






- 实验环境
使用annaconda内的虚拟环境,pyhanlp词典进行词典分类,用vscode进行代码编译运行。
- 实验内容
首先导入 pyhanlp:
from pyhanlp import *
把自己安装 Hanlp 的完整步骤写进实验报告(包括 python 和 java 两部分的安装)。
如果安装时有参考网上的资料,请把资料的链接也写进实验报告中。
HanLP论坛:Butterfly Effect - Natural Language Processing, HanLP
安装视频教程:安装pyhanlp遇到报错,不会解决了 - #2 by feng - 《自然语言处理入门》 - Butterfly Effect
1. 词典加载
采用 HanLP 自带的迷你核心词典,路径为:《自然语言处理入门》随书代码\hanlp-java\HanLP\data\dictionary\CoreNatureDictionary.mini.txt。
在 python 中加载词典的代码参见:《自然语言处理入门》随书代码\hanlp-python\pyhanlp\tests\book\ch02\utility.py
实验代码:
# -*- coding:utf-8 -*-
# Author:hankcs
# Date: 2018-05-24 22:11
# 《自然语言处理入门》2.2.2 词典的加载
# 配套书籍:http://nlp.hankcs.com/book.php
# 讨论答疑:https://bbs.hankcs.com/
from pyhanlp import *
def load_dictionary():
"""
加载HanLP中的mini词库
:return: 一个set形式的词库
"""
IOUtil = JClass('com.hankcs.hanlp.corpus.io.IOUtil')
path = HanLP.Config.CoreDictionaryPath.replace('.txt', '.mini.txt')
dic = IOUtil.loadDictionary([path])
return set(dic.keySet())
if __name__ == '__main__':
dic = load_dictionary()
print(len(dic))
print(list(dic)[0])
实验结果截图:

基于词典的中文分词
2. 完全切分
完全切分指的是,找出一段文本中的所有单词。只要遍历文本中的连续序列,
查询该序列是否在词典中即可。
代码参见:《自然语言处理入门》随书代码
\hanlp-python\pyhanlp\tests\book\ch02\fully_segment.py。
测试句子:
(1)结婚的和尚未结婚的确实在干扰分词啊
(2)中国的首都是北京
(3)随着页游兴起到现在的页游繁盛,依赖于存档进行逻辑判断的设计减少了,但这 块也不能完全忽略掉。
(4)歼-10 飞机拉出七道绚丽的彩烟,庆祝新中国成立 70 周年
(5)这样的人才能经受住考验
(6)将信息技术应用于教学实践
(7)信息技术应用于教学中的哪个方面
(8)人要是行,干一行行一行一行行行行行要是不行干一行不行一行一行不行行行不行
(9)四川人用普通话与川普通电话
(10)他说的确实在理
实验代码:
# -*- coding:utf-8 -*-
# Author:hankcs
# Date: 2018-05-22 21:05
# 《自然语言处理入门》2.3.1 完全切分
# 配套书籍:http://nlp.hankcs.com/book.php
# 讨论答疑:https://bbs.hankcs.com/
from utility import load_dictionary
def fully_segment(text, dic):
word_list = []
for i in range(len(text) # i 从 0 到text的最后一个字的下标遍历
for j in range(i + 1, len(text) + 1): # j 遍历[i + 1, len(text)]区间
word = text[i:j] # 取出连续区间[i, j]对应的字符串
if word in dic: # 如果在词典中,则认为是一个词
word_list.append(word)
return word_list
if __name__ == '__main__':
dic = load_dictionary()
print(fully_segment('结婚的和尚未结婚的确实在干扰分词啊', dic))
print(fully_segment('中国的首都是北京', dic))
print(fully_segment('随着页游兴起到现在的页游繁盛,依赖于存档进行逻辑判断的设计减少了,但这块也不能完全忽略掉', dic))
print(fully_segment('歼-10 飞机拉出七道绚丽的彩烟,庆祝新中国成立 70 周年', dic))
print(fully_segment('这样的人才能经受住考验', dic))
print(fully_segment('将信息技术应用于教学实践', dic))
print(fully_segment('信息技术应用于教学中的哪个方面', dic))
print(fully_segment('人要是行,干一行行一行一行行行行行要是不行干一行不行一行一行不行行行不行', dic))
print(fully_segment('四川人用普通话与川普通电话', dic))
print(fully_segment('他说的确实在理', dic))
实验结果截图:
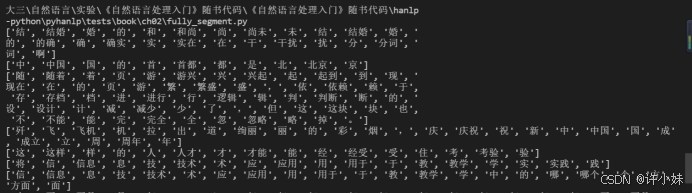
3. 正向最长匹配
从前往后逐个下标递增查词过程中,优先输出更长的单词。
代码参见:《自然语言处理入门》随书代码
\hanlp-python\pyhanlp\tests\book\ch02\forward_segment.py。
测试句子:
(1)中国的首都是北京
(2)随着页游兴起到现在的页游繁盛,依赖于存档进行逻辑判断的设计减少了,但这块也不能完全忽略掉。
(3)歼-10 飞机拉出七道绚丽的彩烟,庆祝新中国成立 70 周年
(4)将信息技术应用于教学实践
(5)信息技术应用于教学中的哪个方面
(6)人要是行,干一行行一行一行行行行行要是不行干一行不行一行一行不行行行不行
实验代码:
# -*- coding:utf-8 -*-
# Author:hankcs
# Date: 2018-05-22 21:05
# 《自然语言处理入门》2.3.2 正向最长匹配
# 配套书籍:http://nlp.hankcs.com/book.php
# 讨论答疑:https://bbs.hankcs.com/
from utility import load_dictionary
# 定义正向最长匹配算法
def forward_segment(text, dic):
word_list = []
i = 0
while i < len(text):
longest_word = text[i] # 当前扫描位置的单字
for j in range(i + 1, len(text) + 1): # 所有可能的结尾
word = text[i:j] # 从当前位置到结尾的连续字符串
if word in dic: # 在词典中
if len(word) > len(longest_word): # 并且更长
longest_word = word # 则更优先输出
word_list.append(longest_word) # 输出最长词
i += len(longest_word) # 正向扫描
return word_list
if __name__ == '__main__':
# 加载词典
dic = load_dictionary()
print(forward_segment('中国的首都是北京', dic))
print(forward_segment('随着页游兴起到现在的页游繁盛,依赖于存档进行逻辑判断的设计减少了,但这 块也不能完全忽略掉。', dic))
print(forward_segment('歼-10 飞机拉出七道绚丽的彩烟,庆祝新中国成立 70 周年', dic))
print(forward_segment('将信息技术应用于教学实践 ', dic))
print(forward_segment('信息技术应用于教学中的哪个方面', dic))
print(forward_segment('人要是行,干一行行一行一行行行行行要是不行干一行不行一行一行不行行行不 行', dic))
实验结果截图:
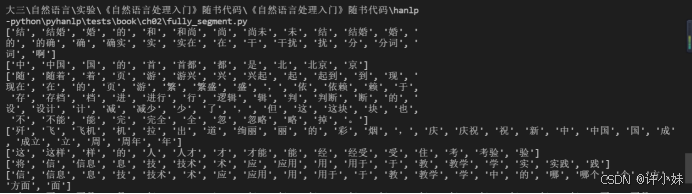
4. 逆向最长匹配
从后往前逐个下标递增查词过程中,优先输出更长的单词。
代码参见:《自然语言处理入门》随书代码
\hanlp-python\pyhanlp\tests\book\ch02\backward_segment.py
测试句子:
(1)结婚的和尚未结婚的确实在干扰分词啊
(2)中国的首都是北京
(3)随着页游兴起到现在的页游繁盛,依赖于存档进行逻辑判断的设计减少了,但这块也不能完全忽略掉。
(5)歼-10 飞机拉出七道绚丽的彩烟,庆祝新中国成立 70 周年
(6)人要是行,干一行行一行一行行行行行要是不行干一行不行一行一行不行行行不行
(7)四川人用普通话与川普通电话
(8)他说的确实在理
实验代码:
# -*- coding:utf-8 -*-
# Author:hankcs
# Date: 2018-05-22 21:05
# 《自然语言处理入门》2.3.3 逆向最长匹配
# 配套书籍:http://nlp.hankcs.com/book.php
# 讨论答疑:https://bbs.hankcs.com/
from utility import load_dictionary
def backward_segment(text, dic):
word_list = []
i = len(text) - 1
while i >= 0: # 扫描位置作为终点
longest_word = text[i] # 扫描位置的单字
for j in range(0, i): # 遍历[0, i]区间作为待查询词语的起点
word = text[j: i + 1] # 取出[j, i]区间作为待查询单词
if word in dic:
if len(word) > len(longest_word): # 越长优先级越高
longest_word = word
break
word_list.insert(0, longest_word) # 逆向扫描,所以越先查出的单词在位置上越靠后
i -= len(longest_word)
return word_list
if __name__ == '__main__':
dic = load_dictionary()
print(backward_segment('结婚的和尚未结婚的确实在干扰分词啊', dic))
print(backward_segment('中国的首都是北京', dic))
print(backward_segment('随着页游兴起到现在的页游繁盛,依赖于存档进行逻辑判断的设计减少了,但这块也不能完全忽略掉', dic))
print(backward_segment('歼-10 飞机拉出七道绚丽的彩烟,庆祝新中国成立 70 周年', dic))
print(backward_segment('这样的人才能经受住考验', dic))
print(backward_segment('人要是行,干一行行一行一行行行行行要是不行干一行不行一行一行不行行行不行', dic))
print(backward_segment('四川人用普通话与川普通电话', dic))
print(backward_segment('他说的确实在理', dic))
实验结果截图:
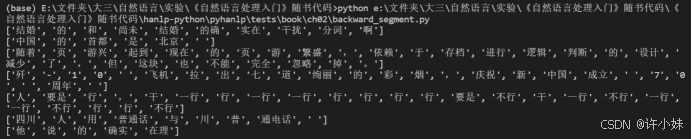
5. 双向匹配
步骤如下:
1. 同时执行正向和逆向最长匹配,若两者的词数不同,则返回词数更少的那一
个。
2. 否则,返回两者中单字更少的那一个。当单字数也相同时,优先返回逆向最
长匹配的结果。
代码参见:
《自然语言处理入门》随书代码\hanlp-python\pyhanlp\tests\book\ch02\
bidirectional_segment.py。
测试句子:
(1)结婚的和尚未结婚的确实在干扰分词啊
(2)中国的首都是北京
(3)随着页游兴起到现在的页游繁盛,依赖于存档进行逻辑判断的设计减少了,但这块也不能完全忽略掉。
(4)歼-10 飞机拉出七道绚丽的彩烟,庆祝新中国成立 70 周年
(5)将信息技术应用于教学实践
(6)人要是行,干一行行一行一行行行行行要是不行干一行不行一行一行不行行行不行
(7)他说的确实在理
实验代码:
# -*- coding:utf-8 -*-
# Author:hankcs
# Date: 2018-05-24 21:23
# 《自然语言处理入门》2.3.4 双向最长匹配
# 配套书籍:http://nlp.hankcs.com/book.php
# 讨论答疑:https://bbs.hankcs.com/
from backward_segment import backward_segment
from forward_segment import forward_segment
from utility import load_dictionary
def count_single_char(word_list: list): # 统计单字成词的个数
return sum(1 for word in word_list if len(word) == 1)
def bidirectional_segment(text, dic):
f = forward_segment(text, dic)
b = backward_segment(text, dic)
if len(f) < len(b): # 词数更少优先级更高
return f
elif len(f) > len(b):
return b
else:
if count_single_char(f) < count_single_char(b): # 单字更少优先级更高
return f
else:
return b # 都相等时逆向匹配优先级更高
if __name__ == '__main__':
dic = load_dictionary()
print(bidirectional_segment('结婚的和尚未结婚的确实在干扰分词啊', dic))
print(bidirectional_segment('中国的首都是北京', dic))
print(bidirectional_segment('随着页游兴起到现在的页游繁盛,依赖于存档进行逻辑判断的设计减少了,但这块也不能完全忽略掉', dic))
print(bidirectional_segment('歼-10 飞机拉出七道绚丽的彩烟,庆祝新中国成立 70 周年', dic))
print(bidirectional_segment('将信息技术应用于教学实践', dic))
print(bidirectional_segment('人要是行,干一行行一行一行行行行行要是不行干一行不行一行一行不行行行不行', dic))
print(bidirectional_segment('他说的确实在理', dic))
实验结果截图:

- 代码分析
对正向最长匹配的代码进行分析:首先,代码从utility.py中导入了load_dictionary函数,这个函数用于加载词典。然后,定义了forward_segment函数,该函数接受一个文本字符串和一个词典作为输入,并返回分词结果。在forward_segment函数中,通过一个循环遍历文本字符串。循环过程中,首先将当前位置的单字设为最长词,默认为当前单字。然后从当前位置开始,依次将当前位置到文本结尾的连续字符串作为候选词进行检查。如果候选词在词典中存在,并且比当前最长词更长,则将候选词作为最长词。循环结束后,将最长词添加到word_list中,并将当前位置前进到最长词的长度。最后,当代码作为主程序执行时,先加载词典,然后对两个示例句子进行正向最长匹配分词,并输出结果。
1、在刚开始运行代码时,遇到以下问题:
File "E:\data\hlp\hanlp-python\pyhanlp\tests\book\ch02\forward_segment.py", line 7, in <module> from tests.book.ch02.utility import load_dictionary
ModuleNotFoundError: No module named 'tests.book'
通过查阅有以下解决办法:(1)确保你已经正确安装了需要的依赖项。根据错误信息,你可能需要安装 pyhanlp 模块。你可以使用命令 pip install pyhanlp 来安装它。
(2)检查文件路径是否正确。确认 forward_segment.py 和 utility.py 文件存在于正确的位置。根据错误信息,它们应该位于 E:\data\hlp\hanlp-python\pyhanlp\tests\book\ch02 目录下。
(3)确保路径中使用的目录分隔符是正确的。在 Windows 系统中,目录分隔符应该是反斜杠 \。如果你在其他操作系统上运行代码,可能需要将路径中的反斜杠改为正斜杠 /。
(4)检查文件路径是否包含特殊字符或空格。特殊字符和空格可能导致导入失败,请确保路径不包含这些字符。
最终的解决办法是:将from tests.book.ch02.utility import load_dictionary
中的tests.book.ch02.进行删减便能解决该问题。
2、对完全切分、正向、逆向、双向匹配运行结果的速度测评实验:
实验代码:
#"""速度测评"""
import os
import sys
import time
from matplotlib import pyplot as plt
sys.path.append(os.pardir) # 为了导入父目录的文件而进行的设定
from utility import load_dictionary
from forward_segment import forward_segment
from backward_segment import backward_segment
from bidirectional_segment import bidirectional_segment
from fully_segment import fully_segment
def evaluate_speed(segment, text, dictionary):
"""
评测速度
:param segment: 匹配规则
:param text: 待切分的文本
:param dictionary: 词典
:return: 运行速度
"""
start_time = time.time()
for i in range(pressure):
segment(text, dictionary)
elapsed_time = time.time() - start_time
return len(text) * pressure / 10000 / elapsed_time
if __name__ == "__main__":
text = "江西鄱阳湖干枯,中国最大淡水湖变成大草原。"
pressure = 10000
segment_list = [{
"name": "完全切分",
"segment": fully_segment
}, {
"name": "正向",
"segment": forward_segment
}, {
"name": "逆向",
"segment": backward_segment
}, {
"name": "双向",
"segment": bidirectional_segment
}]
dic = load_dictionary()
count_list = []
x_list = []
for segment in segment_list:
speed = evaluate_speed(segment.get("segment"), text, dic)
count_list.append(speed)
x_list.append(segment.get("name"))
plt.rcParams["font.sans-serif"] = ['SimHei'] # 正常显示中文
plt.rcParams["axes.unicode_minus"] = False # 正常显示负号
plt.bar(x_list, count_list, width=0.3, color="#409eff", label="python")
plt.legend()
plt.xlabel("匹配规则")
plt.ylabel("万字/秒")
plt.title("词典分词中文4种规则速度对比")
for a, b in zip(x_list, count_list): # 柱子上的数字显示
plt.text(a, b, "%.2f" % b, ha="center", va="bottom", fontsize=10)
plt.show()
实验结果:
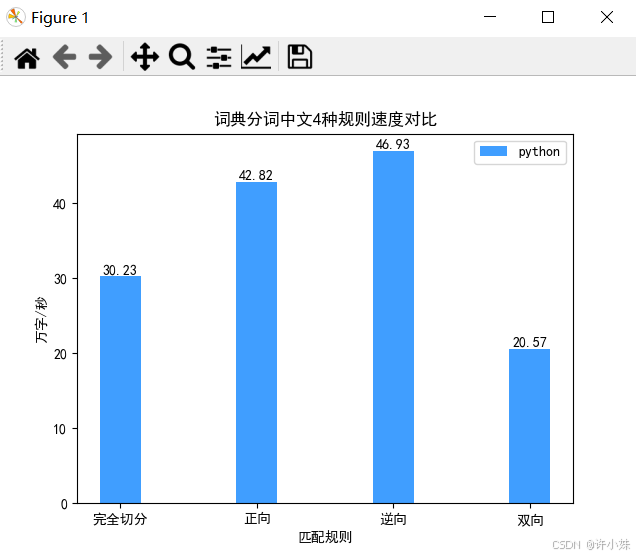
实验结果分析:
正向匹配和逆向匹配的速度差不多,是双向的两倍。这在意料之中,因为双向匹配做了两倍的工作。

















 2250
2250

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









