







1. 什么是索引?
-
索引(Index)是数据库用于 加速查询 的数据结构。它类似于 书的目录,可以提高数据检索效率,但会占用额外的存储空间,并增加 insert、update、delete的成本。
2. 理解mysql中的Buffer Pool和page:
-
mysql服务器在内存中运行时,会自动申请默认128MB的空间(可以修改),这块空间被称为Buffer Pool,用来进行各种缓存,来和磁盘进行IO交互。
-
Buffer Pool由page组成,page是 InnoDB 存储引擎用于管理数据的基本单位。page有多种类型,比如:数据页(存储表中实际数据行)、索引页(存储索引节点)、undo页(存放回滚日志)、系统页、事物页、自由页等。
-
page默认大小是16KB。所以说mysql缓冲区和内存之间交互是以16KB进行的,内存和磁盘交互的最小单位是4KB。
-
先描述,再组织,每个page就是一个结构体,Buffer Pool就是一个page组成的链表,对page的操作本质就是对链表的增删查改。
-
至于为什么page被设置为16kb,涉及到局部性原理,回顾linux中断机制。
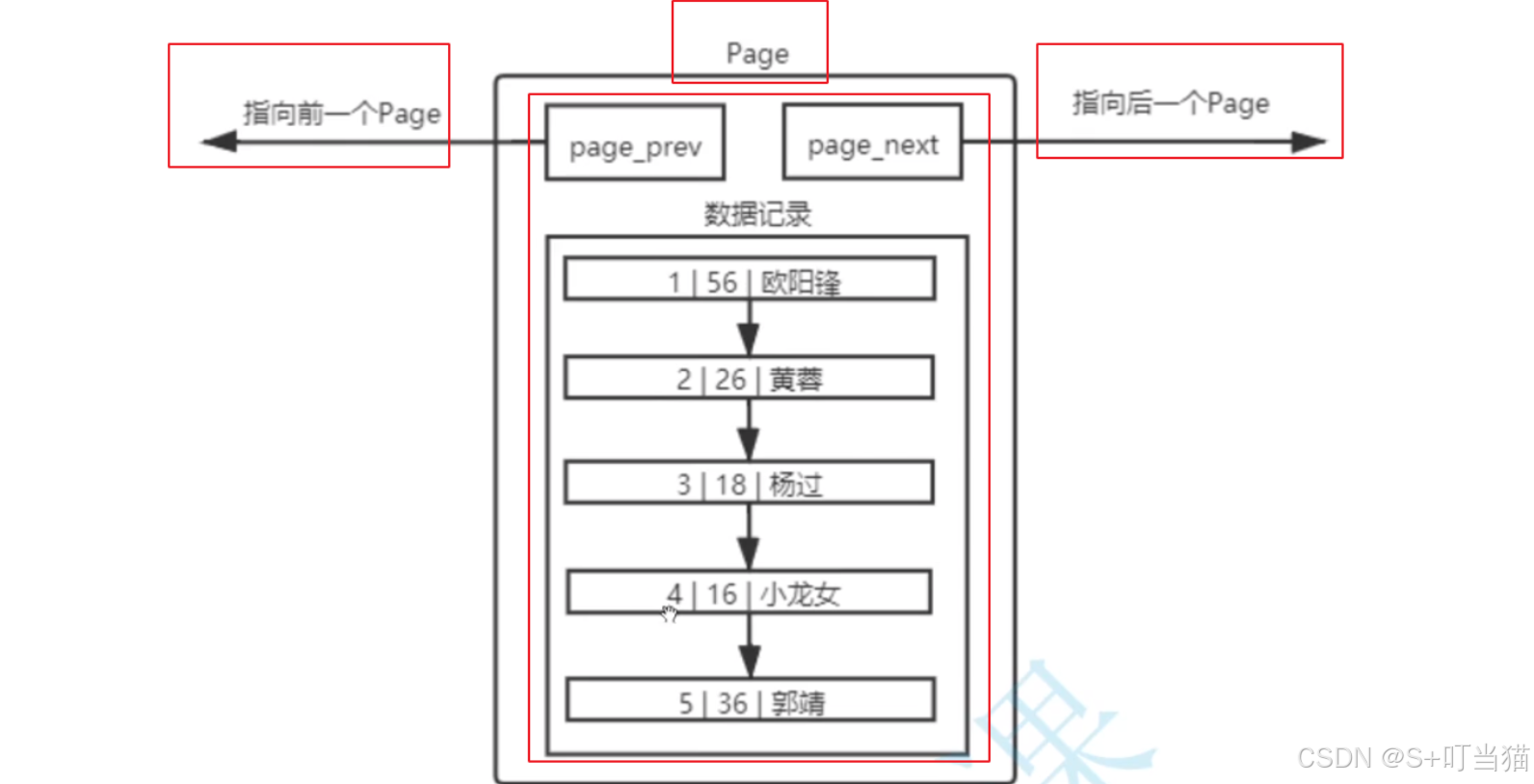
3. 主键和数据排序以及page模式能提高查找效率的原因:
-
page内部本质也是一个链表结构,链表的长处就是增删,短处是查询,所以优化查询速率是必要的。
-
InnoDB 存储引擎默认使用聚簇索引存储数据。如果表有主键,那么数据会按照主键来顺序存储。
-
在有主键的情况下,数据被顺序存储在链接起来的page中,在查询某条数据时,直接将一整页的数据加载到内存中,以减少硬盘IO次数,从而提高性能。
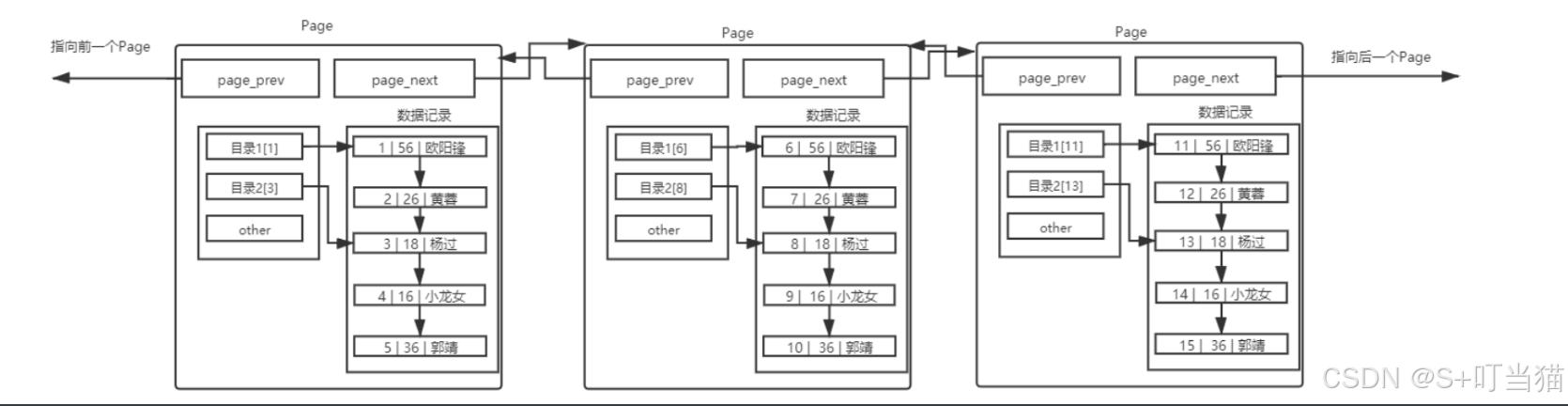
4. 什么是目录页?
-
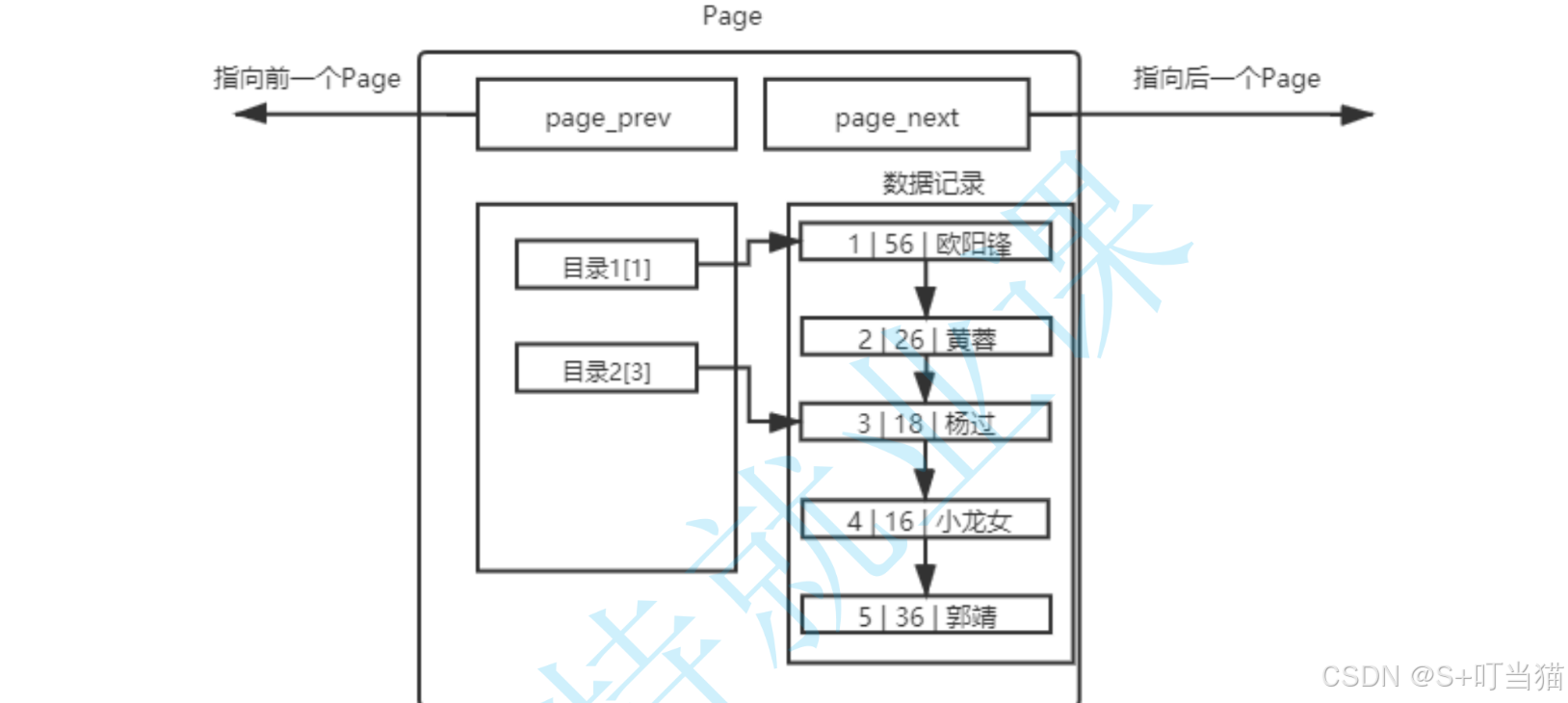
目录页只存在于数据页和索引页,目录页是page内部的一部分,他的作用就是加速页内的数据查找,防止扫描整页。
-
数据页内的记录是有序存储的,但是数据之间并非严格有序,可能是分散的,目录页记录的是页内的每条数据的偏移量,后续通过二分查找可以快速定位到指定的数据。
5. 什么是索引页?
-
要快速定位到某一条数据,就需要先快速定位到该条数据所在的page,要快速定位到所在page,就需要通过索引页。
-
索引页的每条数据就是:当页最小数据索引+page指针。
-
当需要找到某条数据时,就通过二分找到对应的page指针,再定位到该page中找数据。比如一个索引页存储了10、20、30、40、50几个索引键,如果要找第35条数据,就先通过二分找30索引键,然后通过30索引键对应的指针定位到存储30~39数据的page,再在该page中找第35条数据。
-
后续还可以通过索引页来管理索引页,相当于一层一层套娃。由此可以看出整体结构就是一个B+树。
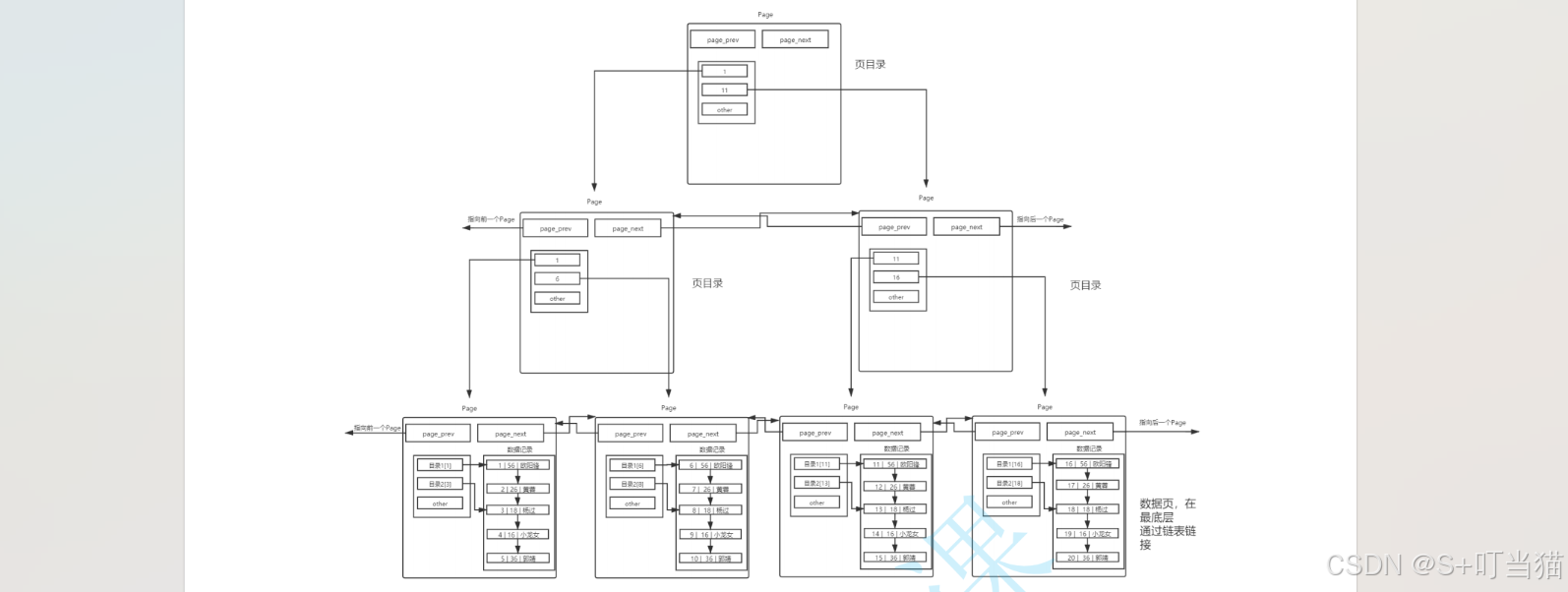
6. 叶子节点存储数据,路径节点存储目录:
-
路径节点不存储数据而是只存储目录项,这样就能够管理更多的叶子节点。
-
如此存储就使得树整体呈现矮胖型,因此路径节点就会变少,因此查找数据就需要更少的IO次数,变相提高了查询速度。
-
叶子节点使用链表进行连接是基于B+树结构,B+树结构的叶子节点本身就是使用链表链接起来的。
7. 索引操作:
-
创建主键索引、唯一键索引、普通索引都会创建一颗独立的B+树。
show index from xxx \G // 查看xxx表的索引
alter table xxx add primary key(字段1); //将字段1设置为xxx表的主键,并创建主键索引
alter table xxx drop primary key; //删除xxx表的主键,同时会删除主键索引
alter table xxx add unique(字段1); // 将字段1设置为xxx表的唯一键,并创建唯一键索引
alter table xxx add index(字段1); // 将xxx表的字段1设置为普通索引
alter table xxx drop index 索引名; // 删除唯一键索引/普通索引,索引名是Key_name,通过show index from可以查看到
create index 索引名 on xxx(字段1); // 为xxx表的字段1创建索引并且起名-
删除唯一键索引和普通索引的方法一致,
create index aaa on xxx(字段1,字段2);
//复合索引:将xxx表的字段1和字段2组合起来所谓一个索引并起名为aaa,在使用show index from xxx是可以看到字段1和字段2都有索引,但是他们两个的索引名是相同的。8. 符合索引使用场景:
-
索引最左匹配原则
-
索引覆盖
9. 索引创建原则:
-
频繁作为查询条件的字段适合添加索引。
-
唯一性过差的字段不适合单独创建索引,但是可以考虑复合索引。
-
更新频繁的字段不适合创建索引。
-
不会出现在where子句中的字段不适合创建索引。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











