






单个视频爬取,仅学习用途
 某视频网站主页
某视频网站主页
一、数据抓包
视频点击进去之后,点击右键-检查-网络。按照大小排序,找到视频和音频的url。
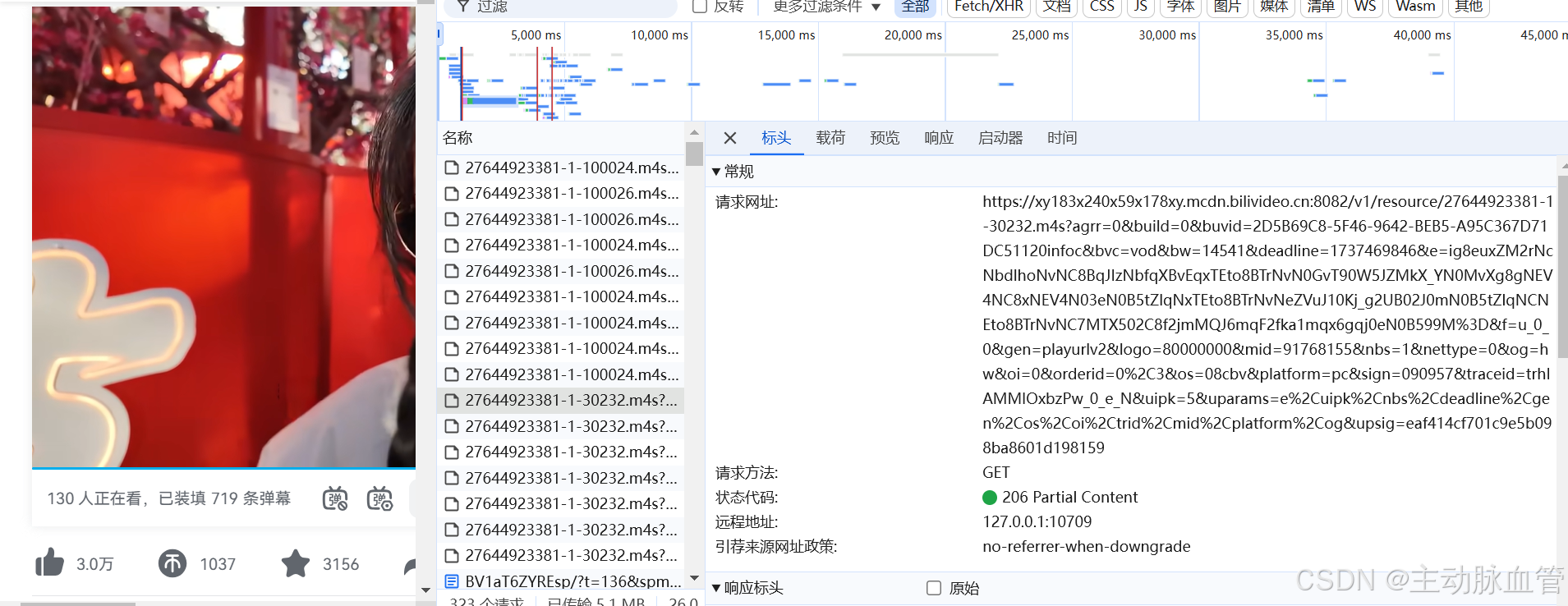
100024和30232分别对应视频和音频
二、编写爬虫代码
# 下载文件的函数
def download_file(url, file_name, headers=None):
try:
response = requests.get(url, headers=headers)
response.raise_for_status() # 检查请求是否成功
with open(file_name, 'wb') as file:
file.write(response.content)
print(f"文件已下载: {file_name}")
except Exception as e:
print(f"下载失败: {e}")
return False
return True这里合并视频借助第三方库 moviepy
# 合并视频和音频的函数
def merge_video_audio(video_path, audio_path, output_path):
try:
video = VideoFileClip(video_path)
audio = AudioFileClip(audio_path)
final_clip = video.with_audio(audio) # 将音频添加到视频
final_clip.write_videofile(output_path, codec='libx264') # 保存合并后的视频
print(f"视频已保存: {output_path}")
except Exception as e:
print(f"合并失败: {e}")
return False
return True
# 主程序
if __name__ == "__main__":
# 输入视频和音频的 URL
video_url = input("请输入视频 URL: ")
audio_url = input("请输入音频 URL: ")
# 设置请求头(模拟浏览器访问)
headers = {
"User-Agent": "用户代理",
"Referer": "某网站视频主页"
}
# 下载视频和音频
video_file = "temp_video.mp4"
audio_file = "temp_audio.mp3"
output_file = "final_video.mp4"
if download_file(video_url, video_file, headers) and download_file(audio_url, audio_file, headers):
# 合并视频和音频
if merge_video_audio(video_file, audio_file, output_file):
print("视频和音频合并成功!")
else:
print("视频和音频合并失败。")
else:
print("下载失败,请检查 URL 或网络连接。")
# 清理临时文件
if os.path.exists(video_file):
os.remove(video_file)
if os.path.exists(audio_file):
os.remove(audio_file)
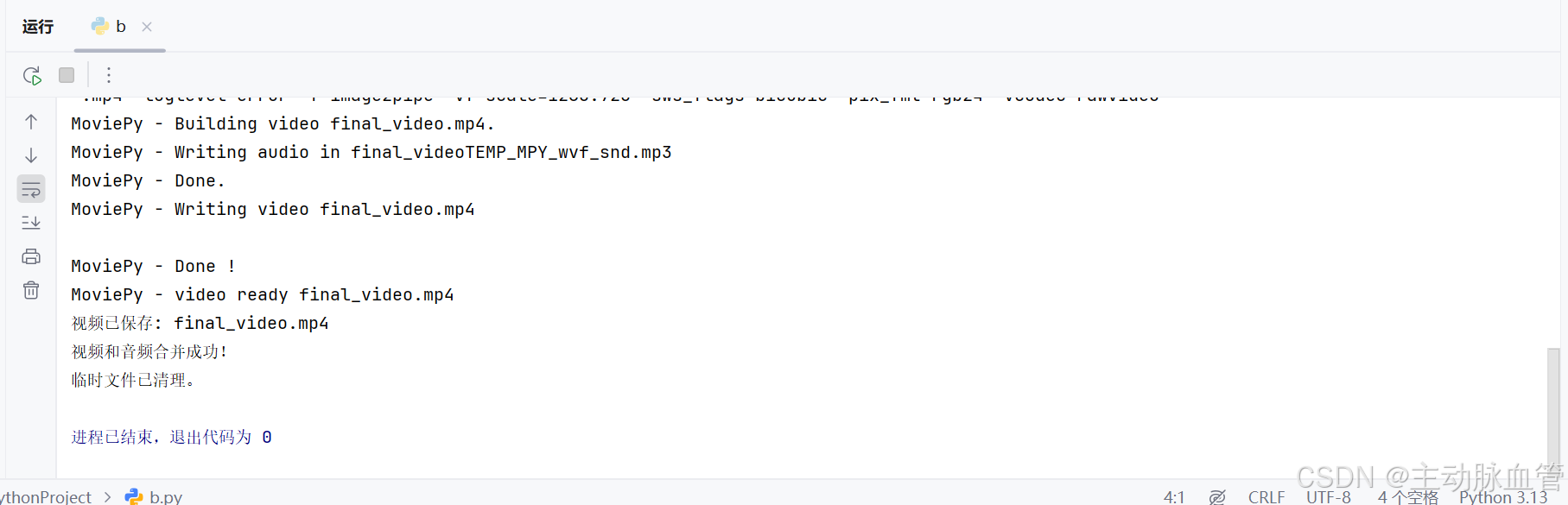
print("临时文件已清理。")三、终端输入我们第一步找到的url


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









