







自定义 Kafka 脚本 kf-use.sh 的解析与功能与应用示例-优快云博客
Kafka 生产者全面解析:从基础原理到高级实践-优快云博客
Kafka 工作流程解析:从 Broker 工作原理、节点的服役、退役、副本的生成到数据存储与读写优化-优快云博客
Kafka 消费者全面解析:原理、消费者 API 与Offset 位移-优快云博客
Kafka 分区分配及再平衡策略深度解析与消费者事务和数据积压的简单介绍-优快云博客
Kafka 核心要点解析_kafka mirrok-优快云博客
Kafka 核心问题深度解析:全面理解分布式消息队列的关键要点_kafka队列日志-优快云博客
目录
(二)__consumer_offsets主题存储结构与原理
九、Kafka 中数据挤压太多,怎么办?(提高消费者的效率)
十、Kafka 中的数据在消费过程中,有漏消费和重复消费的情况,怎么办?
十一、Kafka 中的数据已经消费过的数据,是否可以再次消费?怎么做?
(一)可再次消费的情况及通过auto.offset.reset参数实现的方式
(二)通过seek方法实现重新消费指定位置数据的方式及注意事项
在当今大数据与分布式系统蓬勃发展的时代,Kafka 作为一款卓越的分布式消息队列系统,扮演着极为关键的角色。它在数据处理流程中承担着高效传输、存储与分发数据的重任,为众多复杂的业务场景提供了坚实的基础支撑。无论是大规模数据的实时处理,还是不同系统间的可靠数据传递,Kafka 的性能与功能都备受瞩目。深入探究 Kafka 的内部工作机制,对于优化系统架构、提升数据处理效率以及保障业务的稳定运行具有不可忽视的重要意义。
一、Kafka 是如何做到高效读写?
Kafka 实现高效读写主要依赖于以下几个关键机制:
(一)分区技术与并行处理
Kafka 作为分布式集群,采用分区技术将主题划分为多个分区。每个分区可分布在不同节点,生产者能并行向各分区写入数据,消费者组内多个消费者也可同时从不同分区读取数据,极大提升了系统的并行度和吞吐量。例如,一个主题有多个分区,不同的生产者线程或进程可针对不同分区独立发送消息,而多个消费者可并行处理不同分区的数据,避免了单点瓶颈,充分利用了集群资源。
(二)稀疏索引与快速定位
在数据存储方面,Kafka 使用稀疏索引。这种索引并非对每条数据都建立索引项,而是按照一定间隔建立,从而在减少索引存储空间的同时,仍能快速定位数据大致范围。当需要读取特定 offset 的数据时,先通过稀疏索引确定数据所在的 segment 范围,然后在该 segment 内进一步查找,显著提高了数据定位速度,相比全量索引方式,大大减少了索引维护成本和查找时间开销。
(三)顺序写磁盘优化
Kafka 的生产者写入数据到 log 文件时采用顺序写机制,即数据始终追加到文件末尾。由于磁盘的物理特性,顺序写相较于随机写可省去大量磁头寻址时间。实验数据表明,相同磁盘上顺序写速度可达 600M/s,而随机写仅约 100K/s。这种顺序写方式充分利用了磁盘的顺序读写性能优势,使得 Kafka 在数据写入方面表现卓越,即使面对高并发写入场景,也能高效处理。
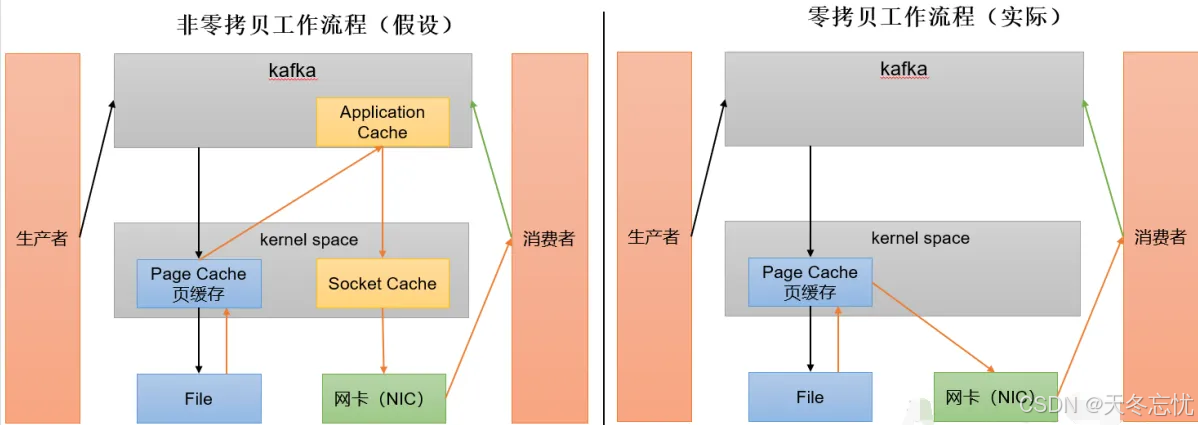
(四)页缓存与零拷贝技术协同
- 零拷贝原理与优势:Kafka 利用零拷贝技术,将数据在网络传输过程中的拷贝次数和上下文切换次数降至最低。数据无需在应用层进行多次不必要的拷贝,而是直接在内核缓冲区之间进行传输,从磁盘读取的数据可直接通过网络接口发送给消费者,减少了 CPU 和内存资源的消耗,提高了数据传输效率。
- PageCache页缓存机制与作用:Kafka 重度依赖操作系统的页缓存功能。当数据写入时,操作系统首先将数据写入页缓存,而非立即写入磁盘。读取数据时,优先从页缓存中查找,如果命中则直接返回数据,避免了磁盘 I/O 操作。只有当页缓存中的数据达到一定阈值或需要持久化时,才会将数据同步到磁盘。这种机制将内存作为磁盘缓存使用,充分发挥了内存的高速读写特性,进一步提升了数据读写性能,类似于 MySQL 中的 buffer pool 机制,有效减少了磁盘访问次数,提高了整体系统性能。
二、Kafka 集群中数据的存储是按照什么方式存储的?
Kafka 数据存储基于 Topic 和 Partition 概念展开:
(一)基于 Topic 和 Partition 的存储结构
Topic 是逻辑上对消息的分类,而 Partition 是物理存储单元。每个 Partition 对应一个 log 文件,生产者生成的数据会被顺序追加到所属 Partition 的 log 文件末端。例如,对于名为 “first” 的 Topic,可能存在 “first - 0”、“first - 1” 等多个分区,每个分区文件夹下包含了与该分区相关的多种文件,如 “.index” 索引文件、“.log” 日志文件以及 “.timeindex” 时间索引文件等。这些文件共同构成了分区的数据存储体系,确保数据的有序存储和高效检索。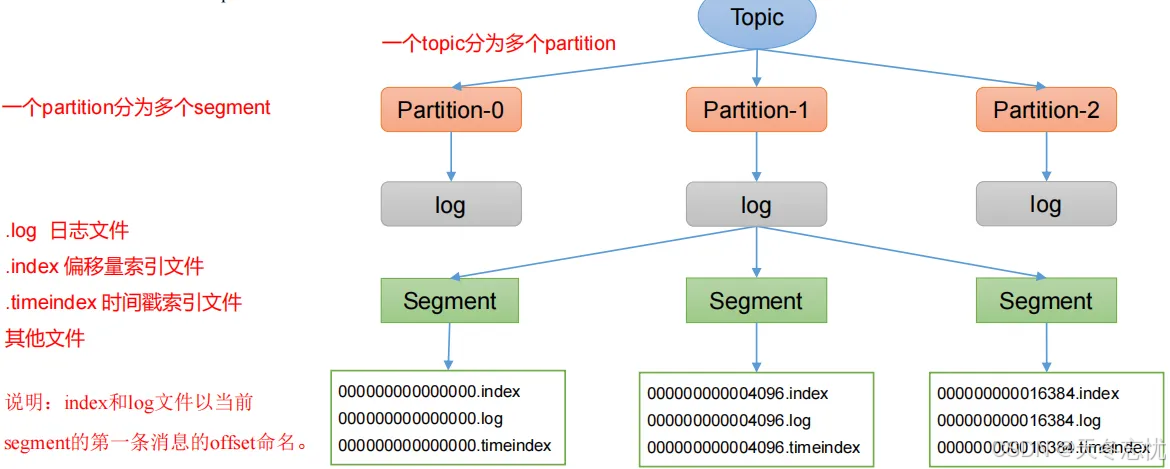
(二)分片和索引机制详解
为应对 log 文件可能过大导致的数据定位效率低下问题,Kafka 引入了分片和索引机制。每个 Partition 被划分为多个 segment,每个 segment 包含上述提到的各类文件。其中,索引文件起到了关键作用,它通过建立数据偏移量与物理存储位置的映射关系,使得在读取数据时能够快速定位到指定 offset 的数据在日志文件中的位置。例如,当需要读取某个 offset 的数据时,可先通过索引文件快速确定其所在的 segment,然后在该 segment 的日志文件中准确获取数据,无需对整个 log 文件进行顺序扫描,极大提高了数据读取效率,尤其在处理大规模数据时优势更为明显。
三、Kafka 中是如何快速定位到一个 offset 的?
Kafka 主要通过稀疏索引机制来快速定位 offset:
(一)稀疏索引原理
Kafka 存储数据时采用稀疏索引方式,并非对每条数据都建立索引,而是按照特定间隔建立索引项。这样在查找 offset 时,首先根据索引项快速定位到数据所在的大致 segment 范围。例如,索引可能每隔一定数量的消息记录建立一个索引项,当查询特定 offset 时,通过比较 offset 与索引项的大小关系,能够迅速确定目标数据所在的 segment。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











