






Background
自从Chat-GPT发布以来,国内外的LLM的军备竞赛正在如火如荼的进行。LLM的综合能力在不断的提升,提升速度也在增加,LLM表现的一些问题也在凸显出来,其中一个比较严重的问题就是“幻觉问题”,Hallucination。
Hallucination:大模型生成的内容听起来有道理,但是实际却是不切实际、没有意义的。
这个问题日常生活中的使用中影响没有那么严重,但是在专业领域,尤其是对于科学和逻辑理论要求十分严格的领域极为重要,一旦出现错误将是十分严重的后果,因此hallucination是一个十分重要的问题,缓解甚至解决这个问题,对于LLM来说将是质的飞跃。
Introduction
幻觉的定义已经讲过不再赘述。那么给出一个具体的案例形象的理解幻觉问题。下面问的问题是:努南综合症的病因是什么?回答是:努南综合征是由 PTEN 基因突变引起的。该基因负责调节细胞生长和分裂,当它发生突变时,可能会导致努南综合征的发生。
标记红色的部分是不切实际的,没有科学依据的内容。事实上PTEN(磷酸酶和张力蛋白同源物)突变通常与努南综合征无关,所以LLM的回答的不切实际、不科学的内容就是Hallucination现象。

Hallucination in Generative Question Answering
Hallucination现象在于GQA(Generation-Question-Answer)中尤其重要是要解决的,但是大模型的训练和改善基于很多数据集以及其他因素,所以彻底解决目前来看不切实际,但是可以缓解这个现象带来的影响。
Faithful GQA 旨在生成严格基于源文本或有效外部知识的答案,已获得了广泛的研究关注。答案越忠实,其中包含的幻觉内容就越少。其他术语如语义漂移、事实正确性也可以反映幻觉程度。
Experimentation
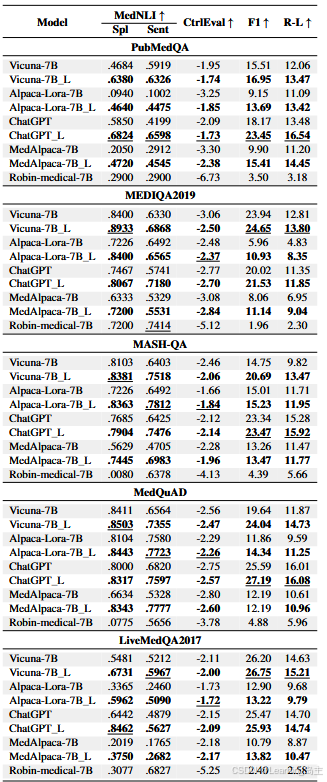
我将实验涉及的数据集和模型以及评估标准以表格的形式展现出来这样更加直观。
实验涉及的数据集
| 数据集 | 描述 | 来源 |
|---|---|---|
| PubMedQA | 包含 1k 专家标注的生物医学问答实例,问题来源于研究文章标题,包含摘要作为上下文,以及来自摘要结论的长答案和简洁的 yes/no/maybe 答案。 | Jin et al., 2019 |
| MedQuAD | 包含 47,457 对来自美国国立卫生研究院(NIH)网站的问答对,涵盖疾病、药物、诊断测试等多个医疗主题。 | Ben Abacha & Demner-Fushman, 2019 |
| MEDIQA2019 | 来自 MEDIQA2019 挑战赛的医疗问答数据集,答案得分为 3 和 4 的被视为黄金答案。 | Ben Abacha et al., 2019 |
| LiveMedQA2017 | 包含用于问题分析和问答系统的注释医疗问答对。 | Ben Abacha et al., 2017 |
| MASH-QA | 包括来自消费者健康领域的 34k 问答对,专为多答案范围(Multiple Answer Spans)医疗问答设计。 | Zhu et al., 2020 |
实验涉及的模型
| 模型名称 | 描述 | 来源 |
|---|---|---|
| Vicuna | 基于 LLaMA 训练,通过对 ShareGPT 中的用户共享对话进行微调训练的模型。 | Chiang et al., 2023 |
| Alpaca-LoRA | 使用低秩适配(LoRA)方法复现 Stanford Alpaca 模型效果。 | Wang, 2023 |
| ChatGPT | 使用人类反馈强化学习(RLHF)优化的通用模型,可解释提示并生成综合性回答。 | OpenAI, 2023 |
| MedAlpaca | 基于 LLaMA 框架,专门在指令微调格式的医疗对话和问答文本上微调。 | Han et al., 2023 |
| Robin-medical | 基于 LLaMA 使用 LMFlow 进行医疗领域微调的模型。 | Diao et al., 2023 |
评估标准
| 评估指标 | 描述 | 来源 |
|---|---|---|
| F1 | 衡量生成答案的精确率与召回率的平衡,适合定量评价生成内容的覆盖程度和准确性。 | Su et al., 2022 |
| ROUGE-L | 基于最长公共子序列(LCS)的文本相似度指标,用于评估生成答案与参考答案的文本重合程度。 | Lin, 2004 |
| Med-NLI | 医学自然语言推理指标,评估生成答案是否与上下文或参考答案在逻辑上一致(包括支持、矛盾、中立)。 | Phan et al., 2021 |
| CTRLEval | 无监督、无参考、任务无关的生成评估指标,针对一致性、流畅性等多个方面进行评估。 | Ke et al., 2022 |
数值越大性能越好。
实验结果:
针对于实验结果产生的问题,大概分为三类:事实不一致、查询不一致和相切性。事实不一致是指答案提供的信息与事实不一致或相冲突。查询不一致是指与查询无关或无意义的答案。切题性是指提供与主题相关的信息但不直接解决问题的答案。
每个模型中不同类型问题出现的原始(幻觉现象优化前)概率。
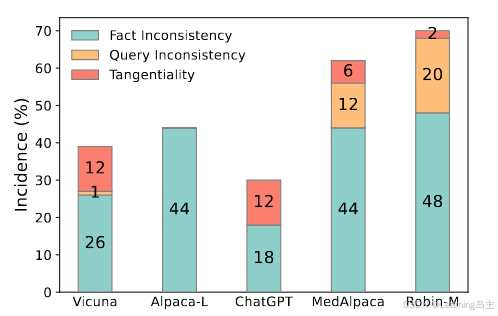
前两类认为属于幻觉问题。下图通过QA的方式体现了三种类别含义。

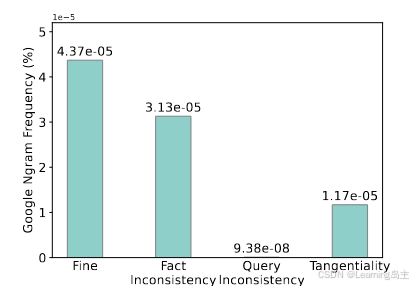
该实验结束后对于幻觉问题的定义,但是同时发现由于使用的实验数据集中每个数据出现的频率的不切实际性,后来又实用Google ngrams4作为自然世界和预训练预料的文本分布代理,然后让LLM随机生成100个样本。精确到词语和句子,最终结果如下图,所以幻觉产生的原因和一些专业词汇的低频性有关系,某个词汇在预料库中出现次数少,对于LLM对其的理解就会出现偏颇,就会产生幻觉的现象。
Hallucination Mitigation Method
为了解决幻觉问题提出了一个自我反思的过程,包括:事实性知识获取循环、知识一致性回答的循环、问题蕴含回答循环。(Factual Knowledge Acquiring Loop, Knowledge-Consistent Answering Loop, and Question-Entailment Answering Loop.)其核心是通过生成-反思-优化的迭代机制,逐步提高生成内容的质量和一致性。
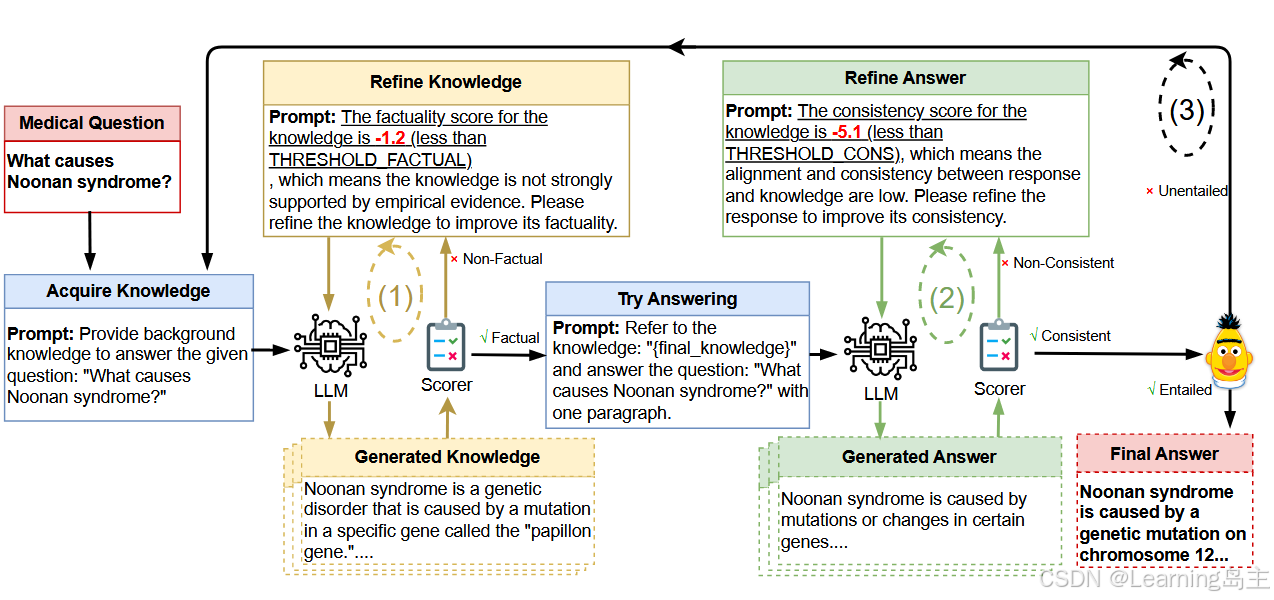
首先,模型根据问题生成初始知识(如 Noonan 综合征的成因),并通过评分机制(Scorer)对生成的知识进行事实性评分;如果评分低于阈值,则通过反馈提示优化知识。随后,模型基于改进后的知识生成初步答案,再次使用评分机制评估答案的一致性。如果一致性评分低,则生成反馈提示,进一步优化答案。这一流程通过“知识优化”和“答案优化”的双循环机制,不断迭代,最终生成逻辑一致且事实准确的高质量答案,减少幻觉问题的发生。
所以我认为这个流程的关键就是使用的语料库和Scorer打分器的构建。
“查询不一致”意味着答案提供与查询无关的信息或者是无意义且无意义的。 “切线”意味着答案提供了与问题相关的信息,但不直接解决问题。 “蕴含”意味着答案直接针对问题。对事实一致性的人工评估是在句子级别进行的,我们要求注释者将答案中的每个句子分类为事实不一致、事实一致或通用。 “事实不一致”意味着答案句子不一致传统或无法通过参考上下文或网站进行验证。“事实一致”是指答案句子得到给定上下文或网站的支持。
经过自我反思循环后各个模型中各个问题类型出现的概率以及之后的综合评估指标数据(结果明显好于经过反思流程之前,有效压制了幻觉现象):
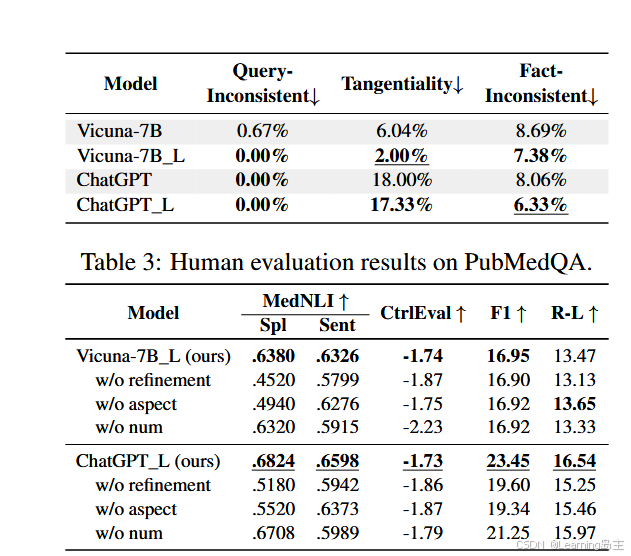
虽然该方法有望减轻幻觉,但并不能完全消除这种可能性。特别是在复杂或模棱两可的情况下,模型仍有可能产生无根据的信息。目前,该方法仍处于早期阶段,还不能直接用于现实世界。它应被视为与检索等其他方法的互补方法,有可能在未来为更强大的应用系统做出贡献。同时研究主要集中在英语医疗查询上,限制了对其他语言、领域和模式的通用性。有必要开展进一步研究,以探讨潜在的特定语言挑战、领域适应挑战和多模态融合挑战。通过解决这些方面的问题,可以使提出的方法适应不同的环境,从而更全面地理解和应用我们的方法,使其适用于不同的语言、多领域和多模态环境。虽然本文已经解决了这一领域的某些问题,但仍存在许多挑战,例如赋予 LLMs 高级能力。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









