







 本文详细介绍了scrapy-redis框架的概念、分布式原理以及在Windows和Linux上搭建master和slave节点的具体步骤,包括Python安装、pip包管理、Scrapy配置和Redis的设置,旨在帮助读者实现高效分布式爬取。
本文详细介绍了scrapy-redis框架的概念、分布式原理以及在Windows和Linux上搭建master和slave节点的具体步骤,包括Python安装、pip包管理、Scrapy配置和Redis的设置,旨在帮助读者实现高效分布式爬取。
目录
6.针对现在Urllib3放弃对 OpenSSL<1.1.1 的支持
11.升级pip,安装scrapy,scrapy-redis
一、scrapy-redis概念
(一)、何为scrapy-redis框架?
一个三方的基于redis的分布式爬虫框架,配合scrapy使用,让爬虫具有了分布式爬取的功能。
(二)、分布式原理
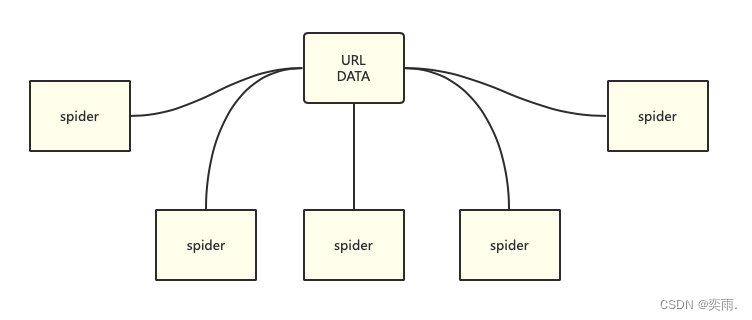
这样的意思是:
scrapy-redis实现分布式,其实从原理上来说很简单,这里为描述方便,我们把自己的核心服务器称为master,而把用于跑爬虫程序的机器称为slave。
我们知道,采用scrapy框架抓取网页,我们需要首先给定它一些start_urls,爬虫首先访问start_urls里面的url,再根据我们的具体逻辑,对里面的元素、或者是其他的二级、三级页面进行抓取。而要实现分布式,我们只需要在这个starts_urls里面做文章就行了
我们在master上搭建一个redis数据库`(注意这个数据库只用作url的存储),并对每一个需要爬取的网站类型,都开辟一个单独的列表字段。通过设置slave上scrapy-redis获取url的地址为master地址。这样的结果就是,尽管有多个slave,然而大家获取url的地方只有一个,那就是服务器master上的redis数据库。
并且,由于scrapy-redis自身的队列机制,slave获取的链接不会相互冲突。这样各个slave在完成抓取任务之后,再把获取的结果汇总到服务器上。
好处:
程序移植性强,只要处理好路径问题,把slave上的程序移植到另一台机器上运行,基本上就是复制粘贴的事情
(三)、分布式爬虫实现的流程
使用三台机器,一台是win11(windows),两台是centos,分别在两台机器上部署scrapy来进行分布式抓取一个网站。
windows的ip地址为
实际IP,用来作为redis的master端,centos的机器作为slave。master的爬虫运行时会把提取到的url封装成request放到redis中的数据。库:“dmoz:requests”,并且从该数据库中提取request后下载网页,再把网页的内容存放到redis的另一个数据库中“dmoz:items”。
slave从master的redis中取出待抓取的request,下载完网页之后就把网页的内容发送回master的redis。
重复上面的3和4,直到master的redis中的“dmoz:requests”数据库为空,再把master的redis中的“dmoz:items”数据库写入到想要存储的数据库中。
master里的reids还有一个数据“dmoz:dupefilter”是用来存储抓取过的url的指纹(使用哈希函数将url运算后的结果),是防止重复抓取的。
使scrapy的工作流程变成这样:
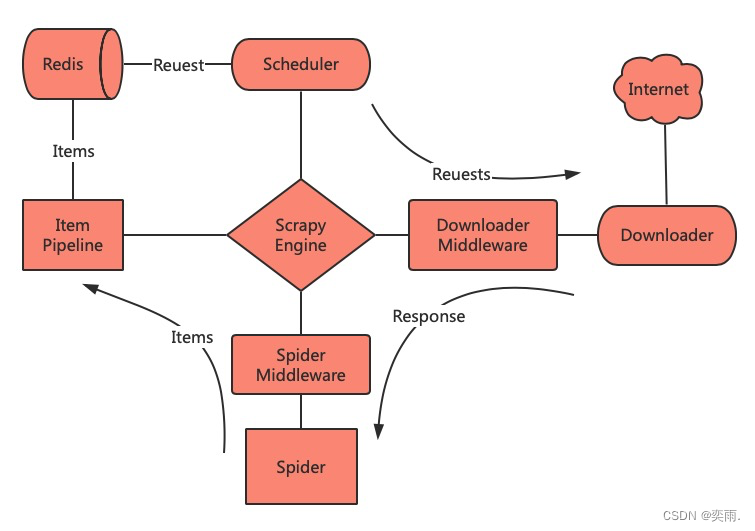
好了,原理了解了,实现是关键!!!
二、分布式爬虫搭建
(一)、Windows(master节点)上要做的事情
1.安装python
官网:https://www.python.org/downloads/
下载安装完成后,务必配置环境变量
2.下载相应的python包
pip install lxml
pip install scrapy
pip install scrapy-redis
3.创建你的爬虫项目
scrapy startproject 项目名
scrapy genspider 爬虫名 域名
4.配置你项目中的settings文件
github地址:https://github.com/darkrho/scrapy-redis
在settings文件中输入以下代码
这是实现分布式的关键:
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
SCHEDULER_PERSIST = True另外还有一些次要但也是重要的:
ROBOTSTXT_OBEY = False # robots协议
USER_AGENT = '' # 可以写死一个User-Agent,亦可动态实现
对redis的配置,同样是settings文件中
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 400,
}
REDIS_HOST = '' # windows机器的IP
REDIS_PORT = 6379 # Redis端口号爬虫文件需要自行定义,这里我就不多说了。
5. Windows上redis的配置(重要)
①安装redis和图形化工具
安装包:https://wwql.lanzout.com/b052o0lmf,密码:3rsj
链接中包含redis压缩包和redis图形化工具
②修改redis.windows.conf和redis.windows.service.conf两个配置文件以达成使虚拟机的ip亦可访问本地redis数据库。具体可访问以下链接:
【Python爬虫】解决Redis无法使用ip访问(127.0.0.1可以访问)的情况-优快云博客
③ 在redis.windows.conf这个配置文件中,修改以下
stop-writes-on-bgsave-error no (默认值为yes)
即当bgsave快照操作出错时停止写数据到磁盘,这样后面写错做均会失败,为了不影响后续写操作,故需将该项值改为no
至此,Windows端(master节点)配置完毕!
(二)、Linux(slave节点)要做的事情
注:这里采用的使CentOS7作为镜像源。
1.配置网络
vi /etc/sysconfig/network-scripts/ifcfg-ens33 # 配置ip,网关,dns等等。
service network restart # 重启网络服务
2.关闭防火墙
systemctl disable firewalld # 永久关闭
3.配置域名映射
vi /etc/hosts # 新增slave节点(两台)的映射,格式为 ip 主机名
4.配置ssh免密
cd ~
ssh-keygen -t rsa # 一路确定
cd ~/.ssh
cp id_rsa.pub authorized_keys
chomd 600 authorized_keys
配置完成后 ssh localhost,ssh 主机名,ssh 0.0.0.0输入yes之后不需要密码即可。
5.安装python3所需要的环境
# 安装编译相关工具
yum -y groupinstall "Development tools"
yum -y install zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel readline-devel tk-devel gdbm-devel db4-devel libpcap-devel xz-devel
yum install libffi-devel -y
6.针对现在Urllib3放弃对 OpenSSL<1.1.1 的支持
GitHub地址:Drop support for OpenSSL<1.1.1 · Issue #2168 · urllib3/urllib3 · GitHub
编译安装openSSL1.1.1n
# 若没有wegt ,使用yum install -y wget
wget https://www.openssl.org/source/openssl-1.1.1n.tar.gz --no-check-certificatetar zxf openssl-1.1.1n.tar.gz -C 指定目录
cd openssl-1.1.1n/
./config --prefix=/usr/local/openssl 设置安装目录 可以自定义 但是要记住,后面会用到
make -j && make install 编译并安装
/usr/local/openssl/lib 路径添加到系统动态库查找路径中,在 etc 目录下的 profile文件最后面添加下面这一行
export LD_LIBRARY_PATH=/usr/local/openssl/lib:$LD_LIBRARY_PATHsource /etc/profile # 使其生效
7.下载Python安装包解压
①官网:
Python Release Python 3.8.2 | Python.org
下载如图所示,点击下载
将该压缩包拖拽或者发送到虚拟机中
cd 指定目录
tar -zxvf Python-3.8.2.tgz -C 指定目录
②
wget https://www.python.org/ftp/python/3.8.2/Python-3.8.2.tgz
8.编译及安装python:
mkdir /usr/local/python3 # 创建编译安装目录
cd python安装目录
./configure --prefix=/usr/local/python3 --with-openssl=/usr/local/openssl --with-ssl-default-suites=openssl --with-system-ffi
make -j && make install
9.配置环境变量
vi /etc/profile
export PATH=$PATH:/usr/local/python3/bin/ # 配置环境变量
source /etc/profile # 使其生效
10.验证pip
pip3 -V
11.升级pip,安装scrapy,scrapy-redis
pip3 install --upgrade pip -i https://pypi.douban.com/simple/
pip3 install scrapy -i https://pypi.douban.com/simple/pip3 install scrapy-redis -i https://pypi.douban.com/simple/
12.运行爬虫项目
scrapy crawl 爬虫名
至此,运行完成!!!
如果有不对的地方,或者有很好的见解,欢迎在评论区指出和发表,谢谢!

















 256
256

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









