







损失函数:衡量模型输出和标签之间的差异
nn.CrossEntropyLoss()
-->
def cross_entropy(
input: Tensor,
target: Tensor,
weight: Optional[Tensor] = None,
size_average: Optional[bool] = None,
ignore_index: int = -100,
reduce: Optional[bool] = None,
reduction: str = "mean",
label_smoothing: float = 0.0,
) -> Tensorinput:网络输出
target:标签
reduction:默认为none,有none,sum,mean三种模式
loss_f_none = nn.CrossEntropyLoss(weight=None, reduction='none')
loss_f_sum = nn.CrossEntropyLoss(weight=None, reduction='sum')
loss_f_mean = nn.CrossEntropyLoss(weight=None, reduction='mean')
# forward
loss_none = loss_f_none(inputs, target)
loss_sum = loss_f_sum(inputs, target)
loss_mean = loss_f_mean(inputs, target)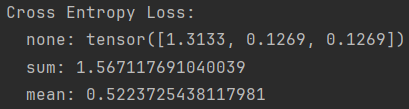
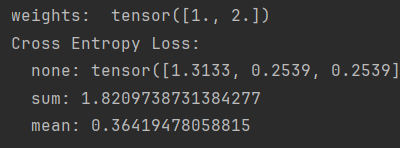
weight:对不同类别的loss设置权重 将第一类的权重设为1,第二类的权重设为2,
则总类别数=第一类别数*权重1+第二类别数*权重2
当第一个样本为类别1,第二、三个样本为类别2,权重为[1,2]时
nn.NLLLoss()
def nll_loss(
input: Tensor,
target: Tensor,
weight: Optional[Tensor] = None,
size_average: Optional[bool] = None,
ignore_index: int = -100,
reduce: Optional[bool] = None,
reduction: str = "mean",
) -> Tensor参数和交叉熵类似
loss_f_none_w = nn.NLLLoss(weight=weights, reduction='none')
loss_f_sum = nn.NLLLoss(weight=weights, reduction='sum')
loss_f_mean = nn.NLLLoss(weight=weights, reduction='mean')
# forward
loss_none_w = loss_f_none_w(inputs, target)
loss_sum = loss_f_sum(inputs, target)
loss_mean = loss_f_mean(inputs, target)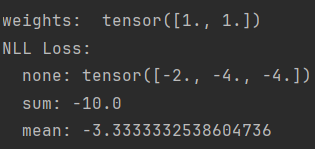
nn.BCELoss()
def binary_cross_entropy(
input: Tensor,
target: Tensor,
weight: Optional[Tensor] = None,
size_average: Optional[bool] = None,
reduce: Optional[bool] = None,
reduction: str = "mean",
) -> Tensor参数同上
weights = torch.tensor([1, 1], dtype=torch.float)
loss_f_none_w = nn.BCELoss(weight=weights, reduction='none')
loss_f_sum = nn.BCELoss(weight=weights, reduction='sum')
loss_f_mean = nn.BCELoss(weight=weights, reduction='mean')
# forward
loss_none_w = loss_f_none_w(inputs, target_bce)
loss_sum = loss_f_sum(inputs, target_bce)
loss_mean = loss_f_mean(inputs, target_bce)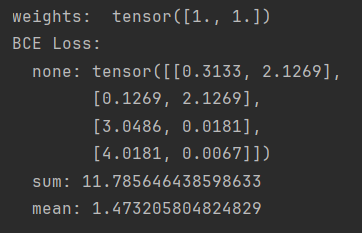
nn.BCEWithLogitsLoss
和BCEloss相同,区别在于在此激活函数前不要加激活函数
def __init__(self, weight: Optional[Tensor] = None, size_average=None, reduce=None, reduction: str = 'mean',
pos_weight: Optional[Tensor] = None) -> None:
super().__init__(size_average, reduce, reduction)
self.register_buffer('weight', weight)
self.register_buffer('pos_weight', pos_weight)
self.weight: Optional[Tensor]
self.pos_weight: Optional[Tensor]pos_weight:可以改变正样本的权值
weights = torch.tensor([1], dtype=torch.float)
pos_w = torch.tensor([3], dtype=torch.float) # 3
loss_f_none_w = nn.BCEWithLogitsLoss(weight=weights, reduction='none', pos_weight=pos_w)
loss_f_sum = nn.BCEWithLogitsLoss(weight=weights, reduction='sum', pos_weight=pos_w)
loss_f_mean = nn.BCEWithLogitsLoss(weight=weights, reduction='mean', pos_weight=pos_w)
# forward
loss_none_w = loss_f_none_w(inputs, target_bce)
loss_sum = loss_f_sum(inputs, target_bce)
loss_mean = loss_f_mean(inputs, target_bce)
nn.L1Loss()
"""Examples::
>>> loss = nn.L1Loss()
>>> input = torch.randn(3, 5, requires_grad=True)
>>> target = torch.randn(3, 5)
>>> output = loss(input, target)
>>> output.backward()
"""
__constants__ = ['reduction']
def __init__(self, size_average=None, reduce=None, reduction: str = 'mean') -> None:
super().__init__(size_average, reduce, reduction)
def forward(self, input: Tensor, target: Tensor) -> Tensor:
return F.l1_loss(input, target, reduction=self.reduction)参数同上
nn.MSELoss()
"""Examples::
>>> loss = nn.MSELoss()
>>> input = torch.randn(3, 5, requires_grad=True)
>>> target = torch.randn(3, 5)
>>> output = loss(input, target)
>>> output.backward()
"""
__constants__ = ['reduction']
def __init__(self, size_average=None, reduce=None, reduction: str = 'mean') -> None:
super().__init__(size_average, reduce, reduction)
def forward(self, input: Tensor, target: Tensor) -> Tensor:
return F.mse_loss(input, target, reduction=self.reduction)参数同上
nn.SmoothL1Loss()
""".. _`Fast R-CNN`: https://arxiv.org/abs/1504.08083
Args:
size_average (bool, optional): Deprecated (see :attr:`reduction`). By default,
the losses are averaged over each loss element in the batch. Note that for
some losses, there are multiple elements per sample. If the field :attr:`size_average`
is set to ``False``, the losses are instead summed for each minibatch. Ignored
when :attr:`reduce` is ``False``. Default: ``True``
reduce (bool, optional): Deprecated (see :attr:`reduction`). By default, the
losses are averaged or summed over observations for each minibatch depending
on :attr:`size_average`. When :attr:`reduce` is ``False``, returns a loss per
batch element instead and ignores :attr:`size_average`. Default: ``True``
reduction (str, optional): Specifies the reduction to apply to the output:
``'none'`` | ``'mean'`` | ``'sum'``. ``'none'``: no reduction will be applied,
``'mean'``: the sum of the output will be divided by the number of
elements in the output, ``'sum'``: the output will be summed. Note: :attr:`size_average`
and :attr:`reduce` are in the process of being deprecated, and in the meantime,
specifying either of those two args will override :attr:`reduction`. Default: ``'mean'``
beta (float, optional): Specifies the threshold at which to change between L1 and L2 loss.
The value must be non-negative. Default: 1.0
Shape:
- Input: :math:`(*)`, where :math:`*` means any number of dimensions.
- Target: :math:`(*)`, same shape as the input.
- Output: scalar. If :attr:`reduction` is ``'none'``, then :math:`(*)`, same shape as the input.
"""
__constants__ = ['reduction']
def __init__(self, size_average=None, reduce=None, reduction: str = 'mean', beta: float = 1.0) -> None:
super().__init__(size_average, reduce, reduction)
self.beta = beta
def forward(self, input: Tensor, target: Tensor) -> Tensor:
return F.smooth_l1_loss(input, target, reduction=self.reduction, beta=self.beta)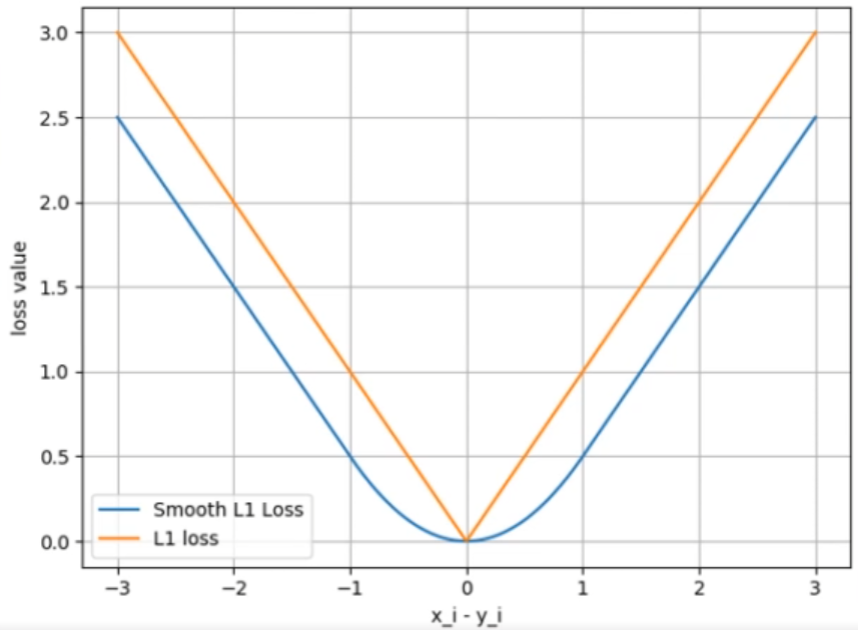
nn.PoissonNLLLoss()
泊松分布的负对数似然函数
__constants__ = ['log_input', 'full', 'eps', 'reduction']
log_input: bool
full: bool
eps: float
def __init__(self, log_input: bool = True, full: bool = False, size_average=None,
eps: float = 1e-8, reduce=None, reduction: str = 'mean') -> None:
super().__init__(size_average, reduce, reduction)
self.log_input = log_input
self.full = full
self.eps = epseps:极小数,1e-8
log_input:为True时,第一个公式;为False时,第二个公式
nn.KLDivLoss()
计算KL散度
在计算之前x要提前经过F.log_softmax()
""" Examples::
>>> import torch.nn.functional as F
>>> kl_loss = nn.KLDivLoss(reduction="batchmean")
>>> # input should be a distribution in the log space
>>> input = F.log_softmax(torch.randn(3, 5, requires_grad=True), dim=1)
>>> # Sample a batch of distributions. Usually this would come from the dataset
>>> target = F.softmax(torch.rand(3, 5), dim=1)
>>> output = kl_loss(input, target)
>>> kl_loss = nn.KLDivLoss(reduction="batchmean", log_target=True)
>>> log_target = F.log_softmax(torch.rand(3, 5), dim=1)
>>> output = kl_loss(input, log_target)
"""
__constants__ = ['reduction']
def __init__(self, size_average=None, reduce=None, reduction: str = 'mean', log_target: bool = False) -> None:
super().__init__(size_average, reduce, reduction)
self.log_target = log_target
def forward(self, input: Tensor, target: Tensor) -> Tensor:
return F.kl_div(input, target, reduction=self.reduction, log_target=self.log_target)reduction:多了一个batchmean,即求和后除以batch_size
nn.MarginRankingLoss()
计算两个向量之间的相似度,用于排序任务
y有两种取值:-1,1
y=1时,希望x1比x2大,当x1>x2时,loss=0
y=-1时,希望x2比x1大,当x2>x1时,loss=0
"""Examples::
>>> loss = nn.MarginRankingLoss()
>>> input1 = torch.randn(3, requires_grad=True)
>>> input2 = torch.randn(3, requires_grad=True)
>>> target = torch.randn(3).sign()
>>> output = loss(input1, input2, target)
>>> output.backward()
"""
__constants__ = ['margin', 'reduction']
margin: float
def __init__(self, margin: float = 0., size_average=None, reduce=None, reduction: str = 'mean') -> None:
super().__init__(size_average, reduce, reduction)
self.margin = margin
def forward(self, input1: Tensor, input2: Tensor, target: Tensor) -> Tensor:
return F.margin_ranking_loss(input1, input2, target, margin=self.margin, reduction=self.reduction)三个输入,返回的是tensor
nn.MultiLabelMarginLoss()
多标签边界损失函数
一个样本具有多个标签
""" Examples::
>>> loss = nn.MultiLabelMarginLoss()
>>> x = torch.FloatTensor([[0.1, 0.2, 0.4, 0.8]])
>>> # for target y, only consider labels 3 and 0, not after label -1
>>> y = torch.LongTensor([[3, 0, -1, 1]])
>>> # 0.25 * ((1-(0.1-0.2)) + (1-(0.1-0.4)) + (1-(0.8-0.2)) + (1-(0.8-0.4)))
>>> loss(x, y)
tensor(0.85...)
"""
__constants__ = ['reduction']
def __init__(self, size_average=None, reduce=None, reduction: str = 'mean') -> None:
super().__init__(size_average, reduce, reduction)
def forward(self, input: Tensor, target: Tensor) -> Tensor:
return F.multilabel_margin_loss(input, target, reduction=self.reduction)nn.SoftMarginLoss()
计算二分类的逻辑损失
class SoftMarginLoss(_Loss):
r"""Creates a criterion that optimizes a two-class classification
logistic loss between input tensor :math:`x` and target tensor :math:`y`
(containing 1 or -1).
.. math::
\text{loss}(x, y) = \sum_i \frac{\log(1 + \exp(-y[i]*x[i]))}{\text{x.nelement}()}
Args:
size_average (bool, optional): Deprecated (see :attr:`reduction`). By default,
the losses are averaged over each loss element in the batch. Note that for
some losses, there are multiple elements per sample. If the field :attr:`size_average`
is set to ``False``, the losses are instead summed for each minibatch. Ignored
when :attr:`reduce` is ``False``. Default: ``True``
reduce (bool, optional): Deprecated (see :attr:`reduction`). By default, the
losses are averaged or summed over observations for each minibatch depending
on :attr:`size_average`. When :attr:`reduce` is ``False``, returns a loss per
batch element instead and ignores :attr:`size_average`. Default: ``True``
reduction (str, optional): Specifies the reduction to apply to the output:
``'none'`` | ``'mean'`` | ``'sum'``. ``'none'``: no reduction will be applied,
``'mean'``: the sum of the output will be divided by the number of
elements in the output, ``'sum'``: the output will be summed. Note: :attr:`size_average`
and :attr:`reduce` are in the process of being deprecated, and in the meantime,
specifying either of those two args will override :attr:`reduction`. Default: ``'mean'``
Shape:
- Input: :math:`(*)`, where :math:`*` means any number of dimensions.
- Target: :math:`(*)`, same shape as the input.
- Output: scalar. If :attr:`reduction` is ``'none'``, then :math:`(*)`, same
shape as input.
"""
__constants__ = ['reduction']
def __init__(self, size_average=None, reduce=None, reduction: str = 'mean') -> None:
super().__init__(size_average, reduce, reduction)
def forward(self, input: Tensor, target: Tensor) -> Tensor:
return F.soft_margin_loss(input, target, reduction=self.reduction)nn.MultiLabelSoftMarginLoss()
nn.SoftMarginLoss()的多标签版本
C:类别个数
class MultiLabelSoftMarginLoss(_WeightedLoss):
r"""Creates a criterion that optimizes a multi-label one-versus-all
loss based on max-entropy, between input :math:`x` and target :math:`y` of size
:math:`(N, C)`.
For each sample in the minibatch:
.. math::
loss(x, y) = - \frac{1}{C} * \sum_i y[i] * \log((1 + \exp(-x[i]))^{-1})
+ (1-y[i]) * \log\left(\frac{\exp(-x[i])}{(1 + \exp(-x[i]))}\right)
where :math:`i \in \left\{0, \; \cdots , \; \text{x.nElement}() - 1\right\}`,
:math:`y[i] \in \left\{0, \; 1\right\}`.
Args:
weight (Tensor, optional): a manual rescaling weight given to each
class. If given, it has to be a Tensor of size `C`. Otherwise, it is
treated as if having all ones.
size_average (bool, optional): Deprecated (see :attr:`reduction`). By default,
the losses are averaged over each loss element in the batch. Note that for
some losses, there are multiple elements per sample. If the field :attr:`size_average`
is set to ``False``, the losses are instead summed for each minibatch. Ignored
when :attr:`reduce` is ``False``. Default: ``True``
reduce (bool, optional): Deprecated (see :attr:`reduction`). By default, the
losses are averaged or summed over observations for each minibatch depending
on :attr:`size_average`. When :attr:`reduce` is ``False``, returns a loss per
batch element instead and ignores :attr:`size_average`. Default: ``True``
reduction (str, optional): Specifies the reduction to apply to the output:
``'none'`` | ``'mean'`` | ``'sum'``. ``'none'``: no reduction will be applied,
``'mean'``: the sum of the output will be divided by the number of
elements in the output, ``'sum'``: the output will be summed. Note: :attr:`size_average`
and :attr:`reduce` are in the process of being deprecated, and in the meantime,
specifying either of those two args will override :attr:`reduction`. Default: ``'mean'``
Shape:
- Input: :math:`(N, C)` where `N` is the batch size and `C` is the number of classes.
- Target: :math:`(N, C)`, label targets must have the same shape as the input.
- Output: scalar. If :attr:`reduction` is ``'none'``, then :math:`(N)`.
"""
__constants__ = ['reduction']
def __init__(self, weight: Optional[Tensor] = None, size_average=None, reduce=None, reduction: str = 'mean') -> None:
super().__init__(weight, size_average, reduce, reduction)
def forward(self, input: Tensor, target: Tensor) -> Tensor:
return F.multilabel_soft_margin_loss(input, target, weight=self.weight, reduction=self.reduction)nn.MultiMarginLoss()
多分类折页损失
""" Examples::
>>> loss = nn.MultiMarginLoss()
>>> x = torch.tensor([[0.1, 0.2, 0.4, 0.8]])
>>> y = torch.tensor([3])
>>> # 0.25 * ((1-(0.8-0.1)) + (1-(0.8-0.2)) + (1-(0.8-0.4)))
>>> loss(x, y)
tensor(0.32...)
"""
__constants__ = ['p', 'margin', 'reduction']
margin: float
p: int
def __init__(self, p: int = 1, margin: float = 1., weight: Optional[Tensor] = None, size_average=None,
reduce=None, reduction: str = 'mean') -> None:
super().__init__(weight, size_average, reduce, reduction)
if p != 1 and p != 2:
raise ValueError("only p == 1 and p == 2 supported")
if weight is not None and weight.dim() != 1 :
raise ValueError(
f"MultiMarginLoss: expected weight to be None or 1D tensor, got {weight.dim()}D instead"
)
self.p = p
self.margin = margin
def forward(self, input: Tensor, target: Tensor) -> Tensor:
return F.multi_margin_loss(input, target, p=self.p, margin=self.margin,
weight=self.weight, reduction=self.reduction)p:为1或2
margin:边界值
reduction:模式
nn.TripletMarginLoss()
计算三元组损失函数,人脸识别中常用,让正向比负向距离锚点更近
"""Examples::
>>> triplet_loss = nn.TripletMarginLoss(margin=1.0, p=2, eps=1e-7)
>>> anchor = torch.randn(100, 128, requires_grad=True)
>>> positive = torch.randn(100, 128, requires_grad=True)
>>> negative = torch.randn(100, 128, requires_grad=True)
>>> output = triplet_loss(anchor, positive, negative)
>>> output.backward()
.. _Learning shallow convolutional feature descriptors with triplet losses:
http://www.bmva.org/bmvc/2016/papers/paper119/index.html
"""
__constants__ = ['margin', 'p', 'eps', 'swap', 'reduction']
margin: float
p: float
eps: float
swap: bool
def __init__(self, margin: float = 1.0, p: float = 2., eps: float = 1e-6, swap: bool = False, size_average=None,
reduce=None, reduction: str = 'mean'):
super().__init__(size_average, reduce, reduction)
self.margin = margin
self.p = p
self.eps = eps
self.swap = swap
def forward(self, anchor: Tensor, positive: Tensor, negative: Tensor) -> Tensor:
return F.triplet_margin_loss(anchor, positive, negative, margin=self.margin, p=self.p,
eps=self.eps, swap=self.swap, reduction=self.reduction)nn.HingeEmbeddingLoss()
计算两个输入的相似性,常用于非线性embedding和半监督学习
损失函数的输入应为两个输入之差的绝对值
""" Args:
margin (float, optional): Has a default value of `1`.
size_average (bool, optional): Deprecated (see :attr:`reduction`). By default,
the losses are averaged over each loss element in the batch. Note that for
some losses, there are multiple elements per sample. If the field :attr:`size_average`
is set to ``False``, the losses are instead summed for each minibatch. Ignored
when :attr:`reduce` is ``False``. Default: ``True``
reduce (bool, optional): Deprecated (see :attr:`reduction`). By default, the
losses are averaged or summed over observations for each minibatch depending
on :attr:`size_average`. When :attr:`reduce` is ``False``, returns a loss per
batch element instead and ignores :attr:`size_average`. Default: ``True``
reduction (str, optional): Specifies the reduction to apply to the output:
``'none'`` | ``'mean'`` | ``'sum'``. ``'none'``: no reduction will be applied,
``'mean'``: the sum of the output will be divided by the number of
elements in the output, ``'sum'``: the output will be summed. Note: :attr:`size_average`
and :attr:`reduce` are in the process of being deprecated, and in the meantime,
specifying either of those two args will override :attr:`reduction`. Default: ``'mean'``
Shape:
- Input: :math:`(*)` where :math:`*` means, any number of dimensions. The sum operation
operates over all the elements.
- Target: :math:`(*)`, same shape as the input
- Output: scalar. If :attr:`reduction` is ``'none'``, then same shape as the input
"""
__constants__ = ['margin', 'reduction']
margin: float
def __init__(self, margin: float = 1.0, size_average=None, reduce=None, reduction: str = 'mean') -> None:
super().__init__(size_average, reduce, reduction)
self.margin = margin
def forward(self, input: Tensor, target: Tensor) -> Tensor:
return F.hinge_embedding_loss(input, target, margin=self.margin, reduction=self.reduction)nn.CosineEmbeddingLoss()
计算两个输入的余弦相似度
"""Args:
margin (float, optional): Should be a number from :math:`-1` to :math:`1`,
:math:`0` to :math:`0.5` is suggested. If :attr:`margin` is missing, the
default value is :math:`0`.
size_average (bool, optional): Deprecated (see :attr:`reduction`). By default,
the losses are averaged over each loss element in the batch. Note that for
some losses, there are multiple elements per sample. If the field :attr:`size_average`
is set to ``False``, the losses are instead summed for each minibatch. Ignored
when :attr:`reduce` is ``False``. Default: ``True``
reduce (bool, optional): Deprecated (see :attr:`reduction`). By default, the
losses are averaged or summed over observations for each minibatch depending
on :attr:`size_average`. When :attr:`reduce` is ``False``, returns a loss per
batch element instead and ignores :attr:`size_average`. Default: ``True``
reduction (str, optional): Specifies the reduction to apply to the output:
``'none'`` | ``'mean'`` | ``'sum'``. ``'none'``: no reduction will be applied,
``'mean'``: the sum of the output will be divided by the number of
elements in the output, ``'sum'``: the output will be summed. Note: :attr:`size_average`
and :attr:`reduce` are in the process of being deprecated, and in the meantime,
specifying either of those two args will override :attr:`reduction`. Default: ``'mean'``
Shape:
- Input1: :math:`(N, D)` or :math:`(D)`, where `N` is the batch size and `D` is the embedding dimension.
- Input2: :math:`(N, D)` or :math:`(D)`, same shape as Input1.
- Target: :math:`(N)` or :math:`()`.
- Output: If :attr:`reduction` is ``'none'``, then :math:`(N)`, otherwise scalar.
"""
__constants__ = ['margin', 'reduction']
margin: float
def __init__(self, margin: float = 0., size_average=None, reduce=None, reduction: str = 'mean') -> None:
super().__init__(size_average, reduce, reduction)
self.margin = margin
def forward(self, input1: Tensor, input2: Tensor, target: Tensor) -> Tensor:
return F.cosine_embedding_loss(input1, input2, target, margin=self.margin, reduction=self.reduction)margin:取[-1,1]推荐[0,0.5]
nn.CTCLoss()
class CTCLoss(_Loss):
r"""The Connectionist Temporal Classification loss.
Calculates loss between a continuous (unsegmented) time series and a target sequence. CTCLoss sums over the
probability of possible alignments of input to target, producing a loss value which is differentiable
with respect to each input node. The alignment of input to target is assumed to be "many-to-one", which
limits the length of the target sequence such that it must be :math:`\leq` the input length.
Args:
blank (int, optional): blank label. Default :math:`0`.
reduction (str, optional): Specifies the reduction to apply to the output:
``'none'`` | ``'mean'`` | ``'sum'``. ``'none'``: no reduction will be applied,
``'mean'``: the output losses will be divided by the target lengths and
then the mean over the batch is taken, ``'sum'``: the output losses will be summed.
Default: ``'mean'``
zero_infinity (bool, optional):
Whether to zero infinite losses and the associated gradients.
Default: ``False``
Infinite losses mainly occur when the inputs are too short
to be aligned to the targets.
Shape:
- Log_probs: Tensor of size :math:`(T, N, C)` or :math:`(T, C)`,
where :math:`T = \text{input length}`,
:math:`N = \text{batch size}`, and
:math:`C = \text{number of classes (including blank)}`.
The logarithmized probabilities of the outputs (e.g. obtained with
:func:`torch.nn.functional.log_softmax`).
- Targets: Tensor of size :math:`(N, S)` or
:math:`(\operatorname{sum}(\text{target\_lengths}))`,
where :math:`N = \text{batch size}` and
:math:`S = \text{max target length, if shape is } (N, S)`.
It represent the target sequences. Each element in the target
sequence is a class index. And the target index cannot be blank (default=0).
In the :math:`(N, S)` form, targets are padded to the
length of the longest sequence, and stacked.
In the :math:`(\operatorname{sum}(\text{target\_lengths}))` form,
the targets are assumed to be un-padded and
concatenated within 1 dimension.
- Input_lengths: Tuple or tensor of size :math:`(N)` or :math:`()`,
where :math:`N = \text{batch size}`. It represent the lengths of the
inputs (must each be :math:`\leq T`). And the lengths are specified
for each sequence to achieve masking under the assumption that sequences
are padded to equal lengths.
- Target_lengths: Tuple or tensor of size :math:`(N)` or :math:`()`,
where :math:`N = \text{batch size}`. It represent lengths of the targets.
Lengths are specified for each sequence to achieve masking under the
assumption that sequences are padded to equal lengths. If target shape is
:math:`(N,S)`, target_lengths are effectively the stop index
:math:`s_n` for each target sequence, such that ``target_n = targets[n,0:s_n]`` for
each target in a batch. Lengths must each be :math:`\leq S`
If the targets are given as a 1d tensor that is the concatenation of individual
targets, the target_lengths must add up to the total length of the tensor.
- Output: scalar if :attr:`reduction` is ``'mean'`` (default) or
``'sum'``. If :attr:`reduction` is ``'none'``, then :math:`(N)` if input is batched or
:math:`()` if input is unbatched, where :math:`N = \text{batch size}`.
Examples::
>>> # Target are to be padded
>>> T = 50 # Input sequence length
>>> C = 20 # Number of classes (including blank)
>>> N = 16 # Batch size
>>> S = 30 # Target sequence length of longest target in batch (padding length)
>>> S_min = 10 # Minimum target length, for demonstration purposes
>>>
>>> # Initialize random batch of input vectors, for *size = (T,N,C)
>>> input = torch.randn(T, N, C).log_softmax(2).detach().requires_grad_()
>>>
>>> # Initialize random batch of targets (0 = blank, 1:C = classes)
>>> target = torch.randint(low=1, high=C, size=(N, S), dtype=torch.long)
>>>
>>> input_lengths = torch.full(size=(N,), fill_value=T, dtype=torch.long)
>>> target_lengths = torch.randint(low=S_min, high=S, size=(N,), dtype=torch.long)
>>> ctc_loss = nn.CTCLoss()
>>> loss = ctc_loss(input, target, input_lengths, target_lengths)
>>> loss.backward()
>>>
>>>
>>> # Target are to be un-padded
>>> T = 50 # Input sequence length
>>> C = 20 # Number of classes (including blank)
>>> N = 16 # Batch size
>>>
>>> # Initialize random batch of input vectors, for *size = (T,N,C)
>>> input = torch.randn(T, N, C).log_softmax(2).detach().requires_grad_()
>>> input_lengths = torch.full(size=(N,), fill_value=T, dtype=torch.long)
>>>
>>> # Initialize random batch of targets (0 = blank, 1:C = classes)
>>> target_lengths = torch.randint(low=1, high=T, size=(N,), dtype=torch.long)
>>> target = torch.randint(low=1, high=C, size=(sum(target_lengths),), dtype=torch.long)
>>> ctc_loss = nn.CTCLoss()
>>> loss = ctc_loss(input, target, input_lengths, target_lengths)
>>> loss.backward()
>>>
>>>
>>> # Target are to be un-padded and unbatched (effectively N=1)
>>> T = 50 # Input sequence length
>>> C = 20 # Number of classes (including blank)
>>>
>>> # Initialize random batch of input vectors, for *size = (T,C)
>>> # xdoctest: +SKIP("FIXME: error in doctest")
>>> input = torch.randn(T, C).log_softmax(1).detach().requires_grad_()
>>> input_lengths = torch.tensor(T, dtype=torch.long)
>>>
>>> # Initialize random batch of targets (0 = blank, 1:C = classes)
>>> target_lengths = torch.randint(low=1, high=T, size=(), dtype=torch.long)
>>> target = torch.randint(low=1, high=C, size=(target_lengths,), dtype=torch.long)
>>> ctc_loss = nn.CTCLoss()
>>> loss = ctc_loss(input, target, input_lengths, target_lengths)
>>> loss.backward()
Reference:
A. Graves et al.: Connectionist Temporal Classification:
Labelling Unsegmented Sequence Data with Recurrent Neural Networks:
https://www.cs.toronto.edu/~graves/icml_2006.pdf
Note:
In order to use CuDNN, the following must be satisfied: :attr:`targets` must be
in concatenated format, all :attr:`input_lengths` must be `T`. :math:`blank=0`,
:attr:`target_lengths` :math:`\leq 256`, the integer arguments must be of
dtype :attr:`torch.int32`.
The regular implementation uses the (more common in PyTorch) `torch.long` dtype.
Note:
In some circumstances when using the CUDA backend with CuDNN, this operator
may select a nondeterministic algorithm to increase performance. If this is
undesirable, you can try to make the operation deterministic (potentially at
a performance cost) by setting ``torch.backends.cudnn.deterministic =
True``.
Please see the notes on :doc:`/notes/randomness` for background.
"""
__constants__ = ['blank', 'reduction']
blank: int
zero_infinity: bool
def __init__(self, blank: int = 0, reduction: str = 'mean', zero_infinity: bool = False):
super().__init__(reduction=reduction)
self.blank = blank
self.zero_infinity = zero_infinity
def forward(self, log_probs: Tensor, targets: Tensor, input_lengths: Tensor, target_lengths: Tensor) -> Tensor:
return F.ctc_loss(log_probs, targets, input_lengths, target_lengths, self.blank, self.reduction,
self.zero_infinity)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









