



 本文详细阐述了YARN的资源调度机制,包括ResourceManger、NodeManager和ApplicationMaster的角色,以及不同调度策略。同时介绍了Hive的语法树解析、优化过程和配置选项,强调了配置管理的重要性。
本文详细阐述了YARN的资源调度机制,包括ResourceManger、NodeManager和ApplicationMaster的角色,以及不同调度策略。同时介绍了Hive的语法树解析、优化过程和配置选项,强调了配置管理的重要性。
分布式资源调度,管理整个hadoop集群的所有服务器资源
-
ResourceManger
-
负责处理所有计算资源申请
-
-
NodeManager
-
负责资源空间(container)的创建
-
-
ApplicationMaster-
管理计算任务,只有产生了mapreduce计算才会运行ApplicationMaster
-
负责具体的资源分配
-
map使用多少
-
reduce使用多少
-
-
1-mapreduce提交计算任务给RM(ResourceManager)
2-RM中的applicationmanager负责创建applicationMaster进程
3-applicationMaster和applicationmanager保持通讯
4-applicationMaster找RM中的ResourceScheduler(资源调度器)申请计算需要的资源
5-applicationMaster通知对应的NodeManger创建资源空间container
6-在资源空间中先运行map阶段的计算,先运行reduce阶段的计算
7-map和reduce运行期间会将自身状态信息汇报给applicationMaster
8-计算完成后,applicationMaster通知NodeManger释放资源
9-资源释放后再通知applicationmanager把自身(applicationMaster)关闭释放资源
yarn的资源调度策略
当有多个计算任务同时请求yarn进行计算,如何分配资源给每个计算任务?
-
先进先出
-
谁先抢到资源谁使用所有资源
-
资源利用效率低
-
如果遇到一个计算时间较长的任务,保资源占用后。其他的任务就无法计算
-
-
容量调度-
将资源分成多份
-
不同计算任务使用不同的资源大小
-
-
-
公平调度
-
资源全部给一个计算任务使用,但是当计算任务中的某个map或reduce计算完成后,可以将自身资源释放掉给其他计算任务使用
-
5个map,其中有两个map计算完成,就可以先释放掉两个资源,给他任务使用,不同等待所有任务计算完成在释放
-
-
Hive的语法树
-
解析器
-
解析sql关键词转为语法数据
-
-
分析器
-
分析语法格式,字段类型等是否正确
-
-
优化器
-
谓词下推
-
调整jion和where执行顺序
-
-
列值裁剪
-
-
执行器
-
将语法中的逻辑转为mapreduce的计算java代码交给MR执行
-
Hive配置优化
hive中有三种配置方式
-
配置文件配置
-
hive的安装目录下的conf目录中的hive-site.xml
-
全局有效,启动hive后会自动使用配置文件中的配置
-
文件格式xml
-
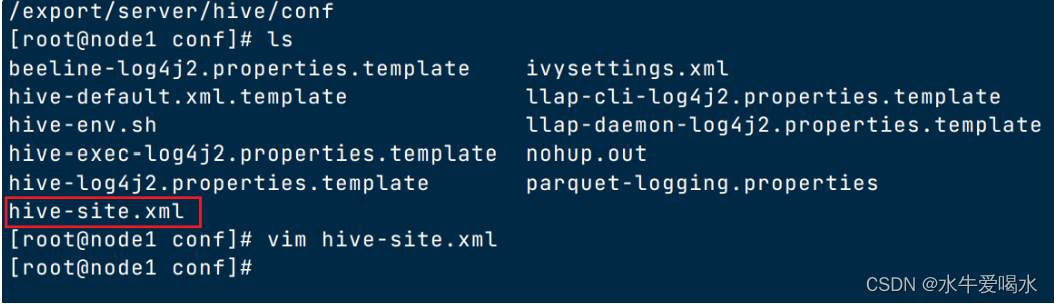
-
hive指令配置
-
set配置
-
在sql的操作界面设置
-
优先级: set配置 > hive指令配置 > 配置文件
set配置只在当前操作界面生效,创建新的连接窗口就是失效了
日常开发中为了减少配置信息的影响,谁开发谁设置,采用set方式
hive的配置属性信息Configuration Properties - Apache Hive - Apache Software Foundation

















 1059
1059

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









