






目录
封装,继承,多态是面向对象的三大特性,今天来谈谈继承。
继承的概念以及定义:
继承是面向对象程序设计使代码可以复用的最重要手段,他允许程序员在保持原有类特性的基础上进行拓展,增加功能,这样产生新的类,称派生类。继承呈现了面向对象设计层次结构,体现了由简单到复杂的认知过程。继承是类设计层次的复用。
概念和定义了即可,接下来看一看具体的继承的使用以及继承的特性:
一.继承的定义及使用
class Person
{
public:
//protected:
string _name = "Peter";//姓名
int _age = 18;//年龄
void Print()
{
cout << _name.c_str() << " ";
cout << _age << endl;
}
};
class Student :public Person
{
protected:
int _stuid;//学号
};假设学校统计人员信息,学生,老师,校工的信息有相似之处,但是也有一些地方是不同的,比如他们的姓名,年龄,性别这些数据是相同类型的,但是学校的学生有学号,老师和校工有工号。上面的代码中Student 这个类就是继承Person这个类,再增加了_stuid这个成员变量。
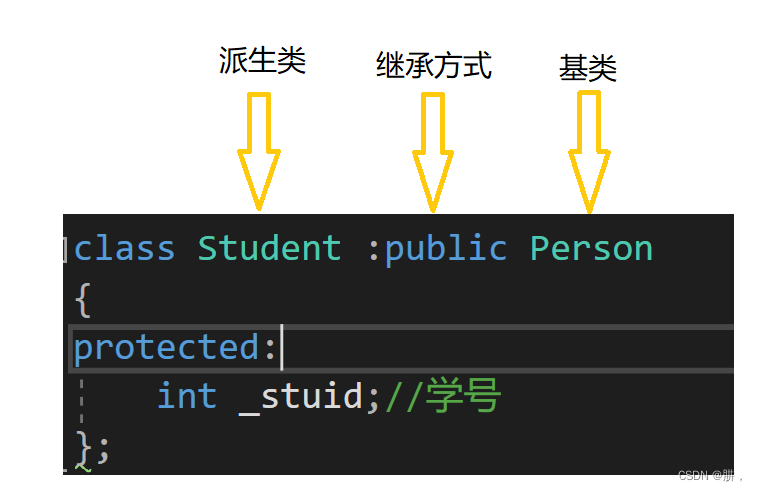
这就是继承的基本语法,这里的Person是父类,也称作基类,Student是子类,也称作派生类。
继承关系和访问限定符
在C++中,我们在类和对象中了解了访问限定符:
在继承中,也是有访问限定符的:
继承中的继承方式就涉及到了继承的访问权限,继承的权限本质上就是为了限制在派生类中访问基类的一些成员变量。
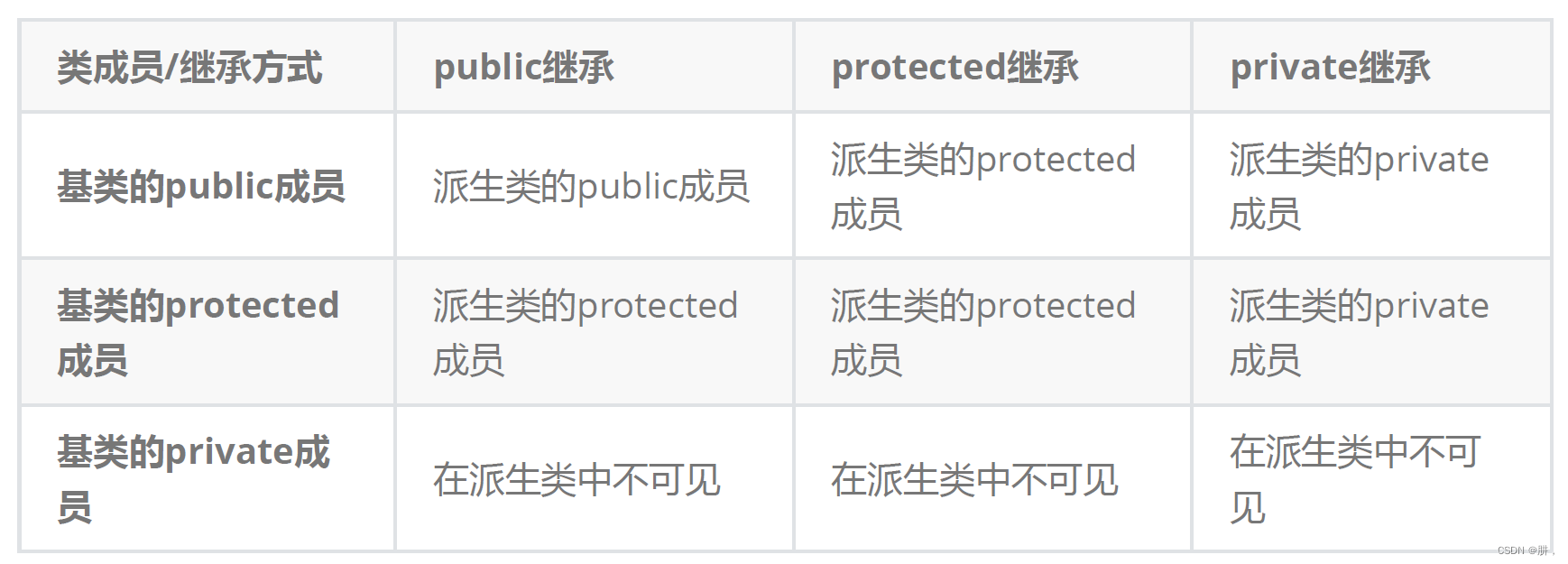
乍一看表格的信息很复杂,但是仔细看也是可以总结出一些东西的:
- 基类的private成员其决定性作用:基类中的所有的private成员无论以任何方式继承到派生类中之后,都是在派生类中不可见。
- 如果权限排序为private>protected>public,基类的非private成员以继承方式以基类成员的排序大小,权限大的为主。
- 使用关键字class时默认继承方式为private,使用关键字struct时默认的继承方式为public
- 在实际使用的时候一般都是public继承,几乎很少使用protected/private继承,也不提倡使用protected/private继承,因为protected/private继承下来的成员只能在派生类的成员里面使用,实际中拓展维护性不强。
- 在派生类中不可见:就是在派生类的类里面和类外面都不能访问。
基类和派生类对象赋值转换
派生类对象可以赋值给基类对象/基类指针/基类引用,也可以叫切片或切割。
这其实也很好理解,因为派生类是在基类的前提下又增加了自己设定的成员变量,所以派生类对象可以切割出来基类的那一部分赋值给基类。
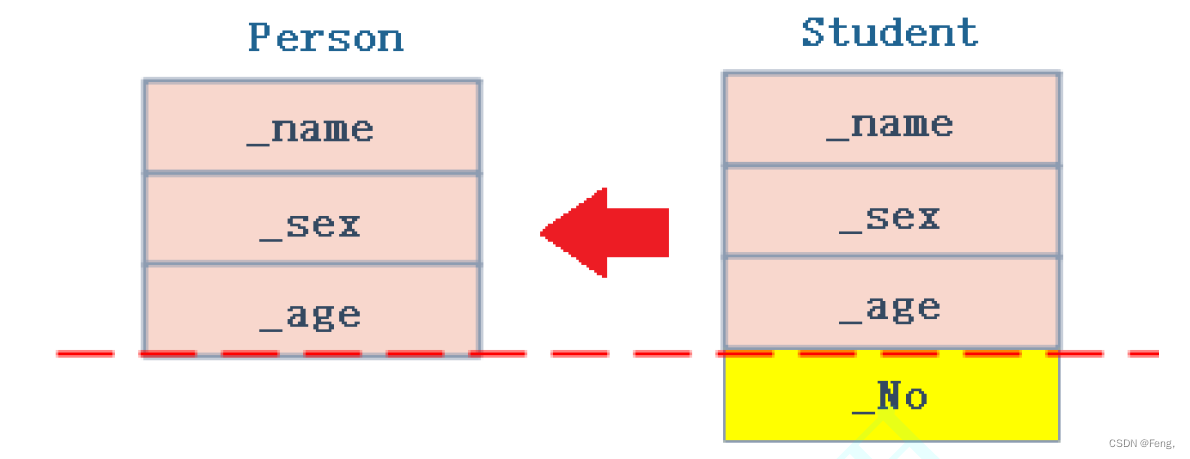
class Person
{
protected:
string _name; // 姓名
string _sex; // 性别
int _age; // 年龄
};
class Student : public Person
{
public:
int _No; // 学号
};
void Test()
{
Student sobj;
// 1.子类对象可以赋值给父类对象/指针/引用
Person pobj = sobj;
Person* pp = &sobj;
Person& rp = sobj;
//2.基类对象不能赋值给派生类对象
//sobj = pobj;
// 3.基类的指针可以通过强制类型转换赋值给派生类的指针
pp = &sobj;
Student * ps1 = (Student*)pp; // 这种情况转换时可以的。
ps1->_No = 10;
pp = &pobj;
Student* ps2 = (Student*)pp; // 这种情况转换时虽然可以,但是会存在越界访问的问题
ps2->_No = 10;
}继承中的作用域
- 在继承体系中基类和派生类都有各自的作用域
- 如果基类和派生类中出现了同名的成员函数或成员变量,子类成员将屏蔽父类对同名成员的直接访问,这种情况叫隐藏,也叫重定义。(在子类成员函数中,可以使用 基类::基类成员 显示访问)
- 与函数重载不同,只要函数名相同,那么基类和派生类的函数成员就构成隐藏
- 在实际中最好不要在继承体系中定义同名成员
派生类的四个成员函数
派生类可以理解为一部分是由基类组成的,而另一部分是自己的。那么四个成员函数属于基类的部分会调用基类对应的函数完成初始化/清理/拷贝
既然派生类中的一部分是由基类组成的,那么在构造函数中也会有些不一样:
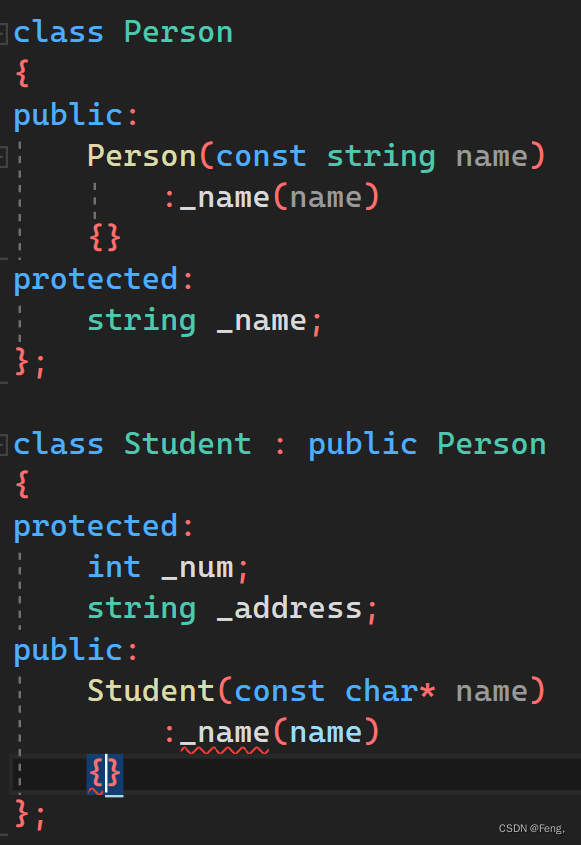
类似于这样初始化是会报错的,那么正确的初始化方式如下:
class Person
{
public:
Person(const string name)
:_name(name)
{}
protected:
string _name;
};
class Student : public Person
{
protected:
int _num;
string _address;
public:
Student(const char* name)
:Person(name)
,_num(1)
,_address("XXX")
{}
};就像构造一个匿名对象一样构造Person对象的成员变量
在拷贝构造函数中,如果让派生类对象的基类部分调用基类的拷贝构造函数,直接传递参数即可:
class Person
{
public:
Person(const string name)
:_name(name)
{}
Person(const Person& per)
{
_name = per._name;
}
protected:
string _name;
};
class Student : public Person
{
protected:
int _num;
string _address;
public:
Student(const char* name)
:Person(name)
,_num(1)
,_address("XXX")
{}
Student(const Student& stu)
:Person(stu)
, _num(stu._num)
, _address(stu._address)
{}
};赋值运算符重载的实现中,我们需要显示调用基类的赋值运算符重载函数,子类的赋值与父类的赋值构成隐藏关系。二者的函数名相同,参数不同:
Student& operator= (const Student& s)
{
if (this != &s)
{
Person::operator= (s);
_num = s._num;
_address = s._address;
}
return *this;
}但是析构函数在这里调用的时候就比较迷了:
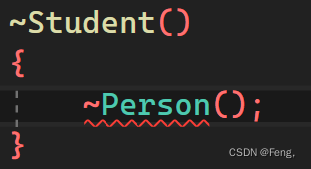
直接调用会报错,要是想调用成功,只能在析构函数前面家Person:: ,这是因为子类析构函数和父类析构函数默认构成隐藏关系,由于多态关系需求,所有析构函数都会特殊处理成destructor函数名
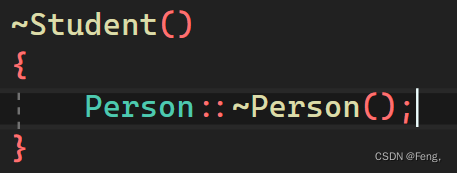
但是运行的时候又会出现问题:我们在Person类的析构函数中打印了一句话,在派生类显示调用析构函数后,会发现这句话打印了两次。
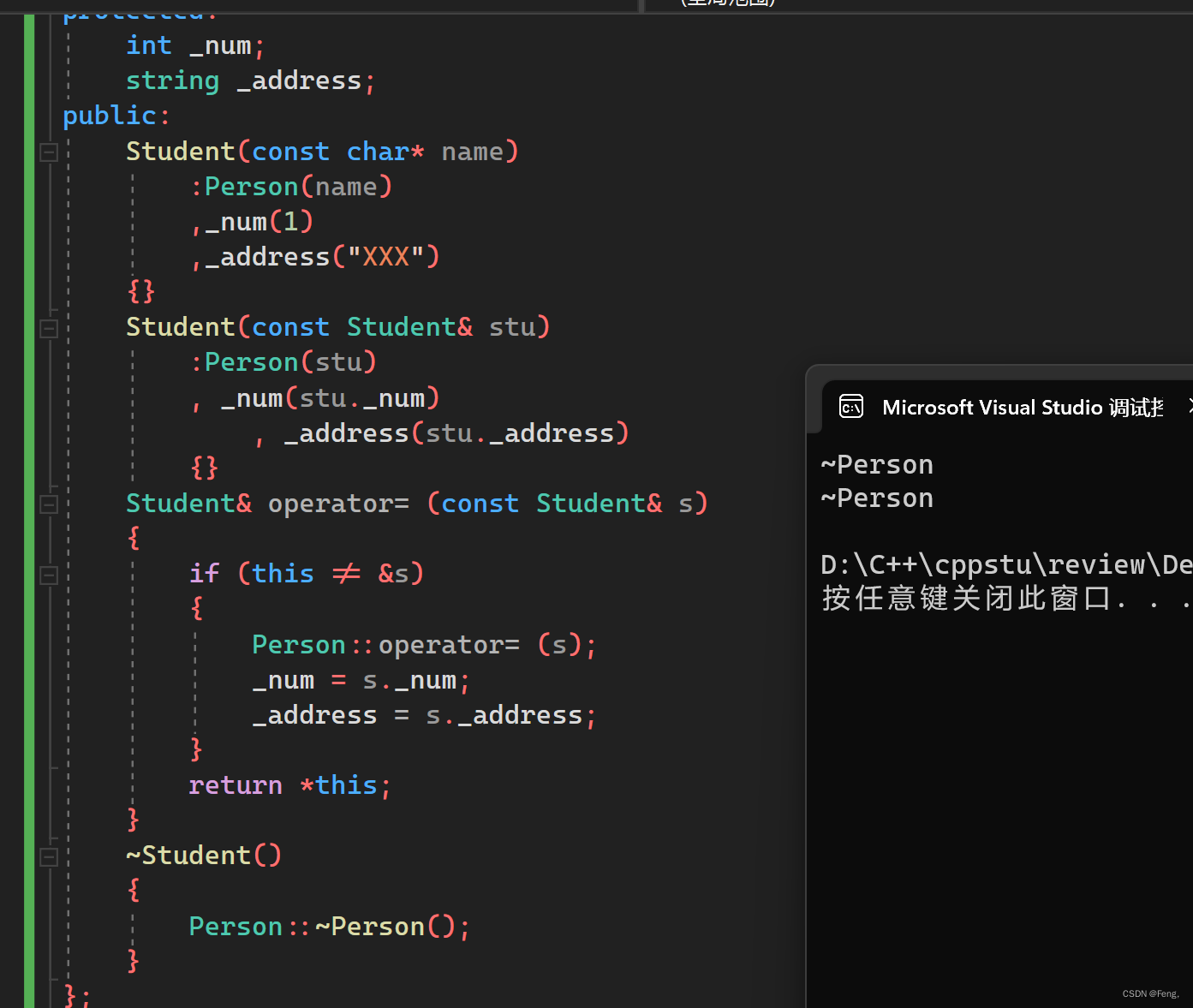
这样会导致什么后果呢? 当前程序下我们没用开辟空间,当然在回收的时候也不需要释放,如果在堆区开辟空间,之后需要释放,就会导致重复释放导致报错。所以在写派生类的析构函数的时候,不需要显示调用基类的析构函数。其次要注意调用顺序,子类先析构,父类后析构,如果显示调用就会打破调用顺序。
继承与类的对象的一些关系
继承和友元的关系
友元关系是无法继承的,也就是说基类的有元函数是无法访问派生类的私有和保护成员的
继承与静态成员
和我们之前讲的一样,静态成员不属于类所创建的对象的任何一个对象,静态成员属于整个类,所有对象,同时也属于所有派生类及对象
多继承
在介绍多继承之前,先来说一下单继承,我们上面的代码中的继承就是单继承,一个派生类只继承一个基类,这个就叫单继承。那么一个派生类继承两个或两个以上的基类,这就叫多继承。但是多继承也会导致一个很麻烦的问题:菱形继承
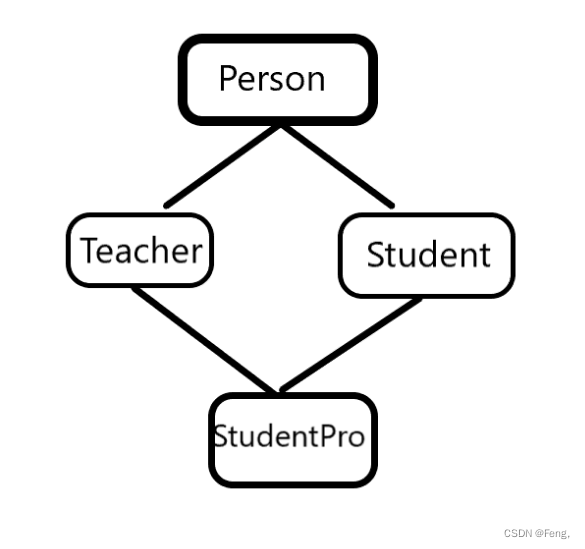
假设Person中有一个IdCard的成员变量,而Student和Teacher中也会继承一个一样的变量,那么最终继承给StudentPro的IdCard应该是谁的呢?这就造成了数据的二义性(数据冗余)问题。
这个问题有什么解决的办法呢?这里就要提到虚拟继承这个新的名词:
首先要知道虚继承是在上图 Teacher和Student这里(在数据冗余的类这里引入虚拟继承)
来看一下效果:
#include <iostream>
#include <string>
using namespace std;
class Person
{
public:
string _name; // 姓名
};
class Student : virtual public Person
{
protected:
int _num; // 学号
};
class Teacher : virtual public Person
{
protected:
int _id; // 职工编号
};
class Assistant : public Teacher, public Student
{
protected:
string _majorCourse; // 主修课程
};
int main()
{
Assistant a;
a._name = "张三";
a.Student::_name = "张同学";
a.Teacher::_name = "张老师";
return 0;
}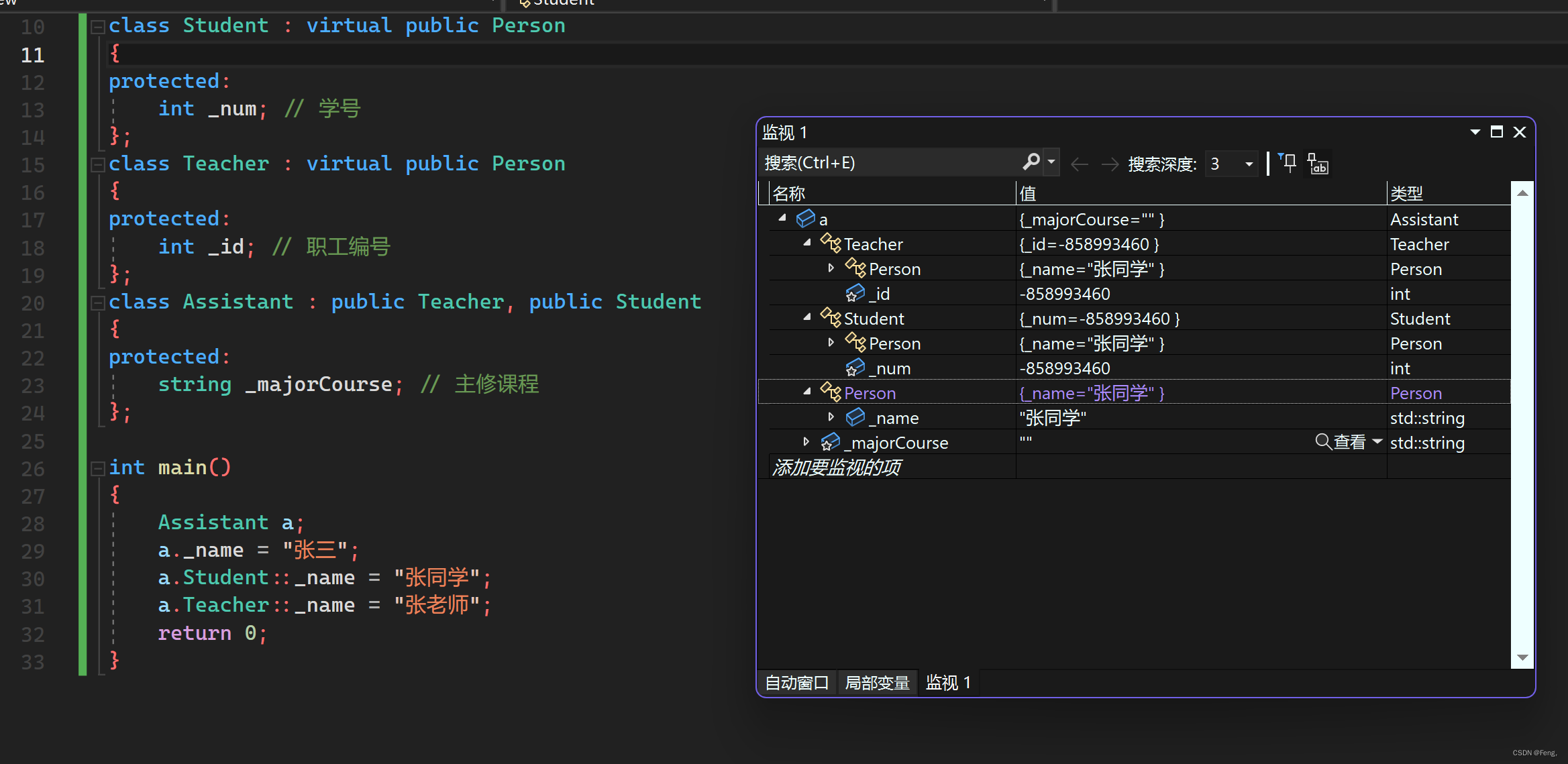
可以发现无论定义多少次_name, _name只有一个,这样就解决了数据冗余的问题。
这里我们创建一个新的菱形继承的模型来深入理解虚拟继承:C++是如何解决数据冗余和二义性的
class A
{
public:
int _a;
};
class B : public A
{
public:
int _b;
};
class C : public A
{
public:
int _c;
};
class D : public B, public C
{
public:
int _d;
}; 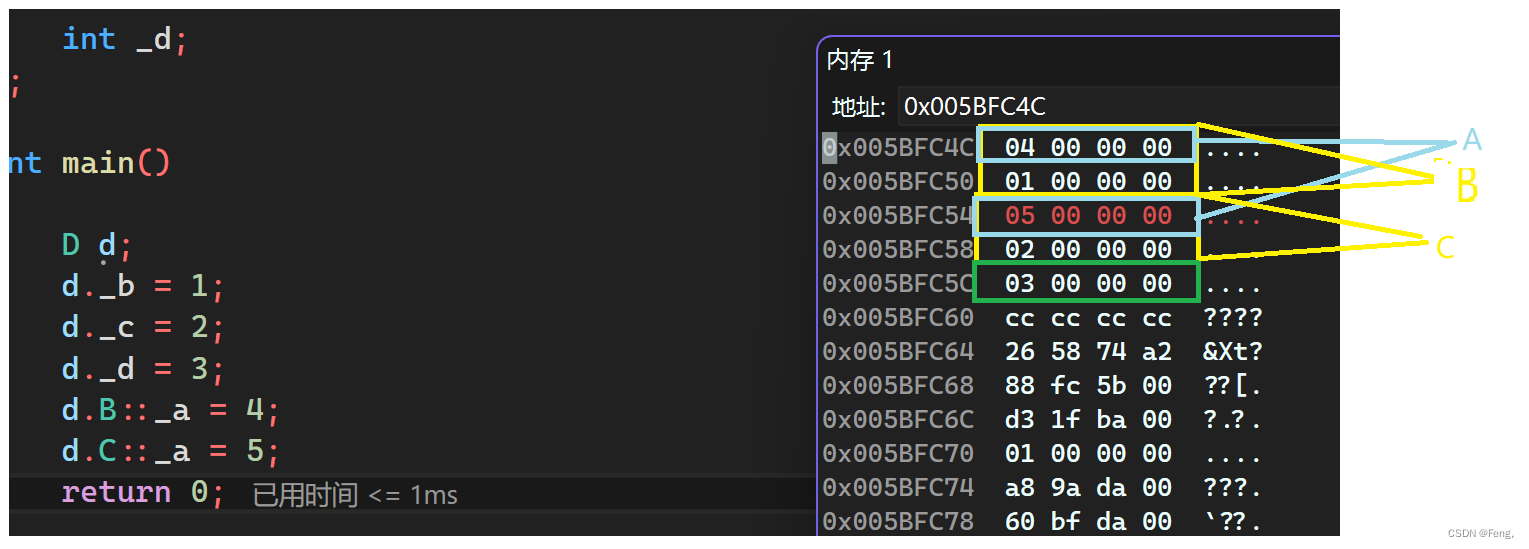
我们可以看到B和C中都存着自己的类中的成员变量,所以会有数据冗余和二义性的问题,但如果是虚拟继承,调试结果就又会不一样:
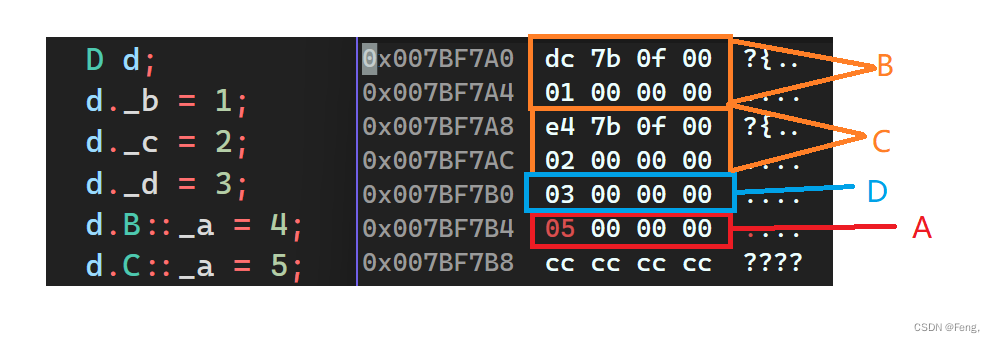
我们发现B和C中第一行的内容很奇怪,好像是个地址,放在内存监视窗口看一看:
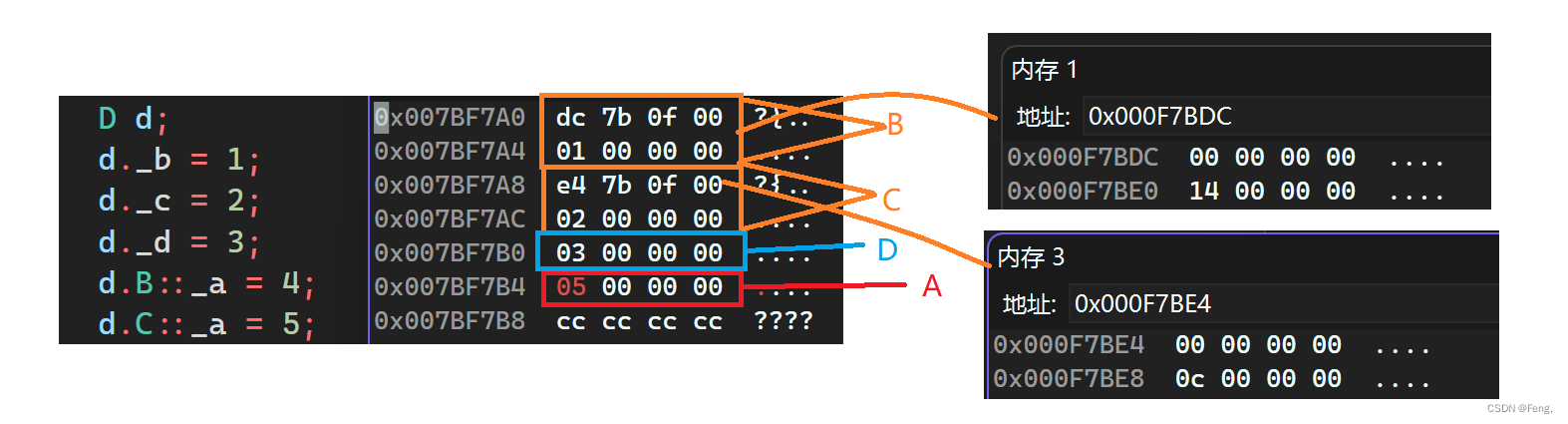
第一行的数据都是0,但是第二行的数据从十六换算成八进制,第一个是20,第二个是12;这两个数字有什么意义呢?仔细观察B的第一行的地址与A这一行地址的差值,就是20,而C第一行的地址与A这一行的地址的差值,也就是距离虚基类对象的偏移量
多继承导致的菱形继承是一个很麻烦的事情,我们在平时编写代码的时候尽量不要使用菱形继承。
探究继承与组合
// 继承
class X
{
int _x;
};
class Y : public X
{
int _y;
};
// 组合
class M
{
int _x;
};
class N
{
M _m;
int _n;
};
继承是一种白箱复用,组合是一种黑箱复用,为了方便大家理解,这里我列举一下白箱和黑箱的概念:
白箱
白箱测试是一种测试方法,它涉及对软件系统的内部结构进行测试,以确定其是否符合预期的功能和性能。白箱测试可以帮助开发人员更好地理解软件系统的内部结构,以及它们如何实现其功能。
黑箱
黑箱测试是一种测试方法,它涉及对软件系统的外部行为进行测试,以确定其是否符合预期的功能和性能。黑箱测试可以帮助开发人员更好地理解软件系统的外部行为,以及它们如何实现其功能。
这样就很好理解了,但是具体在使用的时候,使用继承好还是组合好,如果既可以使用继承又可以使用组合,使用哪个比较好呢?
我们可以发现,组合的耦合度要比继承更低,在软件设计的角度,我们提倡高内聚低耦合。但是为什么组合的耦合度会比继承低呢?
假设有一个基类,又20个公有成员,30个保护成员,50个私有成员,如果继承给派生类,那么对这100个成员进行修改,对派生类造成的最大的影响就是50个成员
那么假设是组合呢?只有共有的20个成员会造成影响,降低了耦合度
继承就介绍到这里了,希望大家学习愉快,早日拿到自己心仪的offer!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











