






我们选择使用云服务器平台AutoDL租用实例配置微调环境:
AutoDL官网:https://www.autodl.com/home
(由于显卡经常出现GPU不足的情况,经常需要通过复制数据盘连接到其它显卡)
在使用Remote插件连接服务器的过程中经常遇到SSH无法登录的情况,解决方案如下:
输入服务器连接指令Enter后无反应:
可能是服务器没有正常关闭导致。
开VScode的 view → palette然后输入 Kill VS Code Setver on Host,再重新连接就可以了。
避免:以后使用完远程服务器关闭资源的时候要恰当的关闭,就像用完U盘要安全推出一样,使用 File → Close Remote Connection来关闭资源。
远程链接Bug解决|VScode连接远程服务器时一直要求输入密码
我们在VSCode上通过SSH-Remote插件与服务器建立连接,并部署模型:
llama-factory使用文档:
llama-factory手册
配置环境后以下命令在本地端口启动llama-Factory的可视化微调界面:
llamafactory-cli webui
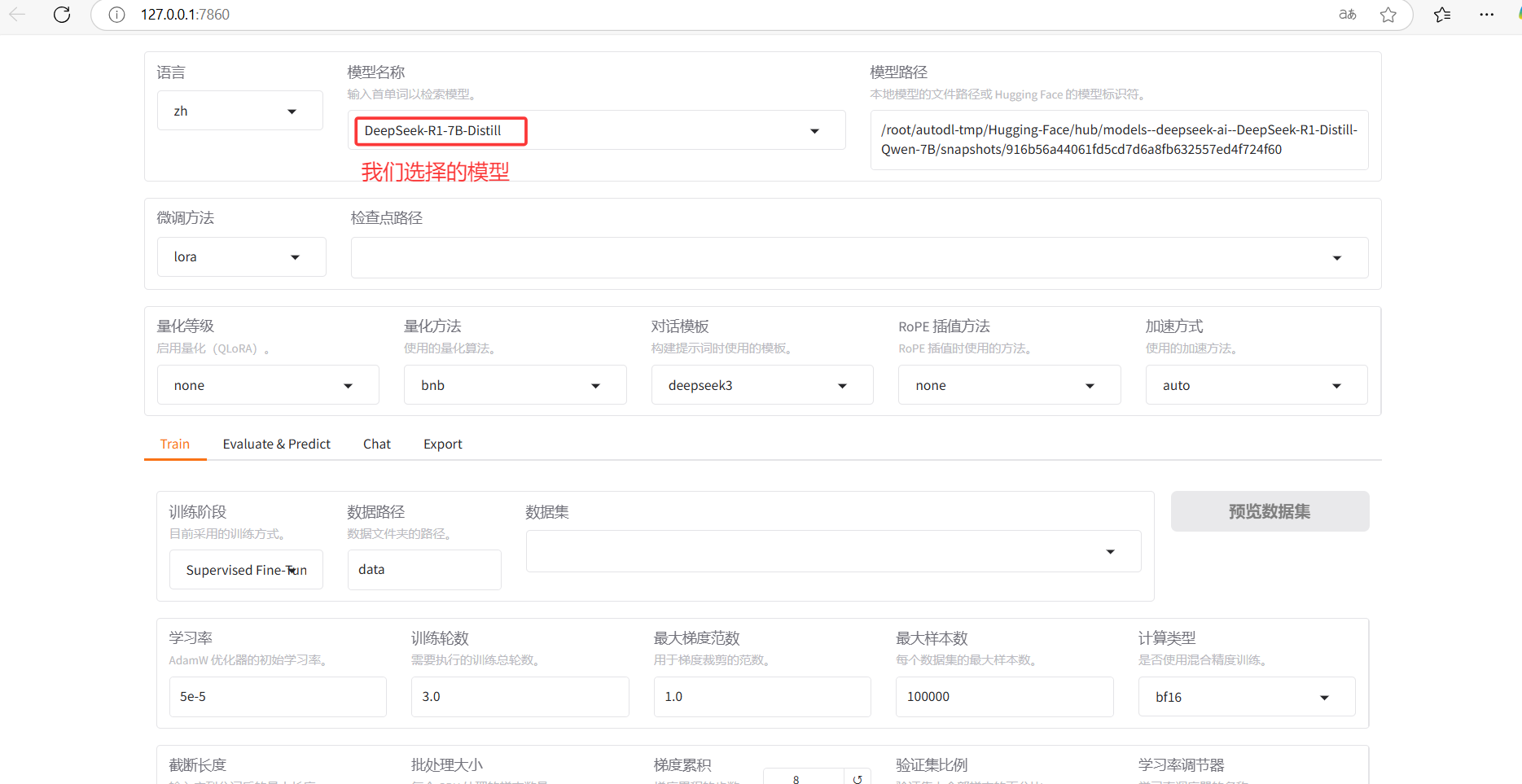
我们选择从HuggingFace下载7B蒸馏版本的deepseek大语言模型进行微调:
DeepSeek-R1-Distill-Qwen-7B
在终端修改镜像源并安装HuggingFace下载工具后通过模型名称下载本体:
**修改 HuggingFace 的镜像源
export HF_ENDPOINT=https://hf-mirror.com
**安装 HuggingFace 官⽅下载⼯具
pip install -U huggingface_hub
**执⾏下载命令
huggingface-cli download --resume-download deepseek-ai/DeepSeek-R1-Distill- Qwen-7B
训练参数:
学习率( Learning Rate):决定了模型每次更新时权重改变的幅度 。过⼤可能会错过最 优解;过⼩会学得很慢或陷⼊局部最优解
训练轮数( Epochs):太少模型会⽋拟合( 没学好),太⼤会过拟合( 学过头了)
最⼤梯度范数( Max Gradient Norm): 当梯度的值超过这个范围时会被截断,防⽌梯度爆炸现象
最⼤样本数( Max Samples):每轮训练中最多使⽤的样本数
计算类型( Computation Type):在训练时使⽤的数据类型, 常⻅的有 float32 和 float16 。在性能和精度之间找平衡;
截断⻓度(Truncation Length):处理⻓⽂本时如果太⻓超过这个阈值的部分会被截断 掉, 避免内存溢出;
批处理⼤⼩ ( Batch Size): 由于内存限制,每轮训练我们要将训练集数据分批次送进去, 这个批次⼤⼩就是 Batch Size;
梯度累积( Gradient Accumulation):默认情况下模型会在每个 batch 处理完后进⾏⼀次更新⼀个参数,但你可以通过设置这个梯度累计,让他直到处理完多个⼩批次的数据后才进⾏⼀次更新;
验证集⽐例(Validation Set Proportion):数据集分为训练集和验证集两个部分,训练集⽤来学习训练,验证集⽤来验证学习效果如何;
学习率调节器( Learning Rate Scheduler):在训练的过程中帮你⾃动调整优化学习率。
**启动训练:
llamafactory-cli train \
--stage sft \
--do_train True \
--model_name_or_path /root/autodl-tmp/Hugging-Face/hub/models--deepseek-ai--DeepSeek-R1-Distill-Qwen-7B/snapshots/916b56a44061fd5cd7d6a8fb632557ed4f724f60 \
--preprocessing_num_workers 16 \
--finetuning_type lora \
--template deepseek3 \
--flash_attn auto \
--dataset_dir data \
--dataset story \
--cutoff_len 2048 \
--learning_rate 5e-05 \
--num_train_epochs 3.0 \
--max_samples 100000 \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 8 \
--lr_scheduler_type cosine \
--max_grad_norm 1.0 \
--logging_steps 5 \
--save_steps 100 \
--warmup_steps 0 \
--packing False \
--report_to none \
--output_dir saves/DeepSeek-R1-7B-Distill/lora/train_2025-04-10-17-23-52 \
--bf16 True \
--plot_loss True \
--trust_remote_code True \
--ddp_timeout 180000000 \
--include_num_input_tokens_seen True \
--optim adamw_torch \
--lora_rank 8 \
--lora_alpha 16 \
--lora_dropout 0 \
--lora_target all
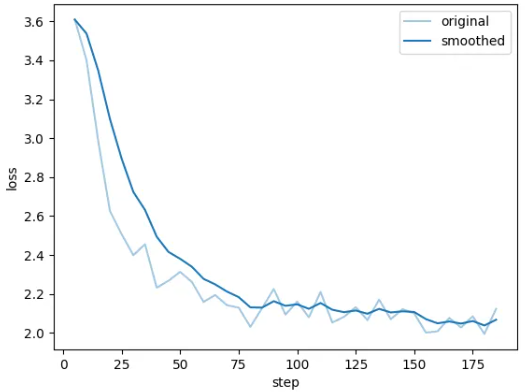
训练过程中损失函数变化:
启动训练阶段的报错信息:
报错信息:[INFO|2025-04-10 16:44:15] tokenization_utils_base.py:2323 >> Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
这个警告是由于transformers版本引起的,transformers会自动往tokenizer_config.json加上一些内容。
tokenizer_file是由于transformers4.34引起的,可以升级到4.35就没有问题了,或者降到4.33,不会添加任何东西。
解决方案
[WARNING|2025-04-10 17:14:52] logging.py:328 >> Sliding Window Attention is enabled but not implemented for sdpa; unexpected results may be encountered.
/root/autodl-tmp/LLaMA-Factory/tests/model/model_utils/test_attention.py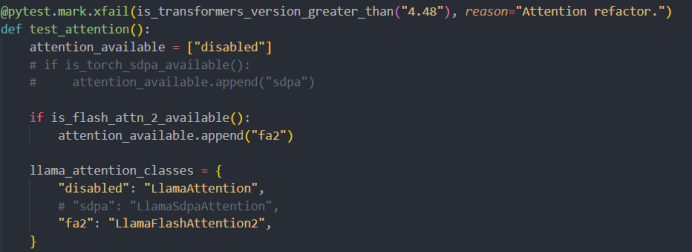
将sdpa注释掉,设置为fa2
解决方案
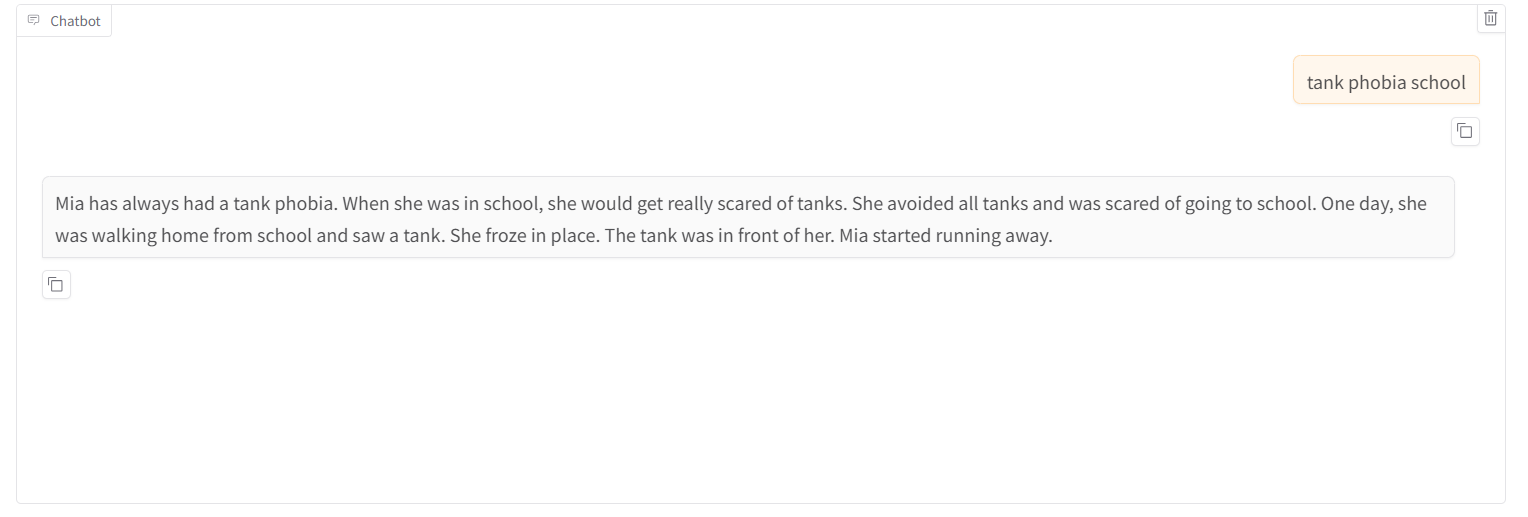
微调结束后可以通过指标和对话的方式测试微调效果:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









