









基于boost库的搜索引擎
前言
Boost是为C++语言标准库提供扩展的一些C++程序库的总称。Boost库是一个可移植、提供源代码的C++库,作为标准库的后备,是C++标准化进程的开发引擎之一,是为C++语言标准库提供扩展的一些C++程序库的总称。
一、项目相关背景
1、想做一个搜索引擎,如:百度、搜狗、360搜索、头条新闻客户端 ,但是这些搜索引擎搜索的是全网内容,我们自己实现是不可能的!
2、站内搜索:搜索的数据更垂直,数据量更小。
3、boost的官网是没有站内搜索,查找时比较麻烦,这时我们可以自己做一个搜索引擎方便查找。
二、搜索引擎的相关宏观原理
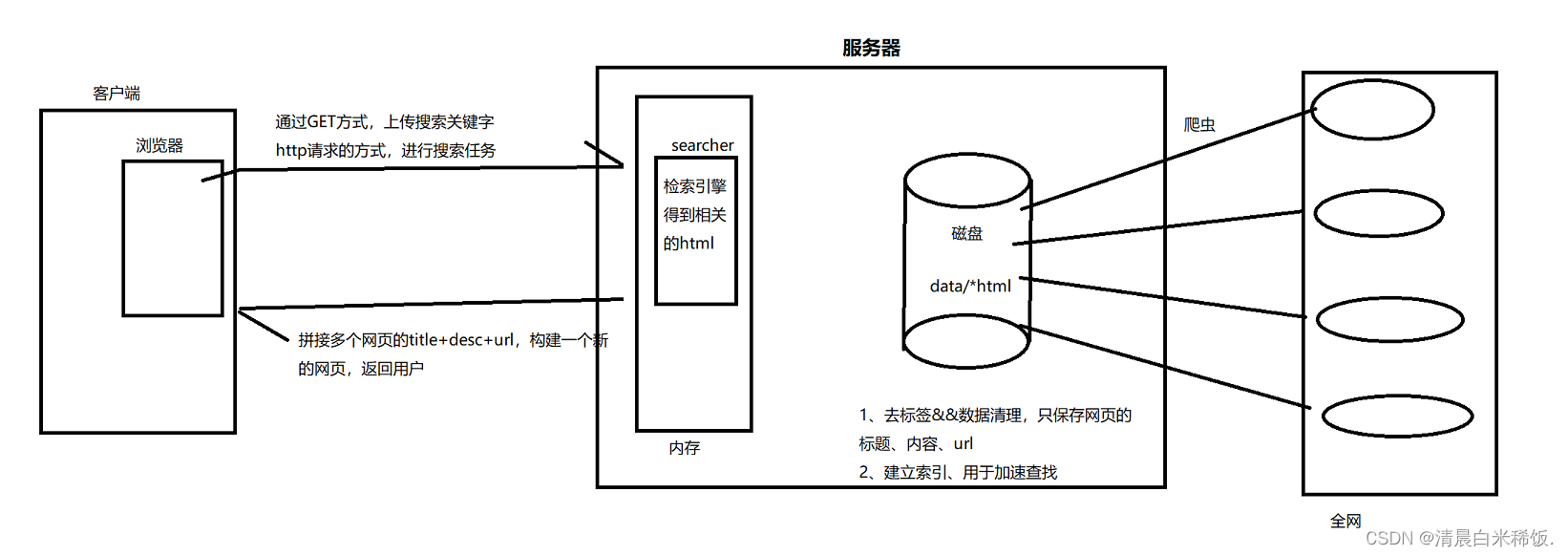
这里因为各种原因,爬虫的内容我们不实现,需要的boost库文件提前用合法途径下载好放在服务器上。
三、搜索引擎技术栈和项目环境
技术栈: C/C++ C++11, STL, 准标准库Boost,Jsoncpp,cppjieba,cpp-httplib , 前端选学: html5,css,js
项目环境:Centos 7云服务器,vim/gcc(g++)/Makefile , vs code
四、搜索引擎具体原理(正排索引 vs 倒排索引)
4.1 正排索引
正排索引:就是从文档ID找到文档内容(文档内的关键字)
如现在有两个文档ID:
| 文档ID | 内容 |
|---|---|
| 文档1 | 小明今年上了小班 |
| 文档2 | 小明是一位小班的小朋友 |
4.2 倒排索引
目标文档进行分词
目的:方便建立倒排索引和查找
停止词:“了”之类的语气词,一般我们在分词的时候可以不考虑
对上面的文档内容进行分词
小明今年上了小班:小明\今年\上了\小班\小明今年上了小班
小明是一位小朋友:小明\是\一位\小班\的\小朋友\小明是一位小班的小朋友
倒排索引:根据文档内容,分词,整理不重复的各个关键字,对应联系到文档ID的方案
| 关键字(具有唯一性) | 文档ID, weight(权重) |
|---|---|
| 小明 | 文档1、文档2 |
| 今年 | 文档1 |
| 上了 | 文档1 |
| 小班 | 文档1、文档2 |
| 一位 | 文档2 |
| 小朋友 | 文档2 |
模拟一次查找的过程:
用户输入:小明 -> 倒排索引中查找 -> 提取出文档ID(1,2) -> 根据正排索引 -> 找到文档的内容 ->title+conent(desc)+url 文档结果进行摘要->构建响应结果
五、编写数据去标签与数据清洗的模块
5.1获取boost库离线数据
boost 官网: https://www.boost.org/
1、在boost官网上随便下载一个版本的库文件
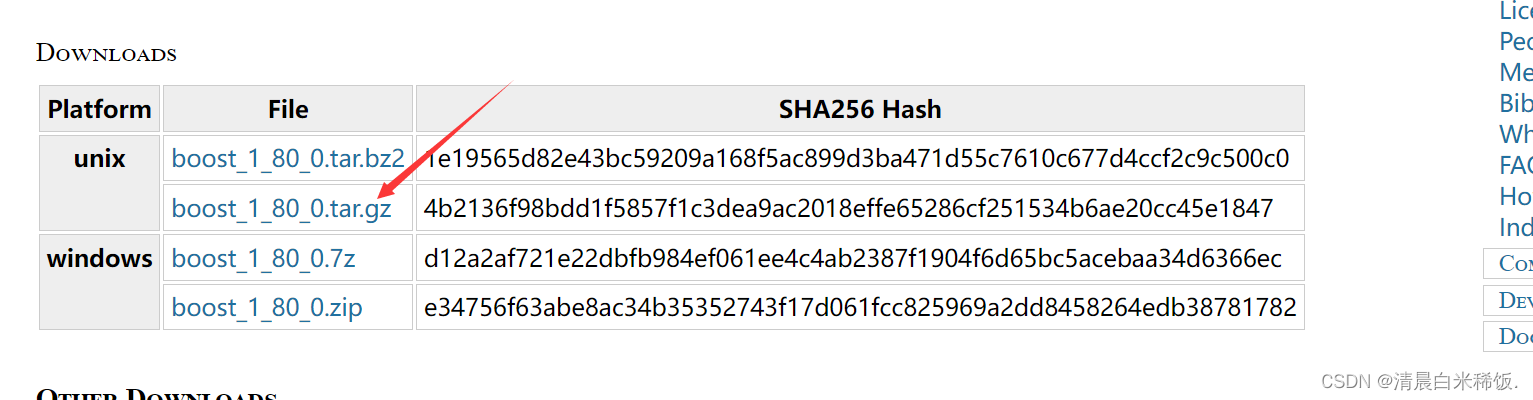
2、下载好后放到Linux上(这里的boost版本是1_79),就此获得了需要的数据

3、我们在网站中搜索内容时,发现都是这个目录下的html:

所以我们只需要展示doc/html下的文件内容,它就是boost组件的使用手册,这就可以做我们的数据源。
5.2 去标签
1、对谁去标签呢?去掉那些标签呢?
首先我们去标签去的是html文件上面的标签,从而拿到对我们有用的内容(摘要+内容+url)。
其次我们来看一个html文档内容
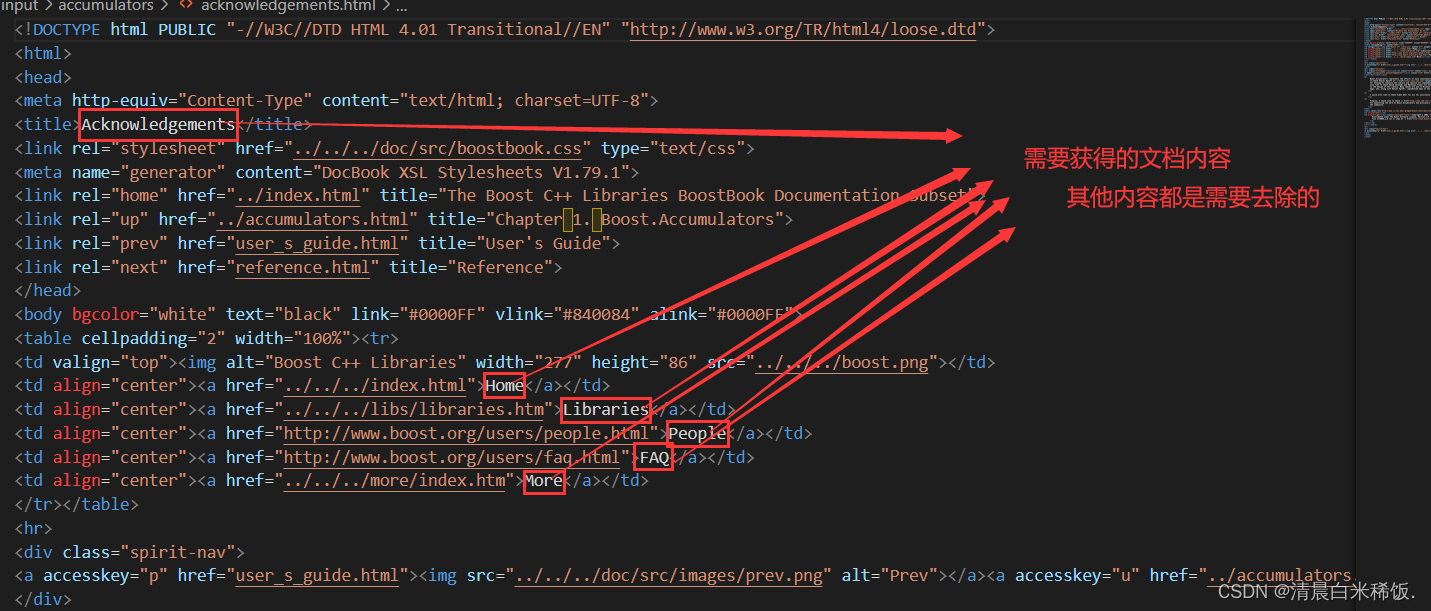
我们可以看到我们需要的内容都是在>和<(>需要的内容<)之间,不需要的内容都在<和>之间(<不需要的内容>)。
所以<> : html的标签,这个标签对我们进行搜索是没有价值的,需要去掉这些标签,一般标签都是成对出现的!
2、去标签后的内容放哪里呢?怎么放呢?
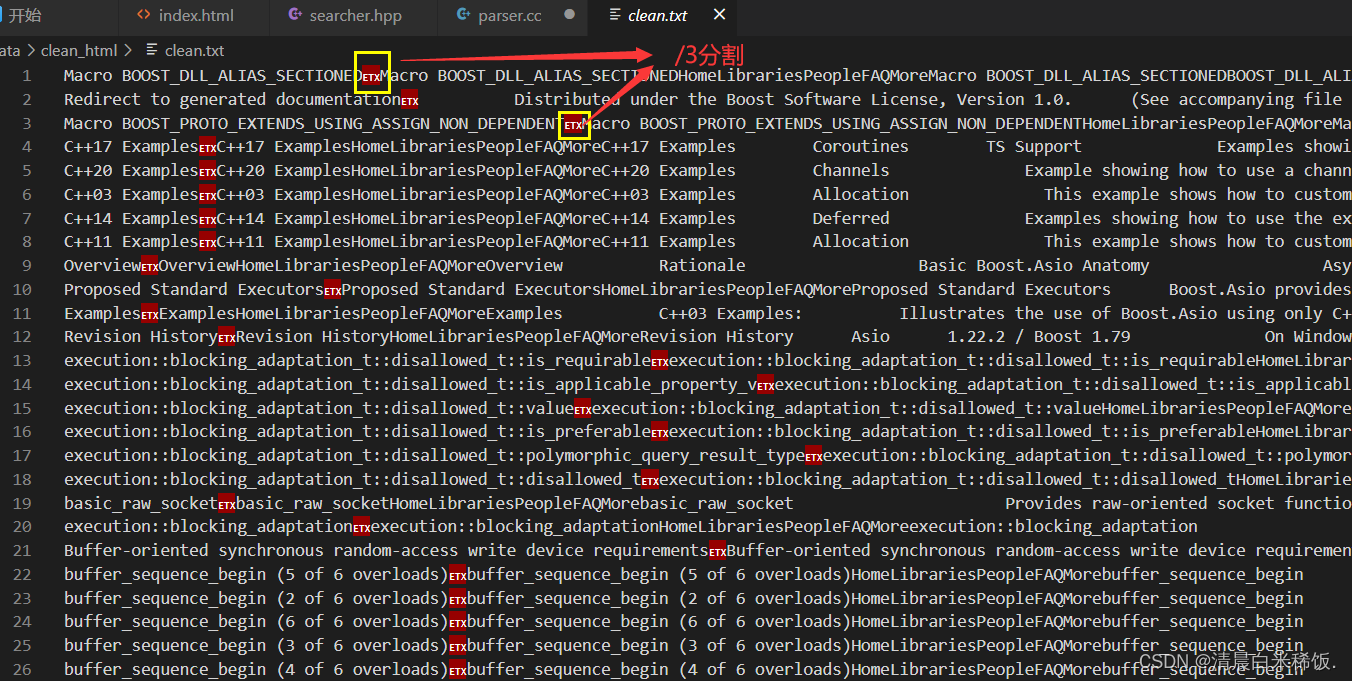
去标签后我们按行放在一个clean.txt文件中,也就是把每个文档都去标签,然后写入到同一个文件中!然后同一个文档内容不需要\n来隔开!同一个文档之间用 \3 区分,不同文档用\n隔开
类似:title\3content\3url \n title\3content\3url \n title\3content\3url \n …
方便我们getline(ifsream, line),直接获取文档的全部内容:title\3content\3url

5.3 编写parser.cc
注意:编写parser.cc时需要用到boost,所以需要安装boost,安装如下
sudo yum install -y boost-devel //是boost 开发库
parser.cc的目的是:得到html文件去标签后的摘要+内容+url。
parser.cc分三步得到:
第一步:递归式的把每个html文件名带路经,保存到files_list中,方便后期进行一个一个的文件读取
获得html文件在文档下的路径
第二步:按照files_list读取每个文件的内容,并进行解析
解析文件分四步:
1、读取文件,Read()
2、解析指定文件,提取title
3、解析指定文件,提取content
4、解析指定的文件路径,构建url
1、读取文件,Read()
此读取文件的ReadFile放在Url.hpp(工具包文件)文件中
ReadFile主要是通过文件操作按读的方式打开,按行的方式(利用 中的 ifstream类与 getline即可)写进一个string对象里面(此时是把全部的内容写进去包括标签)
2、解析指定文件,提取title
如何提取title呢?
我们在html文件中发现title内容总是在
所以我们只需要找到
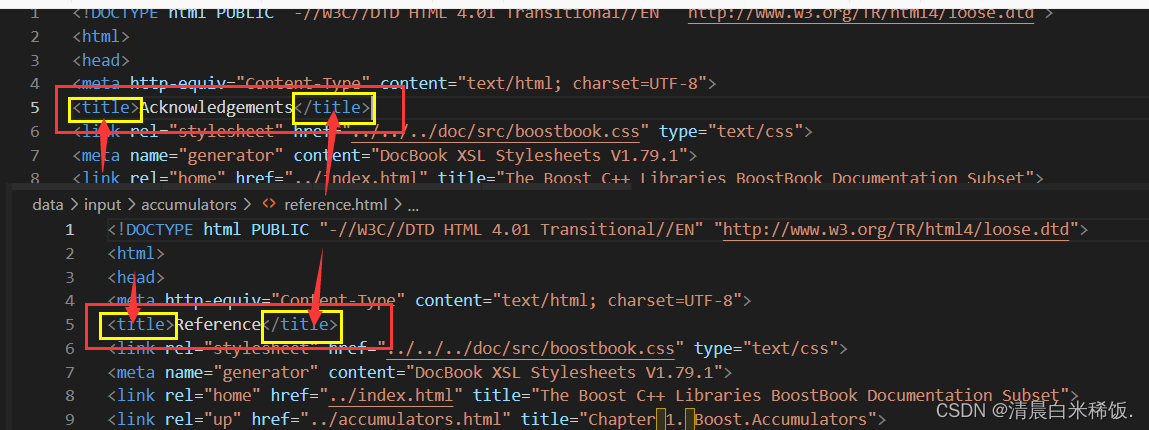
3、解析指定文件,提取content
如何提取content呢?
我们发现在html文件中content的内容总是在>和<之间
所以读取>和<之间的内容,然后写入doc.content就行
在读取写入content中我们可以基于一个简易的状态机
遇到<时状态机会改变,同时当遇到>时表示当前标签已经处理完毕
注意:如果在>和<中间遇到"\n"就替换成" "(空格),因为要用\n作为html解析之后的的文本分割符
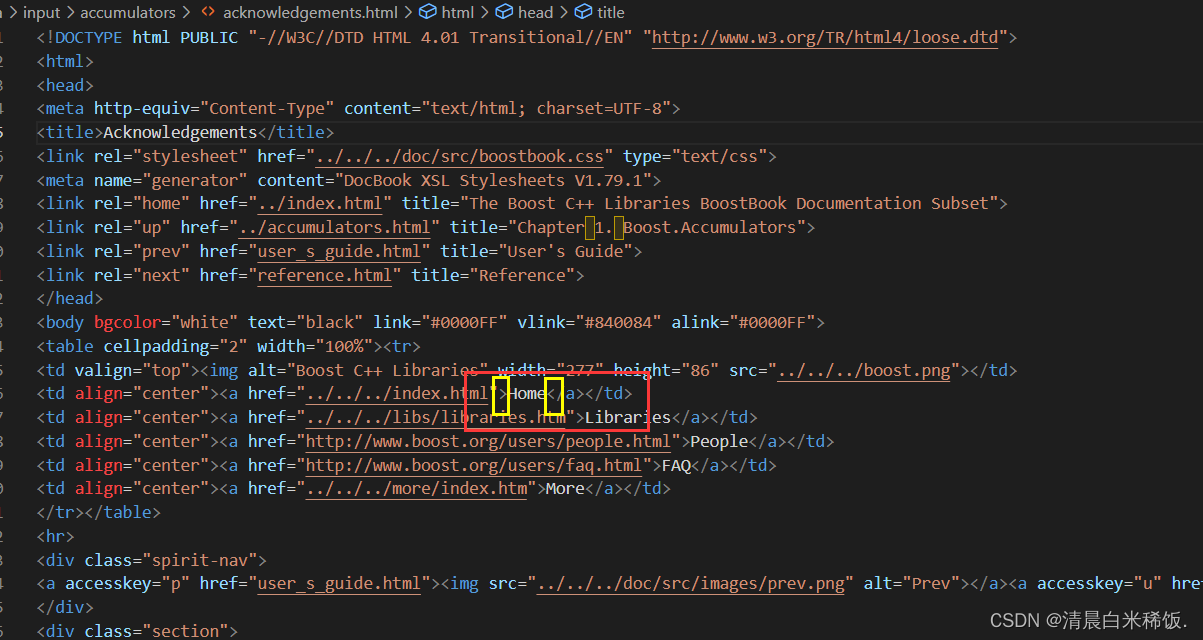
4、解析指定的文件路径,构建url
如何构建url呢?通过观察我们发现
官网URL样例: https://www.boost.org/doc/libs/1_78_0/doc/html/accumulators.html
我们下载下来的url样例:boost_1_78_0/doc/html/accumulators.html
所以我们可以根据路径构建一个官网链接,然后将该链接存放到doc.url中
url_head = “https://www.boost.org/doc/libs/1_78_0/doc/html”;
url_tail = [data/input(删除)] /accumulators.html
-> url_tail = /accumulators.html url = url_head + url_tail ; 相当于形成了一个官网链接
第三步:把解析完毕的各个文件内容,写入到output,按照\3作为文档的分隔符
打开data/clean_html/clean.txt文件,按照二进制方式进行写入
就此得到了html文件去标签后的摘要+内容+url。
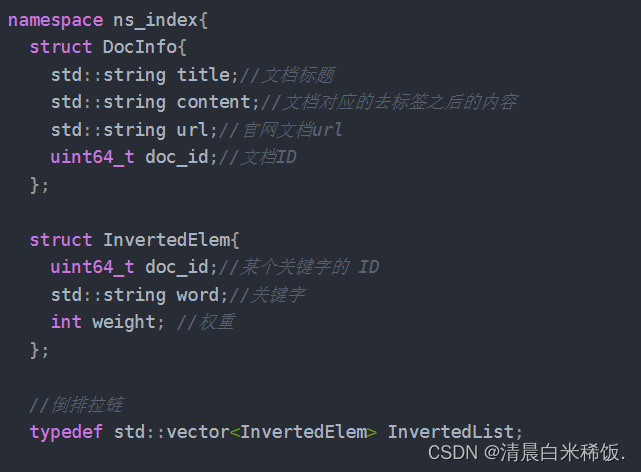
六、编写建立索引的模块 Index
该模块主要是提供了:正排索引函数、倒排索引函数、建立索引函数、jieba分词函数
还提供根据doc_id找到找到文档内容、根据关键字string,获得倒排拉链
6.1 jieba分词函数
分词我们使用jieba分词库,jieba分词库的下载安装
jieba的使用–cppjieba 获取链接: git clone https://gitcode.net/mirrors/yanyiwu/cppjieba.git
如何使用:注意细节,我们需要自己执行: cd cppjieba; cp -rf deps/limonp include/cppjieba/, 不然会编 译报错
注意:该分词代码是采用单例模式
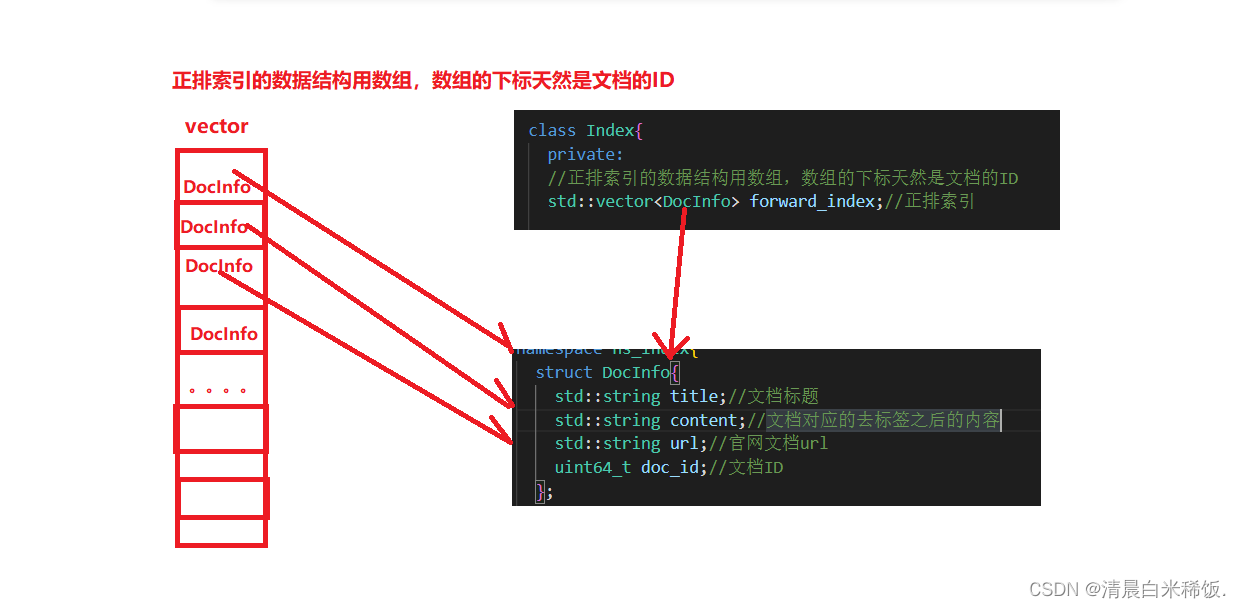
6.2 正排索引函数: DocInfo *BuildForwardIndex(const std::string &line)
首先拿到第五模块解析好的文件,经过按行读取,按"\3"切分,获得摘要+内容+url,最后再插入vector。
正排索引的数据结构用数组,数组的下标天然是文档的ID
`
6.3 倒排索引:bool BuildInverttedIndex(const DocInfo &doc)
首先拿到正排索引形成的内容,在进行对InvertedList的插入形成倒排拉链,最后根据关键字和一组(个)InvertedElem对应形成倒排索引
倒排索引一定是一个关键字和一组(个)InvertedElem对应[关键字和倒排拉链的映射关系]
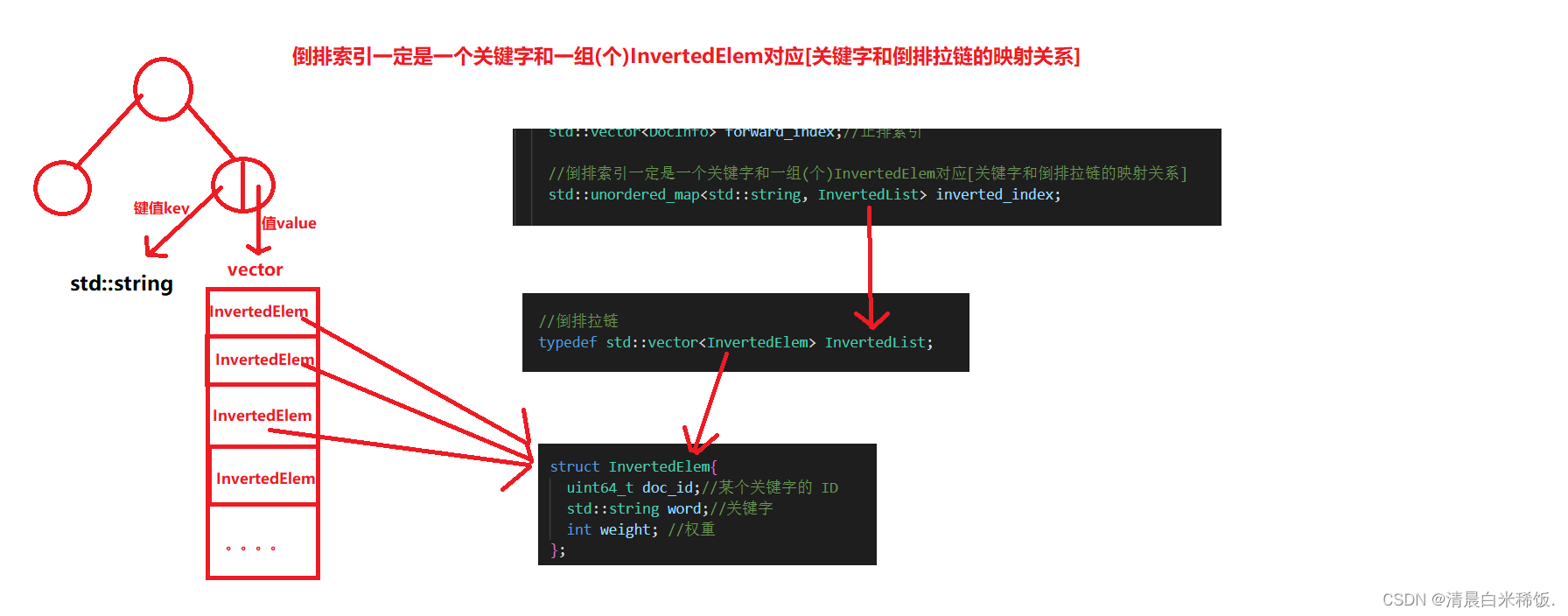
倒排索引代码分析:
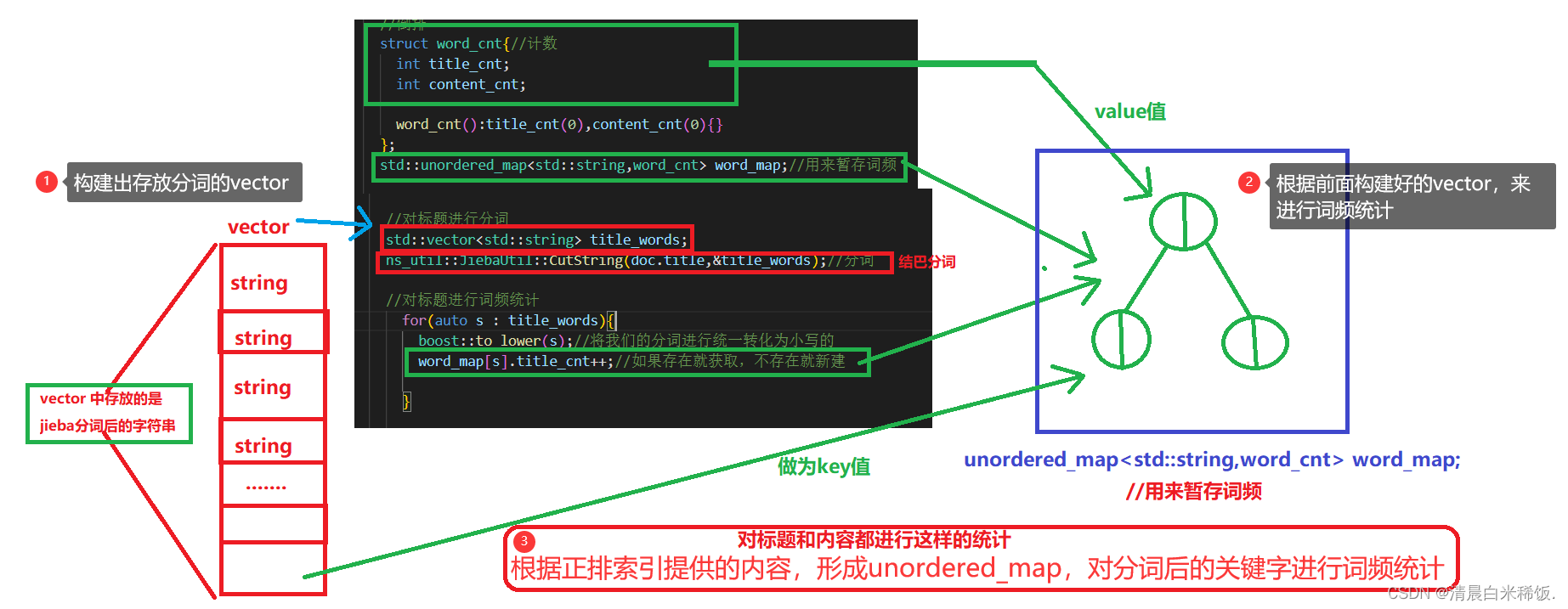
首先根据正排索引的内容形成存放有关键词的vector,再根据vector的内容进行词频统计(仅仅对摘要和内容进行统计),形成unordered_map< std::string,word_cnt > word_map;(具体看下图)
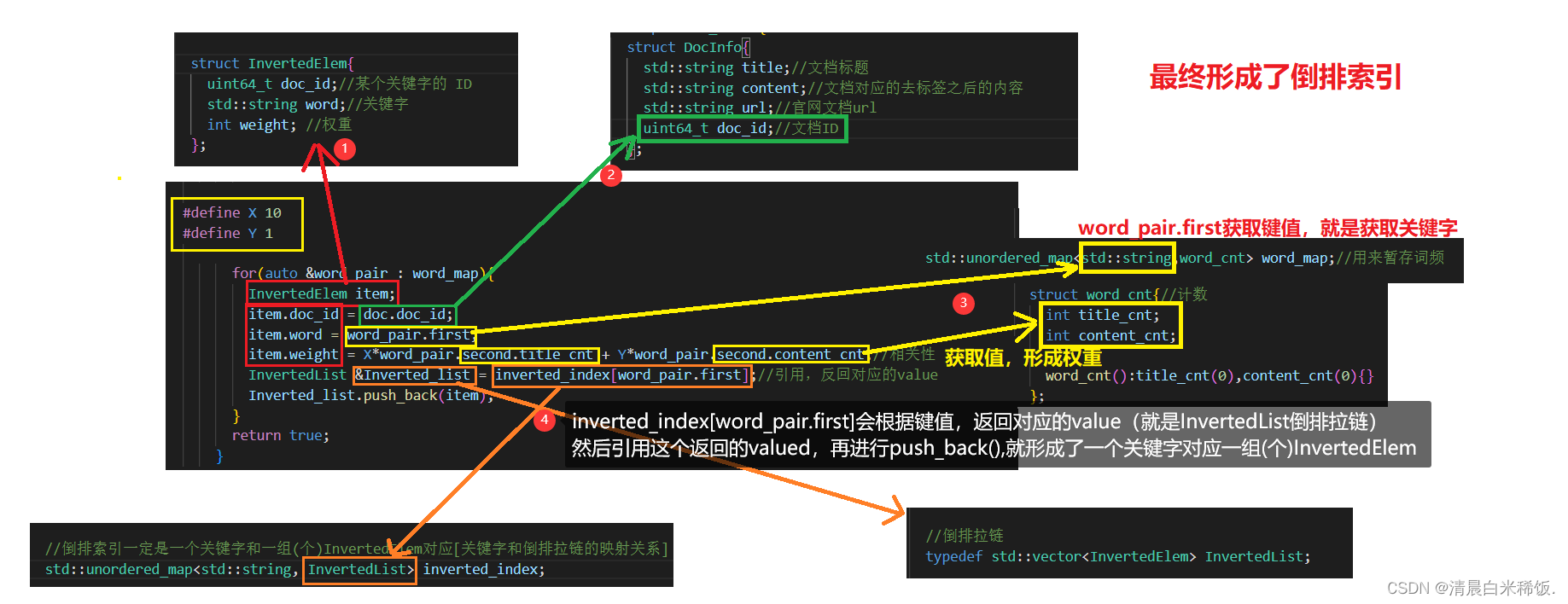
首先创建一个InvertedElem对象,然后根据前面的获取到的信息对该对象进行填充,最后根据{InvertedList &Inverted_list = inverted_index[word_pair.first];}这个语句得到引用value的对象,再进行push_back(),最终获得倒排索引。(具体看下图)
注意1:因为当前我们是一个一个文档进行处理的,一个文档会包含多个”词“, 都应当对应到当前的doc_id
注意2:词和文档的相关性(词频:在标题中出现的词,可以认为相关性更高一些,在内容中出现相关性低一些),后面的网页排序根据权重来排序
注意3:建立倒排索引的时候,要忽略大小写!!
6.4、建立索引
首先根据去标签,格式化之后的文档,构建正排,再根据正排构建倒排索引。
6.5 根据doc_id找到找到文档内容
DocInfo *GetForwardIndex(uint64_t doc_id){
if(doc_id >= forward_index.size()){
std::cerr<<"doc_id out range. error!" <<std::endl;
return nullptr;
}
return &forward_index[doc_id];
}
6.6 根据关键字string,获得倒排拉链
InvertedList *GetInvertedList(const std::string &word){
auto iter = inverted_index.find(word);//查找关键字
if(iter == inverted_index.end()){
std::cerr<<word<<"have no InvertedList" << std::endl;
return nullptr;
}
return &(iter->second);//返回对应的迭代器
}
七、编写搜索引擎模块 Searcher
搜索引擎模块 Searcher主要是供系统进行查找的索引
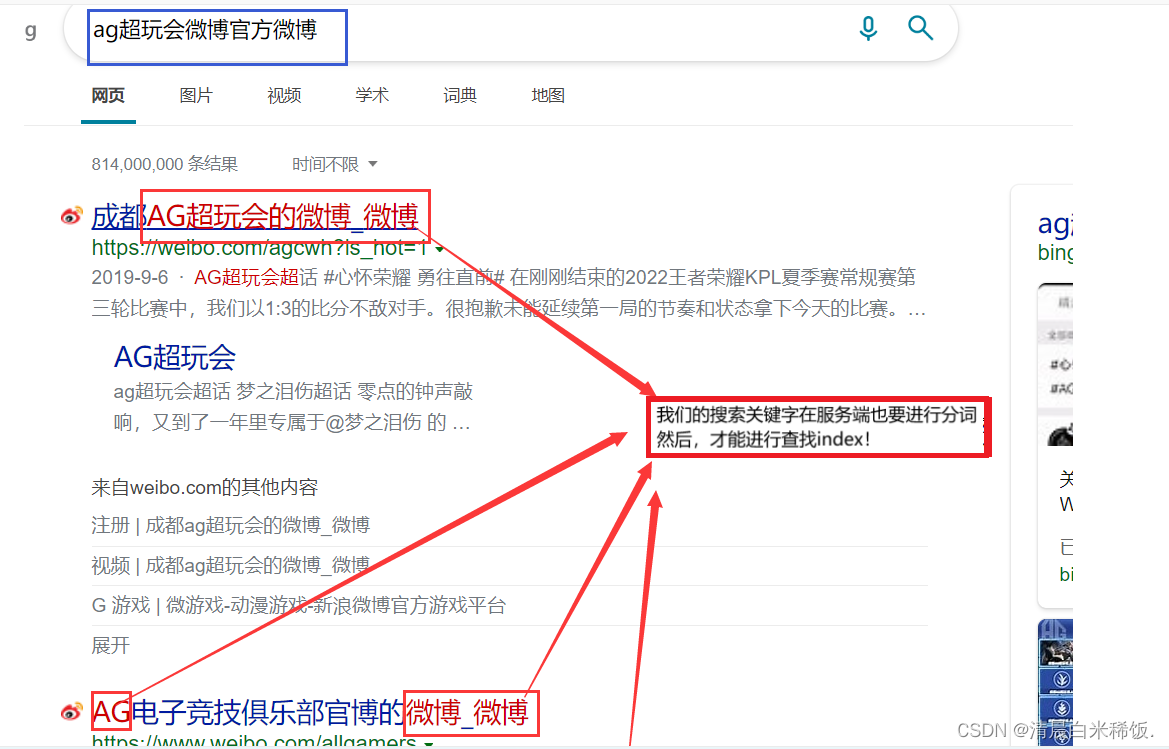
注意:我们的搜索关键字在服务器端也要进行分词,然后才能进行查找index
搜索引擎模块 Searcher向外提供了两个接口
void InitSearcher(const std::string &input)函数
1、获取或者创建index对象
2、根据index对象建立索引首先**InitSearcher(const string &input)**完成初始化,GetInstance()创建索引index对象,index->BuildIndex(input)根据index对象建立索引。
void Search ( const std::string &query,std::string * json_string )函数
1.[分词]:对我们的query进行按照searcher的要求进行分词
2.[触发]:就是根据分词的各个"词",进行index查找
3.[合并排序]:汇总查找结果,按照相关性(weight)降序排序
4.[构建]:根据查找出来的结果,构建json串 – jsoncpp根据用户输入的查询词进行搜索Search ( const string &query, string * json_string )
- 首先对查询词进行分词CutString(query, &words)
- 再根据分词结果的关键词触发倒排索引GetInvertedList(word)
- 然后合并排序汇总查找结果,按照相关性权值(weight)降序排序sort,
- 之后根据倒排索引的结果,拿到文档ID
- 通过ID索引到对应文档内容GetForwardIndex(item.doc_id)
- 最终根据查找出来的结果,构建json串输出*json_string = writer.write(root)
基本代码结构:
#include "index.hpp"
namespace ns_searcher{
class Searcher{
private:
ns_index::Index *index; //供系统进行查找的索引
public:
Searcher(){}
~Searcher(){}
public:
void InitSearcher(const std::string &input)
{
//1. 获取或者创建index对象
//2. 根据index对象建立索引
}
//query: 搜索关键字
//json_string: 返回给用户浏览器的搜索结果
void Search(const std::string &query, std::string *json_string) {
//1.[分词]:对我们的query进行按照searcher的要求进行分词
//2.[触发]:就是根据分词的各个"词",进行index查找
//3.[合并排序]:汇总查找结果,按照相关性(weight)降序排序
//4.[构建]:根据查找出来的结果,构建json串 -- jsoncpp
}
};
}
7.1 void InitSearcher(const std::string &input) 接口
1、获取或者创建index对象
2、根据index对象建立索引
7.2 void Search(const std::string &query, std::string *json_string)接口
1.[分词]:对我们的query(搜索关键字)进行按照searcher的要求进行分词
对于query(搜索关键字)的分词也是运用jieba分词就可以啦!
//1、分词:对我们的query进行按照searcher的要求进行分词
std::vector<std::string> words;
ns_util::JiebaUtil::CutString(query,&words);//分词
2.[触发]:就是根据分词的各个"词",进行index查找
根据上一步分词后的关键字string,获得倒排拉链(一个关键字获得一组InvertedElem)
问题:当合并时就会出现多个关键词对应同一个文档ID,到时候显示给用户的页面就会有所重复
解决方案见代码:
//2、触发:就是根据分词的各个“词”,进行index查找
//ns_index::InvertedList inverted_list_all;// 内部InvertedElem
std::vector<InvertedElemPrint> inverted_list_all;//存放去重之后的InvertedElemPrint
std::unordered_map<uint64_t,InvertedElemPrint> tokens_map;//根据doc_id去重,去重结果放在InvertedElemPrint中
for(std::string word : words){
boost::to_lower(word);//转化小写
ns_index::InvertedList *inverted_list = index->GetInvertedList(word);//获取倒排拉链
if(nullptr == inverted_list){
continue;
}
//不完美的地方 含有输出重复内容bug的地方
// inverted_list_all.insert(inverted_list_all.end(),inverted_list->begin(),inverted_list->end());
for(const auto &elem : *inverted_list){
auto &item = tokens_map[elem.doc_id];//[],如果id存在直接获取,如果id不存在就创建
//这里的item一定是doc_id相同的print节点
item.doc_id = elem.doc_id;
item.weight += elem.weight;
item.words.push_back(elem.word);//此时id相同,插入不同的关键字
}
}
for(const auto &item : tokens_map){
inverted_list_all.push_back(std::move(item.second));
}
3.[合并排序]:汇总查找结果,按照相关性(weight)降序排序
通过sort函数结合lambda表达式,按照相关性进行排序
//3、合并排序:汇总查找结果,按照相关性(weight)降序排序
std::sort(inverted_list_all.begin(),inverted_list_all.end(),
[](const InvertedElemPrint &e1,const InvertedElemPrint &e2){return e1.weight > e2.weight;
});
4.[构建]:根据查找出来的结果,构建json串 – jsoncpp
根据ID获得内容,根据内容构建json串,这里需要安装jsoncpp
安装如下:
sudo yum install -y jsoncpp-devel
构建:根据查找出来的结果,构建json串–jsoncpp 通过jsoncpp完成序列化反序列化;
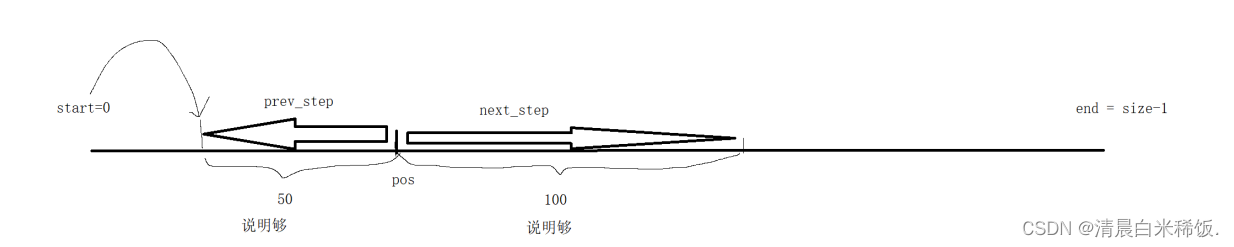
注意:在获取摘要时,我们只获取关键字的前五十个字节和关键字的后一百个字节
八、编写http_server 模块
http_server 模块主要是获取用户的请求,并将结果返回给用户
- 初始化搜索引擎模块
- 构建http网络服务对象
- 设置默认网页根目录
- Get获取参数
- req获取请求的查询词
- 对查询词进行搜索
- rsp将结果输出
- 服务器打开8081访问端口
http_server 模块需要用到cpp-httplib库
下载cpp-httplib库:https://gitcode.net/mirrors/yhirose/cpp-httplib
建议 cpp-httplib 0.7.15
下载zip安装包,上传到服务器即可
安装cpp-httplib库:ln -s ~/boost_searcher/test/cpp-httplib-0.7.15/ cpp-httplib
cpp-httplib在使用的时候需要使用较新版本的gcc,centos 7下默认gcc 4.8.5
首先安装scl:sudo yum install centos-release-scl scl-utils-build
安装新版本gcc:sudo yum install -y devtoolset-7-gcc devtoolset-7-gcc- c++
启动最新版:enable devtoolset-7 bash
然后打开目录:
ls /opt/rh
可以看到目录下存在文件
devtoolset-7注意:启动: 细节,命令行启动只能在本会话有效(每次启动会话都需要命令行启动,网上有自动启动的办法)
九、编写前端模块
9.1 了解 html,css,js
html: 是网页的骨骼 – 负责网页结构
css:网页的皮肉 – 负责网页美观的
js(javascript):网页的灵魂—负责动态效果,和前后端交互
教程: https://www.w3school.com.cn/
效果展示:
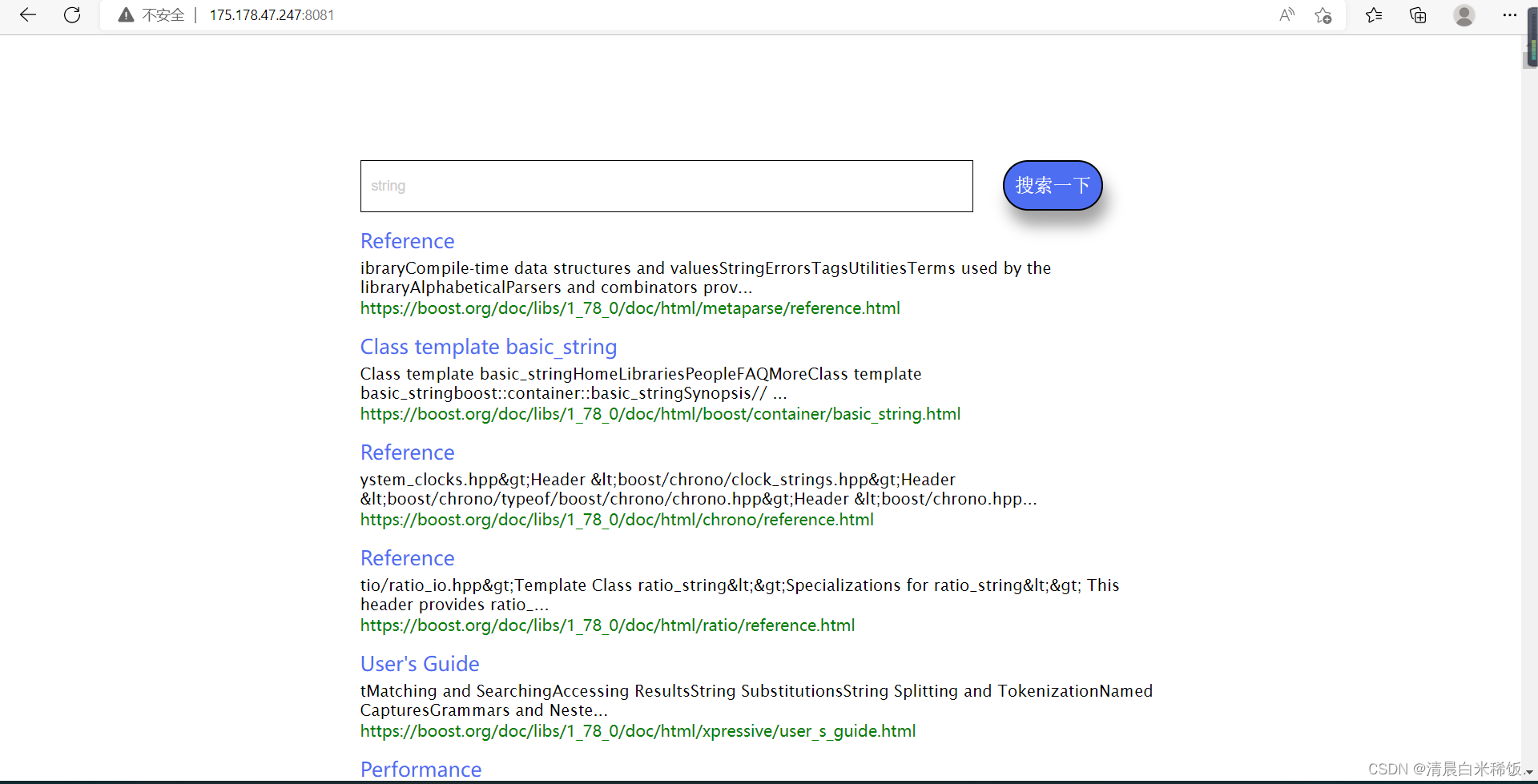
具体前端代码链接:链接: https://gitee.com/xaio-a-zheng/boost-search-engine-library.git
十、添加日志
为方便调试,我们需要加上日志
具体代码:
#pragma once
#include <iostream>
#include <string>
#include <ctime>
//日志等级
#define NORMAL 1
#define WARNING 2
#define DEBUG 3
#define FATAL 4
#define LOG(LEVEL, MESSAGE) log(#LEVEL, MESSAGE, __FILE__, __LINE__)
void log(std::string level, std::string message, std::string file, int line)
{
std::cout << "[" << level << "]" << "[" << time(nullptr) << "]" << "[" << message << "]" << "[" << file << " : " << line << "]" << std::endl;
}
十一、部署服务到 linux 上
nohup ./http_server > log/log.txt 2>&1 &
十二、总结
项目实现了一个Boost站内搜索引擎
当启动服务器时
先启动parser.cc预处理模块,先对boost离线库文件中的html文件进行解析,获得标题、内容和url,然后调用index.hpp模块,根据预处理模块结果完成正排索引和倒排索引,至此服务器启动完毕。
当用户输入查询内容时
通过GET方式,上传搜索关键字,当后端接收到关键字 后调用searcher.hpp模块,通过对用户的关键词进行分词,分词结果形成的关键字触发索引找到结果,对结果根据权值的降序排序,最后拼装整合新的页面结果展现给用户,用户可以点击要查看的标题跳转到相关页面。


















 1604
1604

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











