







目录
四、DataStream (Lambda表达式-扩展 了解)
在大数据处理领域,Flink 凭借其卓越的流批一体特性、高效的实时处理能力以及丰富的 API,备受开发者青睐。今天,我们将深入探讨如何开发 Flink 任务,并将其打包提交到集群上运行,涵盖从基础概念到具体编码、打包、提交的完整流程,希望能帮助大家在 Flink 实践之路上少踩坑、多收获。
一、Flink API 概述
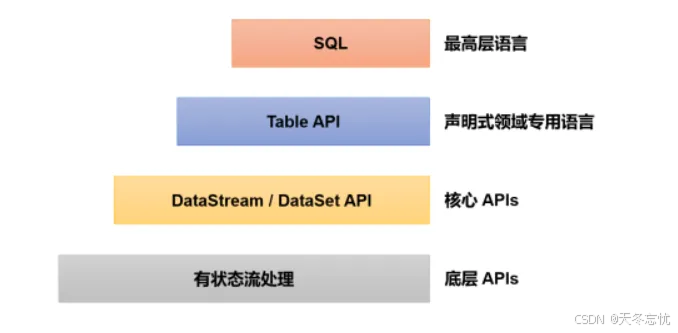
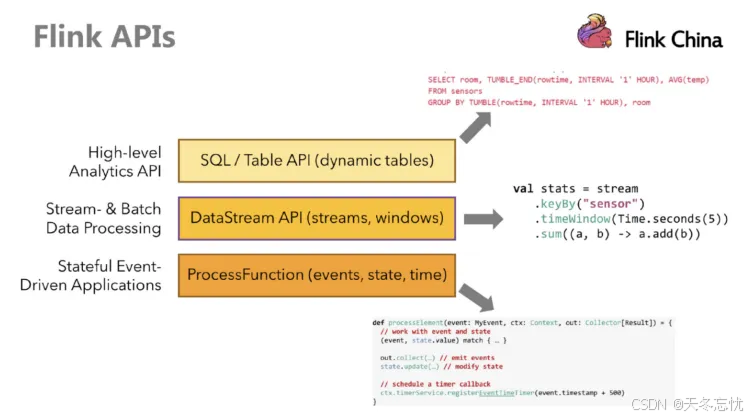
Flink 提供了多个层次的 API,各有优劣。越往上抽象程度越高,上手就越便捷,比如 Table&SQL - API,能让熟悉 SQL 语句的开发者快速编写数据处理逻辑;越往下则越贴近底层,像最底层的一些接口虽使用难度大,但能实现更精细的控制。需注意的是,自 Flink 1.12 起支持流批一体,DataSet API 已渐失宠,当下优先推荐使用 DataStream 流式 API,它既能够应对无界数据(流处理场景),也可处理有界数据(批处理场景),可谓 “全能选手”,本次任务开发我们就聚焦于此。
二、Flink 编码步骤详解
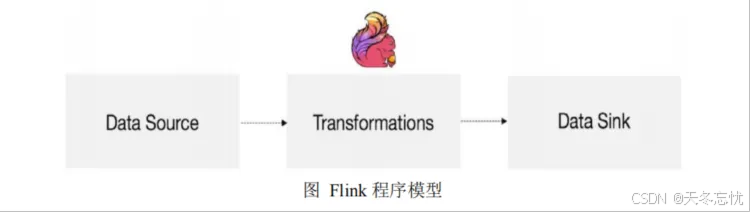
env - 准备环境
这是整个 Flink 任务的 “基石”,在此步骤要配置诸如并行度、运行时模式等基础环境信息。通过代码StreamExecutionEnvironment.getExecutionEnvironment()可获取执行环境对象,该对象承载着后续操作的诸多配置项,像设置并行度可利用setParallelism()方法,依据本机 CPU 逻辑处理器数量(可通过 Java 的Runtime.getRuntime().availableProcessors()获取,其数量往往等同于合理的分区数量)来初始设定并行度,确保资源高效利用。
source - 加载数据
数据源多种多样,常见有文件、Kafka 消息队列等。以读取本地文件为例,利用env.readTextFile("file:///path/to/file")就能将文本文件数据加载为 DataStream 格式,准备进入处理 “流水线”。
transformation - 数据处理转换
此环节是 “数据加工厂”,可进行过滤(filter操作筛掉不符合条件的数据)、映射(map操作按自定义函数转换数据格式或内容)、聚合(keyBy与sum等组合实现分组聚合统计)等丰富操作。比如统计文本文件单词频次,先flatMap分割每行文本为单词,再keyBy按单词分组,接着sum统计出现次数。
sink - 数据输出
处理好的数据得有 “归宿”,输出方式多元,像输出到控制台(print方便调试查看即时结果)、写入文件(writeAsText指定本地或 HDFS 路径存储)、发送至外部存储系统如 MySQL(借助自定义的 JDBC Sink 实现精准入库)等。
execute - 执行
万事俱备,通过env.execute("jobName")触发整个任务执行,让数据在设定流程里 “流动” 起来,完成从输入到输出的华丽变身。
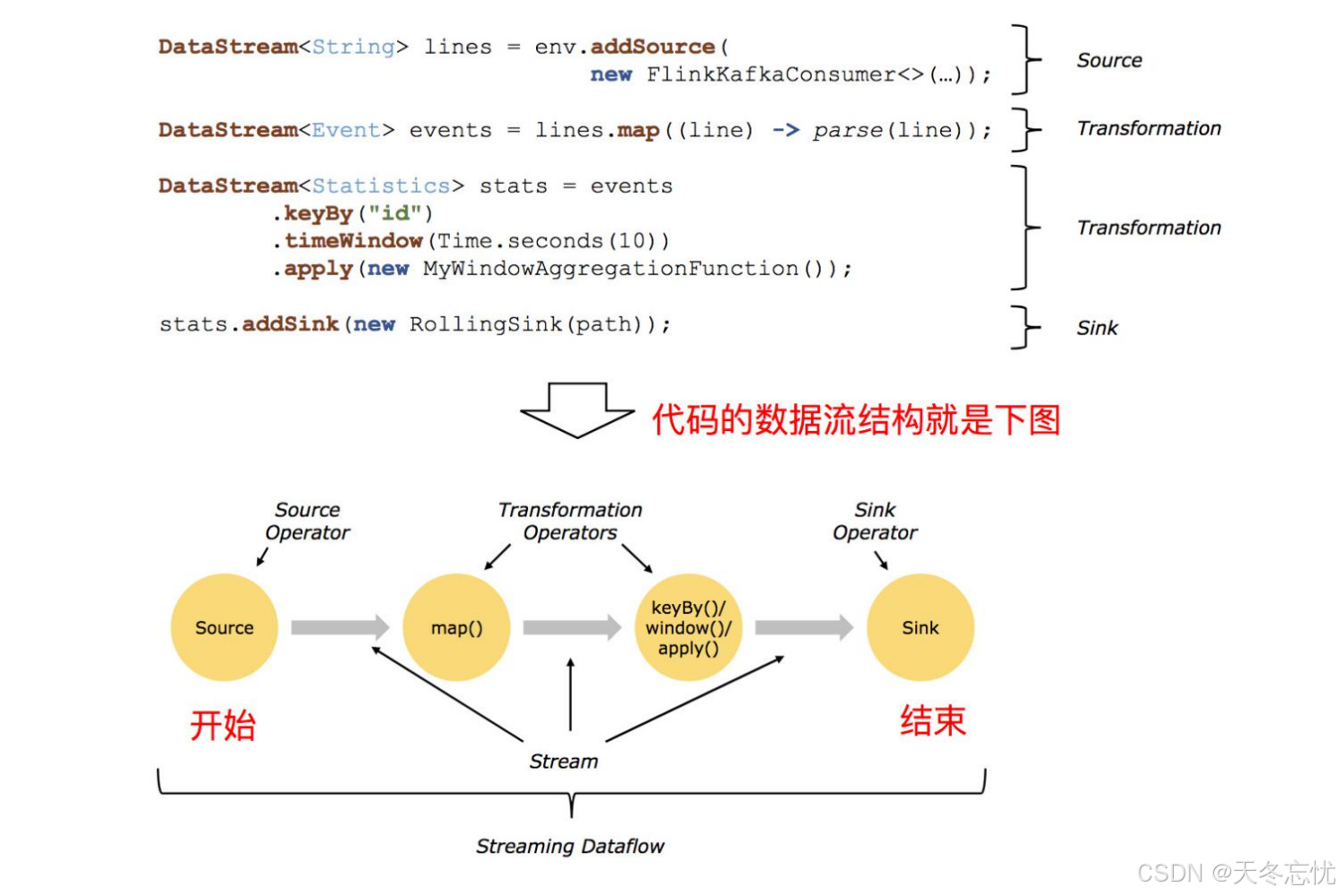
三、DataStream API 开发要点
开发流程
添加依赖
在项目的pom.xml(以 Maven 项目为例)里引入必要的 Flink 相关依赖,涵盖核心模块、连接器(对应数据源与 sink 类型)等,确保代码能顺利调用 Flink 各类接口与功能。
<properties>
<flink.version>1.13.6</flink.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-shaded-hadoop-2-uber</artifactId>
<version>2.7.5-10.0</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.24</version>
</dependency>
</dependencies>
<build>
<extensions>
<extension>
<groupId>org.apache.maven.wagon</groupId>
<artifactId>wagon-ssh</artifactId>
<version>2.8</version>
</extension>
</extensions>
<plugins>
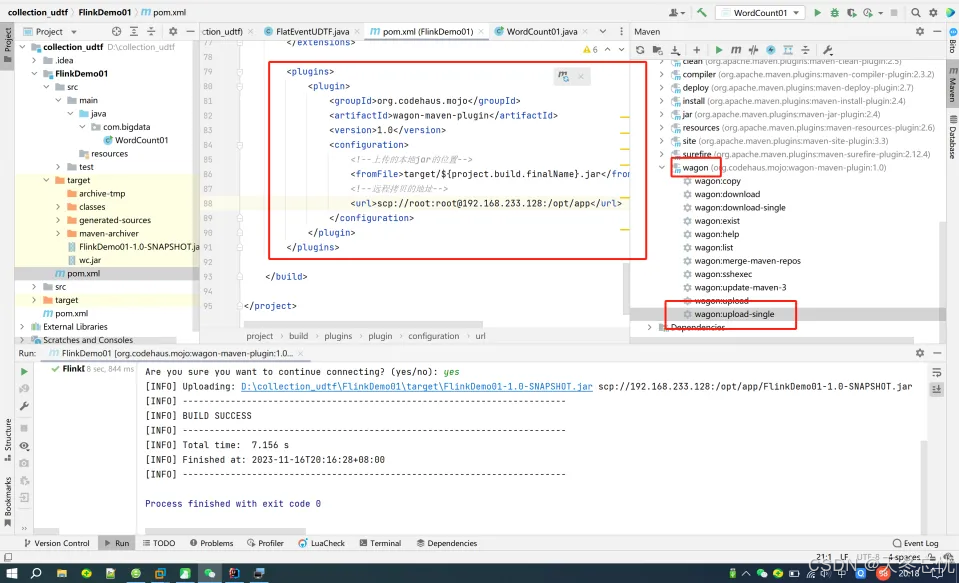
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>wagon-maven-plugin</artifactId>
<version>1.0</version>
<configuration>
<!--上传的本地jar的位置-->
<fromFile>target/${project.build.finalName}.jar</fromFile>
<!--远程拷贝的地址-->
<url>scp://root:root@bigdata01:/opt/app</url>
</configuration>
</plugin>
</plugins>
</build>编写代码
package com.bigdata.day01;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class WordCount01 {
/**
* 1. env-准备环境
* 2. source-加载数据
* 3. transformation-数据处理转换
* 4. sink-数据输出
* 5. execute-执行
*/
public static void main(String[] args) throws Exception {
// 导入常用类时要注意 不管是在本地开发运行还是在集群上运行,都这么写,非常方便
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 这个是 自动 ,根据流的性质,决定是批处理还是流处理
//env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// 批处理流, 一口气把数据算出来
// env.setRuntimeMode(RuntimeExecutionMode.BATCH);
// 流处理,默认是这个 可以通过打印批和流的处理结果,体会流和批的含义
env.setRuntimeMode(RuntimeExecutionMode.STREAMING);
// 获取数据 多态的写法 DataStreamSource 它是 DataStream 的子类
DataStream<String> dataStream01 = env.fromElements("spark flink kafka", "spark sqoop flink", "kakfa hadoop flink");
DataStream<String> flatMapStream = dataStream01.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String line, Collector<String> collector) throws Exception {
String[] arr = line.split(" ");
for (String word : arr) {
// 循环遍历每一个切割完的数据,放入到收集器中,就可以形成一个新的DataStream
collector.collect(word);
}
}
});
//flatMapStream.print();
// Tuple2 指的是2元组
DataStream<Tuple2<String, Integer>> mapStream = flatMapStream.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String word) throws Exception {
return Tuple2.of(word, 1); // ("hello",1)
}
});
DataStream<Tuple2<String, Integer>> sumResult = mapStream.keyBy(new KeySelector<Tuple2<String, Integer>, String>() {
@Override
public String getKey(Tuple2<String, Integer> tuple2) throws Exception {
return tuple2.f0;
}
// 此处的1 指的是元组的第二个元素,进行相加的意思
}).sum(1);
sumResult.print();
// 执行
env.execute();
}
}查看本机的CPU的逻辑处理器的数量,逻辑处理器的数量就是你的分区数量。
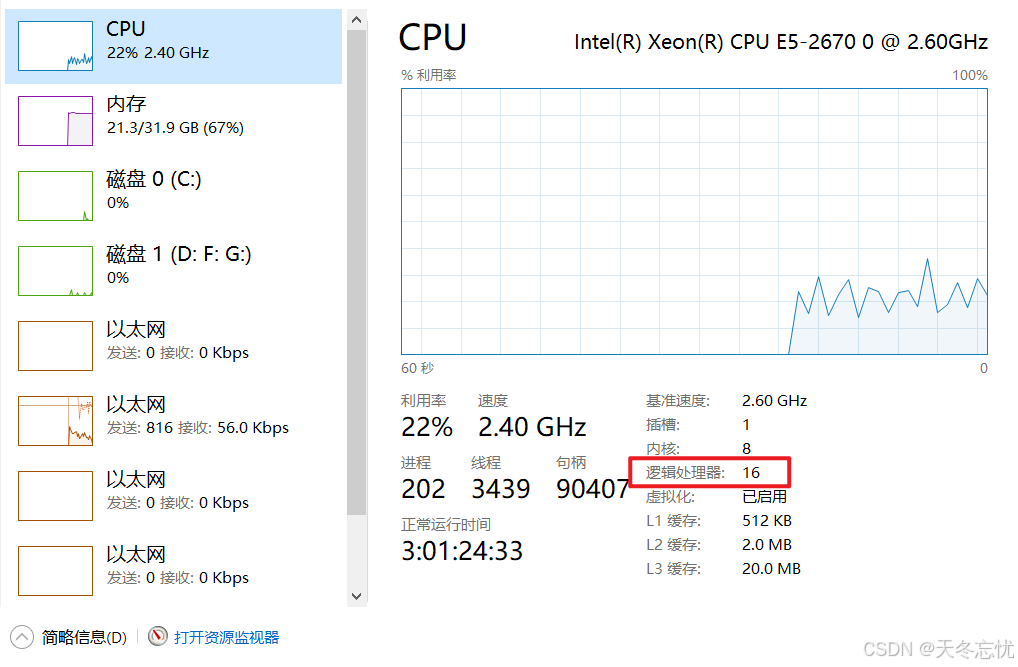
12> spark
13> kakfa
11> spark
11> flink
11> kafka
13> hadoop
12> sqoop
13> flink
12> flink
前面的数字是分区数,默认跟逻辑处理器的数量有关系。对结果进行解释:
什么是批,什么是流?
批处理结果:前面的序号代表分区
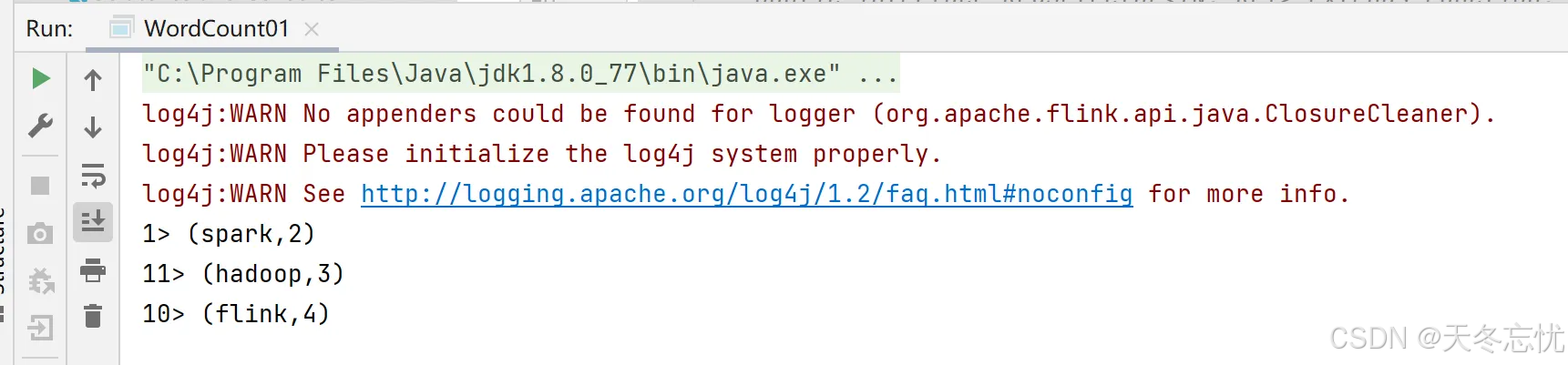
流处理结果:
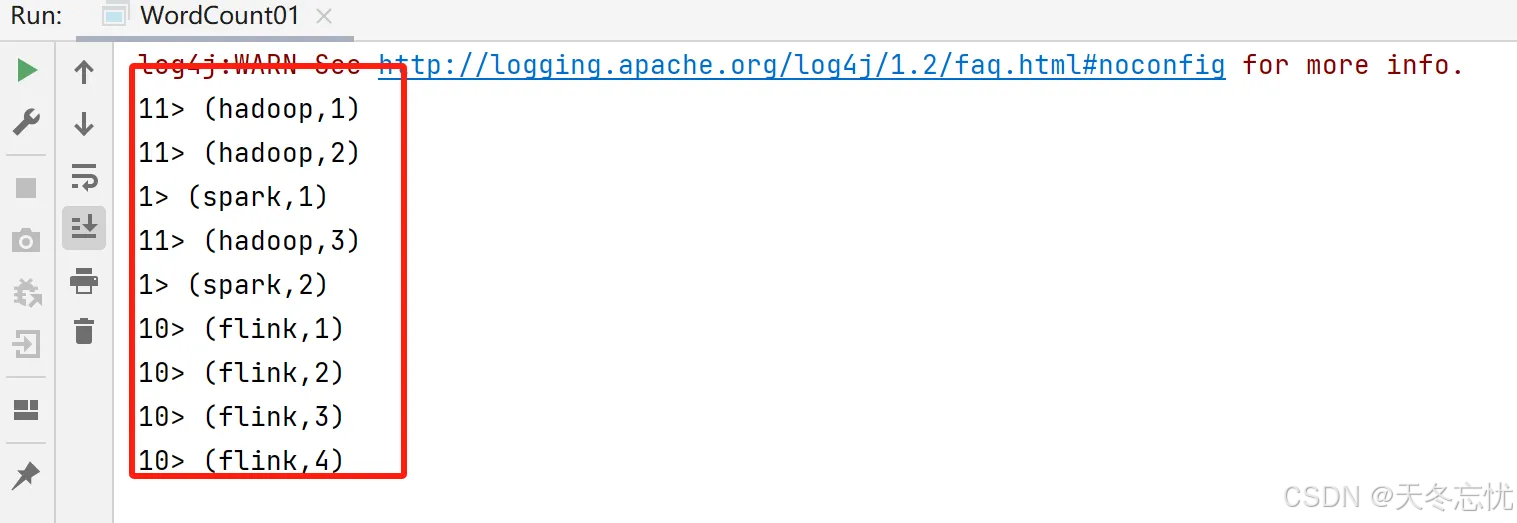
也可以通过如下方式修改分区数量:
env.setParallelism(2);关于并行度的代码演示:
系统以及算子都可以设置并行度,或者获取并行度
打包、上传到虚拟机
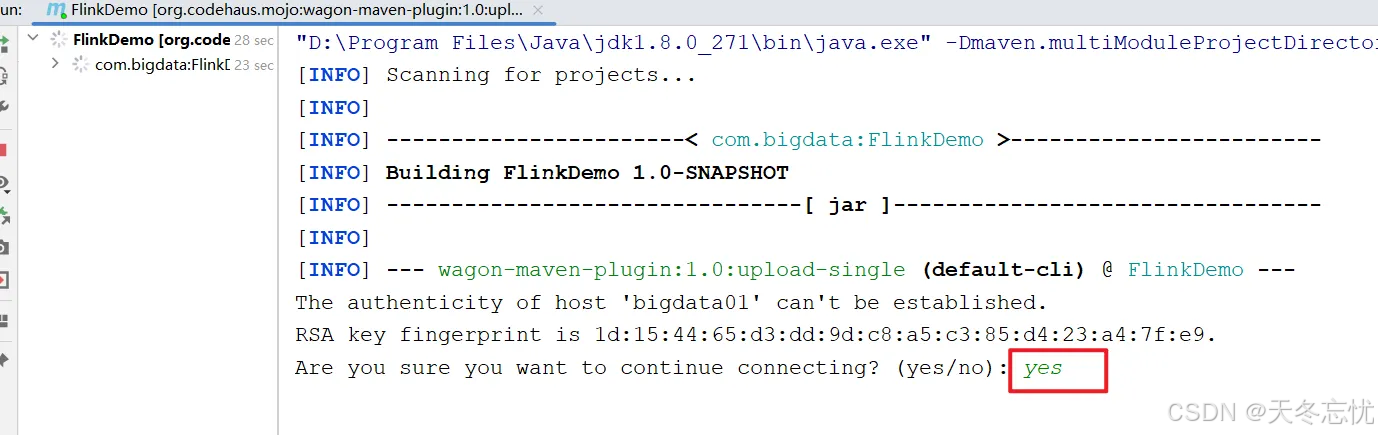
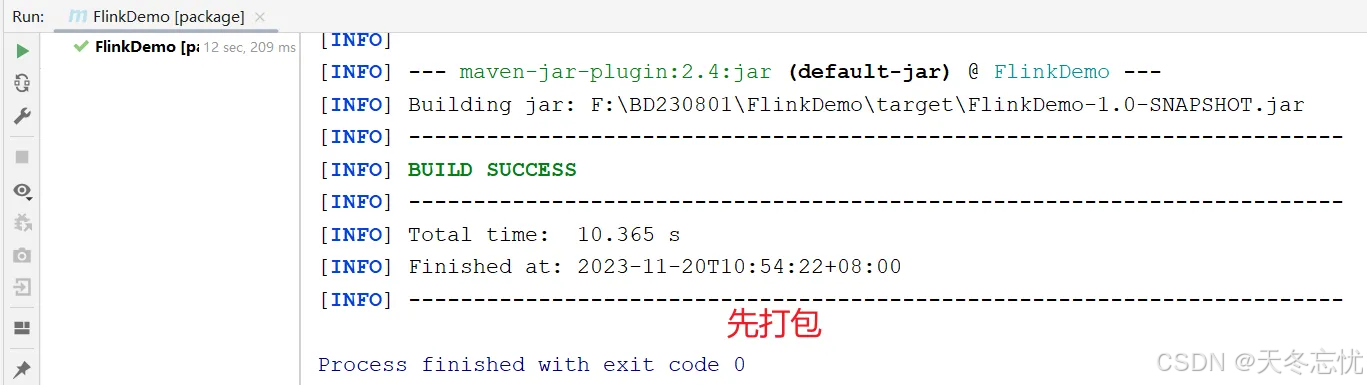
文件夹不需要提前准备好,它可以帮我创建
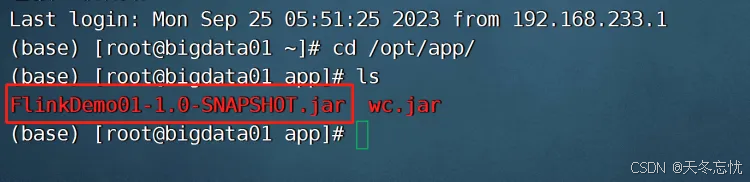
提交我们自己开发打包的任务
flink run -c com.bigdata.day01.WordCount01 /opt/app/FlinkDemo-1.0-SNAPSHOT.jar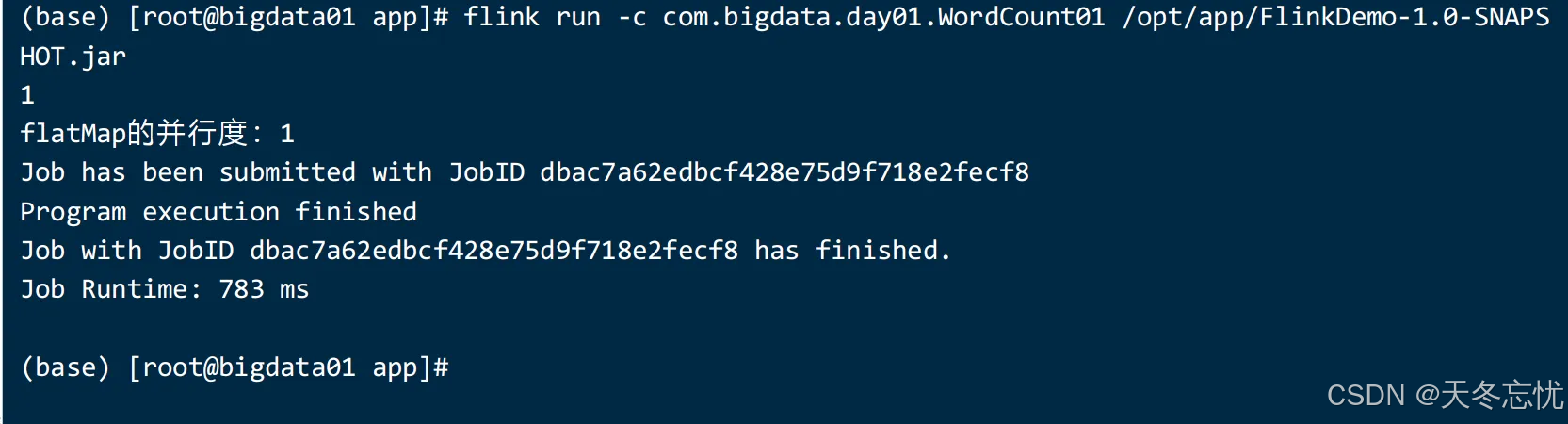
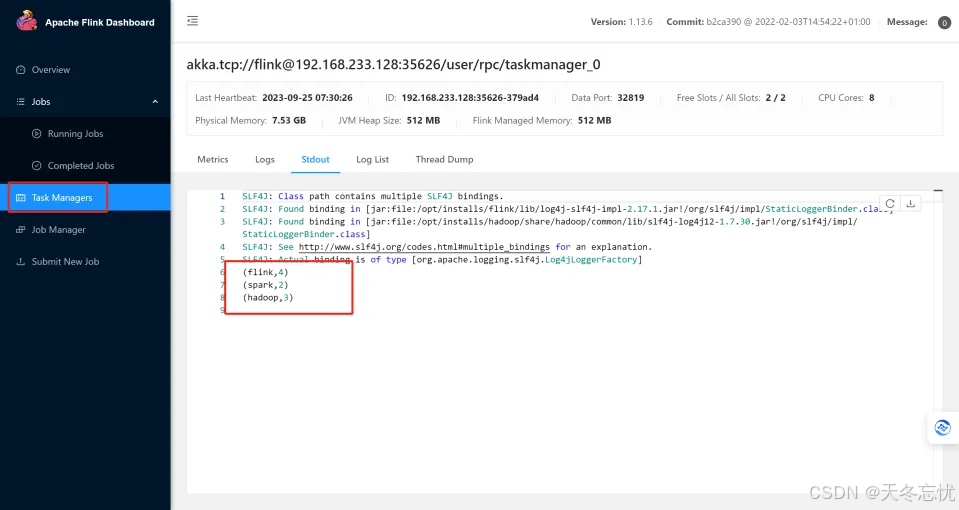
去界面中查看运行结果:
因为你这个是集群运行的,所以标准输出流中查看,假如第一台没有,去第二台查看,一直点。
获取主函数参数工具类
可以通过外部传参的方式给定一个路径
以下代码可以做到,假如给定路径,就获取路径的数据,假如没给,就读取默认数据:
package com.bigdata.day01;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class WordCount02 {
/**
* 1. env-准备环境
* 2. source-加载数据
* 3. transformation-数据处理转换
* 4. sink-数据输出
* 5. execute-执行
*/
public static void main(String[] args) throws Exception {
// 导入常用类时要注意 不管是在本地开发运行还是在集群上运行,都这么写,非常方便
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 这个是 自动 ,根据流的性质,决定是批处理还是流处理
//env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// 批处理流, 一口气把数据算出来
// env.setRuntimeMode(RuntimeExecutionMode.BATCH);
// 流处理,默认是这个 可以通过打印批和流的处理结果,体会流和批的含义
env.setRuntimeMode(RuntimeExecutionMode.STREAMING);
// 将任务的并行度设置为2
// env.setParallelism(2);
// 通过这个获取系统的并行度
int parallelism = env.getParallelism();
System.out.println(parallelism);
// 获取数据 多态的写法 DataStreamSource 它是 DataStream 的子类
// 连着写的本质就是 因为每一个算子的返回值都是DataStream的子类,所以可以这么写
// 以下代码中路径是写死的,能不能通过外部传参进来,当然可以! agrs
DataStream<String> dataStream = null;
System.out.println(args.length);
if(args.length !=0){
String path = args[0];
dataStream = env.readTextFile(path);
}else{
dataStream = env.fromElements("spark flink kafka", "spark sqoop flink", "kakfa hadoop flink");
}
dataStream.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String line, Collector<String> collector) throws Exception {
String[] arr = line.split(" ");
for (String word : arr) {
// 循环遍历每一个切割完的数据,放入到收集器中,就可以形成一个新的DataStream
collector.collect(word);
}
}
}).map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String word) throws Exception {
return Tuple2.of(word, 1); // ("hello",1)
}
}).keyBy(new KeySelector<Tuple2<String, Integer>, String>() {
@Override
public String getKey(Tuple2<String, Integer> tuple2) throws Exception {
return tuple2.f0;
}
// 此处的1 指的是元组的第二个元组,进行相加的意思
}).sum(1).print();
// 执行
env.execute();
}
}
在虚拟机中运行
flink run -c com.bigdata.day01.Demo02 FlinkDemo-1.0-SNAPSHOT.jar /home/wc.txt
这样做,跟我们以前的做法还是不一样。以前的运行方式是这样的
flink run /opt/installs/flink/examples/batch/WordCount.jar --input /home/wc.txt
这个写法,传递参数的时候,带有--字样,而我们的没有。
以上代码进行升级,我想将参数前面追加一个 --input 这样,怎么写?
ParameterTool parameterTool = ParameterTool.fromArgs(args);
if(parameterTool.has("output")){
path = parameterTool.get("output");
}
在代码中的使用:
ParameterTool parameterTool = ParameterTool.fromArgs(args);
String output = "";
if (parameterTool.has("output")) {
output = parameterTool.get("output");
System.out.println("指定了输出路径使用:" + output);
} else {
output = "hdfs://node01:9820/wordcount/output47_";
System.out.println("可以指定输出路径使用 --output ,没有指定使用默认的:" + output);
}
升级过的代码:
package com.bigdata.day01;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class WordCount02 {
/**
* 1. env-准备环境
* 2. source-加载数据
* 3. transformation-数据处理转换
* 4. sink-数据输出
* 5. execute-执行
*/
public static void main(String[] args) throws Exception {
// 导入常用类时要注意 不管是在本地开发运行还是在集群上运行,都这么写,非常方便
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 这个是 自动 ,根据流的性质,决定是批处理还是流处理
//env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// 批处理流, 一口气把数据算出来
// env.setRuntimeMode(RuntimeExecutionMode.BATCH);
// 流处理,默认是这个 可以通过打印批和流的处理结果,体会流和批的含义
env.setRuntimeMode(RuntimeExecutionMode.STREAMING);
// 将任务的并行度设置为2
// env.setParallelism(2);
// 通过这个获取系统的并行度
int parallelism = env.getParallelism();
System.out.println(parallelism);
// 获取数据 多态的写法 DataStreamSource 它是 DataStream 的子类
// 连着写的本质就是 因为每一个算子的返回值都是DataStream的子类,所以可以这么写
// 以下代码中路径是写死的,能不能通过外部传参进来,当然可以! agrs
DataStream<String> dataStream = null;
System.out.println(args.length);
if(args.length !=0){
String path ;
ParameterTool parameterTool = ParameterTool.fromArgs(args);
if(parameterTool.has("input")){
path = parameterTool.get("input");
}else{
path = args[0];
}
dataStream = env.readTextFile(path);
}else{
dataStream = env.fromElements("spark flink kafka", "spark sqoop flink", "kakfa hadoop flink");
}
dataStream.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String line, Collector<String> collector) throws Exception {
String[] arr = line.split(" ");
for (String word : arr) {
// 循环遍历每一个切割完的数据,放入到收集器中,就可以形成一个新的DataStream
collector.collect(word);
}
}
}).map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String word) throws Exception {
return Tuple2.of(word, 1); // ("hello",1)
}
}).keyBy(new KeySelector<Tuple2<String, Integer>, String>() {
@Override
public String getKey(Tuple2<String, Integer> tuple2) throws Exception {
return tuple2.f0;
}
// 此处的1 指的是元组的第二个元组,进行相加的意思
}).sum(1).print();
// 执行
env.execute();
}
}
四、DataStream (Lambda表达式-扩展 了解)
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
import java.util.Arrays;
/**
* Desc 演示Flink-DataStream-流批一体API完成批处理WordCount
* 使用Java8的lambda表示完成函数式风格的WordCount
*/
public class WordCount02 {
public static void main(String[] args) throws Exception {
//TODO 1.env-准备环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//env.setRuntimeMode(RuntimeExecutionMode.STREAMING);//指定计算模式为流
//env.setRuntimeMode(RuntimeExecutionMode.BATCH);//指定计算模式为批
env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);//自动
//不设置的话默认是流模式defaultValue(RuntimeExecutionMode.STREAMING)
//TODO 2.source-加载数据
DataStream<String> dataStream = env.fromElements("flink hadoop spark", "flink hadoop spark", "flink hadoop", "flink");
//TODO 3.transformation-数据转换处理
//3.1对每一行数据进行分割并压扁
/*
public interface FlatMapFunction<T, O> extends Function, Serializable {
void flatMap(T value, Collector<O> out) throws Exception;
}
*/
/*DataStream<String> wordsDS = dataStream.flatMap(new FlatMapFunction<String, String>() {
@Override
public void flatMap(String value, Collector<String> out) throws Exception {
String[] words = value.split(" ");
for (String word : words) {
out.collect(word);
}
}
});*/
//注意:Java8的函数的语法/lambda表达式的语法: (参数)->{函数体}
DataStream<String> wordsDS = dataStream.flatMap(
(String value, Collector<String> out) -> {
String[] words = value.split(" ");
for (String word : words) {
out.collect(word);
}
}
).returns(Types.STRING);
//3.2 每个单词记为<单词,1>
/*
public interface MapFunction<T, O> extends Function, Serializable {
O map(T value) throws Exception;
}
*/
/*DataStream<Tuple2<String, Integer>> wordAndOneDS = wordsDS.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String value) throws Exception {
return Tuple2.of(value, 1);
}
});*/
DataStream<Tuple2<String, Integer>> wordAndOneDS = wordsDS.map(
(String value) -> Tuple2.of(value, 1)
).returns(Types.TUPLE(Types.STRING, Types.INT));
//3.3分组
//注意:DataSet中分组用groupBy,DataStream中分组用keyBy
//KeyedStream<Tuple2<String, Integer>, Tuple> keyedDS = wordAndOneDS.keyBy(0);
/*
public interface KeySelector<IN, KEY> extends Function, Serializable {
KEY getKey(IN value) throws Exception;
}
*/
/*KeyedStream<Tuple2<String, Integer>, String> keyedDS = wordAndOneDS.keyBy(new KeySelector<Tuple2<String, Integer>, String>() {
@Override
public String getKey(Tuple2<String, Integer> value) throws Exception {
return value.f0;
}
});*/
KeyedStream<Tuple2<String, Integer>, String> keyedDS = wordAndOneDS.keyBy((Tuple2<String, Integer> value) -> value.f0);
//3.4聚合
SingleOutputStreamOperator<Tuple2<String, Integer>> result = keyedDS.sum(1);
//TODO 4.sink-数据输出
result.print();
//TODO 5.execute-执行
env.execute();
}
}此处有一个大坑,就是使用完lambda表达式以后,需要添加一个returns(Types.STRING); 否则报错,这样的话,使用lambda也不是特别快了。
连着写的版本如下:
package com.bigdata.day01;
import org.apache.flink.api.common.RuntimeExecutionMode;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class WordCount03 {
/**
* 1. env-准备环境
* 2. source-加载数据
* 3. transformation-数据处理转换
* 4. sink-数据输出
* 5. execute-执行
*/
public static void main(String[] args) throws Exception {
// 导入常用类时要注意 不管是在本地开发运行还是在集群上运行,都这么写,非常方便
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 这个是 自动 ,根据流的性质,决定是批处理还是流处理
//env.setRuntimeMode(RuntimeExecutionMode.AUTOMATIC);
// 批处理流, 一口气把数据算出来
// env.setRuntimeMode(RuntimeExecutionMode.BATCH);
// 流处理,默认是这个 可以通过打印批和流的处理结果,体会流和批的含义
//env.setRuntimeMode(RuntimeExecutionMode.STREAMING);
// 将任务的并行度设置为2
// env.setParallelism(2);
// 通过这个获取系统的并行度
int parallelism = env.getParallelism();
System.out.println(parallelism);
// 获取数据 多态的写法 DataStreamSource 它是 DataStream 的子类
// 连着写的本质就是 因为每一个算子的返回值都是DataStream的子类,所以可以这么写
// 以下代码中路径是写死的,能不能通过外部传参进来,当然可以! agrs
DataStream<String> dataStream = null;
System.out.println(args.length);
if(args.length !=0){
String path ;
ParameterTool parameterTool = ParameterTool.fromArgs(args);
if(parameterTool.has("input")){
path = parameterTool.get("input");
}else{
path = args[0];
}
dataStream = env.readTextFile(path);
}else{
dataStream = env.fromElements("spark flink kafka", "spark sqoop flink", "kakfa hadoop flink");
}
dataStream.flatMap((String line, Collector<String> collector) -> {
String[] arr = line.split(" ");
for (String word : arr) {
// 循环遍历每一个切割完的数据,放入到收集器中,就可以形成一个新的DataStream
collector.collect(word);
}
}).returns(Types.STRING).map((String word)-> {
return Tuple2.of(word, 1); // ("hello",1)
}).returns(Types.TUPLE(Types.STRING, Types.INT))
.keyBy((Tuple2<String, Integer> tuple2)-> {
return tuple2.f0;
}).sum(1).print();
// 执行
env.execute();
}
}五、提交任务的两种方式
利用 Maven(执行mvn clean package)或 Gradle 等构建工具,将编写好的 Flink 代码及其依赖打包成可提交至集群运行的 JAR 包,无需提前手动准备输出文件夹,构建工具会自动创建,生成如FlinkDemo - 1.0 - SNAPSHOT.jar这样的可部署文件。
一)UI 方式递交
登录 Flink 集群管理界面(通常部署在特定端口,如http://cluster-ip:8081),在界面操作栏中按指引上传 JAR 包、配置主类、输入参数等信息,便捷直观,适合可视化操作偏好者及新手快速上手。
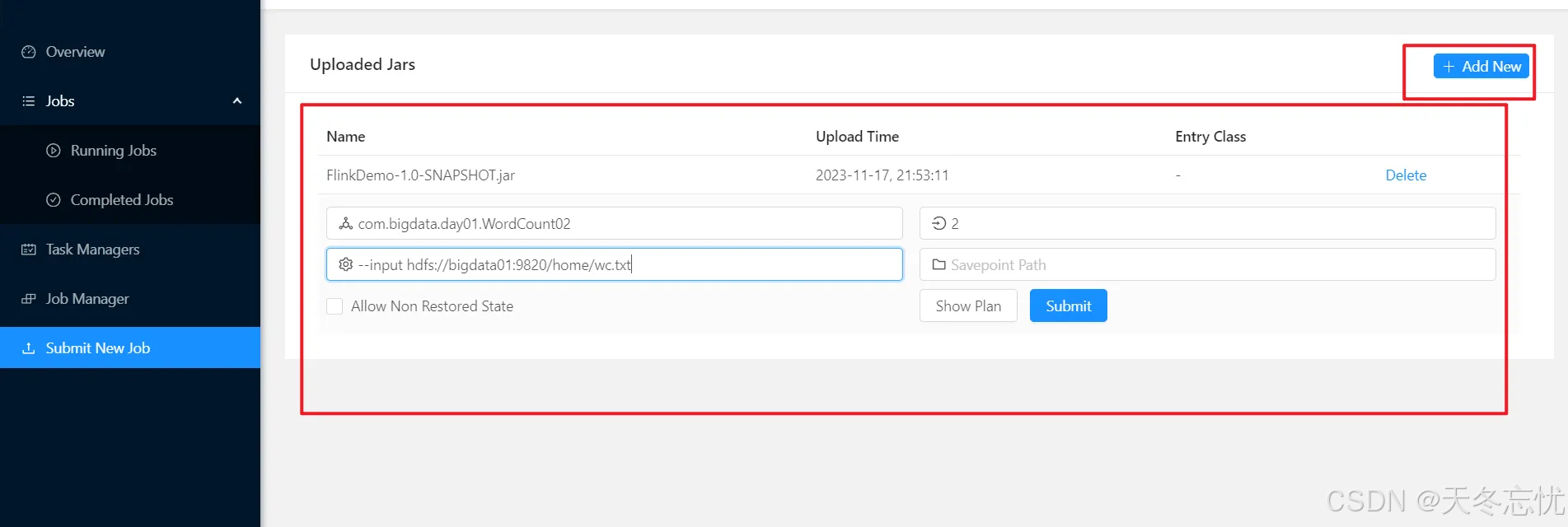
二)命令方式递交
带有自定义 input 参数的提交方式
flink run -c com.bigdata.day01.WordCount02 /opt/app/FlinkDemo-1.0-SNAPSHOT.jar --input /home/wc.txt 通过-c指定主类,后面紧跟 JAR 包路径,再用--input传递自定义输入路径参数,精准指向数据源。
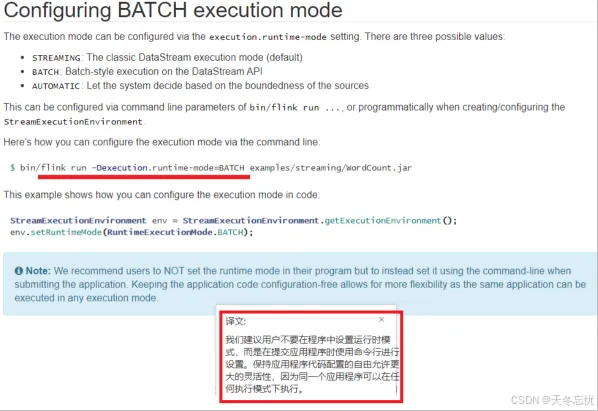
带有运行模式的提交方式
flink run -Dexecution.runtime-mode=BATCH -c com.bigdata.day01.WordCount02 /opt/app/FlinkDemo-1.0-SNAPSHOT.jar --input hdfs://bigdata01:9820/home/wc.txt 借助-Dexecution.runtime-mode设置运行模式(此处为BATCH批处理模式,也可按需设为STREAMING流处理模式),适配不同数据特性与业务场景需求。
六、总结
通过上述步骤,我们完整历经 Flink 任务从编码构思、依 API 规范编写、打包整合再到集群提交运行的全周期。无论是在本地测试验证,还是最终上线集群处理海量数据,只要牢牢把控各环节要点、规避常见 “坑洼”,就能让 Flink 充分施展其大数据处理 “魔力”,高效驱动业务数据流转与价值挖掘。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











