







 文章介绍了数据库的高级查询技巧,包括SELECT查询的进阶操作,如聚合函数和GROUPBY分组,以及数据库约束如NOTNULL、UNIQUE和FOREIGNKEY。还探讨了索引的概念,特别是B+树作为索引背后的数据结构,以及事务的四大特性,强调了事务在确保数据一致性和原子性方面的重要性。
文章介绍了数据库的高级查询技巧,包括SELECT查询的进阶操作,如聚合函数和GROUPBY分组,以及数据库约束如NOTNULL、UNIQUE和FOREIGNKEY。还探讨了索引的概念,特别是B+树作为索引背后的数据结构,以及事务的四大特性,强调了事务在确保数据一致性和原子性方面的重要性。
select 查询进阶操作
在上一篇有关数据库的介绍中,我们介绍了比较简单的sql命令,今天我们需要了解一下比较复杂的查询操作。
数据库约束
我们说数据库是用来组织数据,存储数据,管理数据的,在存储数据时肯定会有一些条件,例如学校的数据库中,存储学生的信息,每个学生的学号需要唯一,如果通过程序员去检测和管理,那么必然会有疏忽的时候,数据库为我们解决了这个问题,约束就是根据数据库中能写什么而给出的一组检测机制,使用约束让计算机去筛选数据,这样就会提高数据库的效率。
| 约束 | 作用 |
|---|---|
NOT NULL | 指示某列不能存储 NULL 值。 |
UNIQUE | 保证某列的每行必须有唯一的值。 |
DEFAULT | 规定没有给列赋值时的默认值。 |
PRIMARY KEY | NOT NULL 和 UNIQUE 的结合。确保某列(或两个列多个列的结合)有唯一标识,有助于更容易更快速地找到表中的一个特定的记录。 |
FOREIGN KEY | 保证一个表中的数据匹配另一个表中的值的参照完整性。 |
CHECK | 保证列中的值符合指定的条件。对于MySQL数据库,对CHECK子句进行分析,但是忽略CHECK子句。 |
在创建表的时候给出这些约束,就可以对可以录入的数据进行一些约束。
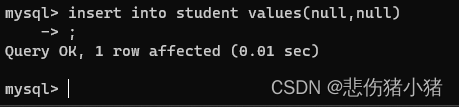
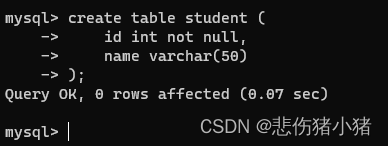
我们看此时student表中可以随意插入null值,我们使用NOt NULL重新见表:create table student ( id int not null, name varchar(50) );
再次插入null值,MySQL报错了,说id不可以为空,这就是约束的作用。

这里面值得重点讲解一下的就是primary key 和foreign key这两个约束前者被称为主键后者被称为外键,主键就是一条记录在表中的身份标识他要求唯一并且不能为空。
外键是用来约束两张表,一个是父表一个是子表,父亲对儿子有一定的约束,儿子对父亲也有一定的约束。具体有什么约束可以看下面的例子。
下面我们来演示一下:
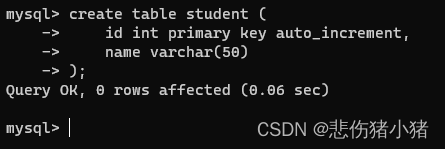
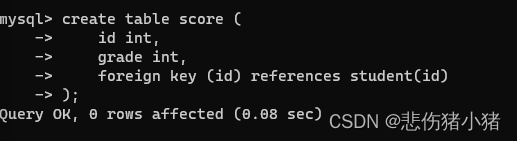
此时我们创建了两张表,我们分别向两张表中添加数据。
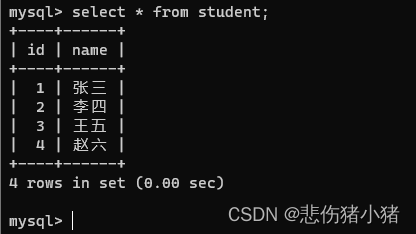
首先向student表中添加数据
insert into student values (null,'张三'),(null,'李四'),(null,'王五'),(null,'赵六');
我们看到了我们插入语句中写的是null而插入表中的数据是1、2、3、4,此时我们称为自增主键,id这一列的数据就是不为空并且唯一的。
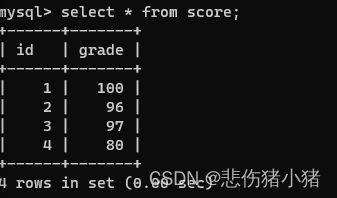
之后向score表中插入学生的成绩,
insert into score values (1,100),(2,96),(3,97),(4,80);
插入成功,我们发现好像外键也没有什么作用啊,我们再次插入一个数据。insert into score values (5,99);
此时就出现了问题,因为id为5的学生在student表中并不存在,并且score将student表中的学生id设置为了外键,所以在score中插入的id必须在student表中存在才可以插入成功。这就是外键的作用,因为必须现有学生才有学生的成绩嘛。此时我们就说score表受到了student表的约束,所以score表就是子表student表就是父表,父亲约束儿子,相反student表中要删除数据也要考虑子表。

聚合查询
聚合函数
在使用数据库管理数据时,肯定会涉及到求一组数据的最大值,最小值等需求,类似于这种简单的统计操作,我们就可以使用聚合函数来完成。
| 聚合函数 | 说明 |
|---|---|
COUNT([DISTINCT] expr) | 返回查询到的数据的 数量 |
SUM([DISTINCT] expr) | 返回查询到的数据的 总和,不是数字没有意义 |
AVG([DISTINCT] expr) | 返回查询到的数据的 平均值,不是数字没有意义 |
MAX([DISTINCT] expr) | 返回查询到的数据的 最大值,不是数字没有意义 |
MIN([DISTINCT] expr) | 返回查询到的数据的 最小值,不是数字没有意义 |
下面我们来简单演示一下:
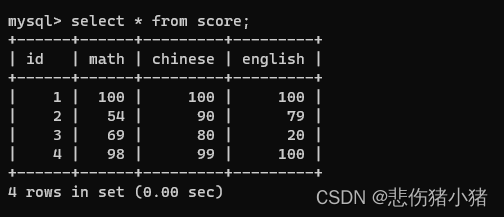
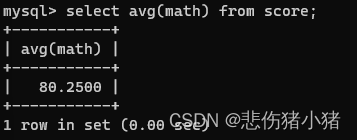
我们有这样的一组数据,我们需要查看数学成绩的平均成绩就可以使用这样的sql命令:select avg(math) from score;
GROUP BY
分组查询,在管理数据时,经常会对数据进行分组,此时我们就可以使用group by这个操作。
我们有这样的一张表:
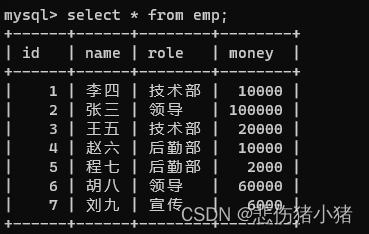
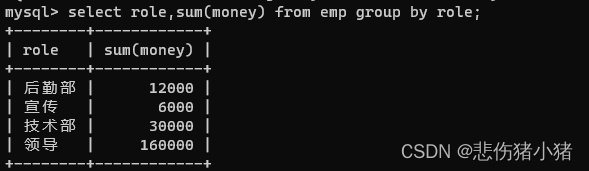
我们查询每个部门的工资总和就可以使用这样的语句select role,sum(money) from emp group by role;
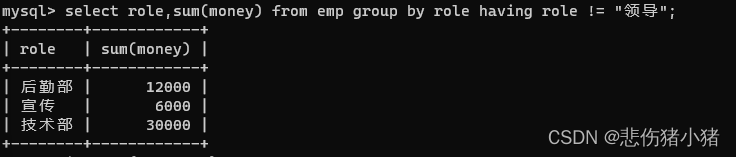
分组查询时也可以对查询数据进行筛选,在分组前我们使用where分组后我们使用having。
select role,sum(money) from emp group by role having role != "领导";
联合查询
在我们日常使用数据库时,有很多数据并不在一张表上,那我们就需要使用联合查询,将两张表上的数据整合到一起。
笛卡尔积
我们现在有这样两张表:
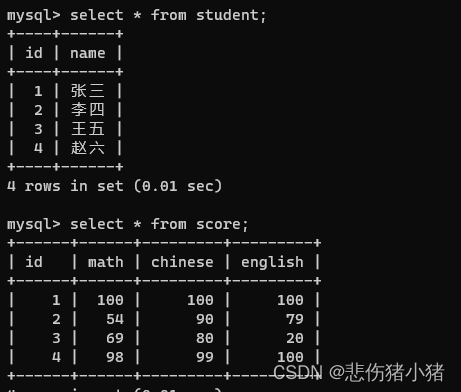
此时我们希望同时查询学生姓名和该学生的成绩,就可以使用联合查询。此时的操作是,将student表中的一行数据与score表中的每一行数据都放在一下进行排列组合,此时我们得到的结果如下,被称为笛卡尔积。select * from score,student;
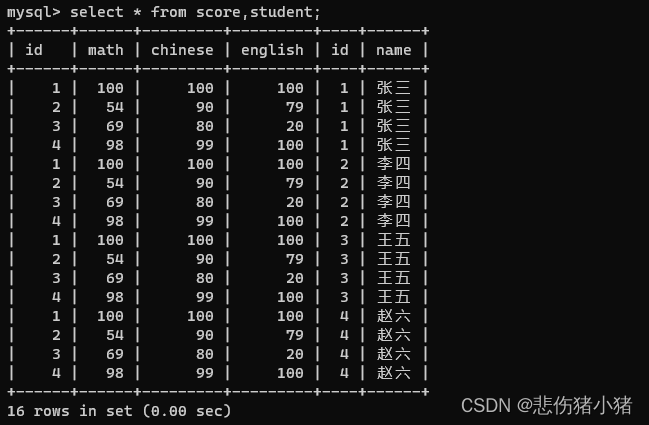
因为笛卡尔积是排列组合出来的结果,所以这里面有许多没有意义的数据,我们使用where对数据进行筛选,就完成了我们的需求。select * from student,score where student.id = score.id;
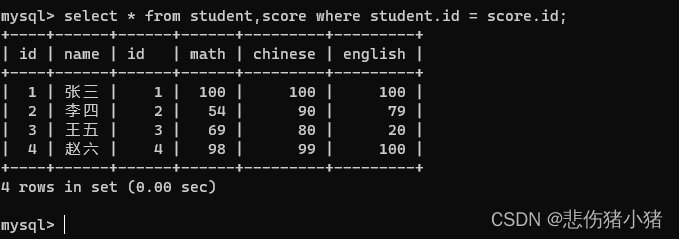
基于笛卡尔积 + 条件 进行查询的操作,我们称为联合查询。
索引
这个词我相信大家都不陌生,在图书管借书的时候都会见到这个东西,索引的作用就是方便大家快速找到自己所需要的图书的位置,在数据库中的索引也是一样,方便大家更快速的查询到数据。
show index from student
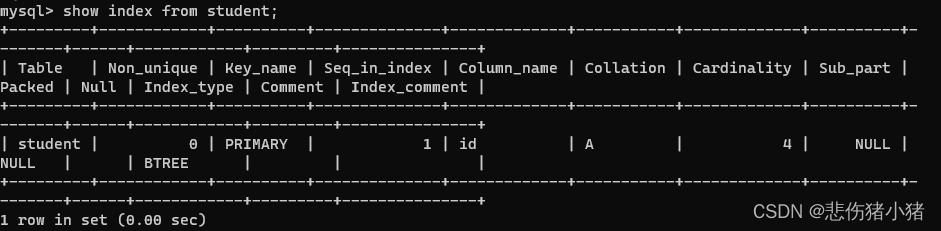
我们可以查看索引,还可以添加索引:create index name on student(name);
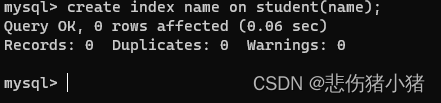
那么问题来了,数据库使用索引到底如何提高查询数据的效率的呢?牵扯到组织数据,我们就能想到数据结构,数据库使用合适的数据结构存储数据就可以提高查询的效率。
索引背后的数据结构
哪些数据结构可以加快查询的速度呢?常见的数据结构比如:二叉搜索树,哈希表等,但是他们MySQL并非使用了这样的数据结构存储数据。因为如果使用二叉搜索树,那么会增加IO的访问次数,而哈希表虽然查询的快,但是在数据库中有范围查询和模糊查询的概念,哈希表并不能完成,数据库其实是使用B+树来存储数据的。
B树与B+树
要了解什么是B+树,我们需要先知道什么是B树呢?下面我们来看一看:
我们可以将B树看作一个N叉搜索树,并且每个节点上的存储的key值有很多个。

类似与这样的数据结构我们称为B树,每个节点存储了N个Key,从而划分出了N+1个区间,子节点中的key的值需要在对应的区间内,这样操作相比较与二叉搜索树降低了树的高度,从而减少了IO的访问次数,但是,每个key存储的都是对应的数据,能不能在进行优化,并且查找每个数据访问IO的次数是不一样的,程序员非常不喜欢不确定的事,我们需要进行优化,这样我们就有了B+树:

上图这种数据结构我们称为B+树,我们发现每个节点的key值都会在子节点中出现,同时也是该子节点的最大值,这是相比于B树最大的区别。我们发现这样的操作使得所有数据都会在叶子节点中出现,而B+树的叶子节点首尾串起来了,看起来像一个链表,并且因为叶子节点包含了所有Key,所以数据只存储在叶子节点中,而非叶子节点这存储key的值,这样做的好处有哪些呢?我们来总结一下:
B+树的优势
1、与B树相同一个节点可以存储多个key值,降低了树的高度,减少了IO访问次数
2、因为数据都存储在叶子节点中,所以查询每个数据访问的IO次数是一样的,相比于B树的不确定,B+树更稳定。
3、B树不方便范围查询,而B+树的叶子节点类似于链表结构,进行范围查询很方便。
4、B树在存储数据时,每个节点都存储数据,而B+树只在叶子节点中存储数据,非叶子节点仅仅存储key值,占用空间较小,所以有可能非叶子节点存放在内存中,这样一来又减少了IO的访问次数。
事务
事务的作用就是把多条sql命令打包成一个整体,让多条sql命令变成一件事务,且具有原子性。
举个例子来说,身为大学生的你每个月都需要向家里要生活费,如果妈妈转生活费的同时,银行的数据库挂了,妈妈账户的钱减少了,你的账户的钱没有增加,是不是很尴尬。而如果我们通过事务将这些sql操作打包成一个事务,他们就具有了原子性,要莫这些命令全部执行成功,要不全部都不执行,这样就避免了上述尴尬的情况出现。(其实不是真的没有执行,而是在执行的过程中出现了错误,把数据回复成没操作之前的状态,我们称为回滚)。
事务的四个关键特性(八股文)
1、原子性 - 事务最核心的性质
2、一致性 - 在事务执行的前后,数据保持一致
3、持久性 - 事务修改的内容是写在硬盘上的,持久存在的。
4、隔离性 - 为了解决并发执行事务,所引起的问题。
那么问题来了,并发执行事务会带来哪些问题呢?
1、脏读问题
事务A正在对数据进行操作,事务B同时读取了数据,此时事务A有可能对数据进行更改,那么事务B读取到的就是一个错误数据,我们称为脏数据。
解决方法:
给写操作加锁,就是事务A在对数据进行更改的同时事务B不能读取数据,必须等事务A执行完毕后才可以读取数据。此时我们降低了事务的并发程度,但是提高了隔离性。
2、不可重复读
事务A提交了数据,此时事务B开始读取数据,但是事务C又提交了数据。此时事务B再次读取数据,发现数据跟第一次读取的不一样,这个问题我们称为不可重复读。
解决方法:
给读操作加锁,刚才的脏读是写的时候不可以读,现在变成了读的时候不可以写了。
3、幻读
在读和写这两把锁的前提下,一个事务两次读取用一个数据,发现读取的数据是一样的,但是结果集不一样,我们称为幻读。例如,事务A,在读xxx.java,事务B发现,现在不能对xxx.java进行更改,但是他闲不住,于是他新建了一个aaa.java。事务A读着读着冒出来了一个aaa.java就很莫名其妙。
解决方法:
使用串行化,彻底放弃事务的并发操作,一个一个的串行处理事务。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











