







 本文详细阐述了Kafka作为消息队列在解耦、削峰、扩展、高吞吐和容灾性方面的优势,以及其通过顺序读写、页缓存、零拷贝和分区机制实现高性能的方法。还介绍了分区策略、leader选举和副本机制,以及与数据库的比较和消费者偏移更新的两种方式。
本文详细阐述了Kafka作为消息队列在解耦、削峰、扩展、高吞吐和容灾性方面的优势,以及其通过顺序读写、页缓存、零拷贝和分区机制实现高性能的方法。还介绍了分区策略、leader选举和副本机制,以及与数据库的比较和消费者偏移更新的两种方式。
为什么要使用 Kafka 消息队列?
解耦、削峰:传统的方式上游发送数据下游需要实时接收,如果上游在某些业务场景:例如上午十点会流量激增至顶峰,那么下游资源可能会扛不住压力。但如果使用消息队列,就可以将消息暂存在消息管道中,下游可以按照自己的速度逐步处理;
可扩展:通过横向扩展生产者、消费者和 broker, Kafka 可以轻松处理巨大的消息流;
高吞吐、低延迟:在一台普通的服务器上既可以达到 10W/s 的吞吐速率;
容灾性:kafka 通过副本 replication 的设置和 leader/follower 的容灾机制保障了消息的安全性。
kafka 的高吞吐、低延迟是如何实现的?
1. 顺序读写
Kafka 使用磁盘顺序读写来提升性能
顺序读写和随机读写性能对比:
| 顺序读 | 随机读 | 顺序写 | 随机写 | |
|---|---|---|---|---|
| 机械硬盘 | 84.0MB/s | 0.033MB/s (512 字节) | 79.0MB/s | 0.083MB/s (512 字节) |
| 固态硬盘 | 220.7MB/s | 5.296MB/s (512 字节) | 77.2MB/s | 10.203MB/s (512 字节) |
从数据可以看出磁盘的顺序读写速度远高于随机读写的速度,这是因为传统的磁头探针结构,随机读写时需要频繁寻道,也就需要磁头和探针频繁的转动,而机械结构的磁头和探针的位置调整是十分费时的,这就严重影响到硬盘的寻址速度,进而影响到随机写入速度。
Kafka 的 message 是不断追加到本地磁盘文件末尾的,而不是随机的写入,这使得 Kafka 写入吞吐量得到了显著提升 。每一个 Partition 其实都是一个文件 ,收到消息后 Kafka 会把数据插入到文件末尾。
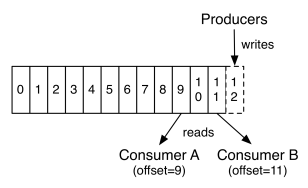
2. 页缓存(pageCache)
PageCache 是系统级别的缓存,它把尽可能多的空闲内存当作磁盘缓存使用来进一步提高 IO 效率;
PageCache 同时可以避免在 JVM 内部缓存数据,避免不必要的 GC、以及内存空间占用。对于 In-Process Cache,如果 Kafka 重启,它会失效,而操作系统管理的 PageCache 依然可以继续使用。
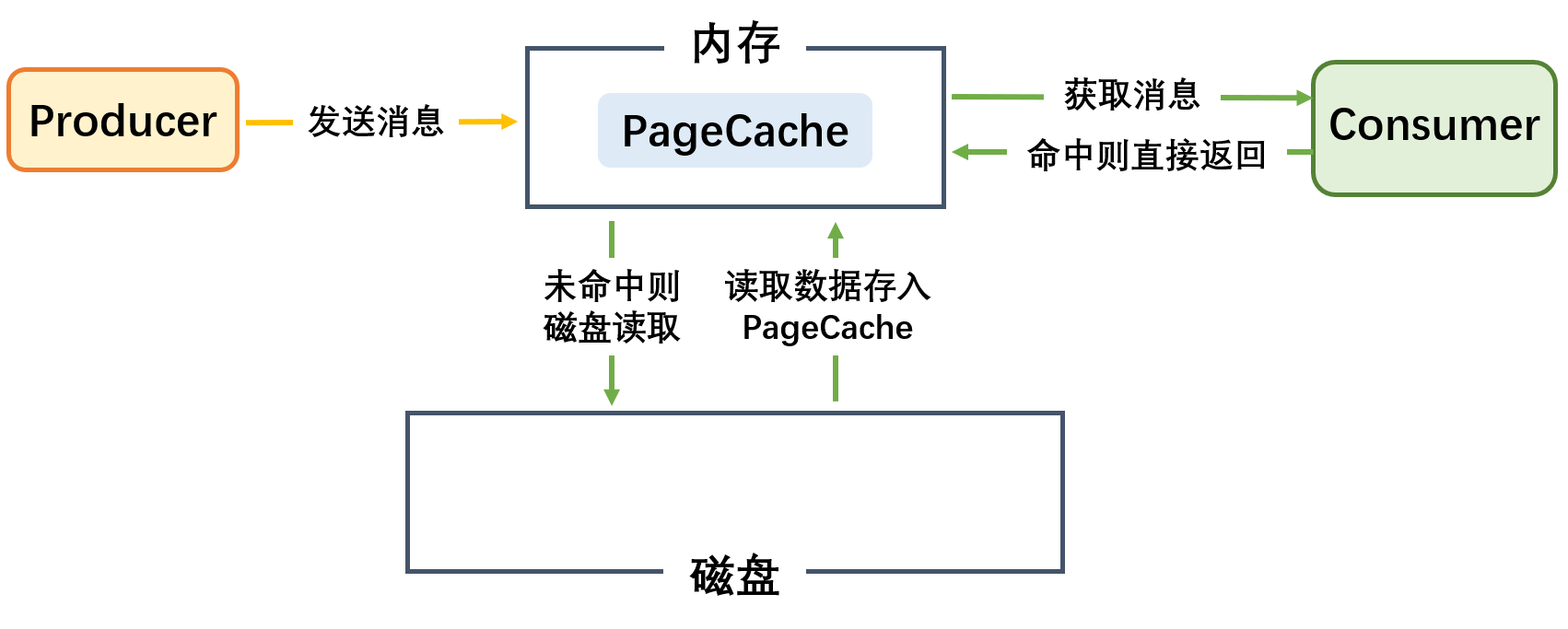
- producer 把消息发到 broker 后,数据并不是直接落入磁盘的,而是先进入 PageCache。PageCache 中的数据会被内核中的处理线程采用同步或异步的方式定期刷盘至磁盘。
- Consumer 消费消息时,会先从 PageCache 获取消息,获取不到才回去磁盘读取,并且会预读出一些相邻的块放入 PageCache,以方便下一次读取。
- 如果 Kafka producer 的生产速率与 consumer 的消费速率相差不大,那么几乎只靠对 broker PageCache 的读写就能完成整个生产和消费过程,磁盘访问非常少
3. 零拷贝
正常过程:
- 操作系统将数据从磁盘上读入到内核空间的读缓冲区中
- 应用程序(也就是 Kafka)从内核空间的读缓冲区将数据拷贝到用户空间的缓冲区中
- 应用程序将数据从用户空间的缓冲区再写回到内核空间的 socket 缓冲区中
- 操作系统将 socket 缓冲区中的数据拷贝到 NIC 缓冲区中,然后通过网络发送给客户端
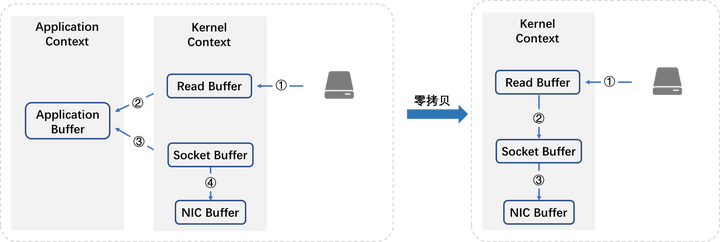
在这个过程中,可以发现, 数据从磁盘到最终发出去,要经历 4 次拷贝,而在这四次拷贝过程中, 有两次拷贝是浪费的。
1. 从内核空间拷贝到用户空间;
2. 从用户空间再次拷贝到内核空间;
除此之外,由于用户空间和内核空间的切换,会带来 Cpu 上下文切换,对于 Cpu
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 3543
3543

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









