






我们之前说到,想要通过爬虫获取数据,就要伪装自己的爬虫,让服务器误以为请求是浏览器发出的,而不是通过爬虫程序发出的,那么我们要怎么去伪装呢? 就要说一下请求头了,
请求头是我们使用浏览器的时候浏览器将我们的个人信息打包在一起的一个字典,然后和我们的需求一起发送给服务器,我们看一下他是什么样子吧。
1、我们打开谷歌浏览器,按F12
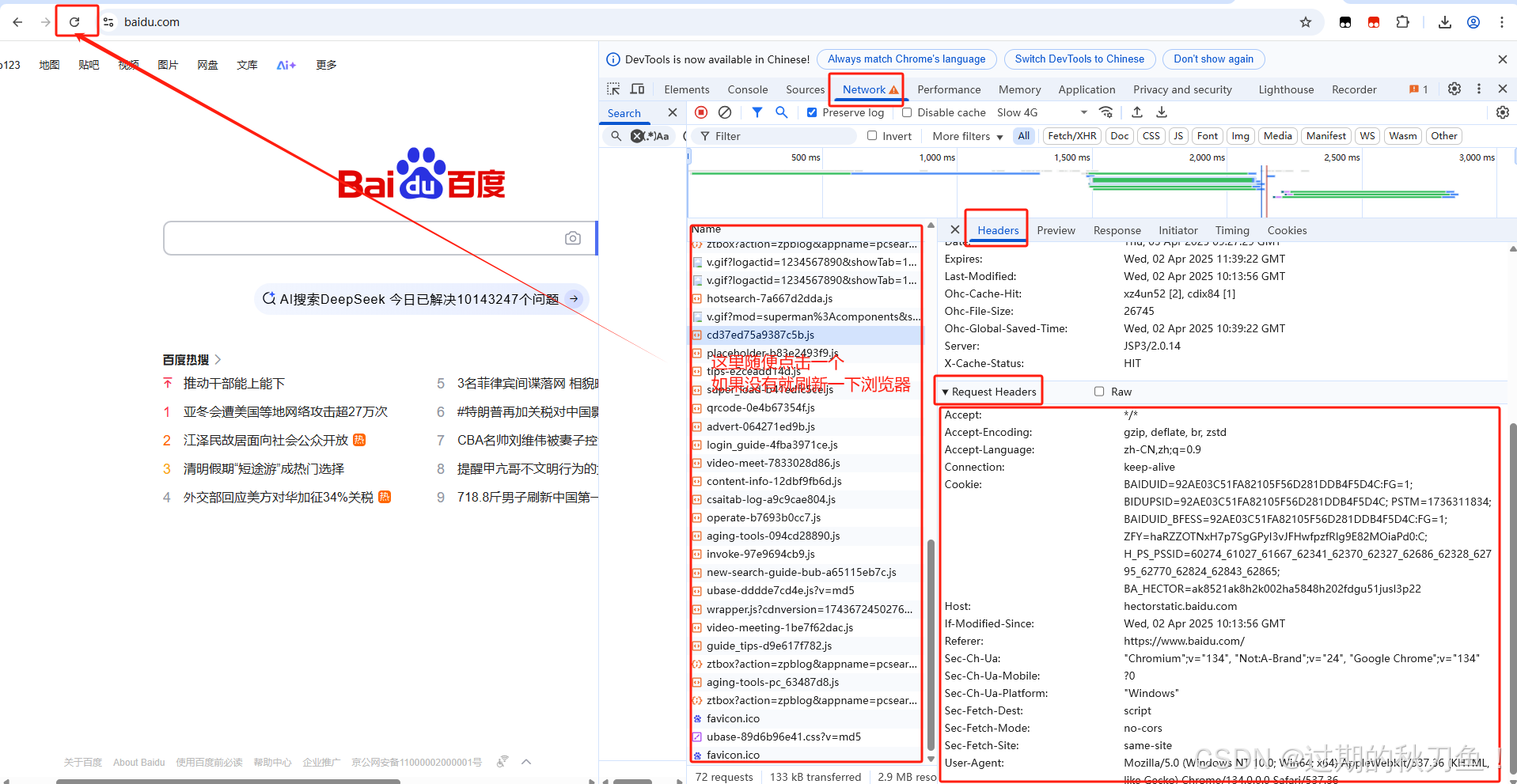
requests就是请求头,我们可以看到有很多的参数,接下来我们说一下每个参数都是什么意思
参数大致分为两种,常见的和不常见的,我们了解常见的参数就可以解决百分之九十以上的参数了。
| 参数名 | 关键程度 | 作用 | 对爬虫的意义 | 示例 |
|---|---|---|---|---|
| User-Agent | 高 | 标识客户端浏览器、操作系统等信息 | 防止被识别为爬虫,必须伪装成浏览器 | Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36... |
| Cookie | 高 | 携带会话凭证(如登录状态) | 访问需登录的页面时必须携带 | Cookie: session_id=abc123; user_token=xyz789 |
| Referer | 中 | 表示当前请求的来源页面 | 绕过防盗链验证(如图片、API接口) | Referer: https://www.example.com/page1 |
| Host | 高 | 指定请求的域名(HTTP/1.1强制要求) | 通常由请求库自动处理,但需确保与目标一致 | Host: www.example.com |
| Accept | 低 | 声明客户端可接受的响应数据类型 | 一般使用默认值即可 | Accept: text/html,application/xhtml+xml,application/xml;q=0.9 |
| Accept-Encoding | 低 | 声明支持的压缩算法(如gzip) | 服务器返回压缩内容时需解压,但requests库会自动处理 | Accept-Encoding: gzip, deflate, br |
| Accept-Language | 低 | 声明客户端接受的语言 | 模拟浏览器语言偏好 | Accept-Language: zh-CN,zh;q=0.9,en;q=0.8 |
| Content-Type | 高(POST时) | 声明请求体的数据类型(如表单、JSON) | POST请求必须指定,否则服务器无法解析 | Content-Type: application/json |
| Authorization | 中 | 携带认证信息(如Token、Basic Auth) | 访问需认证的API时必须携带 | Authorization: Bearer eyJhbGciOiJIUzI1Ni... |
| Connection | 低 | 控制TCP连接是否保持(默认keep-alive) | 一般无需修改 | Connection: keep-alive |
| Upgrade-Insecure-Requests | 中 | 声明支持HTTPS升级 | 现代浏览器默认添加,部分网站会检测 | Upgrade-Insecure-Requests: 1 |
| **Sec-Fetch-***(系列) | 中 | 安全相关头(如Sec-Fetch-Dest、Sec-Fetch-Mode) | 部分反爬严格的网站会检测 | Sec-Fetch-Dest: documentSec-Fetch-Mode: navigate |
| X-Requested-With | 中 | 标识是否为AJAX请求(如XMLHttpRequest) | 绕过某些仅允许AJAX请求的接口 | X-Requested-With: XMLHttpRequest |
| Content-Length | 低 | 声明请求体的字节长度 | POST/PUT请求时自动计算,通常无需手动设置 | Content-Length: 348 |
关键程度说明:
高:爬虫必须设置,否则可能直接失败或被封禁(如User-Agent, Cookie)
中:根据场景需要设置,可绕过特定反爬机制(如Referer, Sec-Fetch-*)。
低:一般无需主动处理,库或浏览器会自动填充。
了解请求头对之后的反扒意义重大,可以这样说,能不能反扒就是大部分取决于你对请求头的了解程度。
那么我么你怎么去用这些请求头来反扒呢?
我们用经典的豆瓣TOP250举例 附上网页链接
https://movie.douban.com/j/chart/top_list
我们用request直接请求这个链接,
import requests url="https://movie.douban.com/j/chart/top_list" respons=requests.get(url=url) print(respons.text) respons.close() 我们发现,代码没出错,但是什么都没有我们就要考虑是否是因为反扒才导致的访问失败,,要一点一点的排查,看一下是什么原因导致这样 我们第一个想到的因该是请求头
我们看一下我们请求的请求头是什么
查看请求头的方法
print(respons.request.headers)#查看求情的headers
完整代码
import requests url="https://movie.douban.com/j/chart/top_list" respons=requests.get(url=url) print(respons.request.headers) #查看求情的headers # print(respons.text) respons.close()
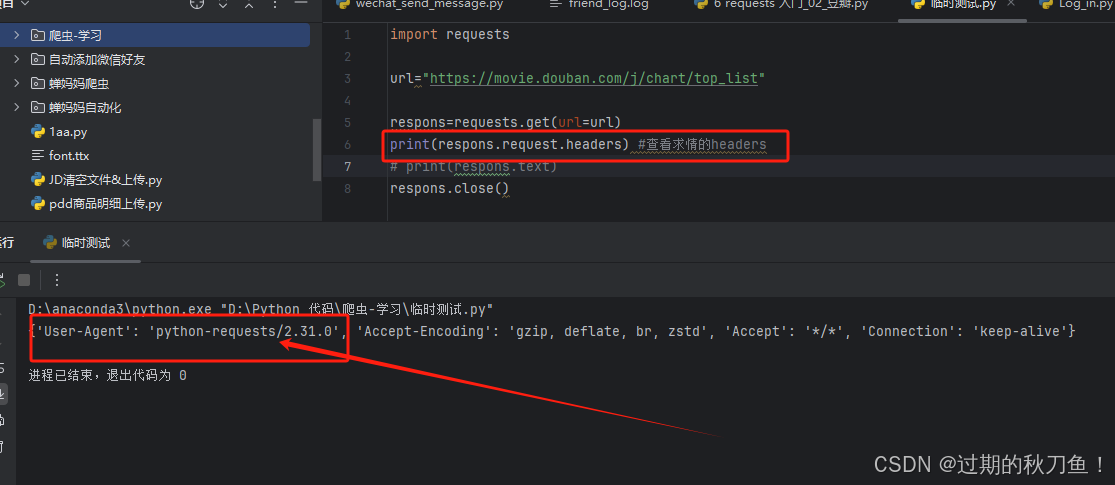
发现了,请求是Python发出的,我们都没有伪装,一看就是爬虫发出来的,我们去浏览器找一下请求头, 点一下F12刷新一下浏览器,步骤和第一个图片一样哦
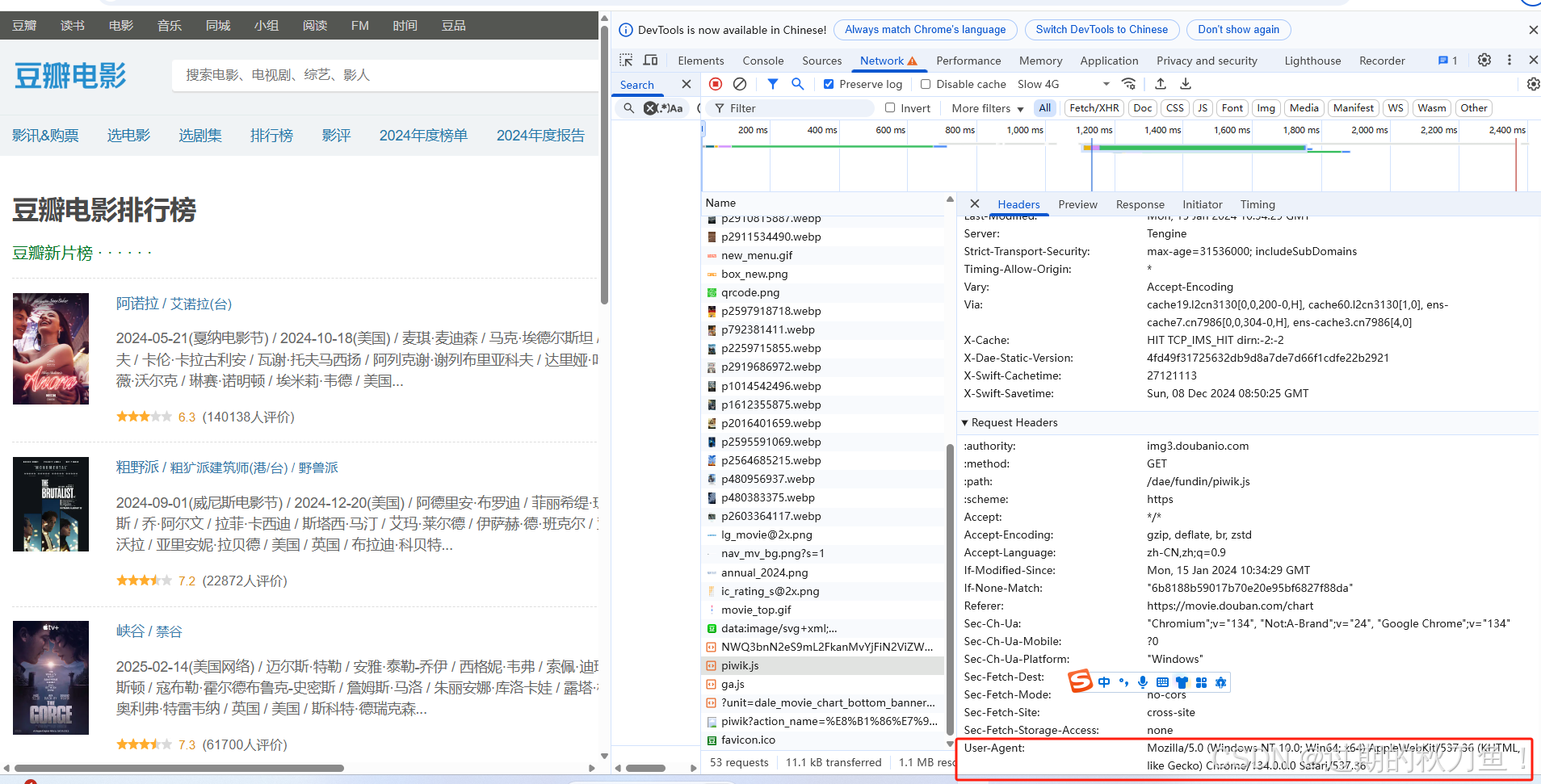
我们找到这个东西给复制下来,放进代码中变成一个字典
import requests
url="https://movie.douban.com/j/chart/top_list"
headers={
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.0.0.0 Safari/537.36"
}
respons=requests.get(url=url,headers=headers) print(respons.request.headers) #查看求情的headers # print(respons.json) respons.close()
运行一下

我们可以看到请求头已经变了
我们用print(respons.json)请求一下数据

状态码200请求成功
延展一下,不同的状态码,代表这什么含义,
| 类别 | 状态码 | 含义 | 常见场景 |
|---|---|---|---|
| 1xx - 信息响应 | 100 | Continue(继续) | 请求已接收,客户端应继续发送。 |
| 2xx - 成功 | 200 | OK(成功) | 请求成功,返回预期数据(如接口调用、页面加载)。 |
| 201 | Created(已创建) | 资源已成功创建(如新增数据)。 | |
| 204 | No Content(无内容) | 请求成功,但响应无返回内容。 | |
| 3xx - 重定向 | 301 | Moved Permanently(永久重定向) | 资源已永久迁移到新URL。 |
| 304 | Not Modified(未修改) | 资源未修改,客户端可复用缓存。 | |
| 4xx - 客户端错误 | 400 | Bad Request(错误请求) | 请求语法或参数有误(如缺少必填字段)。 |
| 401 | Unauthorized(未授权) | 身份验证失败(如未登录或Token过期)。 | |
| 403 | Forbidden(禁止访问) | 无权访问资源(如权限不足)。 | |
| 404 | Not Found(未找到) | 请求的资源不存在(如URL错误)。 | |
| 429 | Too Many Requests(请求过多) | 客户端发送请求过于频繁。 | |
| 5xx - 服务端错误 | 500 | Internal Server Error(服务器内部错误) | 服务器处理请求时发生未知错误。 |
| 502 | Bad Gateway(网关错误) | 网关或代理服务器从上游服务器接收到无效响应。 | |
| 503 | Service Unavailable(服务不可用) | 服务器暂时过载或维护中。 | |
| 504 | Gateway Timeout(网关超时) | 网关或代理服务器未及时从上游服务器获取响应。 |
然后我们开始传入一一些参数,获取数据,还记得上一杰我们说的通过参数拼接链接,获取不同的结果吗,
附上源码
import requests
url="https://movie.douban.com/j/chart/top_list"
headers={
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.0.0.0 Safari/537.36"
}
param ={
"type": "24",
"interval_id": "100:90",
"action": "",
"start": 100,
"limit": 20
}
respons=requests.get(url=url,headers=headers,params=param)
# print(respons.request.headers) #查看求情的headers
print(respons.text)
respons.close()
结果展示

我们可以看到已经获取到数据了。
这还没结束哦,但是我下班了,明天摸鱼我在给大家讲一下怎么去清洗获取到的数据,变成想要的格式,存取Excel中

















 63万+
63万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









