




思维引导
如果把全连接网络比作 “流水线”,前向传播就是 “流水线启动的过程”—— 这一节会带你看 “数据从输入层出发,经过隐藏层处理,最终到输出层产生结果” 的完整流程,还会结合 Pytorch 代码实战,让你从 “理论理解” 过渡到 “代码实现”,搞懂 “网络怎么用参数算出预测结果”。
小节详细内容
-
前向传播(点击前往炮哥教学视频)的定义:数据 “向前走” 的流程前向传播(Forward Propagation)是 “输入数据通过网络各层,逐步计算出输出结果” 的过程,核心是 “按顺序执行神经元的计算逻辑”(加权求和→激活函数),没有反向调整参数(反向传播是后续内容),只做 “正向计算”。也可以通过观察全连接神经网络的动态效果变化来理解神经网络的运算过程
-
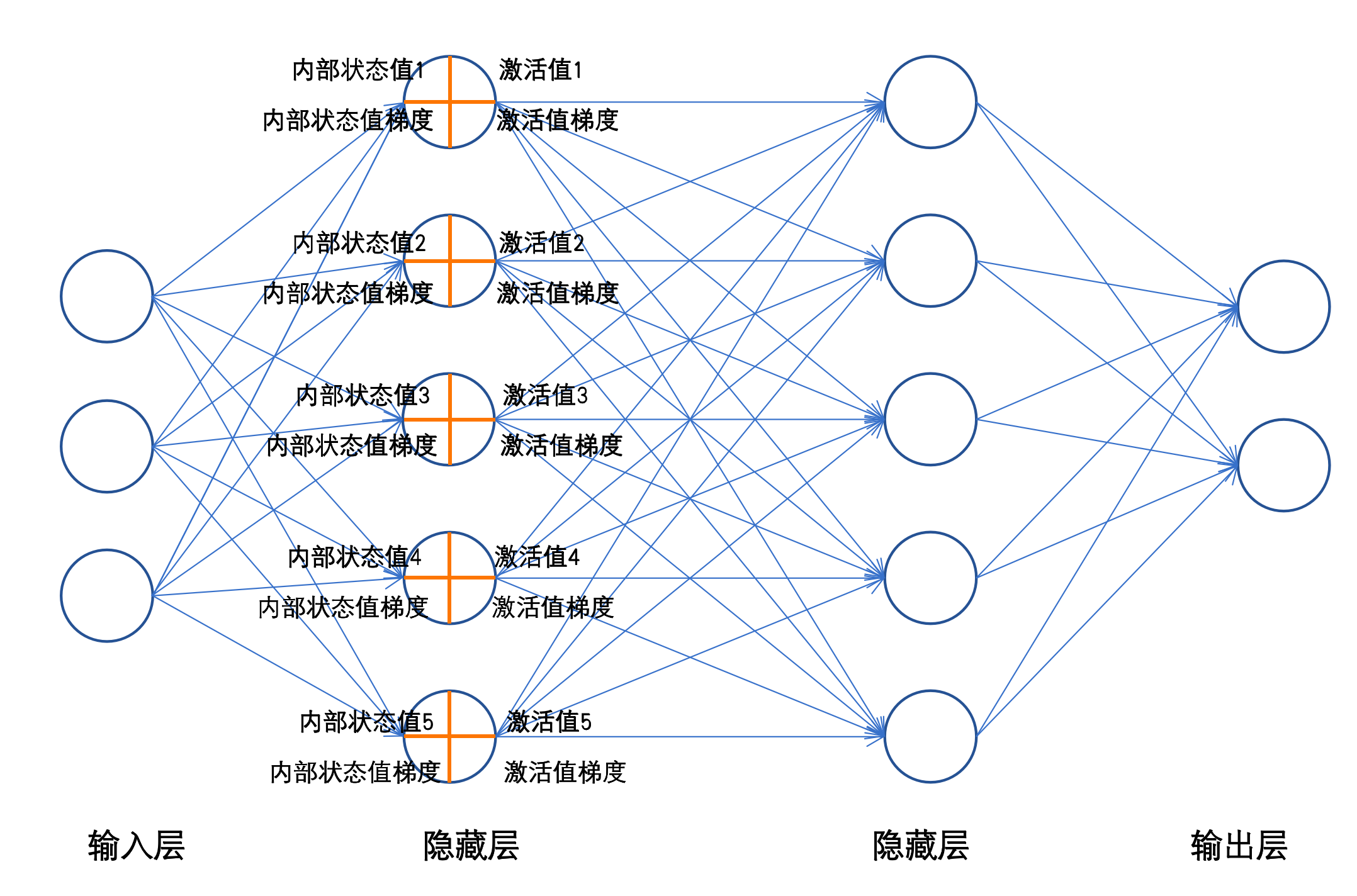
前向传播的步骤(结合实例拆解) 还是用 “手写数字识别” 的网络(输入层 784→隐藏层 128→输出层 10,隐藏层用 ReLU 激活,输出层用 Softmax 激活)为例,拆解每一步的计算:
-
步骤 1:输入层接收数据,传递给隐藏层
图片是数据操作示意,数据举例按照文字中的来看就好,图片只展示流程
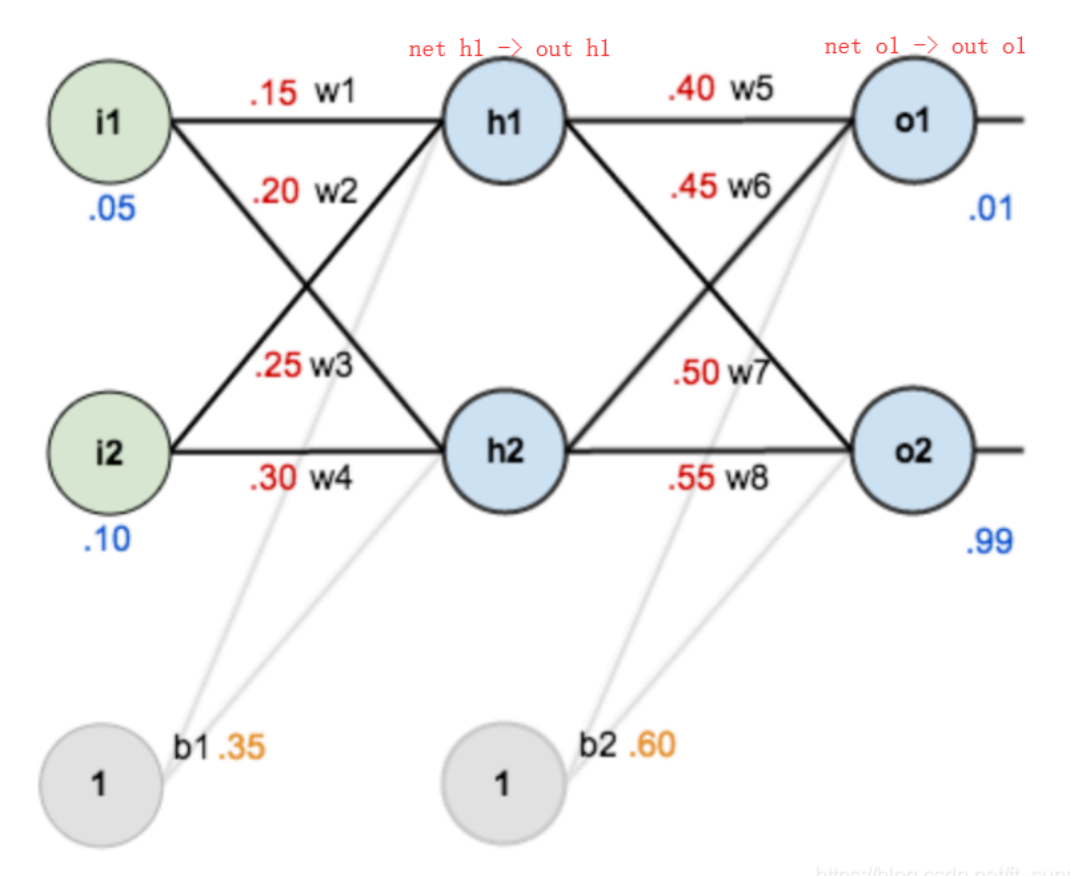
输入数据是 “拉平后的图片向量” x,维度为 (1, 784)(1 表示 “1 个样本”,784 是输入特征数),直接传递给隐藏层的第一个全连接层。 -
步骤 2:隐藏层计算(加权求和→激活函数)
- 加权求和:用隐藏层的权重 w₁(维度 784×128)和偏置 b₁(维度 1×128),计算 z₁ = x × w₁ + b₁,结果 z₁的维度是 (1, 128)(和隐藏层神经元数一致)。
- 激活函数处理:用 ReLU 激活函数对 z₁处理,得到 a₁ = ReLU (z₁),维度还是 (1, 128),这是隐藏层的输出,会传递给输出层。
-
步骤 3:输出层计算(加权求和→激活函数)
- 加权求和:用输出层的权重 w₂(维度 128×10)和偏置 b₂(维度 1×10),计算 z₂ = a₁ × w₂ + b₂,结果 z₂的维度是 (1, 10)(和输出层神经元数一致)。
- 激活函数处理:输出层用 Softmax 激活函数(适合多分类任务),计算 a₂ = Softmax (z₂),结果 a₂的维度是 (1, 10),每个数值代表 “样本属于对应类别的概率”(比如 a₂[0][3] = 0.9,就是 “90% 概率是数字 3”)。
-
步骤 4:输出最终结果
取 a₂中 “概率最大的索引” 作为预测类别,比如 a₂的最大值在索引 3 处,就预测这个样本是 “数字 3”。
-
Pytorch 实现前向传播(实战代码)
Pytorch 通过 “定义网络类 + forward 方法” 实现前向传播,代码逻辑和理论步骤完全对应,新手可以直接套用这个模板:
import torch
import torch.nn as nn
# 1. 定义全连接网络类(继承nn.Module,必须重写__init__和forward)
class FCNet(nn.Module):
def __init__(self):
super(FCNet, self).__init__()
# 定义网络层(输入层→隐藏层,隐藏层→输出层)
self.fc1 = nn.Linear(784, 128) # 输入层784,隐藏层128,自动初始化参数
self.fc2 = nn.Linear(128, 10) # 隐藏层128,输出层10,自动初始化参数
# 定义激活函数
self.relu = nn.ReLU()
self.softmax = nn.Softmax(dim=1) # dim=1表示对“类别维度”做Softmax(每个样本的10个类别概率和为1)
# 2. 定义前向传播流程(核心!数据走的路径)
def forward(self, x):
# 输入层→隐藏层:先过全连接层,再过ReLU
x = self.fc1(x) # 计算z1 = x*w1 + b1
x = self.relu(x) # 计算a1 = ReLU(z1)
# 隐藏层→输出层:先过全连接层,再过Softmax
x = self.fc2(x) # 计算z2 = a1*w2 + b2
x = self.softmax(x)# 计算a2 = Softmax(z2)
return x # 返回最终的概率输出
# 3. 测试前向传播(验证流程是否通顺)
if __name__ == "__main__":
# 创建网络实例
net = FCNet()
# 模拟输入数据(1个样本,784维特征)
input_data = torch.randn(1, 784) # randn生成“符合正态分布”的随机数,模拟图片向量
# 执行前向传播
output = net(input_data)
# 查看结果:输出维度应为(1,10),且每个样本的概率和为1
print("输出维度:", output.shape) # 预期输出:torch.Size([1, 10])
print("概率和:", torch.sum(output).item()) # 预期输出:接近1.0(因浮点误差,可能是0.9999999或1.0000001)
- 关键注意点:
- 网络类必须继承
nn.Module,这是 Pytorch 的 “规范”,能自动管理参数。 forward方法里的 “数据路径” 要和理论一致,不能漏层或乱序(比如必须先过fc1再过relu)。- Softmax 的
dim参数要设对:dim=1表示对 “每个样本的类别维度” 计算(比如 1 个样本有 10 个类别,就对这 10 个值做 Softmax),如果设错会导致概率和不为 1。
- 网络类必须继承
- 前向传播的核心作用
- 对训练来说:前向传播能计算出 “预测结果”,再和 “真实标签” 对比,得到 “损失值”(比如预测是 3,真实是 5,损失值就会大),而损失值是后续 “反向传播调整参数” 的依据。
- 对预测来说:训练好的网络,只需要执行前向传播,就能快速输出预测结果(比如给一张新的手写数字图片,几秒内就能算出它是哪个数字)。
思维引导
这一节你已经实现了 “全连接网络的动态计算”:既懂了前向传播的理论流程,又能用 Pytorch 写出可运行的代码 —— 接下来就要学 “怎么判断预测结果好不好”(损失函数)和 “怎么调整参数让结果更好”(反向传播与优化器),这是让网络从 “不会预测” 到 “预测很准” 的关键步骤。




















 1423
1423

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











