




环境的源代码:gym-carla项目地址
源自蛋总在CARLA平台+Q-learning的尝试(gym-carla)中的启发,嗯...怎么不算是被鸽了之后自力更生呢(x
gym和carla的环境封装请看:Carla封装Gym指南
关于怎么下载anaconda、carla,原项目的超参数设计等等在上述的第二篇文章里都有,这里就不过多赘述,以下主要讲一下gym-carla的状态动作空间以及怎样实现DQN
一、状态与动作空间
1.状态空间
observation_space_dict = {
'camera': spaces.Box(low=0, high=255, shape=(self.obs_size, self.obs_size, 3), dtype=np.uint8),
'lidar': spaces.Box(low=0, high=255, shape=(self.obs_size, self.obs_size, 3), dtype=np.uint8),
'birdeye': spaces.Box(low=0, high=255, shape=(self.obs_size, self.obs_size, 3), dtype=np.uint8),
'state': spaces.Box(np.array([-2, -1, -5, 0]), np.array([2, 1, 30, 1]), dtype=np.float32)
}如果我们在源代码调用_get_obs()函数,就可以得到上述四个观测,它们的维度分别是三个(255,255,3)的图像('camera'、'lidar'、'birdeye'),和一个(4,)的'state'(与车道线的横向距离,与车道线的夹角,当前速度,和前方车辆的距离)
2.动作空间
self.discrete = params['discrete']
self.discrete_act = [params['discrete_acc'], params['discrete_steer']] # acc, steer
self.n_acc = len(self.discrete_act[0])
self.n_steer = len(self.discrete_act[1])
if self.discrete:
self.action_space = spaces.Discrete(self.n_acc*self.n_steer)
else:
self.action_space = spaces.Box(np.array([params['continuous_accel_range'][0],
params['continuous_steer_range'][0]]), np.array([params['continuous_accel_range'][1],
params['continuous_steer_range'][1]]), dtype=np.float32) # acc, steer很复杂,因为params这个字典没有被我附上,但是简单来说动作大概可以被表示为:
# 离散: action_space = space.Discrete(9),即0-8选择数字传进去,得到九种不同的油门速度和转向角的组合
# 连续: action_space = space.Box(np.array(-3.0,3.0),np.array(-0.3,0.3)), 即每次油门在-3.0到3.0之间随机取一个值,转向角在-0.3到0.3之间随机取一个值
二、DQN原理简析
1.DQN在Q-learning上做的改进以及改进的原因:
因为Q-learning使用的Q-table是以列表的形式存放Q值的,这使它只能用于离散的动作空间和有限的状态空间,无法避免“维度灾难”。所以考虑用一个神经网络代替Q-table,神经网络可以近似Q值的分布状态,解决了有限状态空间的问题。训练DQN的神经网络时,我们找到一个损失函数如下,要最小化这个损失函数,然后通过反向传播使用梯度下降的方法来更新神经网络的参数。
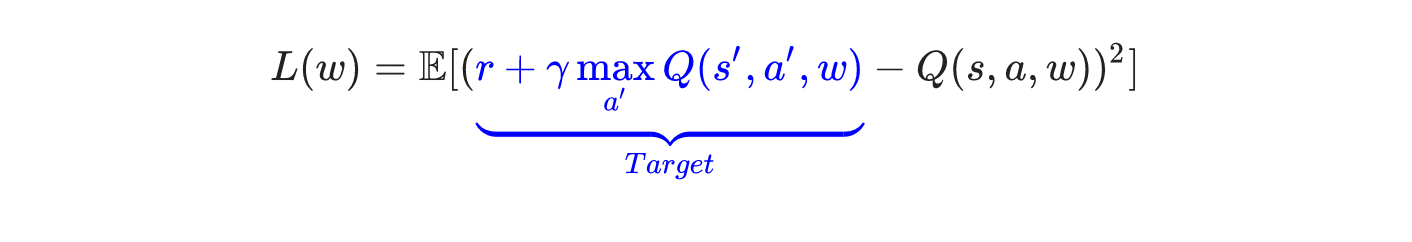 2. DQN伪代码
2. DQN伪代码

3.gym-carla的DQN代码实现
# requirements.txt
ubuntu18.04 + CARLA 0.9.6
# 需要用的包
pygame==1.9.6
gym==0.12.5
pygame==1.9.6
scikit-image==0.16.2random
numpy as np
torch
torchvision
import pygame
import abc
import glob
import os
import sys
from types import LambdaType
from collections import deque
from collections import namedtuple
import random
import time
import numpy as np
import math
import torch
import torch.nn as nn
from torch.autograd import Variable
import torch.nn.functional as F
import torch.optim as optim
import torchvision.transforms as T
from torch import FloatTensor, LongTensor, ByteTensor
Tensor = FloatTensor
import gym
import gym_carla
import carla
# Hyperparameters
IM_WIDTH = 80
IM_HEIGHT = 60
SHOW_PREVIEW = False
SECOND_PER_EPISODE = 10
EPSILON = 0.9 # epsilon used for epsilon greedy approach
GAMMA = 0.9
TARGET_NETWORK_REPLACE_FREQ = 100 # How frequently target netowrk updates
MEMORY_CAPACITY = 100
BATCH_SIZE = 32
LR = 0.01 # learning rate
MODEL_NAME = "nnModule"
def select_action(action_number):
if action_number == 0:
real_action = [1, -0.2]
elif action_number == 1:
real_action = [1, 0]
elif action_number == 2:
real_action = [1, 0.2]
elif action_number == 3:
real_action = [2, -0.2]
elif action_number == 4:
real_action = [2, 0]
elif action_number == 5:
real_action = [2, 0.2]
elif action_number == 6:
real_action = [3.0, -0.2]
elif action_number == 7:
real_action = [3.0, 0]
elif action_number == 8:
real_action = [3.0, 0.2]
return real_action
# Net construction
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 16, kernel_size=5, stride=2)
self.bn1 = nn.BatchNorm2d(16)
self.conv2 = nn.Conv2d(16, 32, kernel_size=5, stride=2)
self.bn2 = nn.BatchNorm2d(32)
self.conv3 = nn.Conv2d(32, 32, kernel_size=5, stride=2)
self.bn3 = nn.BatchNorm2d(32)
self.head = nn.Linear(26912,5) #self.head = nn.Linear(896,5)
def forward(self, x):
x = F.relu(self.bn1(self.conv1(x))) # 一层卷积
x = F.relu(self.bn2(self.conv2(x))) # 两层卷积
x = F.relu(self.bn3(self.conv3(x))) # 三层卷积
return self.head(x.view(x.size(0),-1)) # 全连接层
class DQN(object):
def __init__(self):
self.eval_net,self.target_net = Net(),Net()
# Define counter, memory size and loss function
self.learn_step_counter = 0 # count the steps of learning process
self.memory = []
self.position = 0 # counter used for experience replay buff
self.capacity = 200
#------- Define the optimizer------#
self.optimizer = torch.optim.Adam(self.eval_net.parameters(), lr=LR)
# ------Define the loss function-----#
self.loss_func = nn.MSELoss()
def choose_action(self, x):
# This function is used to make decision based upon epsilon greedy
x = torch.unsqueeze(torch.FloatTensor(x), 0) # add 1 dimension to input state x
x = x.permute(0,3,2,1) #把图片维度从[batch, height, width, channel] 转为[batch, channel, height, width]
# input only one sample
if np.random.uniform() < EPSILON: # greedy
# use epsilon-greedy approach to take action
actions_value = self.eval_net.forward(x)
#print(torch.max(actions_value, 1))
# torch.max() returns a tensor composed of max value along the axis=dim and corresponding index
# what we need is the index in this function, representing the action of cart.
action = torch.max(actions_value, 1)[1].data.numpy()
action = action[0]
else:
action = np.random.randint(0, 5)
return action
def push_memory(self, obs, a, r, obs_):
if len(self.memory) < self.capacity:
self.memory.append(None)
self.memory[self.position] = Transition(torch.unsqueeze(torch.FloatTensor(obs), 0),torch.unsqueeze(torch.FloatTensor(obs_), 0),\
torch.from_numpy(np.array([a])),torch.from_numpy(np.array([r],dtype='int64')))
self.position = (self.position + 1) % self.capacity
def get_sample(self,batch_size):
return random.sample(self.memory, batch_size)
def learn(self):
# Define how the whole DQN works including sampling batch of experiences,
# when and how to update parameters of target network, and how to implement
# backward propagation.
# update the target network every fixed steps
if self.learn_step_counter % TARGET_NETWORK_REPLACE_FREQ == 0:
# Assign the parameters of eval_net to target_net
self.target_net.load_state_dict(self.eval_net.state_dict())
self.learn_step_counter += 1
transitions = self.get_sample(BATCH_SIZE) # 抽样
print(transitions)
batch = Transition(*zip(*transitions))
# extract vectors or matrices s,a,r,s_ from batch memory and convert these to torch Variables
# that are convenient to back propagation
b_s = Variable(torch.cat(batch.state))
# convert long int type to tensor
b_a = Variable(torch.cat(batch.action))
b_r = Variable(torch.cat(batch.reward))
b_s_ = Variable(torch.cat(batch.next_state))
#b_s和b_s_分别对应当前帧和下一帧的图像数据,变量的维度是80*60*3(x*y*rgb_channel),但进入神经网络需将其维度变为3*80*60
b_s = b_s.permute(0,3,2,1)
b_s_ = b_s_.permute(0,3,2,1)
# calculate the Q value of state-action pair
q_eval = self.eval_net(b_s).gather(1,b_a.unsqueeze(1)) # (batch_size, 1)
# calculate the q value of next state
q_next = self.target_net(b_s_).detach() # detach from computational graph, don't back propagate
# select the maximum q value
# q_next.max(1) returns the max value along the axis=1 and its corresponding index
print(q_next)
print(q_next.max(1))
q_target = b_r + GAMMA * q_next.max(1)[0].view(BATCH_SIZE, 1) # (batch_size, 1)
print(q_target)
#q_target shape:32 x 32,looks like that q_next.max didn't make sense.
loss = self.loss_func(q_eval, q_target)
self.optimizer.zero_grad() # reset the gradient to zero
loss.backward()
self.optimizer.step() # execute back propagation for one step
Transition = namedtuple('Transition',('state', 'next_state','action', 'reward'))
def main():
# parameters for the gym_carla environment
params = {
'number_of_vehicles': 100,
'number_of_walkers': 0,
'display_size': 256, # screen size of bird-eye render
'max_past_step': 1, # the number of past steps to draw
'dt': 0.1, # time interval between two frames
'discrete': False, # whether to use discrete control space
'discrete_acc': [-3.0, 0.0, 3.0], # discrete value of accelerations
'discrete_steer': [-0.2, 0.0, 0.2], # discrete value of steering angles
'continuous_accel_range': [-3.0, 3.0], # continuous acceleration range
'continuous_steer_range': [-0.3, 0.3], # continuous steering angle range
'ego_vehicle_filter': 'vehicle.lincoln*', # filter for defining ego vehicle
'port': 2000, # connection port
'town': 'Town03', # which town to simulate
'task_mode': 'roundabout', # mode of the task, [random, roundabout (only for Town03)]
'max_time_episode': 1000, # maximum timesteps per episode
'max_waypt': 12, # maximum number of waypoints
'obs_range': 32, # observation range (meter)
'lidar_bin': 0.125, # bin size of lidar sensor (meter)
'd_behind': 12, # distance behind the ego vehicle (meter)
'out_lane_thres': 2.0, # threshold for out of lane
'desired_speed': 8, # desired speed (m/s)
'max_ego_spawn_times': 200, # maximum times to spawn ego vehicle
'display_route': True, # whether to render the desired route
'pixor_size': 64, # size of the pixor labels
'pixor': False, # whether to output PIXOR observation
}
# Set gym-carla environment
env = gym.make('carla-v0', params=params)
dqn = DQN()
dqn.eval_net.load_state_dict(torch.load('EvalNet.pt')) # 也可以不用load,自己搜一下怎么初始化就行
dqn.eval_net.eval()
dqn.target_net.load_state_dict(torch.load('TargetNet.pt'))
dqn.target_net.eval()
# =============== push memory into buffer ================
count = 0
max_reward = float("-inf")
reward_list = []
for iteration in range(1,100):
print("# Iteration{} start!".format(iteration))
reward = 0
env.reset()
obs = env.reset()
for episode in range(100):
a=dqn.choose_action(obs)
action = select_action(a)
print("# Episode{} start!".format(episode))
print("choose_action:", action)
obs_,r,done,info = env.step(action)
print(obs.shape[0])
dqn.push_memory(obs, a, r, obs_)
reward += r
obs=obs_
if (dqn.position % (MEMORY_CAPACITY-1) )== 0 and reward > max_reward:
dqn.learn()
count+=1
print('learned times:',count)
if done:
print("Done!")
break
print("# the reward of this iteration is", reward)
if reward > max_reward:
max_reward = reward
torch.save(dqn.eval_net.state_dict(),'EvalNet-{}.pt'.format(count))
torch.save(dqn.target_net.state_dict(),'TargetNet-{}.pt'.format(count))
if __name__ == '__main__':
main()
第一次用csdn,为啥我的代码上传出来是这样的??不管了,跑了四五十个iteration,奖励差不多就到300了,总体来说还行吧但是也可以继续优化。
三、gym-carla环境sensor destroy问题
有时候调用reset之后代码总是提示fail to destroy,查看了一下是因为如下代码生成ego_vehicle的时候,固定的生成点总是被其他车辆遮挡,外层又套了个while true所以一直循环生成,很容易卡死,感兴趣的朋友可以在源代码中overlap=True后面加个print再运行,说不定会有填满整个屏幕的惊喜(x
初步想到的解决方法是重写一个load_world函数,把carla的world删除再reload一下,但还没开始实现(好累有没有懂的),就这样!下次再见!
def _try_spawn_ego_vehicle_at(self, transform):
"""Try to spawn the ego vehicle at specific transform.
Args:
transform: the carla transform object.
Returns:
Bool indicating whether the spawn is successful.
"""
vehicle = None
# Check if ego position overlaps with surrounding vehicles
overlap = False
for idx, poly in self.vehicle_polygons[-1].items():
poly_center = np.mean(poly, axis=0)
ego_center = np.array([transform.location.x, transform.location.y])
dis = np.linalg.norm(poly_center - ego_center)
if dis > 8:
continue
else:
overlap = True
break
if not overlap:
vehicle = self.world.try_spawn_actor(self.ego_bp, transform)
if vehicle is not None:
self.ego=vehicle
return True
return False
















 302
302

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









