




前3次作业都很简单,部分题目很简单就不给答案了。手敲公式也挺累的。大家自己写一下,我给点主观题的答案就好了。
答案不一定对。老师对平时作业很严格的,不要轻易拿图,也不要直接照搬文字,建议自己画图&码字(一旦发现抄袭平时分真的会扣很多的!!!!没有开玩笑,80左右的分都是正常的)
第一次作业
2、用实例说明摩尔定律。(摩尔定律的起源,作用,几十年来有何变化,目前是否还成立)
1.起源:
"摩尔定律"的"始作俑者"是戈顿·摩尔,大名鼎鼎的芯片制造厂商Intel公司的创始人之一。20世纪50年代末至用年代初半导体制造工业的高速发展,导致了"摩尔定律"的出台。
早在1959年,美国著名半导体厂商仙童公司首先推出了平面型晶体管,紧接着于1961年又推出了平面型集成电路。这种平面型制造工艺是在研磨得很平的硅片上,采用一种所谓"光刻"技术来形成半导体电路的元器件,如二极管、三极管、电阻和电容等。只要"光刻"的精度不断提高,元器件的密度也会相应提高,从而具有极大的发展潜力。因此平面工艺被认为是"整个半导体工业键",也是摩尔定律问世的技术基础。
1965年4月19日,时任仙童半导体公司研究开发实验室主任的摩尔应邀为《电子学》杂志35周年专刊写了一篇观察评论报告,题目是:"让集成电路填满更多的元件"。摩尔应这家杂志的要求对未来十年间半导体元件工业的发展趋势作出预言。据他推算,到1975年,在面积仅为四分之一平方英寸的单块硅芯片上,将有可能密集65000个元件。他是根据器件的复杂性(电路密度提高而价格降低)和时间之间的线性关系作出这一推断的,他的原话是这样说的:"最低元件价格下的理杂性每年大约增加一倍。可以确信,短期内这一增长率会继续保持。即便不是有所加快的话。而在更长时期内的增长率应是略有波动,尽管没有充分的理由来证明,这一增长率至少在未来十年内几乎维持为一个常数。"这就是后来被人称为"摩尔定律"的最初原型。
2.作用:
摩尔定律关于人类创造的定律,而不是物理学定律。摩尔定律实际上是关于人类信念的定律,当人们相信某件事情一定能做到时,就会努力去实现它。摩尔当初提出他的观察报告时,他实际上是给了人们一种信念,使大家相信他预言的发展趋势一定会持续。这大大加速了计算机集成的发展。
3.几十年的变化:
1975年,在一种新出现的电荷前荷器件存储器芯片中,的的确确含有将近65000个元件,与十年前摩尔的预言的确惊人地一致!另据Intel公司公布的统计结果,单个芯片上的晶体管数目,从1971年4004处理器上的2300个,增长到1997年PentiumII处理器上的7.5百万个,26年内增加了3200倍。我们不妨对此进行一个简单的验证:如果按摩尔本人"每两年翻一番"的预测,26年中应包括13个翻番周期,每经过一个周期,芯片上集成的元件数应提高2n倍(0≤n≤12),因此到第13个周期即26年后元件数应提高了212=4096倍,作为一种发展趋势的预测,这与实际的增长倍数3200倍可以算是相当接近了。如果以其他人所说的18个月为翻番周期,则二者相去甚远。可见从长远来看,还是摩尔本人的说法更加接近实际。
从个人计算机(即PC)的三大要素--微处理器芯片、半导体存储器和系统软件来考察摩尔定律。微处理器方面,从1979年的8086和8088,到1982年的80286,1985年的80386,1989年的80486,1993年的Pentium,1996年的PentiumPro,1997年的PentiumII,功能越来越强,价格越来越低,每一次更新换代都是摩尔定律的直接结果。与此同时PC机的内存储器容量由最早的480k扩大到8M,16M,与摩尔定律更为吻合。系统软件方面,早期的计算机由于存储容量的限制,系统软件的规模和功能受到很大限制,随着内存容量按照摩尔定律的速度呈指数增长,系统软件不再局限于狭小的空间,其所包含的程序代码的行数也剧增:Basic的源代码在1975年只有4,000行,20年后发展到大约50万行。微软的文字处理软件Word,1982年的第一版含有27,000行代码,20年后增加到大约200万行。有人将其发展速度绘制一条曲线后发现,软件的规模和复杂性的增长速度甚至超过了摩尔定律。系统软件的发展反过来又提高了对处理器和存储芯片的需求,从而刺激了集成电路的更快发展。
4.现况:
摩尔定律问世至今已近40年了。人们不无惊奇地看到半导体芯片制造工艺水平以一种令人目眩的速度提高。目前,Intel的微处理器达芯片Pentium4的主频已高2G(即12000M),2011年则要推出含有10亿个晶体管、每秒可执行1千亿条指令的芯片。
人们不禁要问:这种令人难以置信的发展速度会无止境地持续下去吗?不需要复杂的逻辑推理就可以知道:芯片上元件的几何尺寸总不可能无限制地缩小下去,这就意味着,总有一天,芯片单位面积上可集成的元件数量会达到极限。问题只是这一极限是多少,以及何时达到这一极限。业界已有专家预计,芯片性能的增长速度将在今后几年趋缓。一般认为,摩尔定律能再适用10年左右。
其制约的因素一是技术,二是经济。
从技术的角度看,随着硅片上线路密度的增加,其复杂性和差错率也将呈指数增长,同时也使全面而彻底的芯片测试几乎成为不可能。一旦芯片上线条的宽度达到纳米(10-9米)数量级时,相当于只有几个分子的大小,这种情况下材料的物理、化学性能将发生质的变化,致使采用现行工艺的半导体器件不能正常工作,摩尔定律也就要走到它的尽头了。
从经济的角度看,正如上述摩尔第二定律所述,目前是20-30亿美元建一座芯片厂,线条尺寸缩小到0.1微米时将猛增至100亿美元,比一座核电站投资还大。由于花不起这笔钱,迫使越来越多的公司退出了芯片行业。看来摩尔定律要再维持十年的寿命,也决非易事。
3. 说明计算机中二进制浮点数的表示格式和进行四则运算的方法。(找到有关二进制浮点数表示的标准,学习并说明二进制浮点数表示格式(至少包括双精度、单精度、半精度),不同精度之间的区别和主要应用。二进制浮点数四则运算的实现方法都有哪些,如何实现?)
答:
1.二级制浮点数表示标准:
IEEE二进制浮点数算术标准(IEEE 754)是20世纪80年代以来最广泛使用的浮点数运算标准,为许多CPU与浮点运算器所采用。这个标准定义了表示浮点数的格式(包括负零-0)与反常值(denormal number)),一些特殊数值(无穷(Inf)与非数值(NaN)),以及这些数值的“浮点数运算符”;它也指明了四种数值舍入规则和五种例外状况(包括例外发生的时机与处理方式)。
2.表示格式:
IEEE 754标准准确地定义了单精度和双精度浮点格式,并为这两种基本格式分别定义了扩展格式,如下所示:
- 单精度浮点格式(32 位)。
- 双精度浮点格式(64 位)。
- 扩展单精度浮点格式(≥43 位,不常用)。
- 扩展双精度浮点格式(≥79 位,一般情况下,Intel x86 结构的计算机采用的是 80 位,而 SPARC 结构的计算机采用的是 128 位)。
其中,只有 32 位单精度浮点数是本标准强烈要求支持的,其他都是可选部分。下面就来对单精度浮点与双精度浮点的存储格式做一些简要的阐述。
1) 单精度浮点格式
单精度浮点格式共 32 位,其中,s、exp 和 frac 段分别为 1 位、k=8 位和 n=23 位,如图 6 所示。
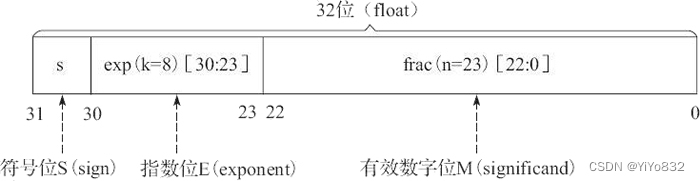
图 6
其中,32 位中的第 0 位存放小数段 frac 的最低有效位 LSB(least significant bit),第 22 位存放小数段 frac 的最高有效位 MSB(most significant bit);第 23 位存放指数段 exp 的最低有效位 LSB,第 30 位存放指数段 exp 的最高有效位 MSB;最高位,即第 31 位存放符号 s。例如,单精度数 8.25 的存储方式如图 7 所示。
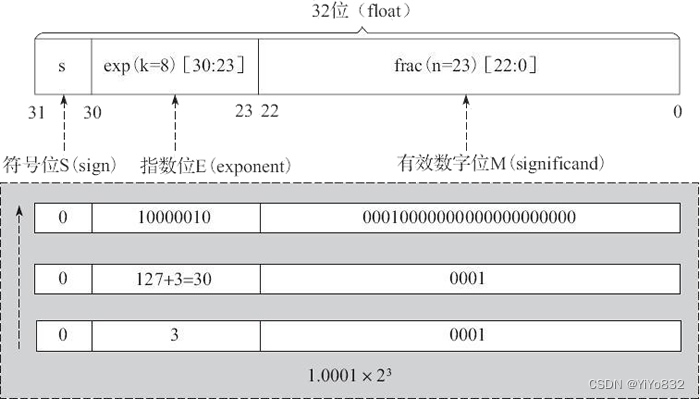
图 7
2) 双精度浮点格式
双精度浮点格式共 64 位,其中,s、exp 和 frac 段分别为 1 位、k=11 位和 n=52 位,如图 8 所示。

图 8
其中,frac[31:0] 存放小数段的低 32 位(即第 0 位存放整个小数段的最低有效位 LSB,第 31 位存放小数段低 32 位的最高有效位 MSB);frac[51:32] 存放小数段的高 20 位(即第 32 位存放高 20 位的最低有效位 LSB,第 51 位存放整个小数段的最高有效位 MSB);第 52 位存放指数段 exp 的最低有效位 LSB,第 62 位存放指数段 exp 的最高有效位 MSB;最高位,即第 63 位存放符号 s。
在 Intel x86 结构的计算机中,数据存放采用的是小端法(Little Endian),故较低地址的 32 位的字中存放小数段的 frac[31:0] 位。而在 SPARC 结构的计算机中,因其数据存放采用的是大端法(Big Endian),故较高地址的 32 位字中存放小数段的 frac[31:0] 位。
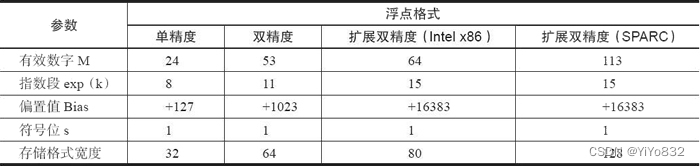
前面主要讨论了 IEEE 754 的单精度与双精度浮点格式,下表对浮点数的相关参数进行了总结,有兴趣的读者可以根据此表对其他浮点格式进行深入解读。

3)半精度
IEEE754-2008包含一种“半精度”格式,只有16位宽。故它又被称之为binary16,这种类型的浮点数只适合用于存储那些对精度要求不高的数字,不适合用于进行计算。与单精度浮点数相比,它的优点是只需要一半的存储空间和带宽,但是缺点是精度较低。
半精度的格式与单精度的格式类似,最左边的一位仍是符号位,指数有5位宽且以余-16(excess-16)的形式存储,尾数有10位宽,但具有隐含1。
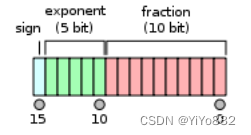
如图所示,sign为符号位,0表示这个浮点数为正,1表示这个浮点数为负
先介绍尾数,再说指数,fraction为尾数,有10位长,但是有隐含1,尾数可以理解为是一个浮点数小数点后的数,如1.11,尾数就为1100000000(1),最后的隐含1主要用于计算时,隐含1可能存在可以进位的情况。
exponent为指数位,有5位长,具体表示的值有以下几种情况:
1.当指数位全为0 ,尾数位也全为0的时,表示的就是0
2.当指数位全为0,尾数位不全为0时,表示为subnormal value,非规格化浮点数,是一个非常小的数
3.当指数位全为1,尾数位全为0时,表示的是无穷大,此时如果符号位为0,表示正无穷,符号位为1,表示负无穷
4.当指数位全为1,尾数位不全为0时,表示的不是一个数
其余情况下,指数位的值减去15就是其表示的指数,如11110表示的就是30-15=15。所以我们可以得到,半精度浮点数的值得计算方式为(-1)^sign×2^(指数位的值)×(1+0.尾数位)
3.四则运算
浮点数的运算步骤
浮点数的加减运算一般由以下五个步骤完成:对阶、尾数运算、规格化、舍入处理、溢出判断
一、对阶
所谓对阶是指将两个进行运算的浮点数的阶码对齐的操作。对阶的目的是为使两个浮点数的尾数能够进行加减运算。
加减运算时,只有使两浮点数的指数值部分相同,才能将相同的指数值作为公因数提出来,然后进行尾数的加减运算。对阶的具体方法是:首先求出两浮点数阶码的差
,将小阶码加上Δ E \Delta EΔE,使之与大阶码相等,同时将小阶码对应的浮点数的尾数右移相应位数,以保证该浮点数的值不变。几点注意:
(1)对阶的原则是小阶对大阶,之所以这样做是因为若大阶对小阶,则尾数的数值部分的高位需移出,而小阶对大阶移出的是尾数的数值部分的低位,这样损失的精度更小。
(2)若Δ E \Delta EΔE=0,说明两浮点数的阶码已经相同,无需再做对阶操作了。
(3)采用补码表示的尾数右移时,符号位保持不变。
(4)由于尾数右移时是将最低位移出,会损失一定的精度,为减少误差,可先保留若干移出的位,供以后舍入处理用。
二、尾数运算
尾数运算就是进行完成对阶后的尾数相加减。这里采用的就是我们前面讲过的纯小数的定点数加减运算。
三、结果规格化
在机器中,为保证浮点数表示的唯一性,浮点数在机器中都是以规格化形式存储的。对于IEEE754标准的浮点数来说,就是尾数必须是1.M的形式。由于在进行上述两个定点小数的尾数相加减运算后,尾数有可能是非规格化形式,为此必须进行规格化操作。
规格化操作包括左规和右规两种情况。
左规操作
将尾数左移,同时阶码减值,直至尾数成为1. M 1.M1.M的形式。例如,浮点数0.0011 ∗ 2 5 0.0011*2^50.0011∗25 是非规格化的形式,需进行左规操作,将其尾数左移3位,同时阶码减3,就变成1.1100 ∗ 2 2 1.1100*2^21.1100∗22规格化形式了。
右规操作
将尾数右移1位,同时阶码增1,便成为规格化的形式了。要注意的是,右规操作只需将尾数右移一位即可,这种情况出现在尾数的最高位(小数点前一位)运算时出现了进位,使尾数成为10. x x x x 10.xxxx10.xxxx或11. x x x x 11.xxxx11.xxxx的形式。
例如,10.0011 ∗ 2 5 10.0011*2^510.0011∗25 右规一位后便成为1.00011 ∗ 2 6 1.00011*2^61.00011∗2 6
的规格化形式了。
四、 舍入处理
浮点运算在对阶或右规时,尾数需要右移,被右移出去的位会被丢掉,从而造成运算结果精度的损失。为了减少这种精度损失,可以将一定位数的移出位先保留起来,称为保护位,在规格化后用于舍入处理。
IEEE754标准列出了四种可选的舍入处理方法:
(1)就近舍入(round to nearest)这是标准列出的默认舍入方式,其含义相当于我们日常所说的“四舍五入”。例如,对于32位单精度浮点数来说,若超出可保存的23位的多余位大于等于100 … 01 100…01100…01,则多余位的值超过了最低可表示位值的一半,这种情况下,舍入的方法是在尾数的最低有效位上加1;若多余位小于等于011 … 11 011…11011…11,则直接舍去;若多余位为100 … 00 100…00100…00,此时再判断尾数的最低有效位的值,若为0则直接舍去,若为1则再加1。
(2)朝+ ∞ +∞+∞舍入(round toward + ∞ +∞+∞)对正数来说,只要多余位不为全0,则向尾数最低有效位进1;对负数来说,则是简单地舍去。
(3)朝− ∞ -∞−∞舍入(round toward − ∞ -∞−∞)与朝+ ∞ +∞+∞舍入方法正好相反,对正数来说,只是简单地舍去;对负数来说,只要多余位不为全0,则向尾数最低有效位进1。
(4)朝0舍入(round toward 0)
即简单地截断舍去,而不管多余位是什么值。这种方法实现简单,但容易形成累积误差,且舍入处理后的值总是向下偏差。
五、 溢出判断
与定点数运算不同的是,浮点数的溢出是以其运算结果的阶码的值是否产生溢出来判断的。若阶码的值超过了阶码所能表示的最大正数,则为上溢,进一步,若此时浮点数为正数,则为正上溢,记为+ ∞ +∞+∞,若浮点数为负数,则为负上溢,记为− ∞ -∞−∞;若阶码的值超过了阶码所能表示的最小负数,则为下溢,进一步,若此时浮点数为正数,则为正下溢,若浮点数为负数,则为负下溢。正下溢和负下溢都作为0处理。
要注意的是,浮点数的表示范围和补码表示的定点数的表示范围是有所不同的,定点数的表示范围是连续的,而浮点数的表示范围可能是不连续的。
加减法:
第一步:对阶
第二步:尾数运算
第三步:规格化
第四步:舍入处理
第五步:溢出判断
乘法:
浮点数的乘法分为以下几个步骤:
计算符号位:通过异或操作计算符号位,若两个操作数符号位相同,则结果符号位为0,否则结果符号为1
计算原始尾数:两个操作数的尾数相乘(注意,这里是1.M * 1.M),得到原始尾数
计算原始指数:将两个操作数的指数(这里指的是指数幂次方,也就是阶码-移码后得到的数)相加,得到原始指数
规格化与舍入:对原始尾数和原始指数进行规格化,获得结果的指数,再对尾数进行舍入,获得结果的尾数
除法:
除法与乘法相差不大,变更为指数相减,尾数相除。
书上习题(略)
第二次作业
1、列举三种处理器的架构,并结合一个具体的处理器型号说明每个功能模块的功能。
答:经过我的查找发现有三种处理器架构:x86架构,ARM架构,RISC-V架构。
1. x86架构:x86是一种32位和64位处理器架构,最初由英特尔公司在1978年推出并广泛采用。它是PC和服务器市场上最流行的架构之一。
x86处理器框架采用复杂指令集计算机(CISC)体系结构。它有多个寄存器和多级缓存,能够更有效地管理内存并提高运行速度。此外,x86处理器采用了分段式内存管理,将内存地址空间划分为多个段,每个段都有自己的基地址和限长,可以实现更灵活的内存管理。具体来说,在x86架构中,数据和指令以字节为单位存储,并使用寄存器来处理数据。在32位模式下,有8个通用寄存器,每个寄存器可以存储32位数据。在64位模式下,有16个通用寄存器,每个寄存器可以存储64位数据。这使得x86架构非常适合处理大量数据和高性能应用程序。
x86架构还包括一个内存管理单元(MMU),它负责将虚拟地址转换为物理地址。这使得操作系统可以将多个进程加载到内存中,而不会相互干扰。此外,x86架构还提供了特权级别来控制访问硬件资源。这使得操作系统可以确保只有具有足够权限的代码才能执行敏感操作。
x86架构还包括一组指令集,这些指令被处理器硬件直接支持。这些指令集包括基本算术操作、逻辑操作、移位操作、比较操作等。此外,x86架构还支持SIMD指令集,这些指令集允许处理器同时对多个数据进行相同的操作,从而提高了处理器的并行处理能力。
我还了解到了,最初的x86架构处理器的时钟频率很低,但随着技术的发展,现代x86处理器的时钟频率已经超过4GHz。此外,x86架构还使用了一些技术来提高处理器的性能和效率,例如超线程技术、动态频率调整和高速缓存。不过,关于上述技术,其实我都搞不太清楚,惭愧惭愧。
总之,x86架构是一种广泛应用于PC和服务器市场的处理器架构。它具有强大的处理能力、内存管理能力、特权级别和指令集支持,可以处理大量数据和高性能应用程序。
例子如下:
x86架构 - Intel Core i7-11700K处理器
- 控制单元:从内存中获取指令并将其解码为可执行操作。
- 算术逻辑单元(ALU):执行加法、减法等基本算术运算,以及位操作和逻辑操作等。
- 浮点数单元(FPU):执行浮点运算,如乘法、除法等。
- 缓存:存储最近频繁使用的数据,以提高性能。
2. ARM架构:ARM处理器是一种基于RISC(Reduced Instruction Set Computing)架构的微处理器,由Arm Holdings开发。它的设计目标是在低功耗和成本下提供高性能计算。ARM处理器已经广泛应用于移动设备、智能家居、物联网等领域。
ARM处理器采用了精简指令集计算机(RISC)的设计思想,这种设计理念强调通过减少指令集的复杂度,来增加指令执行的速度。与CISC(Complex Instruction Set Computing)架构相比,RISC架构具有更少的指令、更小的代码体积和更高的指令执行效率。
ARM处理器分为两个主要类别:处理器核和系统芯片。 处理器核是一个独立的处理器单元,通常由CPU、内存管理单元、系统总线接口和其他附属单元组成。而系统芯片包含I/O接口、时钟控制器、DMA(直接存储器访问)控制器等外围设备。
ARM处理器架构被分为三个级别:应用程序级别、操作系统级别和体系结构级别。在应用程序级别,ARM处理器可以运行各种类型的软件,包括浏览器、多媒体播放器和游戏引擎等。在操作系统级别,ARM处理器支持众多操作系统,包括Android、iOS、Windows Phone等。在体系结构级别,ARM处理器架构包含ARMv7和ARMv8两大版本,其中ARMv8是ARM处理器最新的架构版本。
ARMv7和ARMv8的区别在于指令集的不同。ARMv7使用32位的指令集,而ARMv8则同时支持32位和64位的指令集,这使得ARMv8的处理器能够更好地处理大型数据集和更高级的计算任务。此外,ARMv8还引入了虚拟化技术和硬件加密功能,提高了安全性和可靠性。
总之,ARM处理器架构是一种高性能、低功耗的处理器设计,广泛应用于移动设备、物联网等领域。其采用的RISC架构和ARMv8的优化,使得ARM处理器在计算效率和能效方面都表现出色,成为许多移动设备和嵌入式系统的首选处理器架构。
例子如下:
ARM架构 - Qualcomm Snapdragon 888处理器
- 处理器核心:包含多个执行指令的处理器。
- 内存控制器:从内存中获取数据并将其传递到另一个处理单元。
- 图像信号处理器(ISP):处理相机芯片发出的图像信号。
- 数字信号处理器(DSP):处理音频和视频信号,以及其他数字信号。
3. RISC-V架构:RISC-V(Reduced Instruction Set Computing Five)是一种开放源代码的指令集架构,它旨在提供一个通用的、免费的、可扩展的基础架构,以支持各种处理器和系统的开发。与其他处理器架构不同,RISC-V不受专利限制,任何人都可以自由使用它。
RISC-V指令集架构采用了精简指令集计算(RISC)的设计理念,这意味着它的指令集非常简单,每条指令的执行时间都很短,这有助于提高处理器的效率和性能。同时,RISC-V还采用了模块化的设计方法,使得它可以根据不同的应用需求进行定制,从而实现更好的灵活性和可扩展性。
RISC-V的指令集包含基本指令集(RV32I/RV64I),标准扩展指令集(RV32M/RV64M)、多媒体扩展指令集(RV32A/RV64A)、原子操作扩展指令集(RV32F/RV64F)、浮点数扩展指令集(RV32D/RV64D)和向量扩展指令集(RV32V/RV64V)等多个部分。其中,基本指令集包含了大多数处理器需要的基本指令,而其他扩展指令集则可以根据需要进行选用,以满足不同的应用需求。
RISC-V还采用了类似于ARM的三级特权架构,包括用户模式、监管模式和机器模式。在用户模式下,运行的是应用程序;在监管模式下,操作系统可以管理和控制硬件资源;在机器模式下,则是系统最底层的操作,可以访问所有的硬件资源。
总之,RISC-V是一种高度灵活、可扩展的开放源代码指令集架构,它已经被广泛应用于各种领域,包括物联网、人工智能、高性能计算等。
例子如下:RISC-V架构 - SiFive Freedom E310处理器
- 软件栈:包括编译器、操作系统和应用程序等。
- 用户模式和特权模式:用户模式可访问部分寄存器,而特权模式可以访问全部寄存器。
- 存储管理单元(MMU):将虚拟地址转换为物理地址,并确保程序只访问其允许访问的内存。
2、介绍处理器中流水线的概念。结合某一具体处理器,说明处理器的流水线如何设计和实现的。
答:处理器中的流水线是一种用于提高处理速度和效率的技术,它将指令的执行过程拆分为多个步骤,并让不同的指令同时在不同的阶段执行。这样可以使处理器在同一时刻处理多个指令,从而提高处理器的吞吐量和执行效率。我个人觉得这与编程思想中的二分法,程序中的进程池线程池有着极大的关联。
以Intel Core i7-11700K处理器为例,其流水线的设计如下:
1.取指阶段:从内存中获取下一条指令。
2. 解码阶段:将指令解码成可执行操作,确定该指令需要的资源和数据。
3. 执行阶段:执行该指令所需的计算或操作,生成结果。
4. 访存阶段:将结果存储到内存或者从内存中读取操作数。
5. 回写阶段:将结果写回到寄存器。
这些阶段被组织成一个流水线,每个阶段都有自己的功能模块和专门的电路来执行相应的操作。在一个时钟周期内,处理器会完成一个阶段的操作,并将指令传递给下一个阶段。这样,处理器可以在同一时刻执行多个指令,并实现超标量执行的效果。
但是,流水线也存在一些问题,比如因为相关性等原因导致的数据冲突可能会影响性能。因此,处理器还需要实现一些技术来解决这些问题,如预测分支、乱序执行等。同时,处理器的流水线还需要考虑保证正确性和稳定性的设计,如异常处理、错误检测等。
书上习题(略)
第三次作业
1、列举三种总线协议,并结合他们的应用场景说明每种总线的特点。
以下是三种总线协议和其应用场景及特点:
1.1 USB(Universal Serial Bus)
USB 是一种数字通信总线,可以连接多个外部设备到计算机或其他支持 USB 接口的设备上。它具有以下特点:
- 高速传输:USB 3.2 的最大传输速度可达 20 Gbps。
- 热插拔:可以在不关闭计算机或其他设备的情况下连接或断开外部设备。
- 多设备支持:USB 可以支持多达 127 个设备同时连接到一个主机上。
- 适用于各种设备:USB 适用于各种设备,包括打印机、鼠标、键盘、移动硬盘等。
1.2 PCIe(Peripheral Component Interconnect Express)
PCIe 是一种高速串行总线协议,用于在**计算机内部连接各种组件**,例如显卡、网卡和存储控制器等。它具有以下特点:
- 高速传输:PCIe 4.0 的最大传输速度可以达到 16 GT/s,比 USB 和 SATA 更快。
- 高带宽:PCIe 提供了高达 32 个数据通道,每个通道都可以实现全双工传输,因此能够同时进行读取和写入操作。
- 低延迟:PCIe 具有非常低的延迟,因此适用于对实时性要求较高的应用,例如游戏和视频编辑等。
- 内部连接:PCIe 主要用于在计算机内部连接各种组件。
1.3 I²C(Inter-Integrated Circuit)
I²C 是一种串行总线协议,用于**连接多个数字设备**,例如传感器、存储器和实时时钟等。它具有以下特点:
- 简单易用:I²C 比其他串行总线更容易使用,因为它只需要两条数据线和一个时钟线。
- 多设备支持:I²C 可以支持多达数十个设备同时连接到同一个总线上。
- 低速传输:I²C 的最大传输速度只有几百 kbps,比 USB 和 PCIe 慢得多。
- 低功耗:I²C 的功耗非常低,因此适用于需要长时间运行的电池供电设备,例如智能手表和传感器。
2、学习数字系统/PC的接口。
2.1 数字系统/PC的接口是什么?
数字系统/PC的接口通常是指用于连接外部设备或组件的标准化接口或端口,例如USB、HDMI、Ethernet、PCI等。这些接口允许数字系统与其他设备进行数据传输和通信,并支持各种输入和输出操作。
2.2 几种常见的数字系统/PC的接口
1. 并口(Parallel Port):使用多条并行数据线,可以同时传输多个位的数据。例如,打印机通常使用并口连接到计算机。
2. 串口(Serial Port):使用单条串行数据线,逐位地传输数据。例如,鼠标或调制解调器通常使用串口连接到计算机。
3. USB(Universal Serial Bus):一种高速、热插拔的接口,支持同时传输多个位的数据。USB接口可用于连接各种设备,如打印机、键盘、存储设备等。
4. HDMI(High-Definition Multimedia Interface):一种数字音视频接口,支持高清晰度视频和多声道音频传输。
5. Ethernet(以太网):一种局域网通信协议,使用RJ45接口传输数据。Ethernet接口可用于连接计算机、路由器、交换机等设备。
6. PCIe(Peripheral Component Interconnect Express):一种高速串行总线接口,用于连接内部硬件组件,如显卡、网卡等。
2.3 几种常见的所需的驱动程序和协议
1. USB 驱动程序和协议
2. Ethernet 驱动程序和协议
3. WiFi 驱动程序和协议
4. Bluetooth 驱动程序和协议
5. 显示器和显卡驱动程序
6. 声卡驱动程序
7. 打印机驱动程序
8. 存储设备驱动程序,如硬盘、光盘等
9. 数据总线协议,如PCI、PCI Express
10. 外围设备接口协议,如SPI、I2C、UART等。
3、课后习题:3.5、3.6、3.9、3.10。
3.5 题略
输出函数表达式如下:
((AB)'(A'+C)'+(B⊕C'))'
可以化简为
BC'+A'B'C
(注:A' 表示为 非A , A⊕B 表示异或 )
设计图如下:
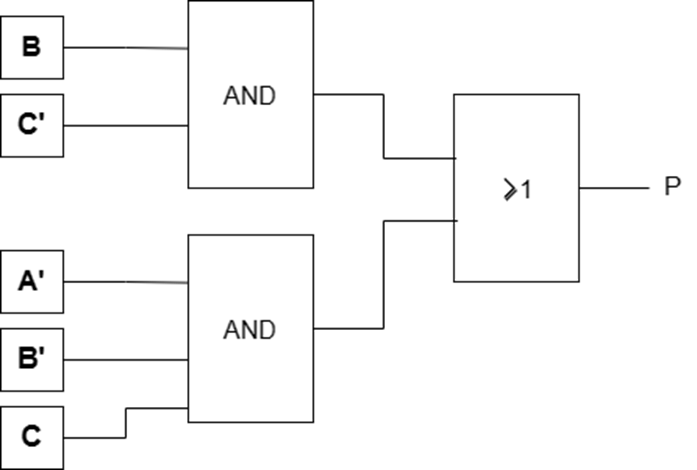
3.6 题略
输入为B1,B2,B4,B8
输出为A1,A2,A4,A8
A1 = B1’
A2 = B2
A4 = B2 ⊕ B4 = B2B4’+B2’B4
A8 = (B2+B4+B8)’ = B2’B4’B8’
推测作用:
绘制出下表:

功能如下:
1.当输入数字0,1;
2.当输入其它数字x,输出(17-x)mod8
3.9 题略
不想画图啦,太麻烦了。hhhhh,不给答案了
4、电子市场一日游。(以游记或日记的形式写,主要内容包括见闻和心得)
GPT吧!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









