类为“是”(出行)。
-
关键内部节点
-
温度=热(天气晴朗分支):
-
所有样本分类为“否”,对应原始数据中天气晴朗且温度高时不出行。
-
-
风速=弱(非晴朗天气分支):
-
50%样本分类为“是”(风速弱时出行),进一步根据天气细分:
-
天气为雨天(
天气 ≤ 1.5):100%出行 -
天气为阴天:50%出行(受其他特征影响)。
-
-
叶节点示例
-
雨天+风速弱:100%出行(对应数据集中样本3、4、9)。
-
阴天+风速强:100%不出行(对应样本6)。
过拟合表现:
-
训练集完美拟合,但测试集准确率骤降至50%,表明模型过度依赖训练数据细节。
-
测试集错误案例推测:
-
测试样本可能包含“阴天+风速强”组合(原始数据中样本6分类为“是”,但模型预测为“否”)。
-
改进策略:
- 参数调整
clf = DecisionTreeClassifier(
max_depth=2, # 限制树深
min_samples_leaf=2 # 叶节点最少样本数
)-
数据增强:增加样本量(尤其测试集仅2条样本,易受随机性影响)。
-
交叉验证:使用K折交叉验证评估模型稳定性:
五、总结
通过本文的学习,我们已经基本掌握了决策树的核心原理和实战应用。接下来可以尝试调整参数观察模型变化,或者挑战更复杂的数据集。决策树作为基础算法,也是随机森林、GBDT等集成方法的基础,理解它将为后续学习打下坚实基础!
如果这篇文章对您有所启发,期待您的点赞关注!


















 244
244

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









