






现在要计算每个部门的平均工资(工资和/员工数),但是要去掉部门的最高工资和最低工资(如果一个部门最高或最低工资有并列的,去掉一个最高的和一个最低的)后,计算部门的平均工资。
数据如下:
| user_id,dept,salary 101,"研发部",50000 102,"研发部",50000 103,"研发部",10000 104,"研发部",20000 105,"研发部",30000 106,"市场部",20000 107,"市场部",30000 108,"市场部",25000 109,"产品部",20000 110,"产品部",30000 111,"产品部",25000 |
import os
# 导入pyspark模块
from pyspark import SparkContext, SparkConf
from pyspark.sql import SparkSession
if __name__ == '__main__':
# 配置环境
os.environ['JAVA_HOME'] = 'D:\Download\Java\JDK'
# 配置Hadoop的路径,就是前面解压的那个路径
os.environ['HADOOP_HOME'] = 'D:\\bigdata\hadoop-3.3.1\hadoop-3.3.1'
# 配置base环境Python解析器的路径
os.environ['PYSPARK_PYTHON'] = 'C:/ProgramData/Miniconda3/python.exe' # 配置base环境Python解析器的路径
os.environ['PYSPARK_DRIVER_PYTHON'] = 'C:/ProgramData/Miniconda3/python.exe'
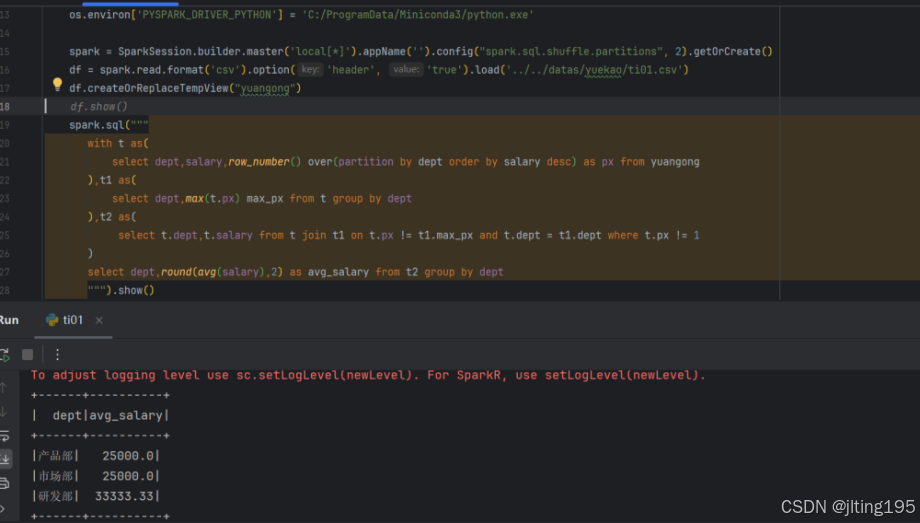
spark = SparkSession.builder.master('local[*]').appName('').config("spark.sql.shuffle.partitions", 2).getOrCreate()
df = spark.read.format('csv').option('header', 'true').load('../../datas/yuekao/ti01.csv')
#起一个临时表名
df.createOrReplaceTempView("yuangong")
spark.sql("""
with t as(
select dept,salary,row_number() over(partition by dept order by salary desc) as px from yuangong
),t1 as(
select dept,max(t.px) max_px from t group by dept
),t2 as(
select t.dept,t.salary from t join t1 on t.px != t1.max_px and t.dept = t1.dept where t.px != 1
)
select dept,round(avg(salary),2) as avg_salary from t2 group by dept
""").show()
spark.stop()
# 使用完后,记得关闭查询结果:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









