









一、PyTorch
1.1、概述
PyTorch 是一个开源的深度学习框架,由 Meta(原名 Facebook)的人工智能研究团队开发和维护。自 2017 年 1 月发布以来,PyTorch 在深度学习社区中的关注度不断上升,尤其是在推出 1.0 版本后,新增了许多功能并优化了原有内容,还整合了 Caffe2,使得使用更加便捷,极大增强了其生产性。
PyTorch 采用 Python 语言接口,易于上手,类似于带有 GPU 支持的 NumPy。作为一个动态框架,PyTorch 继承了 Torch 的灵活性和用户友好的界面,支持快速和灵活地构建动态神经网络。它允许在训练过程中快速修改代码而不影响性能,支持动态图形等尖端 AI 模型的能力,因此成为快速实验的理想选择。
PyTorch 是一个建立在Torch库之上的Python包,旨在加速深度学习应用。它提供一 种类似Numpy的抽象方法来表征张量(或多维数组),可以利用GPU来加速训练。由于 PyTorch 采用了动态计算图(Dynamic Computational Graph)结构,且基于 tape 的 Autograd 系统的深度神经网络。其他很多框架,比如TensorFlow(TensorFlow2.0也加 入了动态网络的支持)、Caffe、CNTK、Theano等,采用静态计算图。使用PyTorch,通 过一种称为Reverse-modeauto-differentiation(反向模型自动微分)的技术,可以零延 迟或零成本地任意改变你的网络的行为。
Torch 是 PyTorch 中的一个重要包,它包含了多维张量的数据结构以及基于其上的多 种数学操作。 自2015年谷歌开源TensorFlow以来,深度学习框架之争越来越激烈,全球多个看重 AI 研究与应用的科技巨头均在加大这方面的投入。PyTorch从2017年年初发布以来,可 谓是异军突起,短时间内取得了一系列成果,成为明星框架。
1.2、组成
PyTorch 由 4个主要的包组成:
torch:类似于Numpy的通用数组库,可将张量类型转换为torch.cuda.TensorFloat, 并在GPU上进行计算。
torch.autograd:用于构建计算图像并自动获取梯度的包。
torch.nn:具有共享层和损失函数的神经网络库。
torch.optim:具有通用优化算法(如SGD、Adam等)的优化包。
1.3、特点
动态计算图:
PyTorch 使用动态计算图,这意味着计算图是在运行时构建的,而不是在编 译时静态定义的。
自动求导(微分):
PyTorch 提供了自动求导机制,称为 Autograd。它能够自动计算张量的梯 度,这对于训练神经网络和其他深度学习模型非常有用。
丰富的神经网络库:
PyTorch 提供了丰富的神经网络库,包括各种各样的层、损失函数、优化器 等。这些库使得构建和训练神经网络变得更加容易。
支持GPU加速:
PyTorch 充分利用了 GPU 的并行计算能力,能够在 GPU 上高效地进行计 算,加速模型训练过程。
1.4、安装
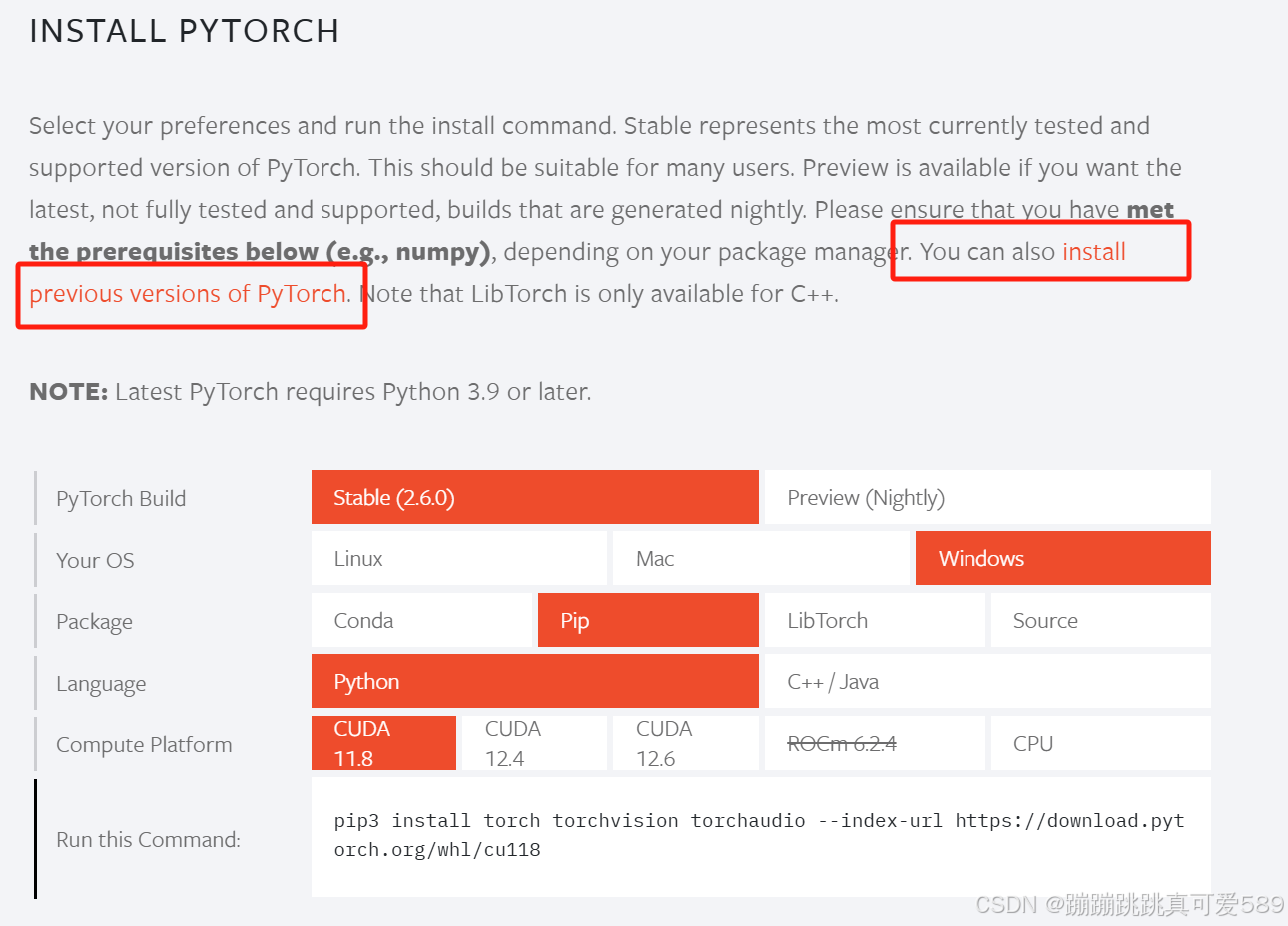
安装PyTorch时,请检查当前环境是否有GPU,如果没有,则安装CPU版;如果有, 则安装GPU版本的。安装PyTorch比较简单,由于PyTorch是基于Python开发,所以如 果没有安装Python需要先安装,然后再安装PyTorch。
官网地址:PyTorch
# conda
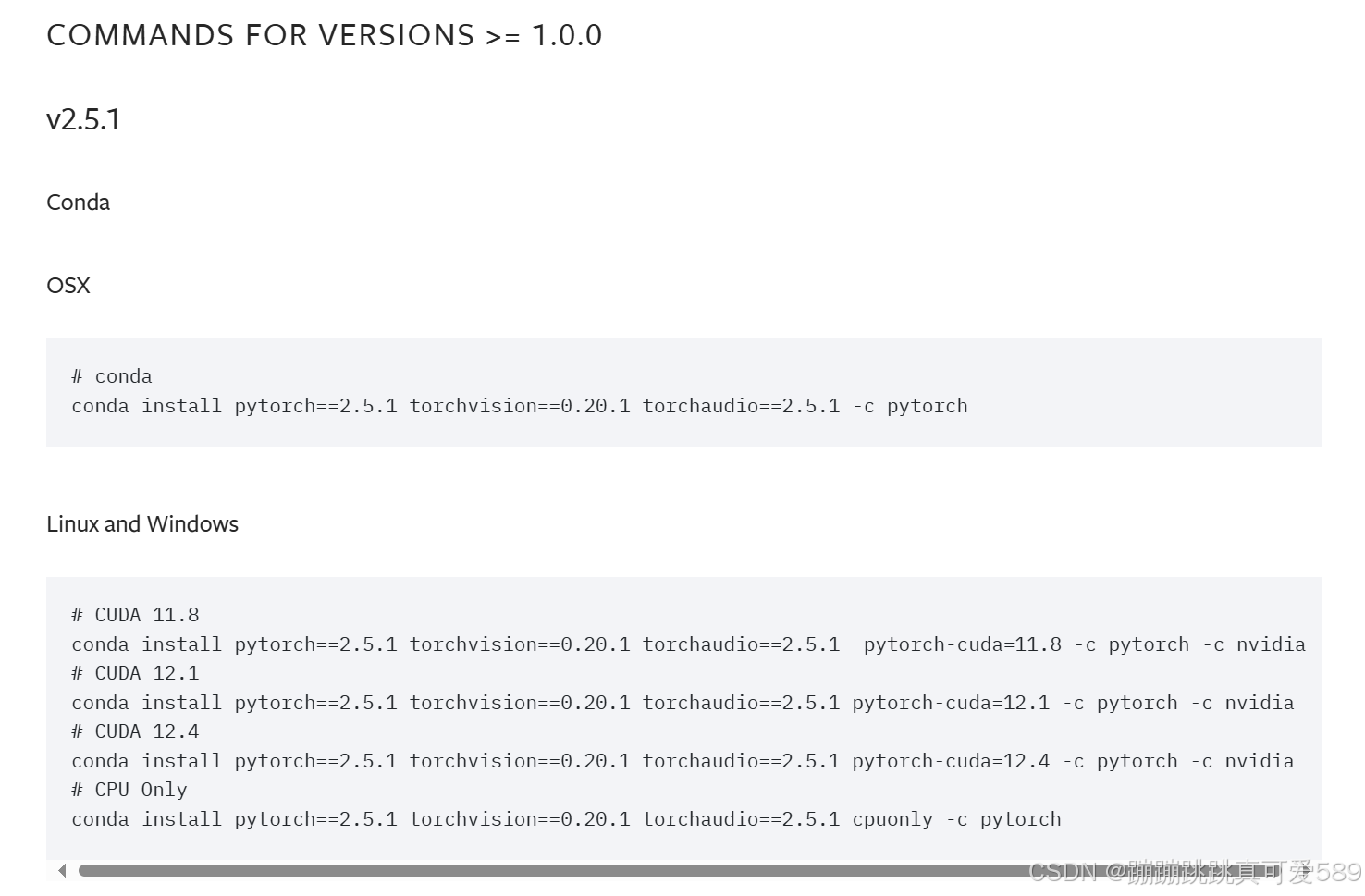
conda install pytorch==2.5.1 torchvision==0.20.1 torchaudio==2.5.1 -c pytorch# CUDA 11.8
conda install pytorch==2.5.1 torchvision==0.20.1 torchaudio==2.5.1 pytorch-cuda=11.8 -c pytorch -c nvidia
# CUDA 12.1
conda install pytorch==2.5.1 torchvision==0.20.1 torchaudio==2.5.1 pytorch-cuda=12.1 -c pytorch -c nvidia
# CUDA 12.4
conda install pytorch==2.5.1 torchvision==0.20.1 torchaudio==2.5.1 pytorch-cuda=12.4 -c pytorch -c nvidia
# CPU Only
conda install pytorch==2.5.1 torchvision==0.20.1 torchaudio==2.5.1 cpuonly -c pytorch安装:
pip install torch torchvision torchaudio -i https://pypi.tuna.tsinghua.edu.cn/simple/
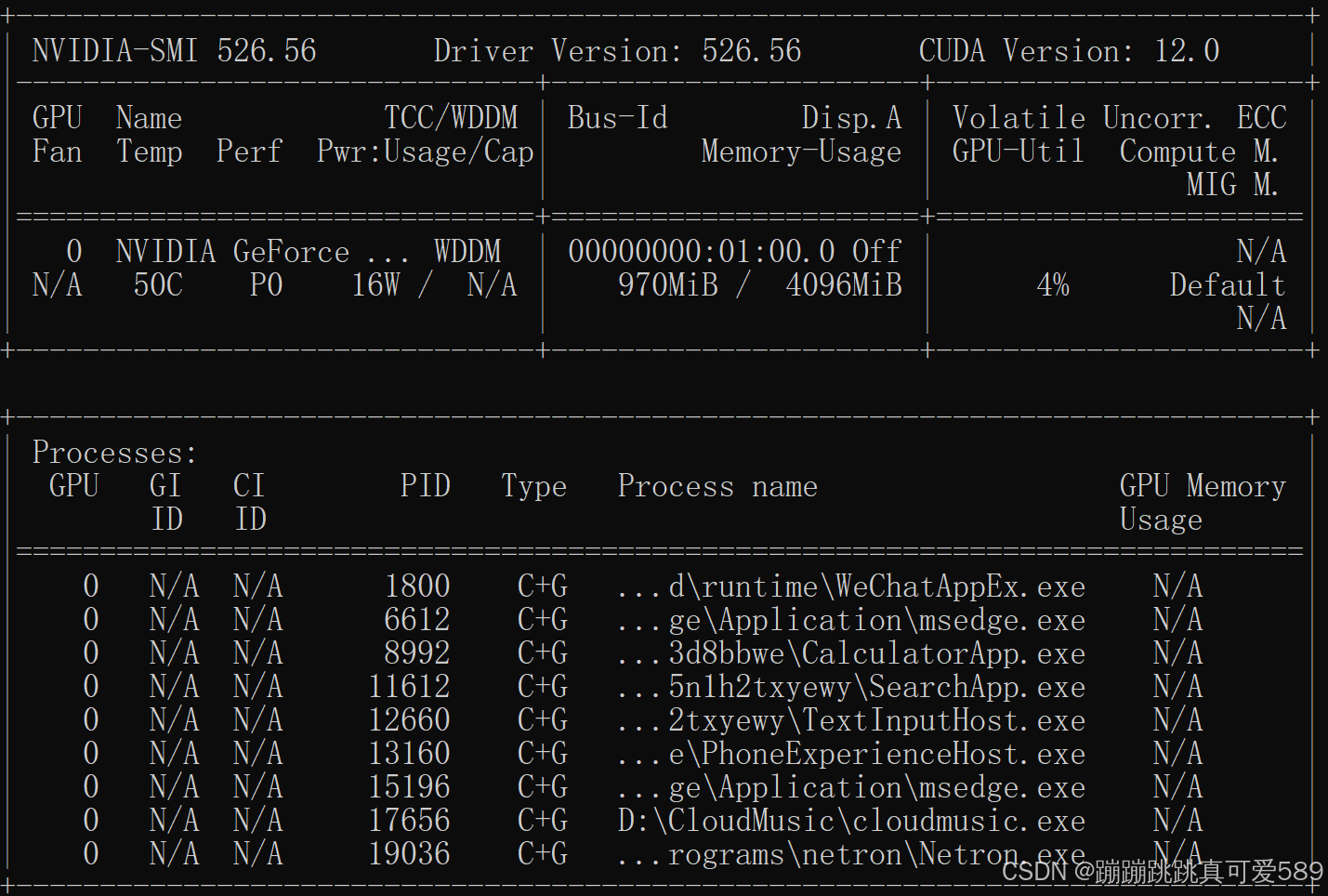
1.5、 验证是否在使用GPU
在命令行运行:nvidia-smi,可以看到下面界面:
import torch
print(torch.__version__)
print("CUDA Available: ", torch.cuda.is_available())二、tensor是什么
PyTorch的Tensor,它可以是零维 (又称为标量或一个数)、一维、二维及多维的数组。Tensor自称为神经网络界的Numpy, 它与Numpy相似,二者可以共享内存,且之间的转换非常方便和高效。不过它们也有不同 之处,最大的区别就是Numpy会把ndarray放在CPU中进行加速运算,而由Torch产生 的Tensor 会放在GPU中进行加速运算(如果当前环境由GPU)。
对Tensor 的操作很多,从接口的角度来划分,可以分为两类:
1) torch.function,如 torch.sum、torch.add 等;
2) tensor.function,如 tensor.view、tensor.add 等。
这些操作对大部分Tensor都是等价的,如torch.add(x,y)与x.add(y)等价。在实际使 用时,可以根据个人爱好选择。
如果从修改方式的角度来划分,可以分为以下两类:
1) 不修改自身数据,如x.add(y),x的数据不变,返回一个新的Tensor。
2) 修改自身数据,如x.add_(y),运行符带下划线后缀,运行结果存在x中,x被修改。
import torch
x=torch.tensor([1,2])
y=torch.tensor([3,4])
z=x.add(y)
print(z)#tensor([4, 6])
x.add_(y)
print(x)#tensor([4, 6])三、tensor的存储机制
在 PyTorch 中,tensor 包含了两个部分,即 storage 和 metadata。 Storage(存储):存储是 tensor 中包含的实际数据的底层缓冲区, 它是一维数组,存储了 tensor 的元素值。不同 tensor 可能共享相 同的存储,即使它们具有不同的形状和步幅。存储是一块连续的内 存区域,实际上存储了 tensor 中的数据。
Metadata(元数据):元数据是 tensor 的描述性信息,包括 tensor 的形状、数据类型、步幅、存储偏移量、设备等。元数据提 供了关于 tensor 的结构和属性的信息,但并不包含 tensor 中的实 际数据。元数据允许 PyTorch 知道如何正确地解释存储中的数据以 及如何访问它们。
数据类型

进制转换
0011101000000000的float16的二进制是多少十进制
需要遵循 IEEE 754 半精度浮点数的标准。
首先,我们需要了解float16格式的结构:在float16中,符号位占1位,指数部分占5位,小数部分(即尾数)占10位。
对于给出的float16值:0011101000000000
符号位:0(表示这是一个正数)
指数部分:01110(二进制),转换为十进制是23+22+21=8+4+2=14
小数部分(尾数):1000000000(二进制)
接下来,将指数部分转换为实际的指数值。在float16中,指数的偏移量是15,因为最大为25−1−1= 15,所以实际的指数是14-15=-1。
尾数部分需要加上隐含的前导1(因为在规格化的浮点数中,前导的1是隐含的),先将小数部分转成 十进制:2−1 =0.5,加上前导1,所以实际尾数得到1.5。
最终计算方法:2**1/2×1.5=0.75。
存储与共享

import torch
tensorA = torch.tensor([[0, 1, 2, 3],
[4, 5, 6, 7],
[8, 9, 10, 11]])
tensorB = tensorA.T
print(tensorA)
print("tensorA存储:", tensorA.storage().tolist())
print('*******************************************************')
print(tensorB)
print("tensorB存储:", tensorB.storage().tolist())
'''
tensor([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
tensorA存储: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
*******************************************************
tensor([[ 0, 4, 8],
[ 1, 5, 9],
[ 2, 6, 10],
[ 3, 7, 11]])
tensorB存储: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
'''具体过程
在PyTorch中,张量的存储是通过torch.Storage类来管理的。张量的值被分配在连续的内存块中,这些内存块是大小可变的一维数组,可以包含不同类型的数据,如float 或int32。
具体来说,当我们创建一个张量时,PyTorch会根据我们提供的数据和指定的数据类型来分配一块连续的内存空间。这块内存空间由torch.Storage对象管理,而张量本身则提供了一种视图,让我们可以通过多维索引来访问这些数据。
此外,PyTorch还提供了一系列的函数和方法来操作张量,包括改变形状、获取元素、拼接和拆分等。这些操作通常不会改变底层的存储,而是返回一个新的张量视图,这个视图指向相同的数据但可能有不同的形状或索引方式。
总的来说,张量的存储实现是PyTorch能够高效进行张量运算的关键。通过管理一块连续的内存空间,并提供了丰富的操作方法,使得用户可以方便地对多维数组进行各种计算和变换。
四、tensor的连续性
连续性指的是其元素在内存中按照其在张量中的顺序紧密存储,没有间隔或间隔是连续的。
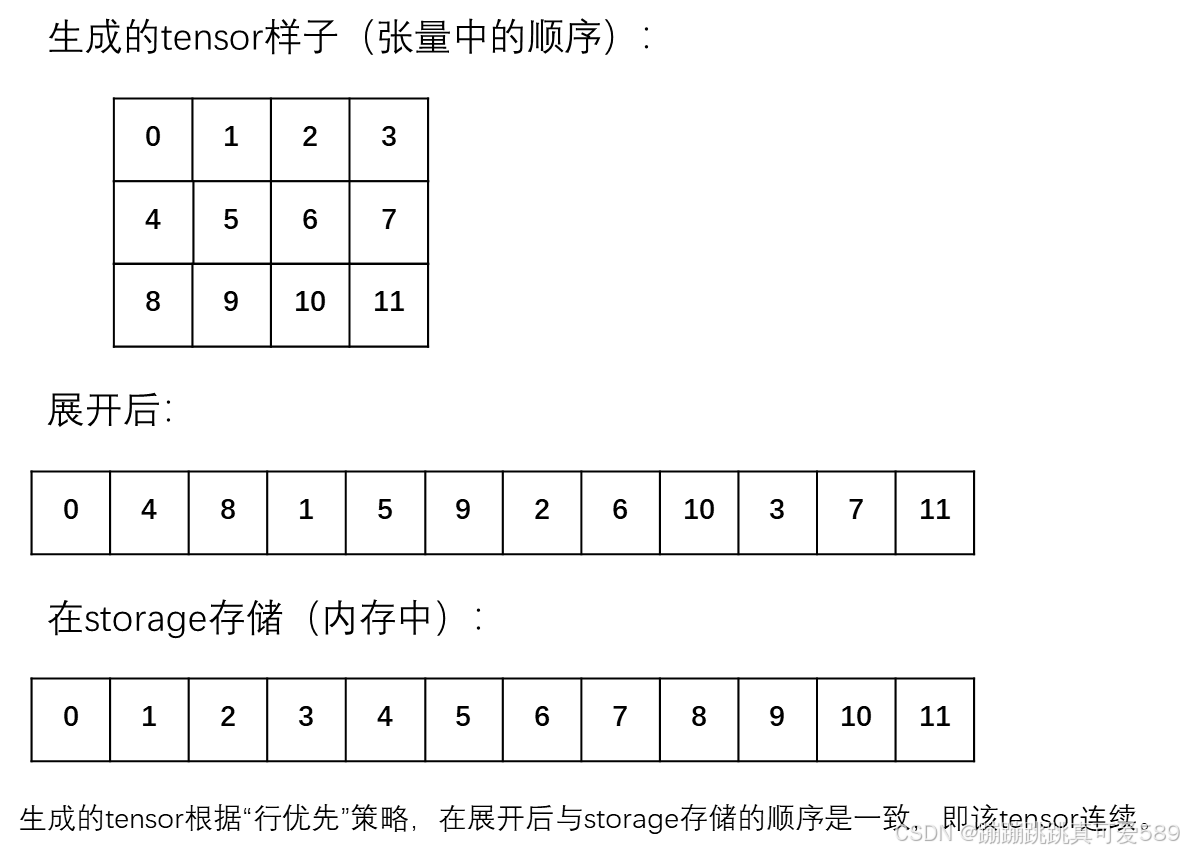
a=torch.arange(12).reshape(3,4)
b=a.transpose(0,1)
print(b)
'''
tensor([[ 0, 4, 8],
[ 1, 5, 9],
[ 2, 6, 10],
[ 3, 7, 11]])
'''
print(b.flatten())
#tensor([ 0, 4, 8, 1, 5, 9, 2, 6, 10, 3, 7, 11])
print(b.storage().tolist())
#[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]不连续的缺点与解决方案
当对Tensor进行某些操作,如转置(transpose)时,可能会导致Tensor变得不连续。
连续的tensor优势:
高效的内存访问:连续的张量在内存中占用一块连续的空间,这使得CPU可以高效地按顺序访问数据,减少了内存寻址的时间,从而提高了数据处理的速度。
优化的计算性能:在进行数学运算时,连续张量可以减少数据的移动和复制,因为数据已经按照计算所需的顺序排列,这样可以减少计算中的延迟,提高整体的计算性能。
其它:在不连续的tensor上进行view()操作会报错。
解决方案:
通过contiguous()方法将不连续的张量转换为连续的张量。
如果tensor不是连续的,则会重新开辟一块内存空间保证数据是在内存中是连续的。
如果Tensor 是连续的,则contiguous()无操作。

















 1548
1548

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









