







目录
前言:
我们已经知道了进程状态,进程调度,OS管理,环境变量,还是否记得我们当时说过folk有两个返回值,我们当时只是说了个大概,这里我们就要来详细介绍到底是为什么。
一、初步认识程序地址空间
我们使用fork创建一个子进程,定义一个全局变量gval,子进程修改该全局变量,父进程只读取,每个进程都打印出gval的地址。观察结果:
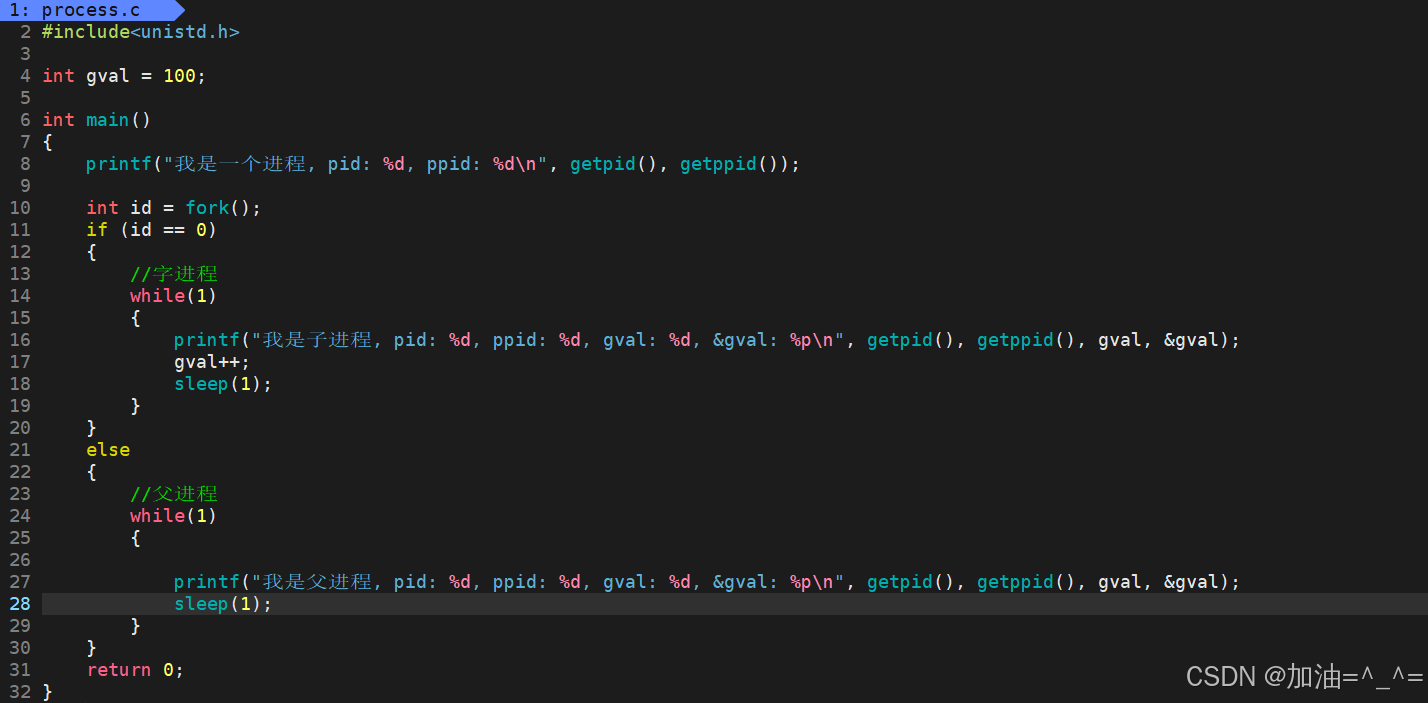
#include<stdio.h>
#include<unistd.h>
int gval = 100;
int main()
{
printf("我是一个进程, pid: %d, ppid: %d\n", getpid(), getppid());
int id = fork();
if (id == 0)
{
//字进程
while(1)
{
printf("我是子进程, pid: %d, ppid: %d, gval: %d, &gval: %p\n", getpid(), getppid(), gval, &gval);
gval++;
sleep(1);
}
}
else
{
//父进程
while(1)
{
printf("我是父进程, pid: %d, ppid: %d, gval: %d, &gval: %p\n", getpid(), getppid(), gval, &gval);
sleep(1);
}
}
return 0;
}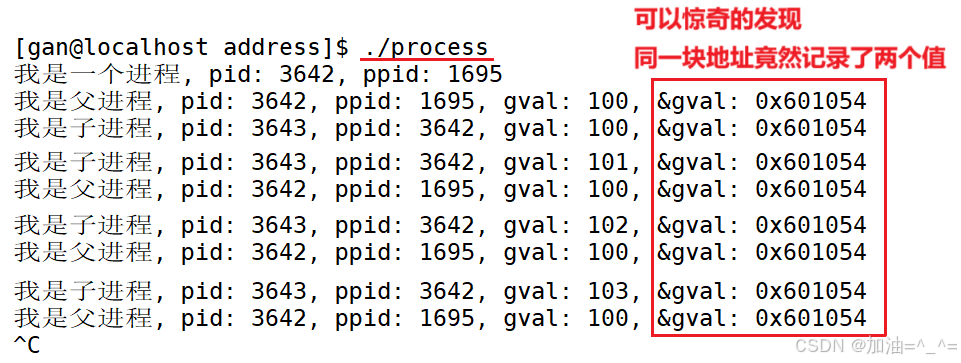
所以可以证明,该地址绝对不是物理地址!
所以此处是虚拟地址/线性地址。
1.虚拟地址
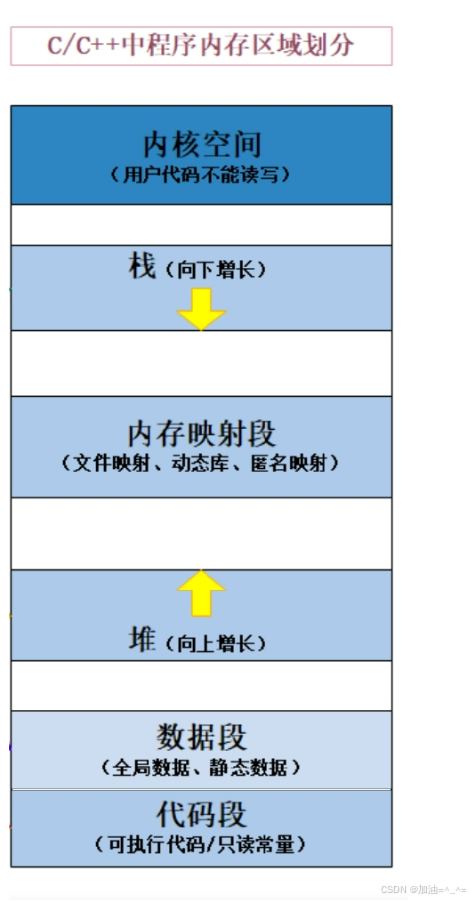
对于C/C++程序的地址空间,大家应该都不陌生:
首先我们要了解两个概念:进程和程序。这两个不是同一个概念。
程序:是一组计算机能识别和执行的指令,通常存储在磁盘等介质上,以文件形式存在。例如.exe可执行文件,是一个静态的指令集合。
进程:是程序在计算机中的一次执行过程。当你启动了一个可执行程序的时候,OS会为这个程序创建一个进程,进程是一个动态的概念。
区别:程序是静态的指令集合,而进程是动态的执行过程。一个程序可以对应多个进程。
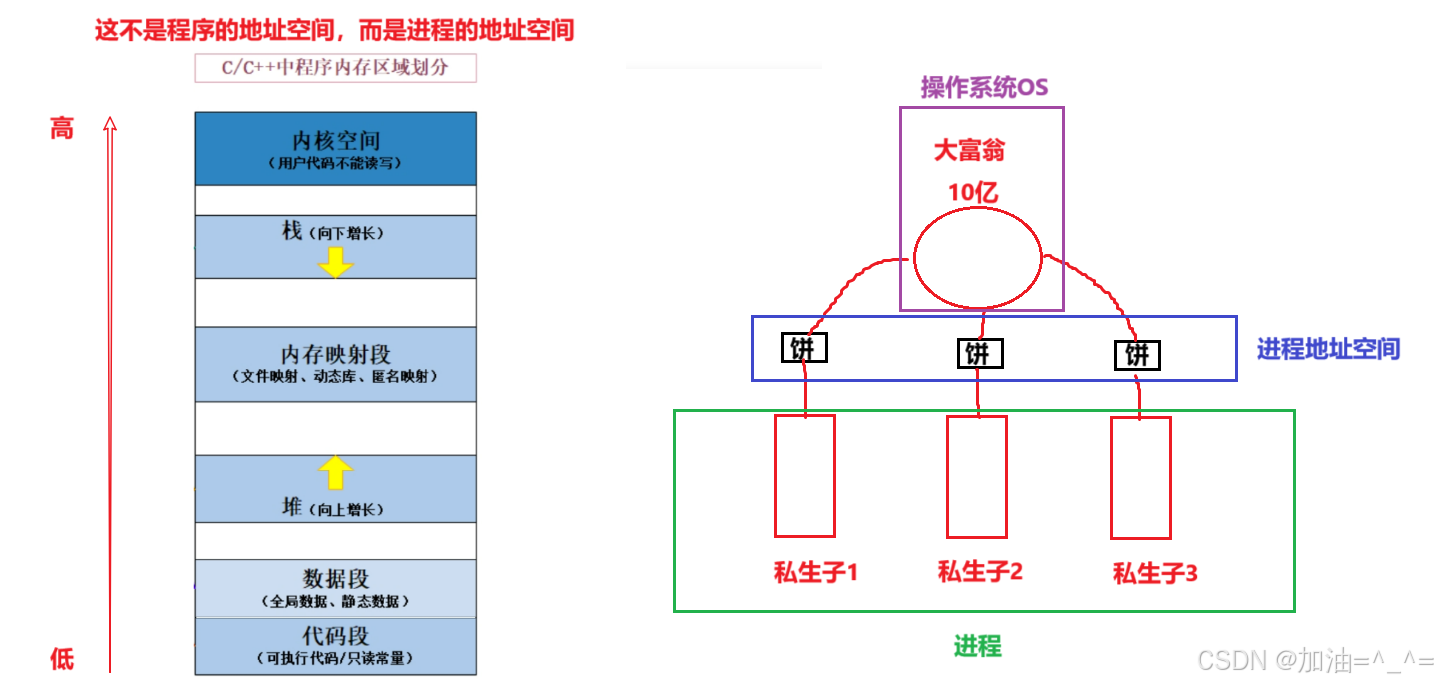
我们平时总会讲起C的地址空间,但是其实这并不是C程序的地址空间,而是启动C程序后的进程地址空间。
这里我们还是用一个小故事来举例:
在美国有一个大富翁,有10亿美金。他有一群子女,这一群子女看到这10亿美金就会想着如何占有,每人都想据为己有,这样大富翁压力就会很大。
在一个平行宇宙中,这个大富翁吸取了这个大富翁的教训,不同的是这个大富翁私生活比较混乱,有一群私生子。私生子1在读博士,大富翁说你加油,学得好10亿归你。私生子2从商,大富翁说你加油,做得好10亿归你等等。此时大富翁就在对这些私生子进行画饼,而每个私生子都认为自己有10亿美金,私生子1说项出国留学,向大富翁要1w美金,大富翁肯定会给;私生子2说要100亿,大富翁说你要干嘛?肯定不给!
此时大富翁就在给这些私生子们画饼,但是大富翁也要管理好这些饼。所以大家可以把大富翁理解为OS,私生子理解为进程;这些饼理解为进程地址空间。
对这些饼的管理也是先描述再组织。
让每一个进程都认为自己是独占系统物理内存大小,进程彼此之间不知道,不关心对方的存在,从而实现一定程度的隔离。所以所谓的进程虚拟地址空间,本质是一个内核数据结构对象(类似PCB)。
这里我们来看看源代码:


2.mm_struct区域划分
而这个mm_struct有时如何进行区域划分的呢?
假设此时你设计了一个能进行区域划分的结构体,你应该会这样写:
struct destoproom
{
int start_part1, end_part1;
int start_part2, end_part2;
};所以mm_struct也是这样进行区域划分的。

理解地址空间上的地址(记录的是虚拟地址)。
地址的本质就是一个数字,可以使用unsigned long(4字节)保存,空间范围内的地址,我们可以随意使用,暂时不需要记录它的地址。
二、写时拷贝
在虚拟地址和物理地址会使用页表进行映射(这里不会把页表解释的很清楚,但是大家要大致知道原理是什么)。
在我们没有创建子进程之前,时间上是这样的:

虚拟地址空间和页表就是Linux对虚拟内存的管理方案。
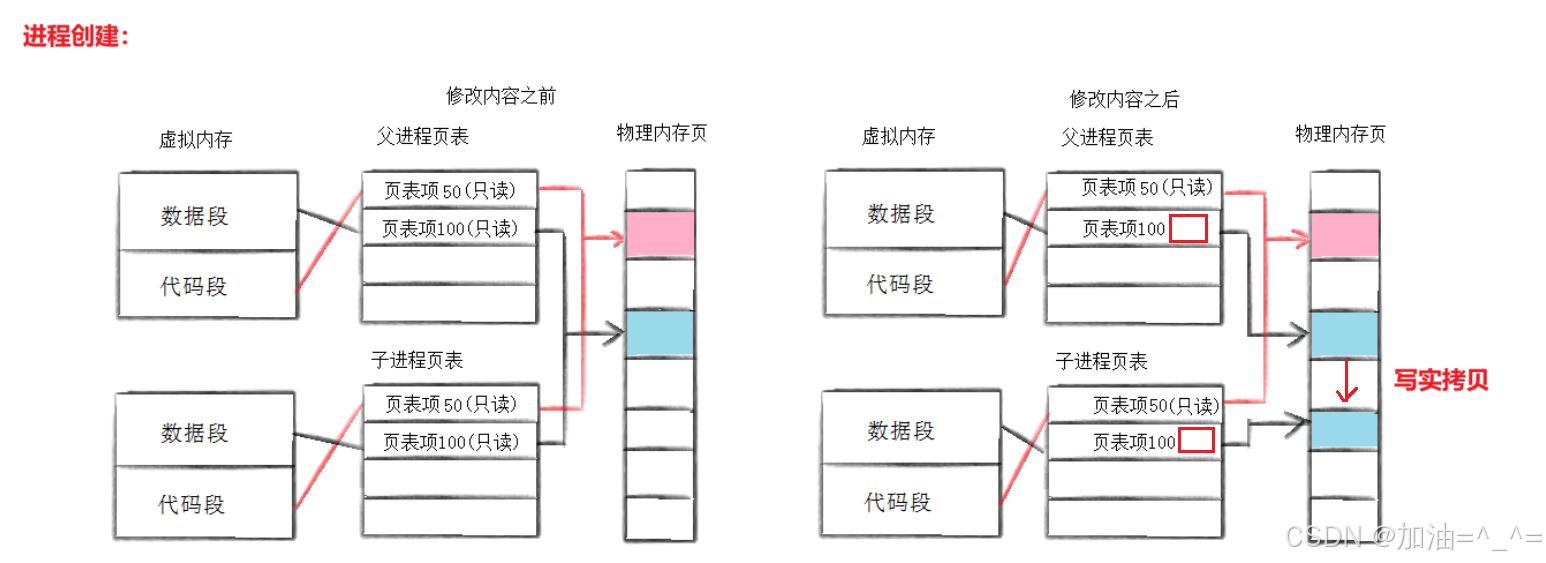
当创建子进程时,会以父进程为模版,把PCB(会修改一些必要属性)拷贝,页表拷贝,也就是浅拷贝。刚开始子进程没有自己的代码和数据,只能由父进程继承。
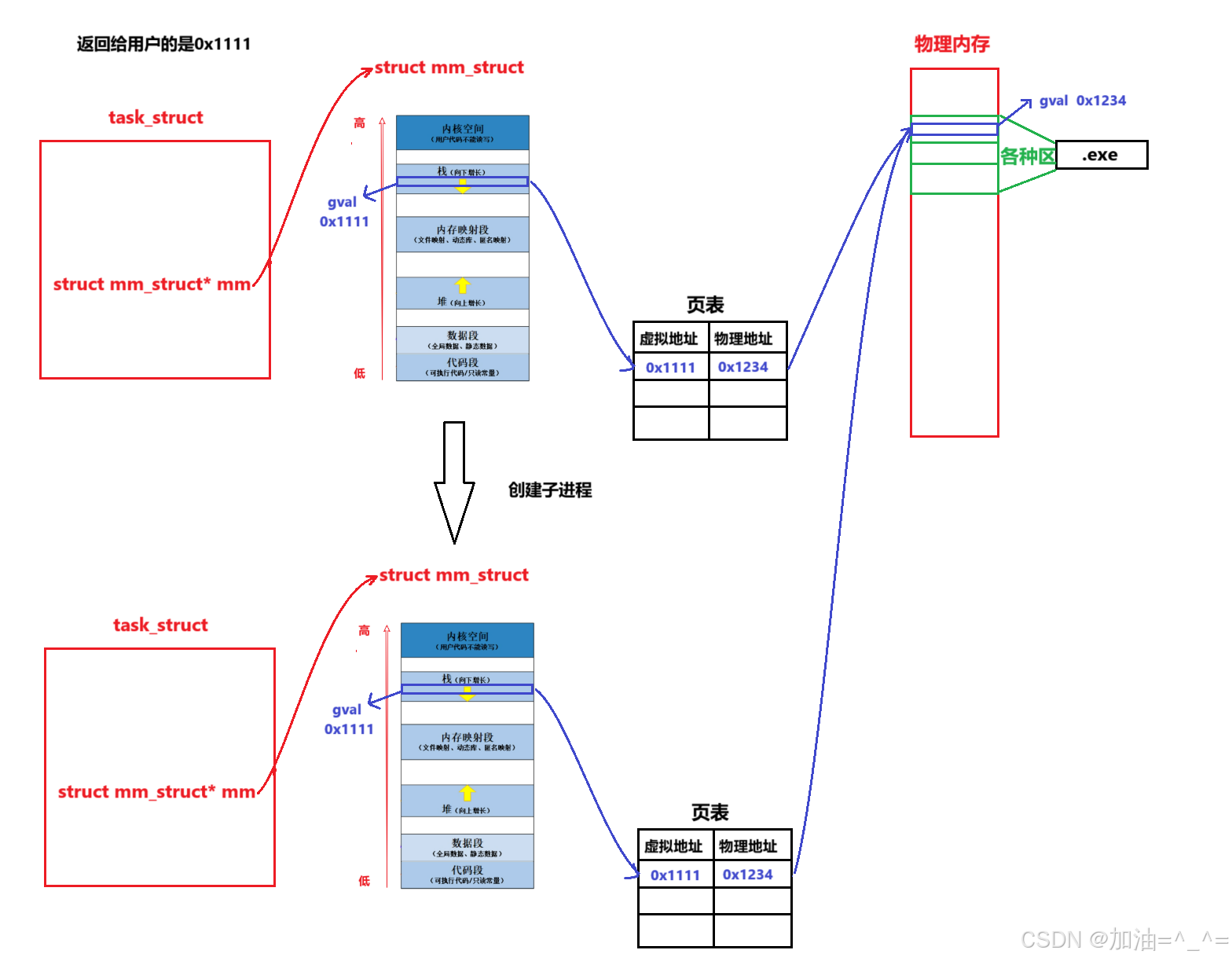
此时父子进程映射到同样的内存区域,所以父子代码共享。但是如果子进程此时修改了数据,而进程具有独立性,所以会发生写实拷贝(OS自主完成,是写时拷贝机制)。
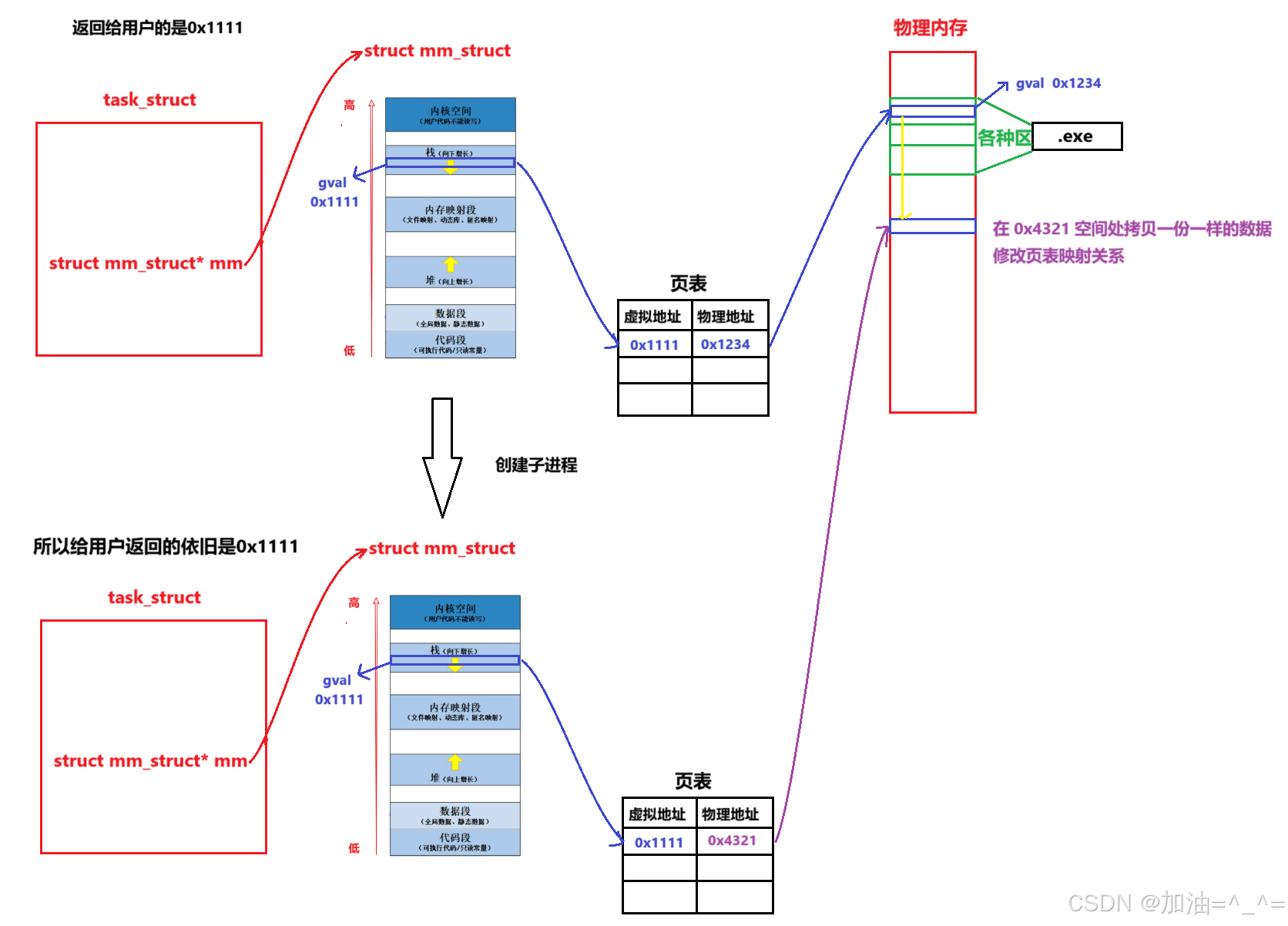
所以我们就可以在相同的地址空间看到存储的值不同了。这也就是fork有两个返回值的原因,因为不同进程使用不同的页表查看,映射的物理内存不一样。
其实变量名就是地址。
所以再次理解进程:
进程 = 内核数据结构(task_struct/mm_struct/页表) + 自己的代码和数据
内核数据结构各自一份,代码和数据也是独立的。
三、页表(宏观认识)
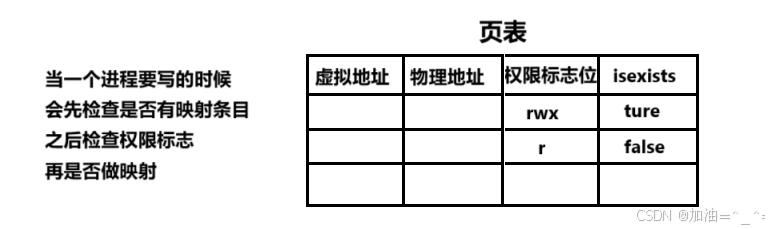
页表可以理解为map这个数据结构。
页表中其实还有很多标记位,比如权限标志位和isexists标志位。
我们之前会写这样的代码:
char *str = "hello bit";
*str = 'H'这是拿着栈区的指针指向放在常量区的数据,此时有要修改常量区数据,如果我们运行程序就会崩溃。这是OS做的事情,因为这段区域的权限是'r',而我们要进行'w',所以OS就杀死了该进程。
这个代码能编译过,所以编译器是发不现的,只有在运行的时候OS会发现,所以一般建议加上const,这样编译器就会发现。
1.isexists标志位
还是否记得,我们在加载一个程序的时候,是先加载PCB之后加载代码和数据。
此时有一个1GB的程序运行,我们先加载其PCB,关于物理地址我们先不管。此时这个程序会直接整个塞到内存中吗?如果真的是这样,后面的程序就很难跑了。
而前期我们只用前半部分,后面几乎不用;而之后前半部分跑完了,执行后半部分,前面的代码就几乎不会被执行了。所以在页表中有一个isexists标记位,表示目标数据是否在内存中,如果在内存中,就直接映射访问。否则发现目标地址无法访问,就会从外设加载到内存,所以会进行分批加载和挂起等操作。
也就是说当一个进程创建时,PCB先创建,页表虚拟地址创建,可能物理地址都没有,当访问时,发现物理地址没有,isexists标志位为false,就从磁盘中加载到内存,这样就建立好了映射关系。
这就是为什么我们内存8GB能玩128GB的游戏。
四、关于mm_struct地址空间初始化
是结构体就需要初始化,每个程序的大小都不一样,所以每个代码的正文代码大小都不一样,它应该是从哪来的?
readelf是一个用于查看 ELF(Executable and Linkable Format)文件信息的工具(这部分内容设计编译原理,比较难理解,目前作者也只能讲个大概,不过绝对可以帮助你理解一些问题)。
1.ELF格式文件
ELF 是一种用于可执行文件、目标文件、共享库等在 Linux 和许多类 Unix 系统中的标准文件格式。
readelf可以显示ELF文件的各种详细信息。我们使用readelf -S envtest来查看envtest程序信息。
这是一个可执行程序形成的分段:
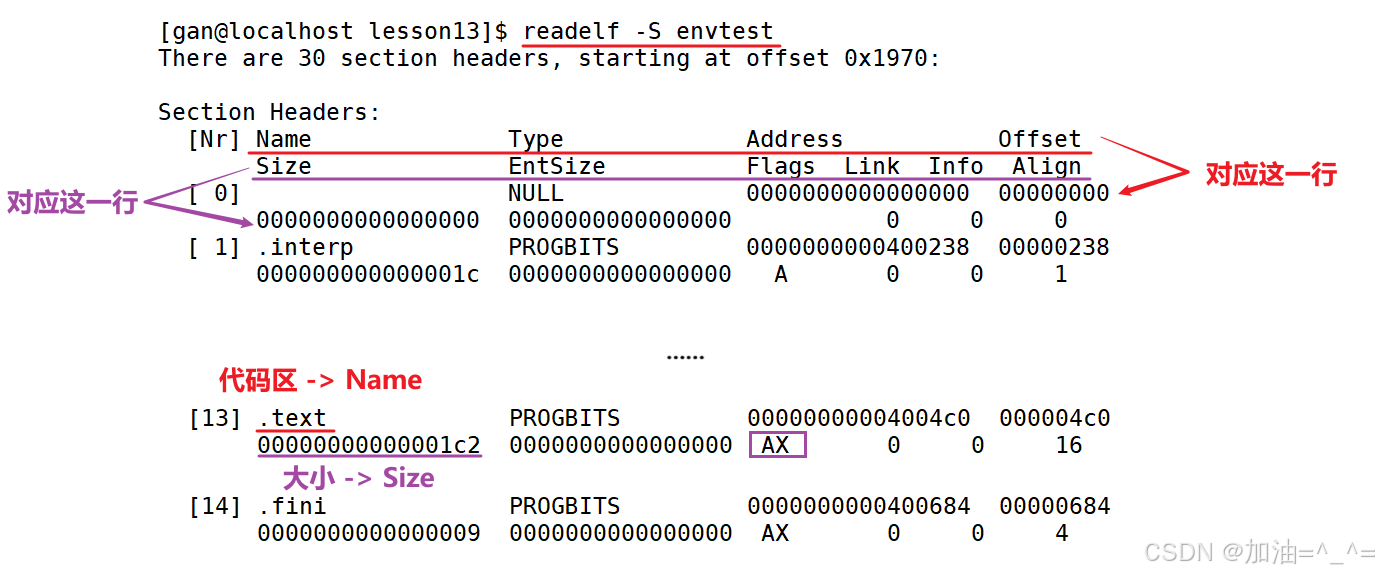
可执行程序在编译的时候,各个区域的大小区域就已经知道了。所以mm_struct各个区域大小从可执行程序来的,可执行程序会进行分段,当加载程序时,可以不加载代码和数据,但是会维护这个可执行程序的属性,比如其代码区有多大等都会维护,初始化mm_struct各个区域的大小。
我们可以通过可执行程序初始化页表的权限标志位,就是通过flags完成的。
可执行程序在编译的时候,各个区域的大小区域就已经知道了,在编译后的文件中声明。但是堆区和栈区这些内容并不存在,之后在加载(运行)进程被OS创建的。堆区在申请时,其实也就是改变之前的end_part1改变而已。
注意刚开始申请的空间可能并没有物理内存,因为刚申请并不一定要使用,当使用时申请物理内存。所以堆区开辟内存本质就是把虚拟内存空间扩大一点点。
五、为什么存在虚拟地址空间?
为什么存在虚拟地址空间?可以保护内存。什么又叫野指针呢?因为指向的是虚拟内存,页表查看权限标记或者映射关系,不对就会崩溃。
进程管理和内存管理在系统层面进行解耦合了,就是分开了。让进程以统一的视角看待物理内存,可执行程序的代码和数据可以加载到物理内存的任意地址处。也就是无序变有序。
这些以上操作都是有OS自动完成的,只要把进程管理好,地址空间就管理好了。
全局变量,字符常量的全局性,在程序运行期间都会有效,因为在他们在地址空间中,随着进程一直存在,全局变量的虚拟地址,大家都看得到。
六、重谈写时拷贝
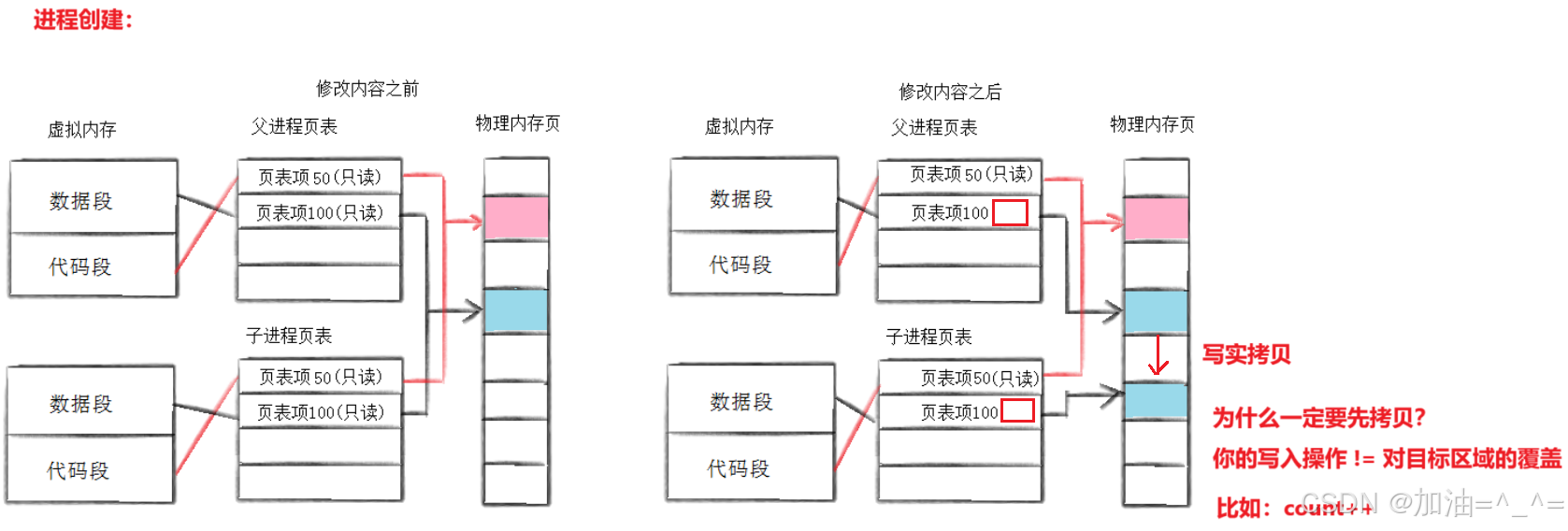
系统怎么知道哪个地方要发生写时拷贝?
当父进程创建子进程时,父进程的页表权限全部改为只读。子进程创建后,复制父进程页表,当子进程修改数据时,页表可以识别对只读的区域进行写入,触发系统错误(缺页中断)。系统检测修改的区域是代码区还是数据区,OS判定发生写时拷贝。OS就会申请内存,发生拷贝,修改页表,恢复权限。
大家有没有想过,为什么一定要对修改的数据先要进行拷贝?因为我们的写入操作 != 要对目标区域进行覆盖才做。比如:count++
fork失败的原因:系统中有太多进程或者实际用户的进程数超过了限制。
七、命令总结:
readelf:可以显示ELF文件的各种详细信息。
-S:项用于显示 ELF 文件中的节头表(Section Headers)信息。
总结:
我们大致了解了进程地址空间,而且比较详细的了解了写时拷贝的机制,和页表这个玩意儿,那么接下来的文章将更加劲爆!进程替换和进程退出码我们都是需要知道的,这样你对操作系统的很多操作就会醍醐灌顶,记得追剧!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









