






对应文章:《Neural Rays for Occlusion-aware Image-based Rendering》CVPR2022
Q:NeuRay中基于MVSNet生成可见性特征图做重建时,为什么使用的是MVSNet生成的正则化代价体(概率体P),而不是直接使用初始深度图或refine后的深度图?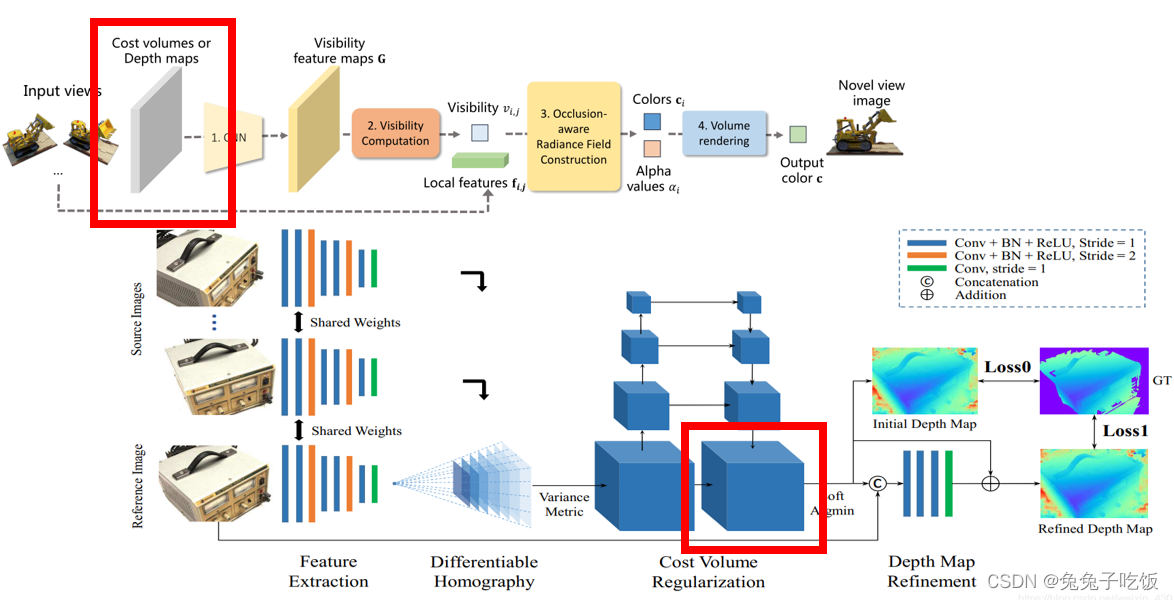
A:当我们有了深度图像后,我们可以通过一个2维的卷积去得到它的深度特征,在此基础上,我们可以建立代价体(cost volumn),并用一个维度来存储视差,对于这个维度,再通过softmax的处理方式,就可以得到不同视差的概率分布,并选择最大值或者期望作为最终估计。为了训练网络,我们可以从lidar中采取真值进行训练。然而,视差和深度存在着反比的关系,这会造成对于远处的物体,微小的视差区别将造成深度估计的很大变化,因此,一种思路是直接用深度而不是视差参与网络和代价体的设计,实验证明,这样确实可以让物体检测的效果显著提升。
然而,深度图的估计因为涉及到代价体的建立,通常需要较长的时间估计。通过降低分辨率的思路设计网络虽然可以提高速度,但是也会降低精度。
对于深度图,它自身的问题在于图像近大远小的特性,使得近处的物体对应的像素点多,因此训练时的权重也就更大,另外,这也会造成代价体的信息分布不均匀。
(链接:https://blog.youkuaiyun.com/soaring_casia/article/details/120438692)综上。简单说,使用mvsnet得到的深度图虽然会提高速度,但精度降低;且从代价体得到的信息不均匀,不如直接使用代价体。
Q:IBRNet中已经存在attention机制,为什么NeuRay还要设计可见性特征图?是否多余?
A:作者知乎相关回答如下

















 1041
1041

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









