






I/O模型
一、阻塞 I/O 模型
进程读取数据时会一直阻塞等待,等待内核通过系统调用对数据进行处理,直到数据包到达且被复制到缓冲区或者发生错误时才返回。
二、非阻塞 I/O 模型
进程读取数据时可以通过 MSG_DONTWAIT 标志位非阻塞读,此时如果缓冲区没有数据,会直接返回一个 EAGAIN 或 EWOULDBLOCK 错误,而不会让进程一直等待。但这也意味着如果进程想要读取数据就需要不断发起读请求,直到读取到数据为止。
非阻塞 I/O 模型的特点是实现难度低,应用开发较为容易。但是进程轮询会消耗大量的 CPU 资源,不适用于并发量较大的应用。
三、I/O 复用模型
I/O 复用模型的思路就是将多个进程的 I/O 注册到一个复用器(select、poll 或 epoll)上,并由该复用器对数据读取进行监听。
以 select 为例,如果 select 监听的 I/O 在内核缓冲区都没有可读数据,select 调用进程就会被阻塞。但只要当任一 I/O 在内核缓冲区中有可读数据时,select 调用就会返回,这时 select 进程再去通知 I/O 进程读取内核中准备好的数据。
可以看到,在采用 I/O 复用模型后,尽管有多个进程注册了 I/O,但只有一个 select 进程会被阻塞。
Linux 中 I/O 复用的实现方式主要有 select、poll 和 epoll。
3.1 select
select 基于轮询的方式进行对文件描述符进行监听,因此需要在内核反复遍历传递进来的所有文件描述符,这在注册了大量 I/O 时会导致性能急剧下降。此外,每次调用 select 时都需要把文件描述符集合从用户态拷贝到内核态,这个开销在文件描述符很多时也会很大。同时 select 的监听数量也有限制。
3.2 poll
poll 与 select 一样,也是基于轮询的方式进行对文件描述符进行监听,只不过修改了文件描述符集合的结构,没有了监听数量的限制。
但是轮询监听和整体复制导致的开销问题依然没有解决。
3.3 epoll
epoll 从 Linux 2.5.44 后开始支持,底层数据结构为红黑树,增删改综合效率高。而且 epoll 模型修改主动轮询为被动通知,这里的被动通知主要指的是执行 epoll_wait() 函数后,程序会等待内核通知,而无需轮询所有的文件描述符查看状态。同时由 mmap 实现内核与用户空间的消息传递,监听数量大效率高。
四、信号驱动 I/O 模型
当进程发起一个 I/O 操作,会通过系统调用 sigaction() 或 siganal()向内核注册一个信号处理函数,然后进程返回不阻塞。当内核中有数据就绪时会发送一个信号给读取进程,读取进程会在信号处理回调函数中调用 I/O 读取数据。
信号驱动 I/O 模型基于回调机制实现,但应用开发难度较大,且实际应用较少。
五、异步 I/O 模型
当进程发起一个 I/O 操作后会告知内核处理 I/O,随后该进程直接返回不阻塞,但也不能立刻得到结果。等到内核把整个 I/O 处理完后会通知该进程,如果 I/O 操作成功则进程直接获取到数据。
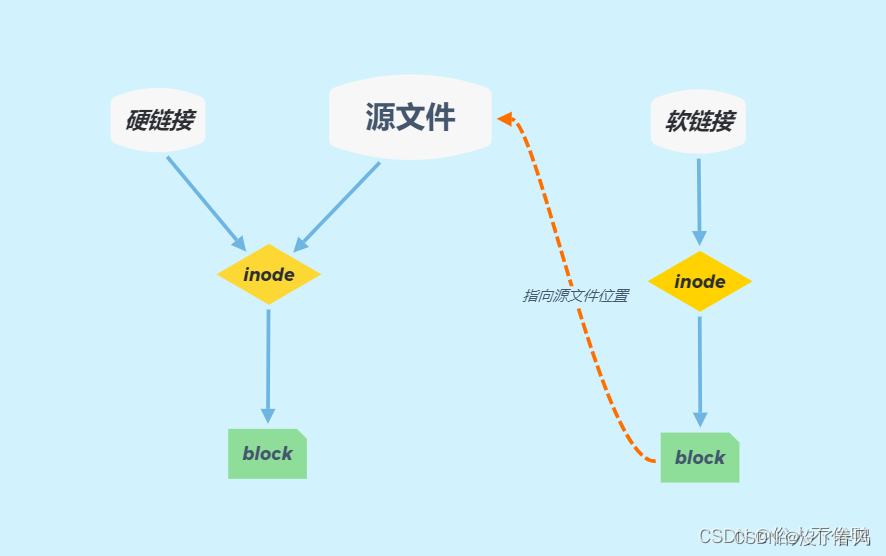
inode
inode的作用可以总结为:
- 唯一标识文件或目录:每个文件或目录都有一个唯一的inode号码,通过这个号码可以直接访问并操作对应的文件或目录。
- 存储文件元数据:包括文件的权限、拥有者、大小、时间戳、链接数等信息,但不包括文件名。
- 提升文件系统性能:文件系统通过inode来组织和管理存储空间,提高了文件系统的性能和效率。
- 硬链接:允许多个文件名指向同一个inode,这是Linux文件系统中硬链接的基础
软链接和硬链接
文件描述符
文件描述符是一个非负整数,用于唯一标识一个正在打开的文件。文件描述符是操作系统内核为每个进程维护的一种机制,它提供了一种抽象的方法来访问文件、套接字和其它I/O资源。
-
整数标识符:文件描述符是一个整数,它作为文件在进程中的唯一标识符。在大多数系统中,0、1、2分别被称为标准输入、标准输出和标准错误输出。
-
资源引用:文件描述符不仅仅用于文件,它也可以表示管道、套接字、设备和其它形式的I/O资源。
-
打开文件表:每个进程都有一个打开文件表,记录了所有当前打开的文件描述符及其状态信息。
-
系统调用:进程通过系统调用(如
open()、read()、write()等)来操作文件描述符,进行读写、定位和关闭等操作。 -
文件描述符的限制:每个进程能够打开的文件描述符数量通常受到操作系统的限制,可以通过修改操作系统的配置参数来调整这个限制。

ps:文件描述符0、1、2分别被称为标准输入、标准输出和标准错误输出,所以是从3开始;
每创建一次子进程/使用open()函数,引用计数会+1;进程每使用一次close()函数,引用计数会-1。当引用计数变为 0, 则会释放 struct file 相关的所有资源。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









