






冒泡排序是一种简单直观的排序算法。它重复地遍历要排序的列表,一次比较两个元素,如果它们的顺序错误就把它们交换过来。遍历列表的工作是重复地进行直到没有再需要交换,也就是说列表已经排序完成。这个算法的名字由于越小的元素会经由交换慢慢“浮”到数列的顶端,故名。
这个过程好比是在一个水池中不断冒泡的气泡,较大的气泡会先浮出水面。这就是为什么这个算法被称为“冒泡排序”的原因。冒泡排序的时间复杂度为O(n^2),其中n是列表的长度。尽管冒泡排序在大多数情况下效率较低,但它容易理解和实现,适用于小型数据集的排序。
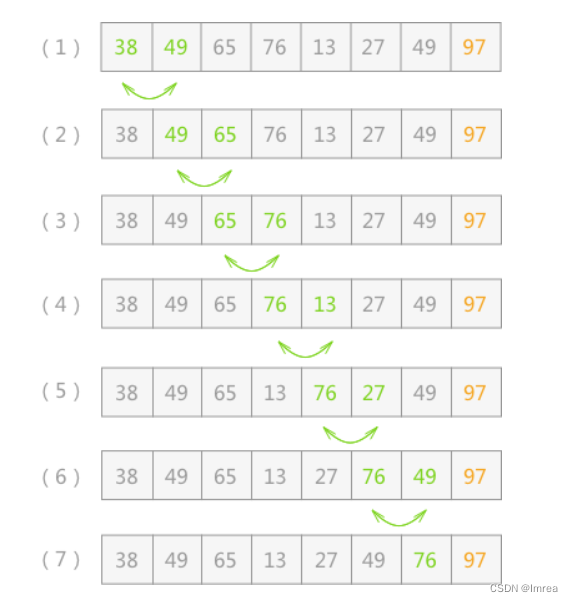
例如,对无序表{49,38,65,97,76,13,27,49}进行升序排序的具体实现过程如图 1 所示:

如图 1 所示是对无序表的第一次起泡排序,最终将无序表中的最大值 97 找到并存储在表的最后一个位置。具体实现过程为:
- 首先 49 和 38 比较,由于 38<49,所以两者交换位置,即从(1)到(2)的转变;
- 然后继续下标为 1 的同下标为 2 的进行比较,由于 49<65,所以不移动位置,(3)中 65 同 97 比较得知,两者也不需要移动位置;
- 直至(4),97 同 76 进行比较,76<97,两者交换位置,如(5)所示;
- 同样 97>13(5)、97>27(6)、97>49(7),所以经过一次冒泡排序,最终在无序表中找到一个最大值 97,第一次冒泡结束;
由于 97 已经判断为最大值,所以第二次冒泡排序时就需要找出除 97 之外的无序表中的最大值,比较过程和第一次完全相同。
经过第二次冒泡,最终找到了除 97 之外的又一个最大值 76,比较过程完全一样,这里不再描述。
#include <stdio.h>
//交换 a 和 b 的位置的函数
void swap(int *a, int *b);
int main()
{
int array[8] = {49,38,65,97,76,13,27,49};
int i, j;
int key;
//有多少记录,就需要多少次冒泡,当比较过程,所有记录都按照升序排列时,排序结束
for (i = 0; i < 8; i++){
key=0;//每次开始冒泡前,初始化 key 值为 0
//每次起泡从下标为 0 开始,到 8-i 结束
for (j = 0; j+1<8-i; j++){
if (array[j] > array[j+1]){
key=1;
swap(&array[j], &array[j+1]);
}
}
//如果 key 值为 0,表明表中记录排序完成
if (key==0) {
break;
}
}
for (i = 0; i < 8; i++){
printf("%d ", array[i]);
}
return 0;
}
void swap(int *a, int *b){
int temp;
temp = *a;
*a = *b;
*b = temp;
}


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











