







 本文探讨了在样本数量有限的情况下,如何利用迁移学习改善分类模型的性能。通过引入与原始数据有相似特征的辅助数据,结合迁移学习的概念,如使用预训练的imageNet模型对Pokemon图片进行分类,可以避免过拟合,显著提高分类准确率。通过在公共模型基础上进行微调,最终实现模型性能的大幅提升。
本文探讨了在样本数量有限的情况下,如何利用迁移学习改善分类模型的性能。通过引入与原始数据有相似特征的辅助数据,结合迁移学习的概念,如使用预训练的imageNet模型对Pokemon图片进行分类,可以避免过拟合,显著提高分类准确率。通过在公共模型基础上进行微调,最终实现模型性能的大幅提升。
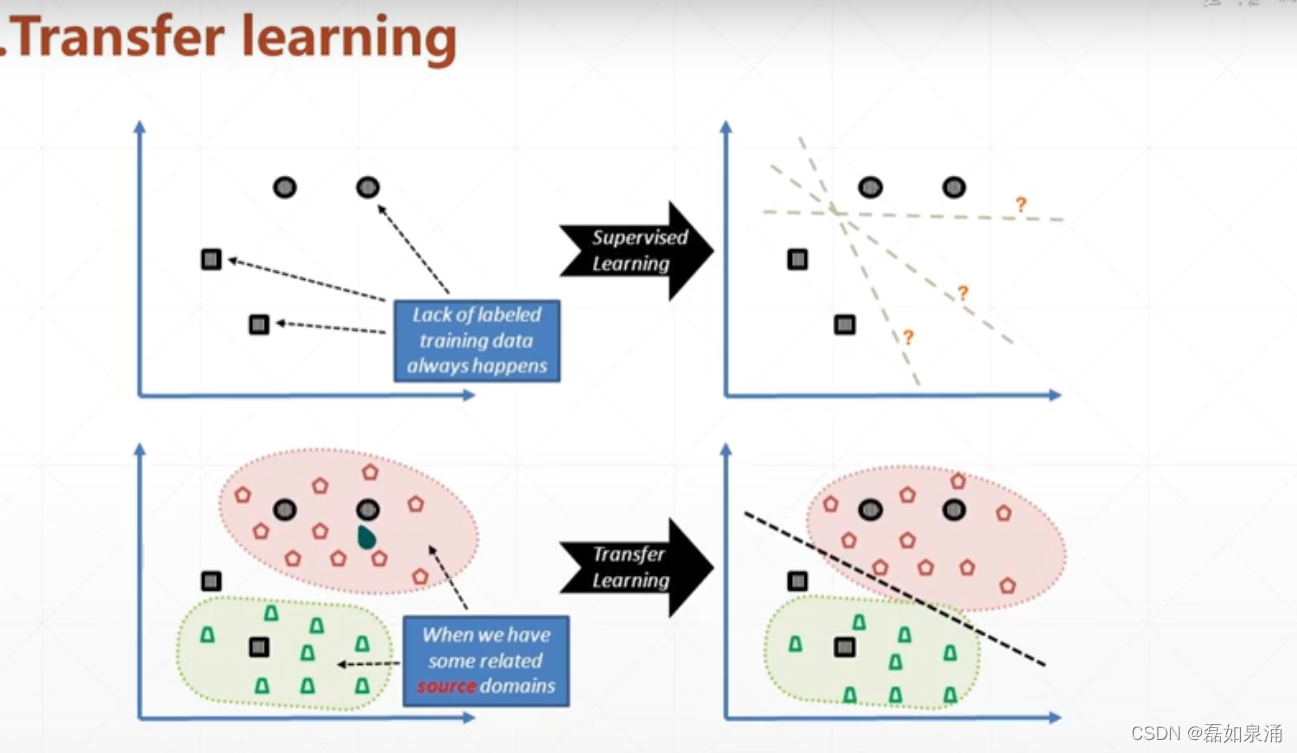
第一种模式,是一个简单的两分类,样本数太少,不足以训练一个靠谱的模型,可以右图看到,他可能有各式各样的方法来进行分类得到模型,但是有可能得到的并不是最好的那种情况,并且很容易发生过拟合。造成acc比较低的情况出现。
下边是我们找到了各式各样的辅助数据进行一起分类,这种辅助数据一半和原有数据有着相似的特征。
这里我们可以考虑迁移学习的概念,比如Pokemon图片和imageNet的样本是有着很多共同的特征的,所以我们可以考虑使用imageNet(公有的知识)已有的模型,来处理Pokemon(特定问题)分类的问题。 (即我们现在任务A上train出一个模型,然后把模型加上特定问题的数据进行微调,放到任务B上使用。)
# 用torchvision自带的resnet18可以直接得到一个比较好的model
train_model = resnet18(pretrained=True)
# 要使用公用知识的特征,取他的前17层 下边索引,0-(-1)
model = nn.Sequential(
*list(train_model.children())[:-1], # 这里的输出是[b,512,1,1]
Flatten(), # [b,512,1,1]=>[b,512]
nn.Linear(51 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









