








一、GPT-2介绍
GPT-2(Generative Pre-trained Transformer 2)是由OpenAI在2019年发布的一款基于Transformer架构的语言模型。它是一个深度学习模型,设计用于生成自然语言文本,能够根据给定的文本片段预测并生成后续的文本内容。GPT-2通过大规模无监督学习训练,在互联网上抓取的大量文本数据上进行了预训练,使其能够理解和生成多种类型的文本,包括文章、故事、诗歌等
from transformers import GPT2LMHeadModel
model = GPT2LMHeadModel.from_pretrained("./gpt2") # 124M
sd = model.state_dict()
for k, v in sd.items():
print(k, v.shape)transformer.wte.weight torch.Size([50257, 768])
transformer.wpe.weight torch.Size([1024, 768])
transformer.h.0.ln_1.weight torch.Size([768])
transformer.h.0.ln_1.bias torch.Size([768])
transformer.h.0.attn.c_attn.weight torch.Size([768, 2304])
transformer.h.0.attn.c_attn.bias torch.Size([2304])
transformer.h.0.attn.c_proj.weight torch.Size([768, 768])
transformer.h.0.attn.c_proj.bias torch.Size([768])
transformer.h.0.ln_2.weight torch.Size([768])
transformer.h.0.ln_2.bias torch.Size([768])
transformer.h.0.mlp.c_fc.weight torch.Size([768, 3072])
transformer.h.0.mlp.c_fc.bias torch.Size([3072])
transformer.h.0.mlp.c_proj.weight torch.Size([3072, 768])
transformer.h.0.mlp.c_proj.bias torch.Size([768])
transformer.h.1.ln_1.weight torch.Size([768])
transformer.h.1.ln_1.bias torch.Size([768])
transformer.h.1.attn.c_attn.weight torch.Size([768, 2304])
transformer.h.1.attn.c_attn.bias torch.Size([2304])
transformer.h.1.attn.c_proj.weight torch.Size([768, 768])
transformer.h.1.attn.c_proj.bias torch.Size([768])
transformer.h.1.ln_2.weight torch.Size([768])
transformer.h.1.ln_2.bias torch.Size([768])
transformer.h.1.mlp.c_fc.weight torch.Size([768, 3072])
transformer.h.1.mlp.c_fc.bias torch.Size([3072])
transformer.h.1.mlp.c_proj.weight torch.Size([3072, 768])
transformer.h.1.mlp.c_proj.bias torch.Size([768])
transformer.h.2.ln_1.weight torch.Size([768])
transformer.h.2.ln_1.bias torch.Size([768])
transformer.h.2.attn.c_attn.weight torch.Size([768, 2304])
transformer.h.2.attn.c_attn.bias torch.Size([2304])
transformer.h.2.attn.c_proj.weight torch.Size([768, 768])
transformer.h.2.attn.c_proj.bias torch.Size([768])
transformer.h.2.ln_2.weight torch.Size([768])
transformer.h.2.ln_2.bias torch.Size([768])
transformer.h.2.mlp.c_fc.weight torch.Size([768, 3072])
transformer.h.2.mlp.c_fc.bias torch.Size([3072])
transformer.h.2.mlp.c_proj.weight torch.Size([3072, 768])
transformer.h.2.mlp.c_proj.bias torch.Size([768])
transformer.h.3.ln_1.weight torch.Size([768])
transformer.h.3.ln_1.bias torch.Size([768])
transformer.h.3.attn.c_attn.weight torch.Size([768, 2304])
transformer.h.3.attn.c_attn.bias torch.Size([2304])
transformer.h.3.attn.c_proj.weight torch.Size([768, 768])
transformer.h.3.attn.c_proj.bias torch.Size([768])
transformer.h.3.ln_2.weight torch.Size([768])
transformer.h.3.ln_2.bias torch.Size([768])
transformer.h.3.mlp.c_fc.weight torch.Size([768, 3072])
transformer.h.3.mlp.c_fc.bias torch.Size([3072])
transformer.h.3.mlp.c_proj.weight torch.Size([3072, 768])
transformer.h.3.mlp.c_proj.bias torch.Size([768])
transformer.h.4.ln_1.weight torch.Size([768])
transformer.h.4.ln_1.bias torch.Size([768])
transformer.h.4.attn.c_attn.weight torch.Size([768, 2304])
transformer.h.4.attn.c_attn.bias torch.Size([2304])
transformer.h.4.attn.c_proj.weight torch.Size([768, 768])
transformer.h.4.attn.c_proj.bias torch.Size([768])
transformer.h.4.ln_2.weight torch.Size([768])
transformer.h.4.ln_2.bias torch.Size([768])
transformer.h.4.mlp.c_fc.weight torch.Size([768, 3072])
transformer.h.4.mlp.c_fc.bias torch.Size([3072])
transformer.h.4.mlp.c_proj.weight torch.Size([3072, 768])
transformer.h.4.mlp.c_proj.bias torch.Size([768])
transformer.h.5.ln_1.weight torch.Size([768])
transformer.h.5.ln_1.bias torch.Size([768])
transformer.h.5.attn.c_attn.weight torch.Size([768, 2304])
transformer.h.5.attn.c_attn.bias torch.Size([2304])
transformer.h.5.attn.c_proj.weight torch.Size([768, 768])
transformer.h.5.attn.c_proj.bias torch.Size([768])
transformer.h.5.ln_2.weight torch.Size([768])
transformer.h.5.ln_2.bias torch.Size([768])
transformer.h.5.mlp.c_fc.weight torch.Size([768, 3072])
transformer.h.5.mlp.c_fc.bias torch.Size([3072])
transformer.h.5.mlp.c_proj.weight torch.Size([3072, 768])
transformer.h.5.mlp.c_proj.bias torch.Size([768])
transformer.h.6.ln_1.weight torch.Size([768])
transformer.h.6.ln_1.bias torch.Size([768])
transformer.h.6.attn.c_attn.weight torch.Size([768, 2304])
transformer.h.6.attn.c_attn.bias torch.Size([2304])
transformer.h.6.attn.c_proj.weight torch.Size([768, 768])
transformer.h.6.attn.c_proj.bias torch.Size([768])
transformer.h.6.ln_2.weight torch.Size([768])
transformer.h.6.ln_2.bias torch.Size([768])
transformer.h.6.mlp.c_fc.weight torch.Size([768, 3072])
transformer.h.6.mlp.c_fc.bias torch.Size([3072])
transformer.h.6.mlp.c_proj.weight torch.Size([3072, 768])
transformer.h.6.mlp.c_proj.bias torch.Size([768])
transformer.h.7.ln_1.weight torch.Size([768])
transformer.h.7.ln_1.bias torch.Size([768])
transformer.h.7.attn.c_attn.weight torch.Size([768, 2304])
transformer.h.7.attn.c_attn.bias torch.Size([2304])
transformer.h.7.attn.c_proj.weight torch.Size([768, 768])
transformer.h.7.attn.c_proj.bias torch.Size([768])
transformer.h.7.ln_2.weight torch.Size([768])
transformer.h.7.ln_2.bias torch.Size([768])
transformer.h.7.mlp.c_fc.weight torch.Size([768, 3072])
transformer.h.7.mlp.c_fc.bias torch.Size([3072])
transformer.h.7.mlp.c_proj.weight torch.Size([3072, 768])
transformer.h.7.mlp.c_proj.bias torch.Size([768])
transformer.h.8.ln_1.weight torch.Size([768])
transformer.h.8.ln_1.bias torch.Size([768])
transformer.h.8.attn.c_attn.weight torch.Size([768, 2304])
transformer.h.8.attn.c_attn.bias torch.Size([2304])
transformer.h.8.attn.c_proj.weight torch.Size([768, 768])
transformer.h.8.attn.c_proj.bias torch.Size([768])
transformer.h.8.ln_2.weight torch.Size([768])
transformer.h.8.ln_2.bias torch.Size([768])
transformer.h.8.mlp.c_fc.weight torch.Size([768, 3072])
transformer.h.8.mlp.c_fc.bias torch.Size([3072])
transformer.h.8.mlp.c_proj.weight torch.Size([3072, 768])
transformer.h.8.mlp.c_proj.bias torch.Size([768])
transformer.h.9.ln_1.weight torch.Size([768])
transformer.h.9.ln_1.bias torch.Size([768])
transformer.h.9.attn.c_attn.weight torch.Size([768, 2304])
transformer.h.9.attn.c_attn.bias torch.Size([2304])
transformer.h.9.attn.c_proj.weight torch.Size([768, 768])
transformer.h.9.attn.c_proj.bias torch.Size([768])
transformer.h.9.ln_2.weight torch.Size([768])
transformer.h.9.ln_2.bias torch.Size([768])
transformer.h.9.mlp.c_fc.weight torch.Size([768, 3072])
transformer.h.9.mlp.c_fc.bias torch.Size([3072])
transformer.h.9.mlp.c_proj.weight torch.Size([3072, 768])
transformer.h.9.mlp.c_proj.bias torch.Size([768])
transformer.h.10.ln_1.weight torch.Size([768])
transformer.h.10.ln_1.bias torch.Size([768])
transformer.h.10.attn.c_attn.weight torch.Size([768, 2304])
transformer.h.10.attn.c_attn.bias torch.Size([2304])
transformer.h.10.attn.c_proj.weight torch.Size([768, 768])
transformer.h.10.attn.c_proj.bias torch.Size([768])
transformer.h.10.ln_2.weight torch.Size([768])
transformer.h.10.ln_2.bias torch.Size([768])
transformer.h.10.mlp.c_fc.weight torch.Size([768, 3072])
transformer.h.10.mlp.c_fc.bias torch.Size([3072])
transformer.h.10.mlp.c_proj.weight torch.Size([3072, 768])
transformer.h.10.mlp.c_proj.bias torch.Size([768])
transformer.h.11.ln_1.weight torch.Size([768])
transformer.h.11.ln_1.bias torch.Size([768])
transformer.h.11.attn.c_attn.weight torch.Size([768, 2304])
transformer.h.11.attn.c_attn.bias torch.Size([2304])
transformer.h.11.attn.c_proj.weight torch.Size([768, 768])
transformer.h.11.attn.c_proj.bias torch.Size([768])
transformer.h.11.ln_2.weight torch.Size([768])
transformer.h.11.ln_2.bias torch.Size([768])
transformer.h.11.mlp.c_fc.weight torch.Size([768, 3072])
transformer.h.11.mlp.c_fc.bias torch.Size([3072])
transformer.h.11.mlp.c_proj.weight torch.Size([3072, 768])
transformer.h.11.mlp.c_proj.bias torch.Size([768])
transformer.ln_f.weight torch.Size([768])
transformer.ln_f.bias torch.Size([768])
lm_head.weight torch.Size([50257, 768])transformer.wte.weight 是词嵌入矩阵,其中wte 是 "word token embeddings" 的缩写
transformer.wpe.weight 是位置嵌入矩阵,其中wpe 是 "word position embeddings" 的缩写
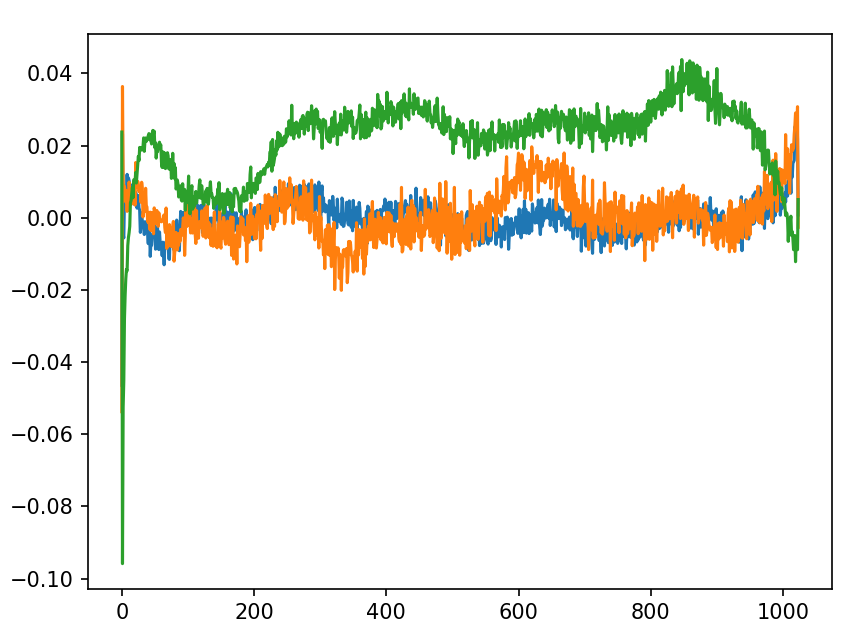
这张图展示了GPT-2模型位置嵌入矩阵中三个特定维度(150、200和250)随序列位置(0到1024)的权重变化情况。图中三条曲线分别对应transformer.wpe.weight矩阵中第150、200和250列的值,直观呈现了不同维度上位置编码的分布模式。
从曲线形态可以观察到几个关键特征:
-
维度特异性:不同维度的曲线展现出显著差异的波动模式。绿色曲线呈现明显的正向递增趋势,而橙色和蓝色曲线则在零值附近震荡,表明模型在不同维度上采用了差异化的位置编码策略。
-
非线性编码:这些编码既不同于简单的线性位置编码,也不完全等同于传统的正余弦位置编码,而是呈现出经过优化调整后的复杂波形结构。这种非线性特征反映了模型在自然语言数据训练过程中学习到的位置依赖关系。
-
信息分布:曲线的非周期性波动表明,GPT-2通过端到端训练,自主发现了将位置信息分布式编码到多个维度的有效方式。每个维度的编码模式都承担着特定的位置表征功能,共同构成完整的位置感知系统。
这种多维差异化编码机制使模型能够:
精确捕捉长距离依赖关系 区分相近位置的细微差别
适应不同长度的序列输入 维持位置信息的鲁棒性
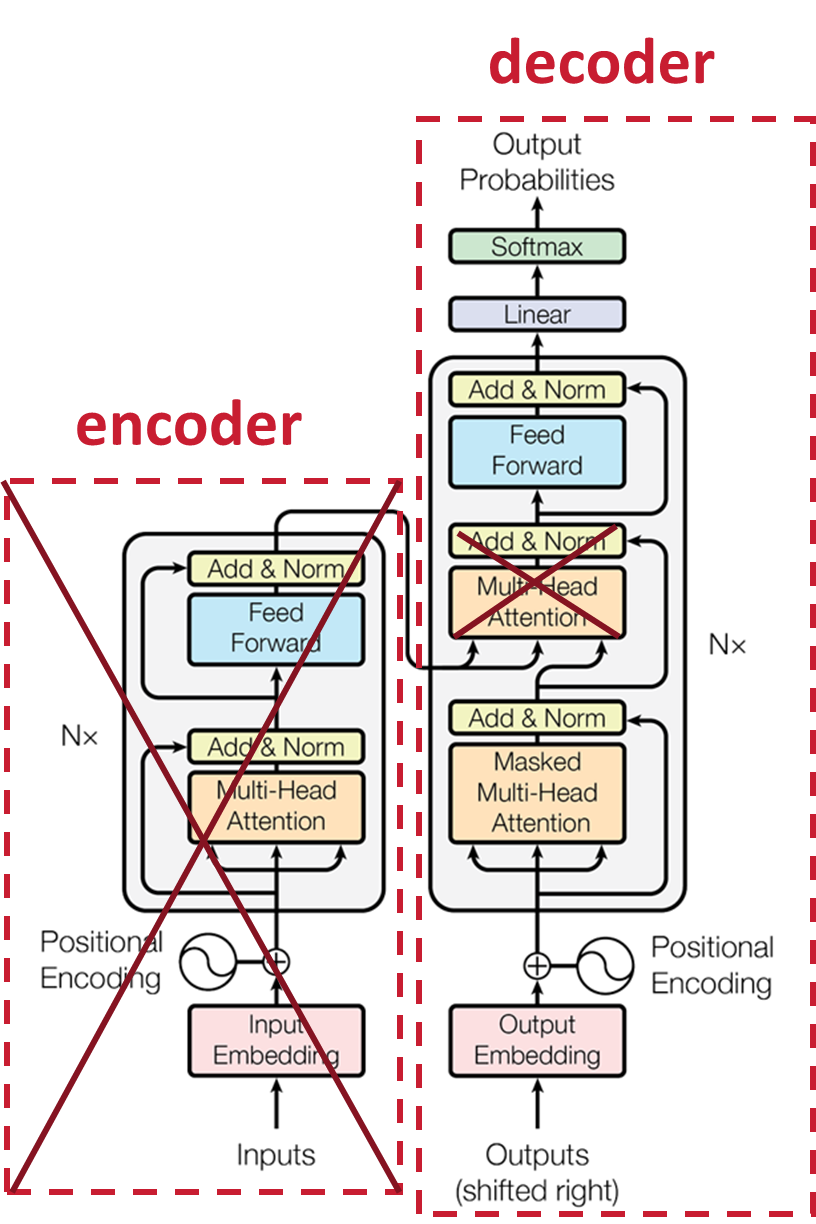
GPT-2对比Transformer,去掉了Encoder部分,同时去掉了交叉注意力。

Layer normalization层归一化被移动到每个子块的输入中,类似于预激活残 差网络(1),并在最后一个自注意力块之后添加了一个额外的层归一化(2)。使用修改 后的初始化,该初始化考虑了模型深度上的残差路径的累积。我们在初始化时将残差 层的权重乘以1/N,其中 N 是残差层的数量(3)。
(1):在传统的残差网络中,层归一化通常放在残差块的输出处。而在 GPT-2 中,层归一化被移到了每个子块的输入处,类似于预激活残差网络(Pre-activation Residual Network)的做法。
(2):在最后一个自注意力块(Self-Attention Block)之后添加了一个额外的层归一 化层。进一步增强了模型的稳定性和性能。
(3):这种缩放方法有助于平衡不同深度的残差路径上的信号,使得模型在训练初期 更加稳定,减少梯度消失和梯度爆炸的风险。
二、手写GPT-2
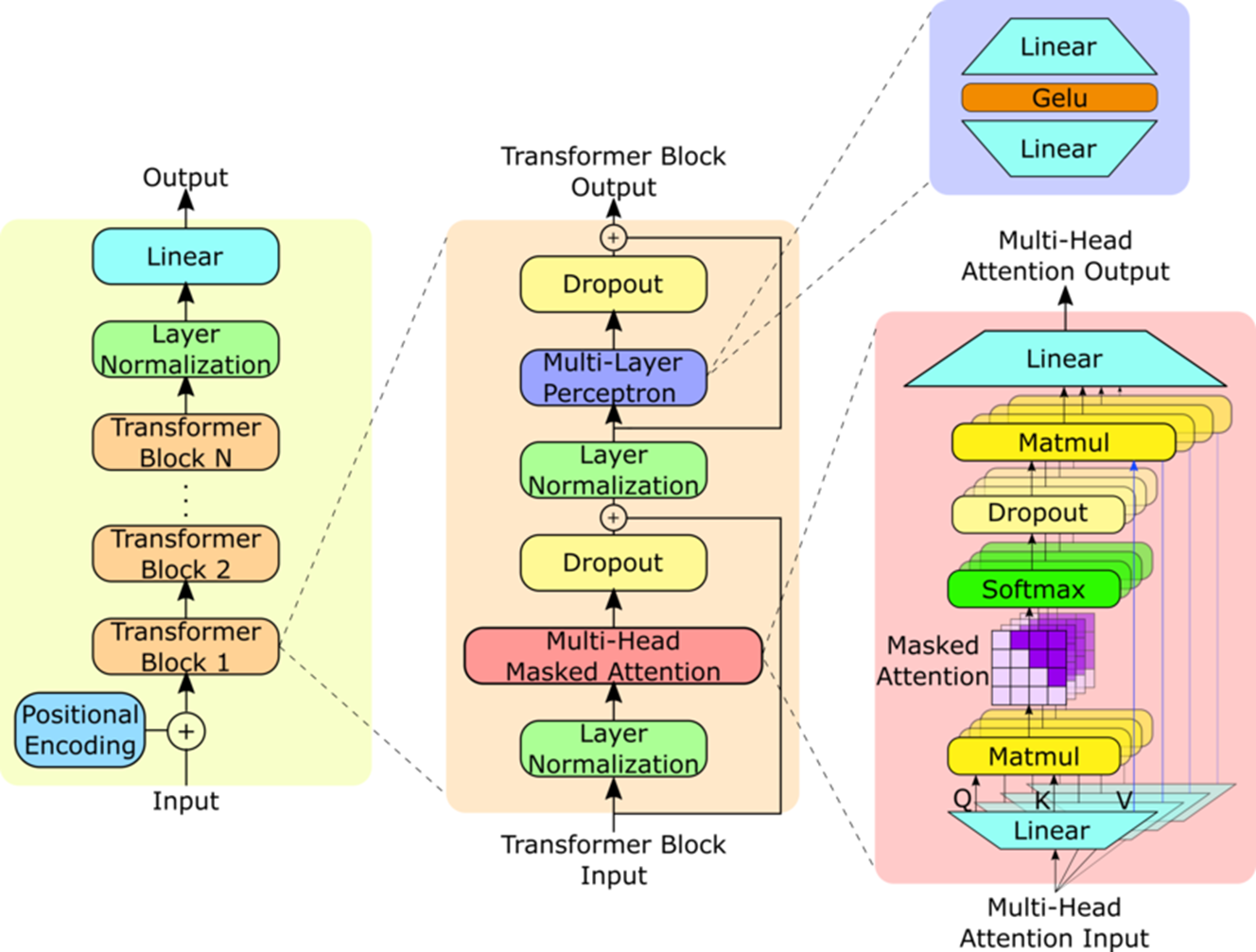
2.1、定义库函数和对应的整个网络结构信息
import torch.nn as nn
from dataclasses import dataclass
@dataclass
class GPTConfig:
block_size: int = 1024
vocab_size: int = 50257
n_layer: int = 12
n_head: int = 12
n_embd: int = 768
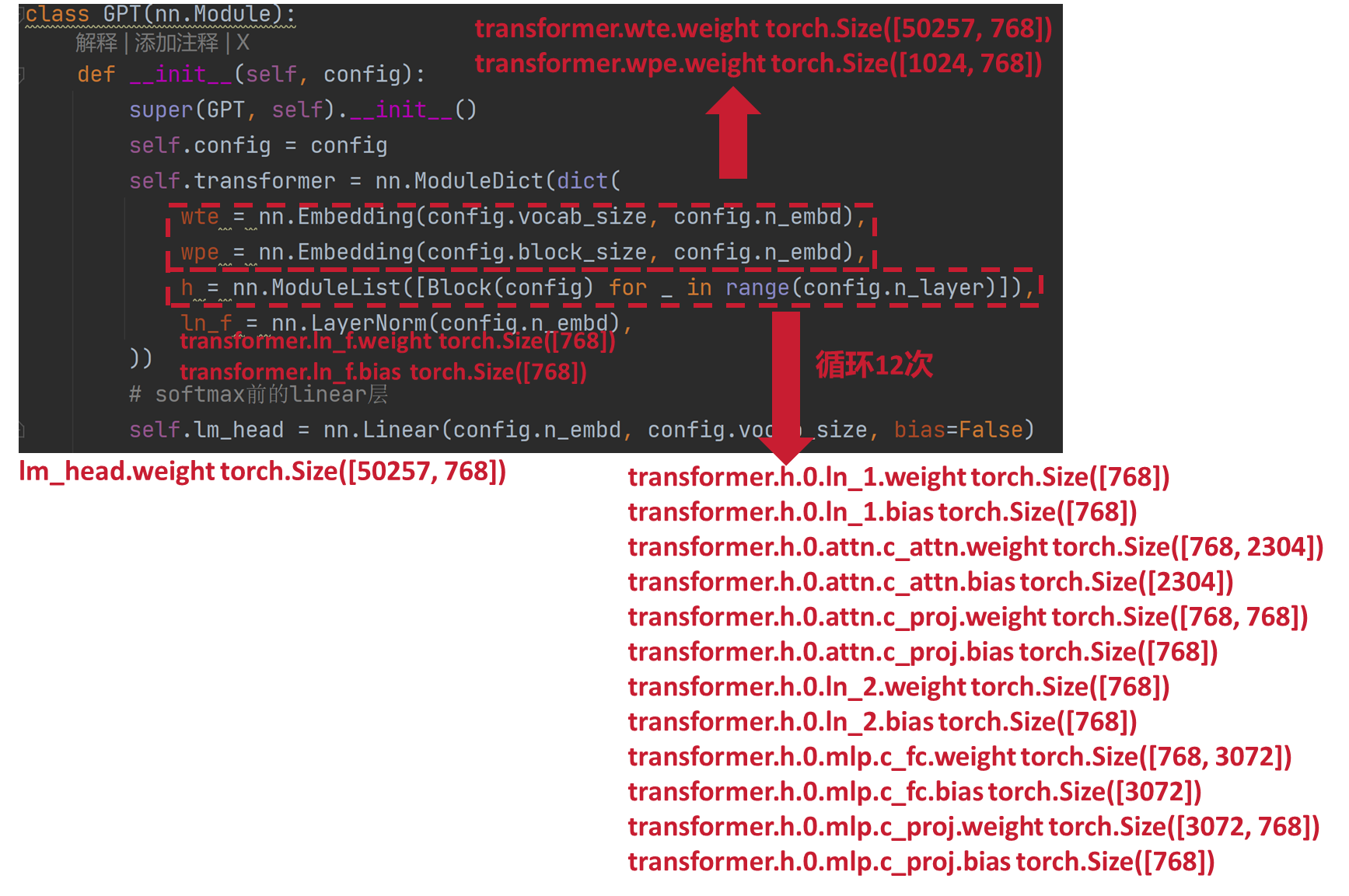
class GPT(nn.Module):
def __init__(self, config):
super(GPT, self).__init__()
self.config = config
self.transformer = nn.ModuleDict(dict(
wte = nn.Embedding(config.vocab_size, config.n_embd),
wpe = nn.Embedding(config.block_size, config.n_embd),
h = nn.ModuleList([Block(config) for _ in range(config.n_layer)]),
ln_f = nn.LayerNorm(config.n_embd),
))
# softmax前的linear层
self.lm_head = nn.Linear(config.n_embd, config.vocab_size, bias=False)
 2.2、Block
2.2、Block
class Block(nn.Module):
def __init__(self, config):
super(Block, self).__init__()
# 初始化LayerNorm层
self.ln_1 = nn.LayerNorm(config.n_embd)
# 初始化自注意力层
self.attn = CausalSelfAttention(config)
# 初始化LayerNorm层
self.ln_2 = nn.LayerNorm(config.n_embd)
# 初始化MLP层
self.mlp = MLP(config)
def forward(self, x):
# 将输入x通过自注意力层,并加上原始输入x
x = x + self.attn(self.ln_1(x))
# 将输入x通过MLP层,并加上原始输入x
x = x + self.mlp(self.ln_2(x))
# 返回结果
return xAttention是reduce,MLP是MAP。
2.3、定义MLP块
在 Transformer 的 MLP(Multi-Layer Perceptron,通常是两个线性层加一个激活 函数)部分,对每个输入向量单独进行映射操作。MLP 逐个处理输入的每个特征 (或每个向量),进行非线性变换,而不改变其维度或位置。MLP 的这种操作类似 于“映射”功能,将输入映射到新的特征空间中去。
Attentionis Reduce:Attention 机制通过计算注意力分数并将 Value 向量进行 加权求和,将多个输入向量整合成一个新的向量,这是一个 Reduce 操作。
MLP is Map:MLP 通过全连接网络对每个输入向量进行独立的非线性变换,输 出与输入具有相同的维度,这是一个 Map 操作。
class MLP(nn.Module):
def __init__(self, config):
super(MLP, self).__init__()
self.c_fc = nn.Linear(config.n_embd, 4 * config.n_embd)
self.gelu = nn.GELU(approximate="tanh")
self.c_proj = nn.Linear(4 * config.n_embd, config.n_embd)
def forward(self, x):
x = self.c_fc(x)
x = self.gelu(x)
x = self.c_proj(x)
return x
2.4、定义CausalSelfAttention
Python----循环神经网络(Transformer ----Attention中的mask)
在 Transformer 的 Attention 机制中,特别是 Self-Attention,通过加权求和的方式 将来自不同位置的信息汇聚到一个新的表示上。也就是说,Attention 对输入序列的 信息进行了某种“聚合”操作,将分散的信息进行加权平均。因此,Attention 过程类 似于 Reduce 操作,将多个输入(所有词的向量表示)“简化”为一个新的向量表示。
Query, Key, Value:在多头自注意力机制中,输入向量被投影成 Query (Q)、 Key (K) 和 Value (V) 向量。
Attention Scores:计算 Query 和 Key 之间的点积,得到注意力分数 (Attention Scores),这些分数反映了不同位置的词之间的相关性。
Weighted Sum:根据注意力分数对 Value 向量进行加权求和,得到一个新的向 量。这个新的向量可以看作是输入向量的加权平均,因此是一个 Reduce 操作。
class CausalSelfAttention(nn.Module):
def __init__(self, config):
super(CausalSelfAttention, self).__init__()
# 确保嵌入维度可以被注意力头整除
assert config.n_embd % config.n_head == 0
self.c_attn = nn.Linear(config.n_embd, 3 * config.n_embd)
self.c_proj = nn.Linear(config.n_embd, config.n_embd)
self.n_head = config.n_head
self.n_embd = config.n_embd
# 做一个mask
self.register_buffer("bias", torch.tril(torch.ones(config.block_size, config.block_size))
.view(1, 1, config.block_size, config.block_size))
def forward(self, x):
# bs, seq_len, embd
B, T, C = x.size()
qkv = self.c_attn(x)
q, k, v = qkv.split(self.n_embd, dim=2)
q = q.view(B, T, self.n_head, C // self.n_head).transpose(1, 2)
k = k.view(B, T, self.n_head, C // self.n_head).transpose(1, 2)
v = v.view(B, T, self.n_head, C // self.n_head).transpose(1, 2)
att = (q @ k.transpose(-2, -1)) * (1.0 / math.sqrt(k.size(-1)))
att = att.masked_fill(self.bias[:, :, :T, :T] == 0 , float("-inf"))
att = F.softmax(att, dim=-1)
y = att @ v # (B, nh, T, T) X (B, nh, T, hs) -> (B, nh, T, hs)
y = y.transpose(1, 2).contiguous().view(B, T, C)
y = self.c_proj(y)
return y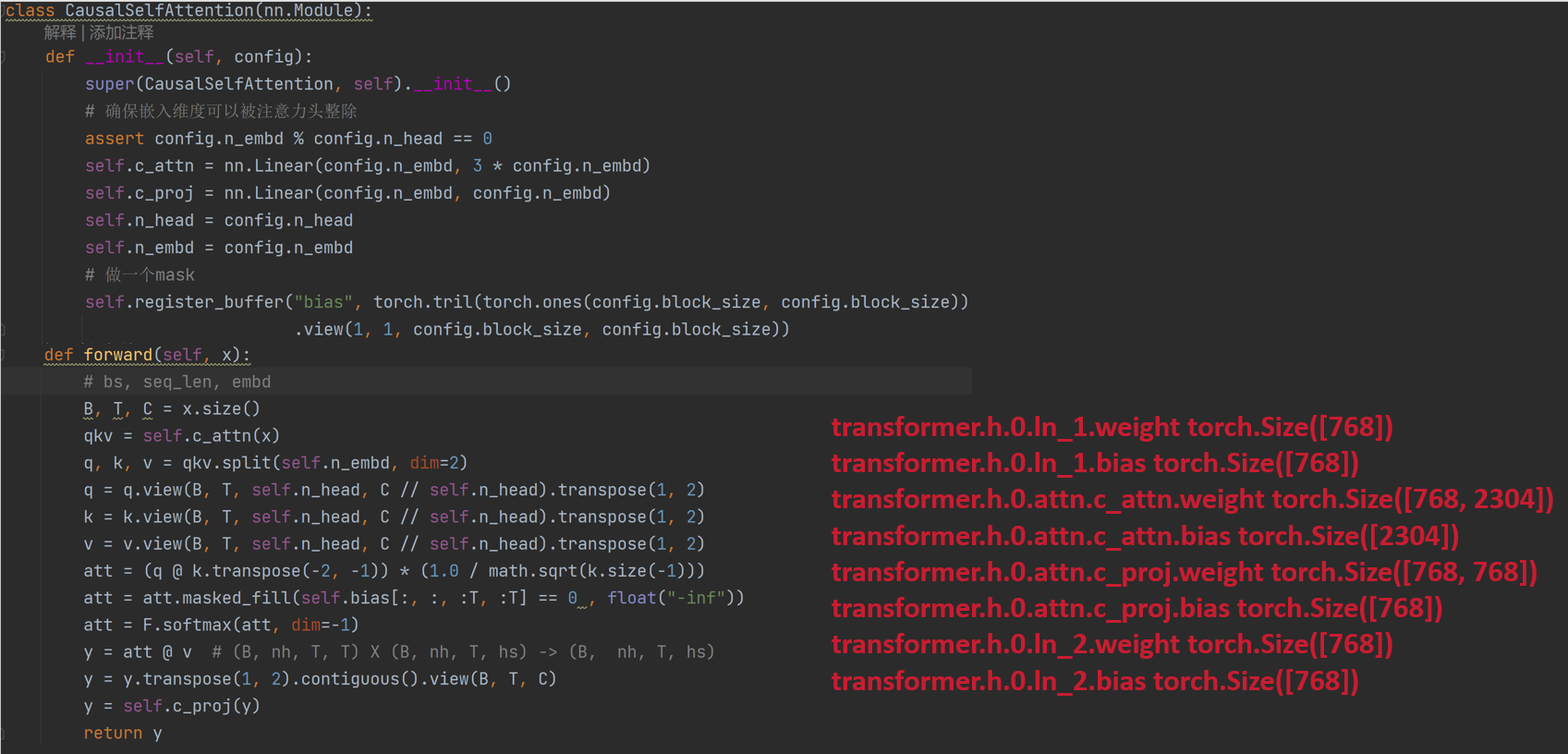
2.5、forward
def forward(self, idx):
B, T = idx.size()
assert T <= self.config.block_size, f"不能让seq_len {T} 大于 block_size {self.config.block_size}"
pos = torch.arange(0, T, dtype=torch.long, device=idx.device)
pos_emb = self.transformer.wpe(pos) # (T, n_embd)
tok_emb = self.transformer.wte(idx) # (B, T, n_embd)
x = pos_emb + tok_emb
for block in self.transformer.h:
x = block(x)
x = self.transformer.ln_f(x)
logits = self.lm_head(x) # (B, T, vocab_size)
return logits2.6、from_pretrained
@classmethod
def from_pretrained(cls, model_type):
assert model_type in {"gpt2", "gpt2-medium", "gpt2-large", "gpt2-xl"}
from transformers import GPT2LMHeadModel
print("从预训练的GPT中加载模型:", model_type)
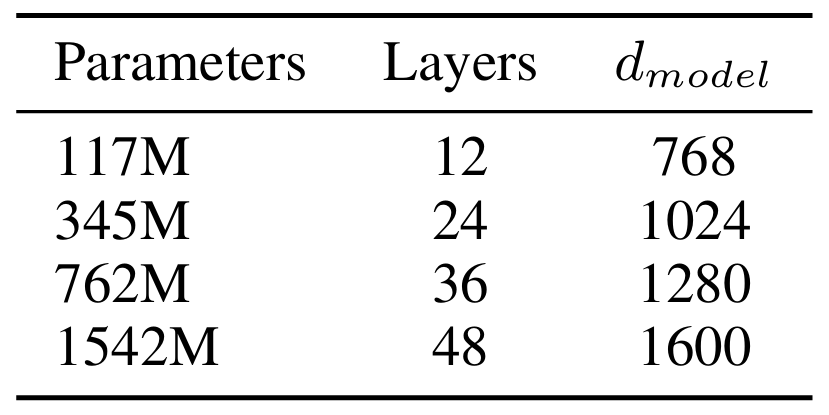
# 根据模型类型确认参数
config_args = {
"gpt2": dict(n_layer=12, n_head=12, n_embd=768), # 124M param
"gpt2-medium": dict(n_layer=24, n_head=16, n_embd=1024), # 350M param
"gpt2-large": dict(n_layer=36, n_head=20, n_embd=1280), # 774M param
"gpt2-xl": dict(n_layer=48, n_head=25, n_embd=1600), # 1558M param
}[model_type]
config_args["vocab_size"] = 50257
config_args["block_size"] = 1024
# 创建GPT模型
config = GPTConfig(**config_args)
model = GPT(config)
sd = model.state_dict()
sd_keys = sd.keys()
sd_keys = [k for k in sd_keys if not k.endswith(".attn.bias")]
# 从huggingface/transformers模型中初始化
model_hf = GPT2LMHeadModel.from_pretrained(model_type)
sd_hf = model_hf.state_dict()
# 将参数逐一对齐并复制
sd_keys_hf = sd_hf.keys()
sd_keys_hf = [k for k in sd_keys_hf if not k.endswith(".attn.masked_bias")]
sd_keys_hf = [k for k in sd_keys_hf if not k.endswith(".attn.bias")]
transposed = ["attn.c_attn.weight", "attn.c_proj.weight", "mlp.c_fc.weight", "mlp.c_proj.weight"]
assert len(sd_keys_hf) == len(sd_keys), f"键不匹配, {len(sd_keys_hf)} != {len(sd_keys)}"
for k in sd_keys_hf:
# openai使用了一个叫conv1d的模型,功能与linear一致,我们使用linear,需要单独处理它。需要转置
if any(k.endswith(w) for w in transposed):
assert sd_hf[k].shape[::-1] == sd[k].shape
with torch.no_grad():
sd[k].copy_(sd_hf[k].t())
else: # 其余的直接复制
assert sd_hf[k].shape == sd[k].shape
with torch.no_grad():
sd[k].copy_(sd_hf[k])
return model三、模型训练
3.1、初始化模型
device='cuda' if torch.cuda.is_available() else 'cpu'
model = GPT(GPTConfig()).to(device)3.2、数据集
# 加载数据集并制作数据集
import tiktoken
enc = tiktoken.get_encoding("gpt2") # 获取 GPT-2 编码器
with open('shakespeare.txt','r') as f: # 读取莎士比亚文本文档(这里只取前 1000 个字符用于演示)
text = f.read()
text = text[:1000]
tokens = enc.encode(text) # 使用编码器将文本转换为 token 列表
B, T = 4, 32 # 设置批次大小 (B) 和序列长度 (T)
# 创建一个包含 B*T + 1 个 token 的张量
# 之所以是 B*T + 1,是为了创建目标序列 y,它比输入序列 x 多一个 token
buf = torch.tensor(tokens[:B*T +1])
# 创建输入序列 x
# buf[:-1] 切片操作选取 buf 中除了最后一个元素之外的所有元素
# view(B, T) 将切片后的张量重塑为 (B, T) 的形状
x = buf[:-1].view(B, T).to(device)
# 创建目标序列 y
# buf[1:] 切片操作选取 buf 中从第二个元素(索引为 1)到最后一个元素的所有元素
# view(B, T) 将切片后的张量重塑为 (B, T) 的形状
y = buf[1:].view(B, T).to(device)3.3、优化器
# AdamW 是对 Adam 的一个改进,主要解决了 Adam 在应用权重衰减(weight decay)时存在的问题。
optimizer = torch.optim.AdamW(model.parameters(), lr=3e-4)3.4、模型训练
model.train()
# 训练模型
for i in range(50):
optimizer.zero_grad()
logits,loss = model(x, y)
loss.backward()
optimizer.step()
print(f"step {i},loss:{loss.item()}")
















 2059
2059

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









