







🍻适合计算机二级,考研复试,期末复习…

一、易错题
1.1🎁 二维数组的初始化

A 选项:
在 C 语言中,对二维数组进行部分初始化 int a[][4] = {0, 0};,未明确给出初始值的元素会自动被初始化为 0。所以数组 a 的每个元素都可得到初值 0,该选项正确。
B 选项:
当二维数组的第一维大小省略,通过初始化列表来确定大小时,系统会根据初始化数据和第二维大小计算第一维大小。这里初始化列表中有 2 个元素,第二维大小为 4,由于每个 “行” 有 4 个元素,所以第一维大小为 1(2 / 4 向上取整 ,这里实际只有 1 行有显式初始化数据,其余元素补 0),该选项正确。
C 选项:
同 B 选项的分析,第二维大小为 4,初始化值有 2 个,按照规则可以推断出数组 a 的行数(第一维大小)为 1,该选项正确。
D 选项:
因为对二维数组进行部分初始化时,未被显式初始化的元素会自动初始化为 0,所以不只是 a[0][0] 和 a[0][1] 为 0,而是整个数组的所有元素都会被初始化为 0,该选项错误。
答案D
注意第一个括号是一维
1.2🎁 二维数组的初始化2

在 C 语言中,当定义数组 int a[3][4]; 时,这只是声明了一个二维数组,没有对其进行初始化操作。
未初始化的自动存储类型(在函数内部定义,没有 static 修饰)的数组元素,其值是不确定的,不会在编译阶段或运行阶段自动被初始化为 0。只有经过显式初始化,例如 int a[3][4] = {0}; 这种形式,数组元素才会被初始化为 0。
答案C
1.3🎁 二维数组的初始化2

第 3 行:int a[3]={3 * 0}; 等价于 int a[3]={0};,这是对数组a进行初始化,将数组的第一个元素初始化为0,其余元素自动初始化为0,语法正确。
第 5 行:for(i = 0; i < 3; i++) scanf(“%d”, &a[i]); 用于循环读取用户输入的整数存入数组a中。在循环过程中,i从0到2,&a[i]是合法的取地址操作,语法正确。
第 6 行:for(i = 1; i < 3; i++) a[0]=a[0]+a[i]; 这里存在逻辑问题。在这个循环中,不断将a[0]与a[1]、a[2]相加并把结果存回a[0],但在第一次循环时,a[0]的值就是初始值0,这样每次相加后a[0]的值会被改变,后续计算就不是基于原始数组元素的和了。并且从代码意图来看,可能是想计算数组元素的和,但写法有误。不过从语法角度,该行代码本身语法是正确的。
第 7 行:printf(“%d\n”, a[0]); 用于输出数组元素a[0]的值,语法正确。
综合来看,整段代码在语法上没有错误,只是第 6 行存在逻辑问题,但题目问的是代码是否有错误(从语法层面)。
答案D
1.4🎁 字符串数组初始化

A 选项:char s[5] = {“abc”}; ,字符串 “abc” 在存储时会自动在末尾添加 ‘\0’ 作为结束标志,总共占 4 个字节,加上字符串结束符共 4 个字符,数组大小为 5,可以容纳,初始化正确。
B 选项:char s[5] = {‘a’, ‘b’, ‘c’}; ,对字符数组部分初始化,未初始化的元素自动初始化为 ‘\0’ ,数组大小为 5,这种初始化方式可行。
C 选项:char s[5] = “”; ,表示一个空字符串,存储时仅包含字符串结束符 ‘\0’ ,数组大小为 5,可以容纳,初始化正确。
D 选项:char s[5] = “abcdef”; ,字符串 “abcdef” 包含 6 个字符,再加上自动添加的字符串结束符 ‘\0’ ,共 7 个字节,而数组 s 的大小为 5,无法容纳,初始化不正确。
答案D
字符串数组初始化总结:
// 一维字符数组初始化字符串示例
// 用字符串常量初始化,数组大小指定为6,能容纳"hello"和结束符'\0'
char str1[6] = "hello";
// 省略数组大小,编译器根据"world"和结束符'\0'自动确定数组大小为6
char str2[] = "world";
// 用字符常量逐个初始化,但未添加字符串结束符'\0',若后续当字符串用会有问题
char str3[5] = {'h', 'e', 'l', 'l', 'o'};
// 手动添加字符串结束符'\0',可作为正常字符串使用
char str4[6] = {'h', 'e', 'l', 'l', 'o', '\0'};
// 二维字符数组初始化字符串数组示例
// 初始化多个固定长度字符串,3行10列,可存储3个长度不超9(含结束符)的字符串
char strArray[3][10] = {"apple", "banana", "cherry"};
// 省略第一维大小,编译器根据初始化字符串数量确定为3,第二维固定为10
char strArray2[][10] = {"red", "green", "blue"};
1.5🎁 字符串数组的printf输出

在 C 语言中,%s是printf函数用于输出字符串的格式控制符。它在输出时,会从给定的字符数组首地址开始,依次输出字符,直到遇到字符串结束标志’\0’为止。
在定义字符数组c时,c[5] = {‘a’, ‘b’, ‘\0’, ‘c’, ‘\0’} ,当使用printf(“%s”, c);输出时,遇到第一个’\0’(即c[2]位置)就会停止输出。所以只会输出’a’和’b’两个字符。
答案B
1.6🎁 字符串数组的输入

A 选项:gets函数一次只能接收一个字符串,其参数为字符数组名(即数组首地址),不能同时传入两个数组参数a和b,所以该选项错误。
B 选项:scanf函数中,%s用于输入字符串,当输入字符串时,scanf会自动在输入的字符串末尾添加’\0’。对于字符数组名,本身就是数组首地址,所以直接使用数组名a和b作为参数即可,该选项正确。
C 选项:字符数组名已经表示数组首地址,不需要再使用取地址符&,使用&a和&b是错误的,会导致scanf无法正确读取输入,所以该选项错误。
D 选项:gets函数的参数应该是字符数组名,而不是用双引号括起来的字符串字面量"a"和"b",所以该选项错误。
答案B
注:a[] 这种写法不算是完整规范的数组名,数组名是a。a[] 通常出现在函数形参声明中,比如 void func(int a[])
1.7🎁 字符串数组strcpy

首先定义了两个字符数组 a 和 b,a 的长度为 7 并初始化为 “abcdef” (实际存储时末尾会自动添加 ‘\0’ ),b 的长度为 4 并初始化为 “ABC” (末尾同样有 ‘\0’ )。
然后执行 strcpy(a, b) ,strcpy 函数的作用是将字符串 b 复制到字符串 a 中。复制后,a 中的内容变为 “ABC\0ef” ,原来 a 中的前三个字符被覆盖,b 字符串结束符 ‘\0’ 也被复制到 a 中,截断了后面的字符。
最后执行 printf (“%c”,a[5]) ,此时 a[5] 对应的字符是 ‘f’ 。
答案 D
1.8🎁 字符串数组strlen

在 C 语言中,分析字符数组c的初始化字符串"\t\v\\0will\n":
\t是转义字符,表示水平制表符,算 1 个字符。
\v是转义字符,表示垂直制表符,算 1 个字符。
\\是转义字符,表示反斜杠\,算 1 个字符。
\0是字符串结束标志,strlen函数遇到\0就会停止计数,并且\0本身不被计入字符串长度。所以在\0之后的’w’、‘i’、‘l’、‘l’、'\n’都不会被统计。
综上,strlen( c)统计到\0前,长度为 3。
答案B
1.9🎁 字符串数组strcmp

在 C 语言中,字符串不能直接使用关系运算符(如>、<等)进行比较,需要使用strcmp函数来比较。
strcmp函数的原型为int strcmp(const char *s1, const char *s2) ,它会对两个字符串从左到右逐个字符比较 ASCII 码值。
当s1和s2相等时,函数返回 0。
当s1大于s2(即s1中第一个不相等字符的 ASCII 码值大于s2中对应字符的 ASCII 码值 )时,函数返回一个大于 0 的值。
当s1小于s2时,函数返回一个小于 0 的值。
要判断字符串s1是否大于字符串s2,就需要判断strcmp(s1, s2)的返回值是否大于 0。
答案 D
注意它有三种返回情况
二、代码分析题
2.1🎁 统计单词个数

c1 = s[i]; 获取当前字符,c2 在当前字符不是字符串第一个字符时获取前一个字符(当 i == 0 时,将 c2 初始化为空格 )。
选项 A c1 == ’ ’ && c2 == ’ ’ 表示当前字符和前一个字符都是空格,不符合判断新单词的逻辑。
选项 B c1 != ’ ’ && c2 == ’ ’ ,即当前字符不是空格,而前一个字符是空格,说明遇到了一个新单词,符合统计单词数量的逻辑。
选项 C c1 == ’ ’ && c2 != ’ ’ 表示当前字符是空格,前一个字符不是空格,这是单词结束的情况,不是判断新单词的条件。
选项 D c1 != ’ ’ && c2 != ’ ’ 表示当前字符和前一个字符都不是空格,也不符合判断新单词的条件。
答案B
关键在于单词与单词之间用空格分隔。当遇到一个非空格字符,且它的前一个字符是空格时,就表示遇到了一个新单词。
2.2🎁 字符串strcat,小心i++

程序中首先定义了两个字符数组 a 初始化为 “AB” , b 初始化为 “LMNP” ,并初始化 i = 0 。
然后使用 strcat(a, b); 函数,该函数的作用是将字符串 b 连接到字符串 a 的末尾,执行后 a 的内容变为 “ABLMNP” 。
接着执行 while(a[i++] != ‘\0’) b[i]=a[i]; ,在这个循环中:
第一次循环,a[0] 是 ‘A’ ,此时 i 先取值为 0 参与判断,然后自增为 1 ,但 b[i]=a[i] 即 b[1]=a[1] ,把 a 中的 ‘B’ 赋值给了 b 的第二个位置 。
后续循环继续,直到遇到 a 中的字符串结束符 ‘\0’ ,但由于 i 自增的特性,会导致 b 中原本的首字符 ‘L’ 保留,后面的字符被 a 中除首字符外的内容覆盖。最终 b 的内容变为 “LBLMNP” 。
最后 puts(b); 输出字符串 b 。
答案D
2.3🎁 字符串输出puts,注意下标和位序

程序定义字符数组a初始化为"morming",字符变量t,整型变量i和j(j初始为0)。
for循环从i = 1到i < 7,if(a[j]<a[i]) j = i; 这个语句会遍历数组,找到a[0]到a[6]中 ASCII 码值最大的字符,将其下标赋给j。
初始j = 0,a[0]=‘m’。当i = 1时,a[1]=‘o’,‘m’ < ‘o’,所以j更新为1。
后续继续比较,最终j会指向’r’(ASCII 码相对较大)的下标,这里假设j最终为2(实际执行会根据比较过程确定) 。
接着执行 t = a[j]; a[j]=a[7]; a[7]=t; ,这里代码存在数组越界问题,因为数组a实际有效长度为 7,但访问了a[7]。不过从逻辑上看,目的是把找到的最大字符与末尾字符交换。而由于访问越界,a[7]是不确定值,在很多环境下可能是’\0’ 。
执行交换后,假设a[7]是’\0’,那么原本最大字符的位置就被’\0’覆盖了。puts(a)函数输出字符串时,遇到’\0’就会停止。最初a[0]到a[1]为’m’和’o’,遇到’\0’后输出终止。
答案B
a[7]是’\0’ ,a[6]是g,长度是7的字符串,最后一个字符在下标为6的位置。别马虎!
2.4 常量表达式
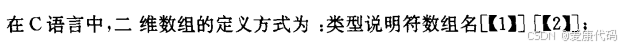
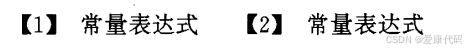
2.5 二维数组的位置

别写成这样了 a[0][0]+i*m+j
要这样
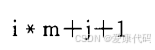
2.6十进制转n进制

【1】
%:十进制转进制时,通过取余获取每一位的余数,存入num数组。
【2】/:每次用除法更新n,去掉已处理的最低位。
【3】j = i - 1; j >= 0; j--:由于取余是从低位到高位存储,输出需逆序,从最后一个有效元素(i-1)遍历到0。
高位和低位是描述数字中不同数位权重的概念:
- 高位:数字中权重较大的数位,位置偏左。例如十进制数
123,百位的1是高位,代表1×100;二进制数101中,最左侧的1是高位,代表1×2²。 - 低位:数字中权重较小的数位,位置偏右。如十进制
123的个位3,代表3×1;二进制101最右侧的1,代表1×2⁰。
在计算机存储中,多字节数据也分高低位。例如 16 位整数 0x1234,0x12 是高位字节,0x34 是低位字节,存储时遵循大端(高位在前)或小端(低位在前)规则。
2.7打印数阵
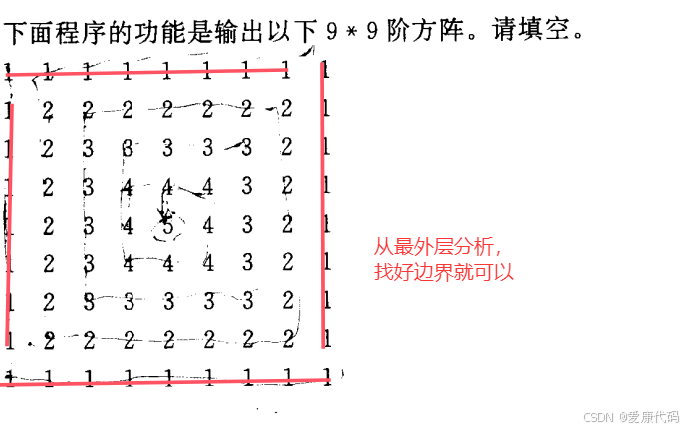

【1】m=(n+1)/2:当n为奇数时,计算中间层数,如n=9时,m=(9+1)/2=5,覆盖对称填充的范围。
【2】n-1-i:上下对称填充,a[n-1-i][j]与a[i][j]对应。
【3】n-1-i:左右对称填充,a[j][n-1-i]与其他位置形成对称关系。
2.8 用数组统计不同年龄人数

【1】if(age >= 16 && age <= 31) a[age - 16]++
分析:输入年龄后,判断是否在16~31岁区间,若是则对应数组位置(age - 16)计数加1。
【2】i = 16; i <= 31
分析:遍历16~31岁,输出每个年龄的统计人数,i表示年龄,通过a[i - 16]获取对应计数。
2.9 检查对称数组


【1】i = j:检查二维数组对称性时,只需遍历上三角(或下三角)部分,避免重复比较,因此内层循环从 i = j 开始。
【2】found = 1:当发现 a[j][i] != a[i][j] 时,说明数组不对称,标记 found 为 1。
第一个空别填i=0;因为这样重复比较了,只需要遍历上三角就可以了!
2.10快速顺序查找法

【1】a[8] = x:快速顺序查找法中,先将关键字存入数组末尾,简化查找时的边界判断。
【2】i < 8:若循环结束后 i < 8,说明找到的是数组原有元素(而非末尾添加的关键字),即查找成功。
2.11字符串的长度

答案:9 这样数a b \n \ 0 1 2 \ "
再比如"ab\n\012\“” 这样的字符串是6,\012算一个
2.12三个字符串比大小 借助函数

答案:
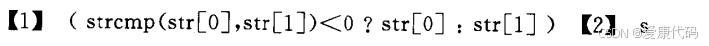
2.13 字符运算

- 初始化二维字符数组
n[2][LEN+1] = {"8980", "9198"}。 - 循环从
j = LEN-1(即j=3)倒序处理:- 对每个
j,计算c = n[0][j] + n[1][j] - 2 * '0'(将字符转为数字相加)。 - 取
c % 10作为新值(只保留个位),转换为字符存回n[0][j]。
- 对每个
- 处理后:
n[0]变为"7078",n[1]保持"9198"。
- 最终输出
n[0]和n[1]。
运行结果:
7078
9198
提别篇:24个英文字母


















 397
397

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











