






 本文介绍了Slowfast网络用于视频行为识别。行为识别是对视频连续帧检测设定的行为动作,Slowfast要提取环境与动作特征并融合。其网络分两部分分别提取特征,取帧间隔不同。提取完特征后将动作特征融入环境特征实现行为识别,还介绍了处理特征图维度差异的三种方法。
本文介绍了Slowfast网络用于视频行为识别。行为识别是对视频连续帧检测设定的行为动作,Slowfast要提取环境与动作特征并融合。其网络分两部分分别提取特征,取帧间隔不同。提取完特征后将动作特征融入环境特征实现行为识别,还介绍了处理特征图维度差异的三种方法。
简述
行为识别与目标检测很相似。如果说目标检测是对静态图片提取特征最终进行检测,那行为识别就是对视频连续的帧进行检测,检测的对象主要为人为设定好的各种行为动作。
Slowfast要提取的特征为环境特征与动作特征,环境特征即视频图片中的背景,动作特征顾名思义即视频中人物的动作。slowfast的基本思想便是:如何提取视频中的环境特征与动作特征,并对两者进行融合。
网络架构
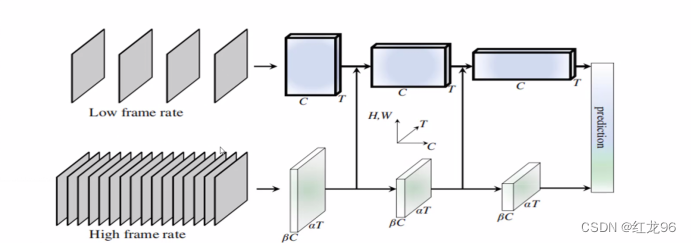
Slowfast的网络分两部分,一部分提取环境特征,一部分提取动作特征,每一部分都是取相同间隔的帧输入网络。在一段视频中,环境特征大多并不会发生太大变化,因此该部分的网络取帧的间隔会大一些,也就是输入网络的数据会少一些;而在一段视频中人的动作是时刻都在发生变化的,所以该部分的网络取帧的间隔得小一些,也就是输入网络的数据要多一些。
我们可以知道,提取环境特征取帧的间隔较大,对环境特征的提取更多是基于单张图片,因此提取环境特征时需要较多的特征图,以提取较为详细的特征;提取动作特征时取帧间隔较小,对动作信息的提取以及动作的预测更多是基于连续的图片,而不是单张图片,因此提取动作特征时需要较少的特征图,这能够使得在保证一定精度的同时还能减少计算量。
分别提取完动作和环境的特征后,还得将动作特征给融入环境特征,这样的操作得进行好几步,最终便可实现对于行为的识别。
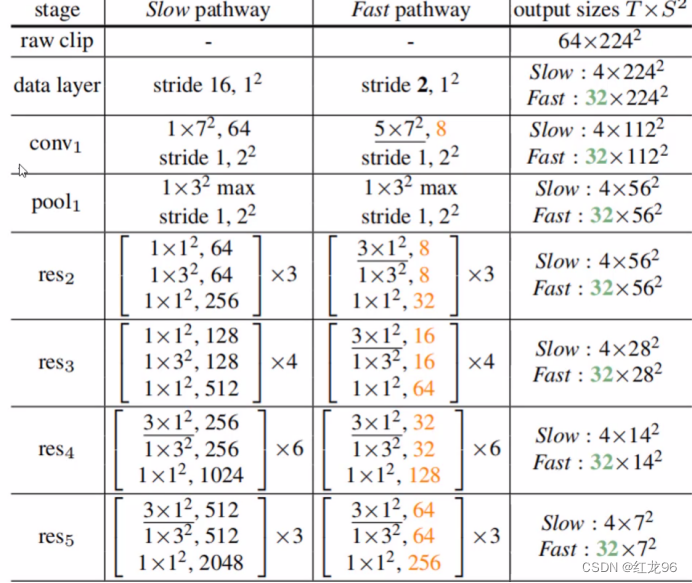
特征融合
环境特征与动作特征最终得到的特征图在维度上的差异可能会使得它们无法进行拼接,这里的差异主要在于输出特征图的帧数这个维度有差异,也就是图中的T维度,这个时候就需要对特征图进行处理,论文中给出了以下三种做法:
①直接reshape;②截取部分帧;③3D卷积。
论文中采取的办法是再进行一个3D卷积然后再在帧数这个维度上进行拼接。

















 1129
1129

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









