






二、结构化流的编程模型
1、数据结构
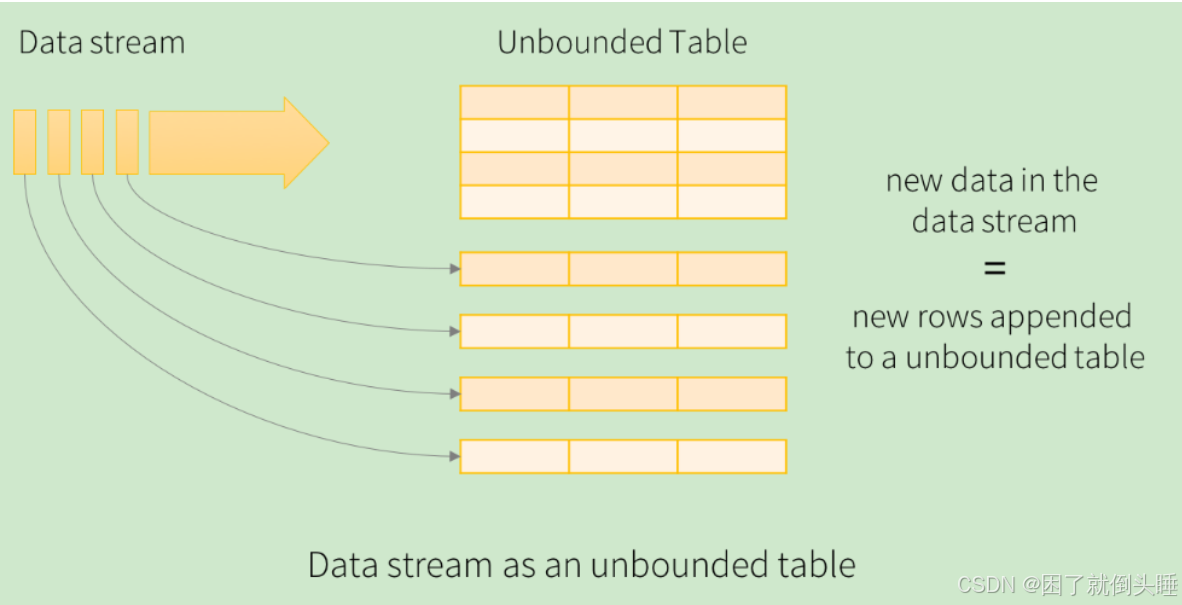
在结构化流中,我们可以将DataFrame称为无界的DataFrame或者无界的二维表
2、读取数据源
对应官网文档内容:
Structured Streaming Programming Guide - Spark 3.1.2 Documentation
结构化流默认提供了多种数据源,从而可以支持不同的数据源的处理工作。目前提供了如下数据源:
-
File Source:文件数据源。读取文件系统,一般用于测试。如果文件夹下发生变化,有新文件产生,那么就会触发程序的运行
-
Socket Source:网络套接字数据源,一般用于测试。也就是从网络上消费/读取数据
-
Rate Source:速率数据源。了解即可,一般用于基准测试。通过配置参数,由结构化流自动生成测试数据。
-
Kafka Source:Kafka数据源。也就是作为消费者来读取Kafka中的数据。一般用于生产环境。
2.1 File Source

相关的参数:
| option参数 | 描述说明 |
|---|---|
| maxFilesPerTrigger | 每次触发时要考虑的最大新文件数 (默认: no max) |
| latestFirst | 是否先处理最新的新文件, 当有大量文件积压时有用 (默认: false) |
| fileNameOnly | 是否检查新文件只有文件名而不是完整路径(默认值:false)将此设置为 true 时,以下文件将被视为同一个文件,因为它们的文件名“dataset.txt”相同: “file:///dataset.txt” “s3://a/dataset.txt " "s3n://a/b/dataset.txt" "s3a://a/b/c/dataset.txt" |
将目录中写入的文件作为数据流读取,支持的文件格式为:text、csv、json、orc、parquet。。。。
文件数据源特点: 1- 只能监听目录,不能监听具体的文件 2- 可以通过*通配符的形式监听目录中满足条件的文件 3- 如果监听目录中有子目录,那么无法监听到子目录的变化情况
读取代码通用格式:
# 原生API
sparksession.readStream
.format('CSV|JSON|Text|Parquet|ORC...')
.option('参数名1','参数值1')
.option('参数名2','参数值2')
.option('参数名N','参数值N')
.schema(元数据信息)
.load('需要监听的目录地址')
# 简化API
针对具体数据格式,还有对应的简写API格式,例如:
sparksession.readStream.csv(path='需要监听的目录地址',schema=元数据信息。。。)
可能遇到的错误一:

原因: 如果是文件数据源,需要手动指定schema信息
可能遇到的错误二:

原因: File source只能监听目录,不能监听具体文件
2.2 Socket Source

首先: 先下载一个 nc(netcat) 命令. 通过此命令打开一个端口号, 并且可以向这个端口写入数据
下载命令: yum -y install nc
执行nc命令, 开启端口号, 写入数据: nc -lk 端口号
查看端口号是否被使用命令: netstat -nlp | grep 要查询的端口
注意: 要先启动nc,再启动我们的程序
代码格式:
df = spark.readStream \
.format('socket') \
.option('host', '主机地址') \
.option('port', '端口号') \
.load()
2.3 Rate Source
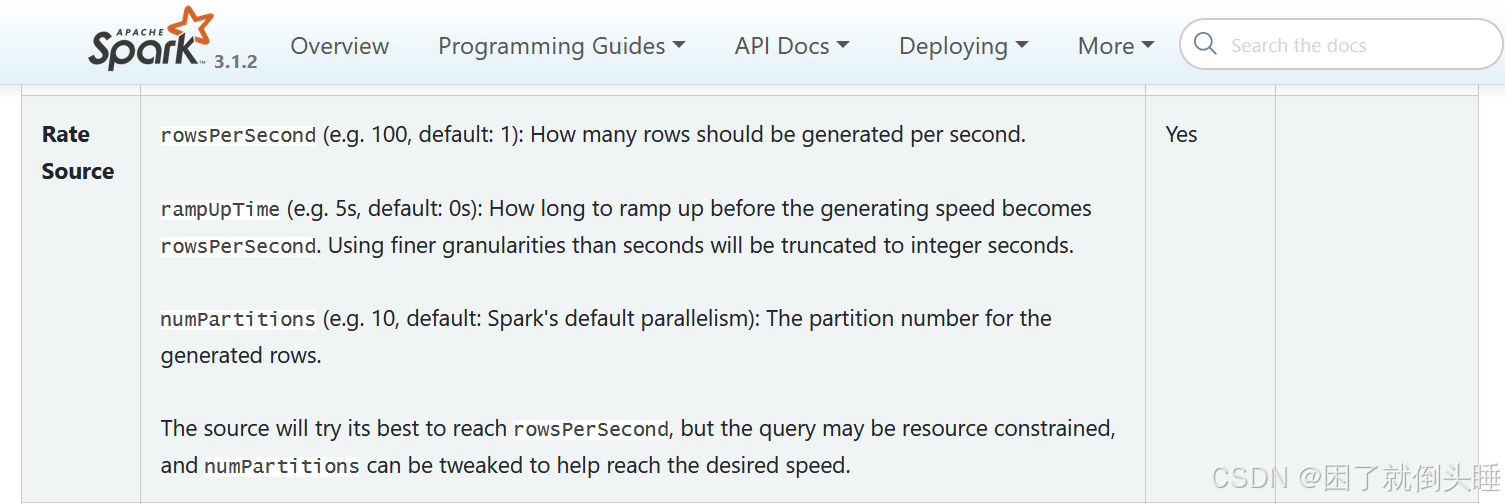
此数据源的提供, 主要是用于进行基准测试
| option参数 | 描述说明 |
|---|---|
| rowsPerSecond | 每秒应该生成多少行 : (例如 100,默认值:1) |
| rampUpTime | 在生成速度变为rowsPerSecond之前应该经过多久的加速时间(例如5 s,默认0) |
| numPartitions | 生成行的分区: (例如 10,默认值:Spark 的默认并行度) |
3、数据处理
指的是数据处理部分,该操作和Spark SQL中是完全一致。可以使用SQL方式进行处理,也可以使用DSL方式进行处理。
4、数据输出
在结构化流中定义好DataFrame或者处理好DataFrame之后,调用writeStream()方法完成数据的输出操作。在输出的过程中,我们可以设置一些相关的属性,然后启动结构化流程序运行。
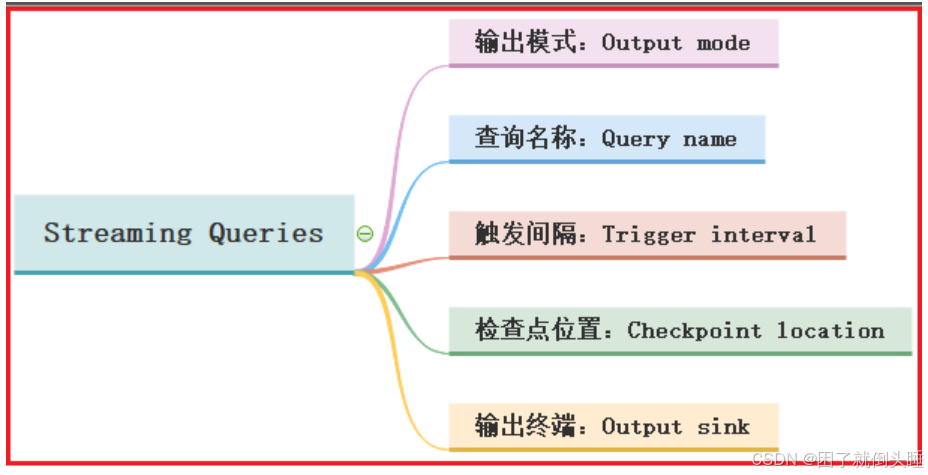
4.1 输出模式
可能遇到的错误:
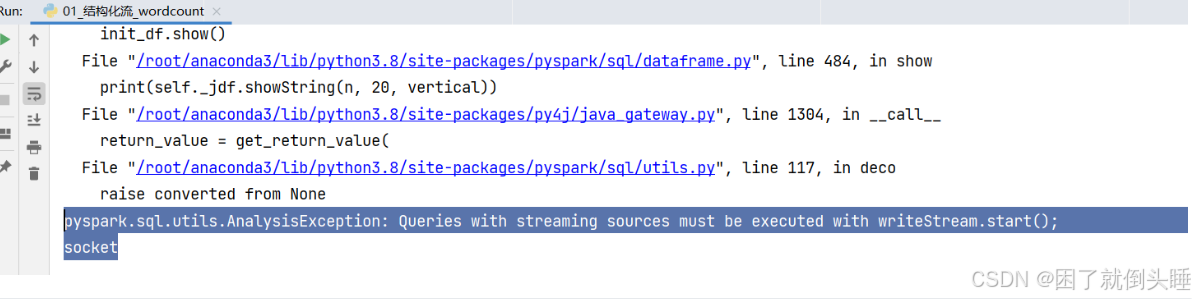
原因: 在结构化流中不能调用show()方法
解决办法: 需要使用writeStream().start()进行结果数据的输出
在进行数据输出的时候,必须通过outputMode来设置输出模式。输出模式提供了3种不同的模式:
-
1- append模式:增量模式 (默认)
特点:当结构化程序处理数据的时候,如果有了新数据,才会触发执行。而且该模式只支持追加。不支持数据处理阶段有聚合的操作。如果有了聚合操作,直接报错。而且也不支持排序操作。如果有了排序,直接报错。
-
2- complete模式:完全(全量)模式
特点:当结构化程序处理数据的时候,每一次都是针对全量的数据进行处理。由于数据越来越多,所以在数据处理阶段,必须要有聚合操作。如果没有聚合操作,直接报错。另外还支持排序,但是不是强制要求。
-
3- update模式:更新模式
特点:支持聚合操作。当结构化程序处理数据的时候,如果处理阶段没有聚合操作,该模式效果和append模式是一致。如果有了聚合操作,只会输出有变化和新增的内容。但是不支持排序操作,如果有了排序,直接报错。
4.1.1 append 模式
1- append模式:增量模式
特点:当结构化程序处理数据的时候,如果有了新数据,才会触发执行。而且该模式只支持追加。不支持数据处理阶段有聚合的操作。如果有了聚合操作,直接报错。而且也不支持排序操作。如果有了排序,直接报错。
如果有了聚合操作,会报如下错误:
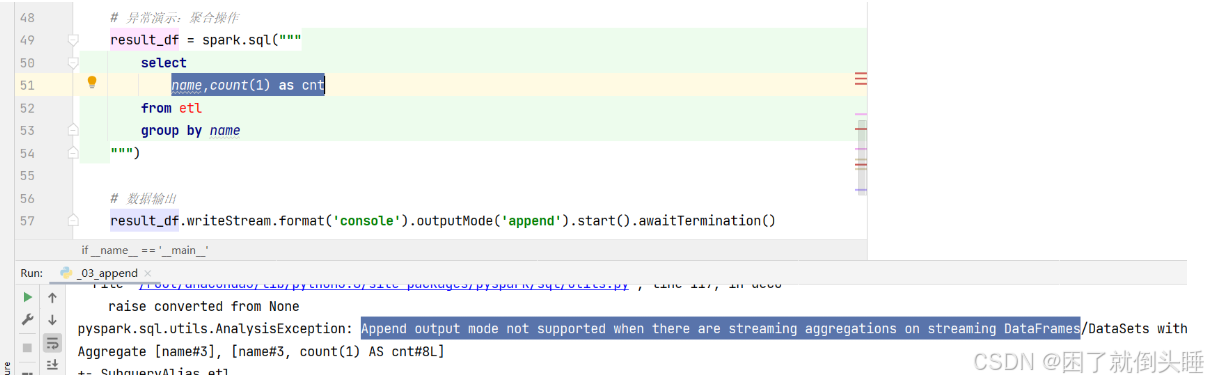
如果有了排序操作,会报如下错误:
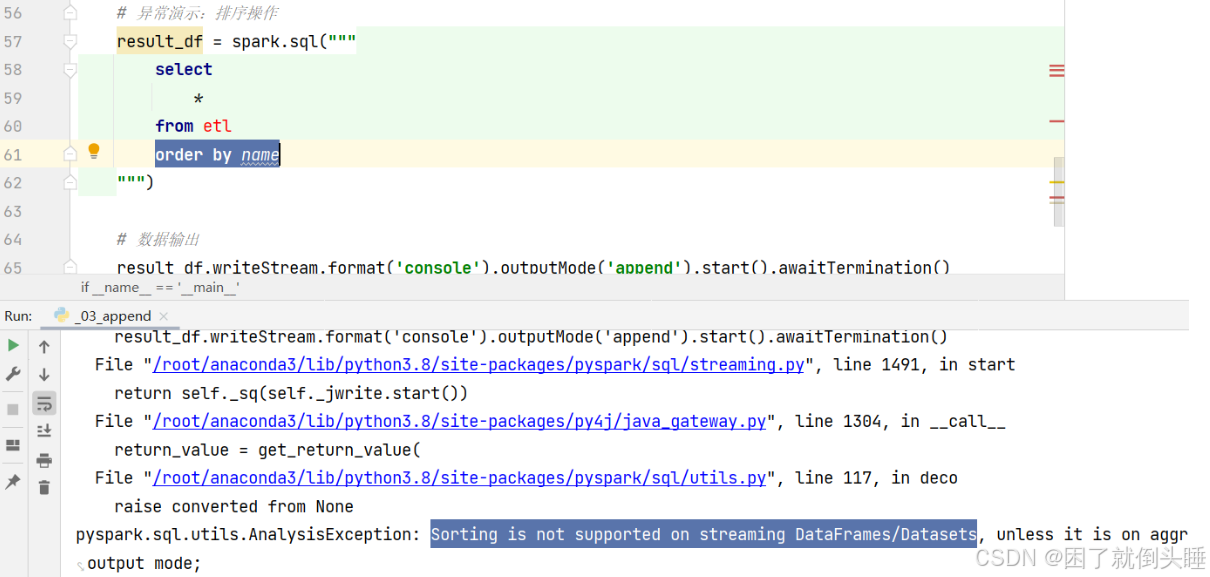
4.1.2 complete模式
2- complete模式:完全(全量)模式
特点:当结构化程序处理数据的时候,每一次都是针对全量的数据进行处理。由于数据越来越多,所以在数据处理阶段,必须要有聚合操作。如果没有聚合操作,直接报错。另外还支持排序,但是不是强制要求。
如果没有聚合操作,会报如下错误:
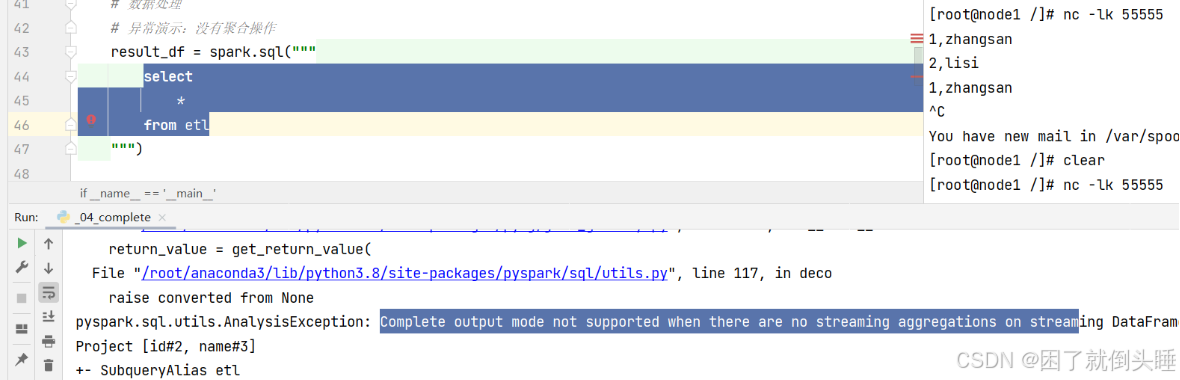
4.1.3 update模式
3- update模式:更新模式
特点:支持聚合操作。当结构化程序处理数据的时候,如果处理阶段没有聚合操作,该模式效果和append模式是一致。如果有了聚合操作,只会输出有变化和新增的内容。但是不支持排序操作,如果有了排序,直接报错。
如果有了排序操作,会报如下错误:
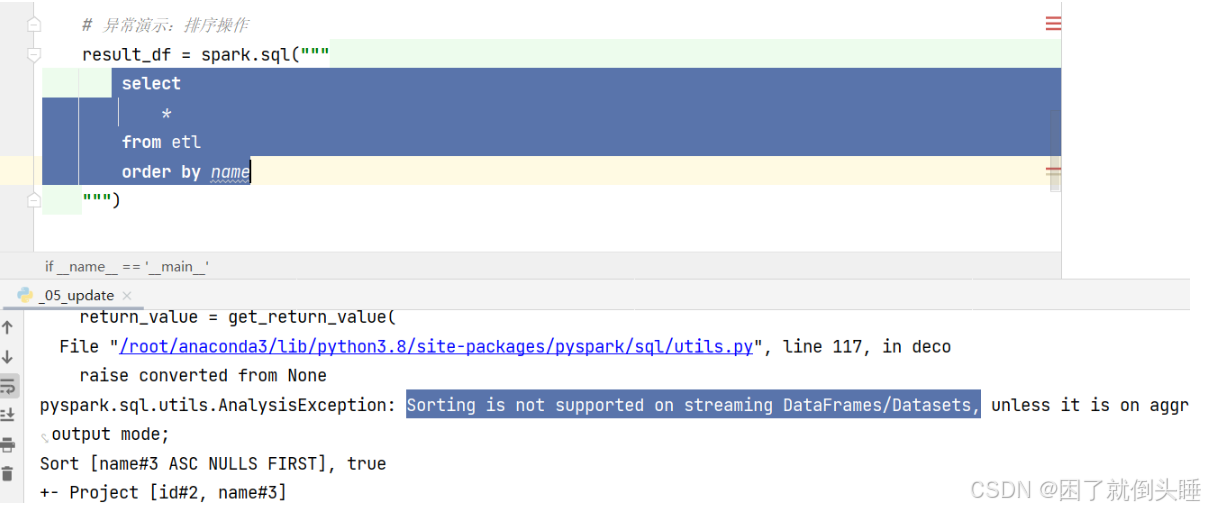
4.2 输出终端/位置
默认情况下,Spark的结构化流支持多种输出方案:
1- console sink: 将结果数据输出到控制台。主要是用在测试中,并且支持3种输出模式 2- File sink: 输出到文件。将结果数据输出到某个目录下,形成文件数据。只支持append模式 3- foreach sink 和 foreachBatch sink: 将数据进行遍历处理。遍历后输出到哪里,取决于自定义函数。并且支持3种输出模式 4- memory sink: 将结果数据输出到内存中。主要目的是进行再次的迭代处理。数据大小不能过大。支持append模式和complete模式 5- Kafka sink: 将结果数据输出到Kafka中。类似于Kafka中的生产者角色。并且支持3种输出模式
5、设置触发器Trigger
触发器Trigger:决定多久执行一次操作并且输出结果。也就是在结构化流中,处理完一批数据以后,等待一会,再处理下一批数据
主要提供如下几种触发器:
-
1- 默认方案:也就是不使用触发器的情况。如果没有明确指定,那么结构化流会自动进行决策每一个批次的大小。在运行过程中,会尽可能让每一个批次间的间隔时间变得更短
result_df.writeStream\ .outputMode('append')\ .start()\ .awaitTermination()
-
2- 配置固定的时间间隔:在结构化流运行的过程中,当一批数据处理完以后,下一批数据需要等待一定的时间间隔才会进行处理(常用,推荐使用)
result_df.writeStream\ .outputMode('append')\ .trigger(processingTime='5 seconds')\ .start()\ .awaitTermination() 情形说明: 1- 上一批次的数据在时间间隔内处理完成了,那么会等待我们配置触发器固定的时间间隔结束,才会开始处理下一批数据 2- 上一批次的数据在固定时间间隔结束的时候才处理完成,那么下一批次会立即被处理,不会等待 3- 上一批次的数据在固定时间间隔内没有处理完成,那么下一批次会等待上一批次处理完成以后立即开始处理,不会等待
-
3- 仅此一次:在运行的过程中,程序只需要执行一次,然后就退出。这种方式适用于进行初始化操作,以及关闭资源等
result_df.writeStream.foreachBatch(func)\ .outputMode('append')\ .trigger(once=True)\ .start()\ .awaitTermination()
6、CheckPoint检查点目录设置
设置检查点,目的是为了提供容错性。当程序出现失败了,可以从检查点的位置,直接恢复处理即可。避免出现重复处理的问题
如何设置检查点:
1- SparkSession.conf.set("spark.sql.streaming.checkpointLocation", "检查点路径")
2- option("checkpointLocation", "检查点路径")
推荐: 检查点路径支持本地和HDFS。推荐使用HDFS路径
检查点目录主要包含以下几个目录位置:
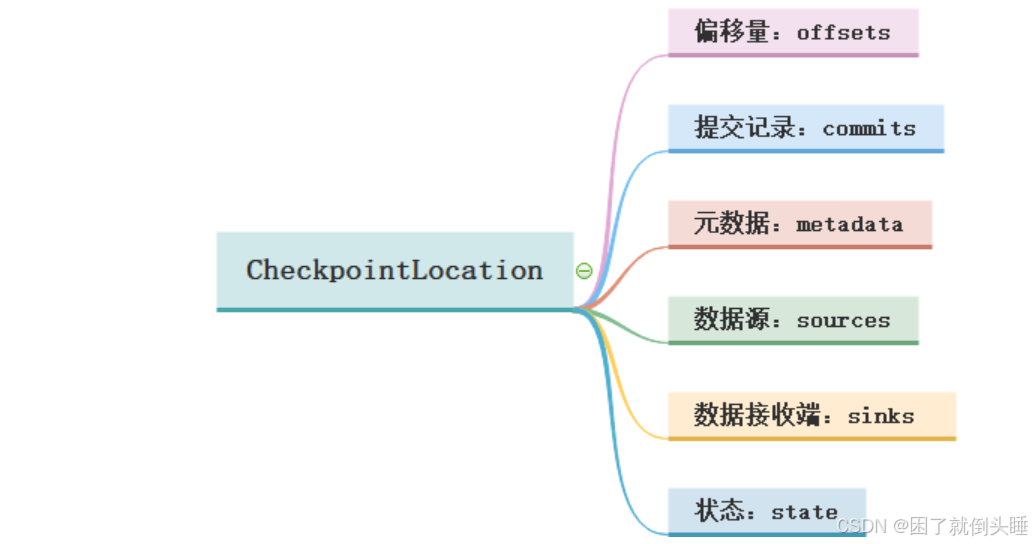
1-偏移量offsets: 记录每个批次中的偏移量。为了保证给定的批次始终包含相同的数据。在处理数据之前会将offset信息写入到该目录
2-提交记录commits: 记录已经处理完成的批次。重启任务的时候会检查完成的批次和offsets目录中批次的记录进行对比。确定接下来要处理的批次
3-元数据文件metadata: 和整个查询关联的元数据信息,目前只保留当前的job id
4-数据源sources: 是数据源(Source)各个批次的读取的详情
5-数据接收端sinks: 是数据接收端各个批次的写出的详情
6-状态state: 当有状态操作的时候,例如:累加、聚合、去重等操作场景,这个目录会用来记录这些状态数据。根据配置周期性的生成。snapshot文件用于记录状态


















 604
604

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











