






一、下载安装antlr4
二、生成modelica解析文件
2.1 下载modelica的解析文件
下载解析文件modelica.g4
地址 modelica.g4
注意这里我把文件名和内容第一行都改为Modelica
2.2 生成解析器代码
安装依赖
注意一定要和antlr4.jar文件版本一致
pip install antlr4-python3-runtimecmd窗口输入生成解析器代码
antlr4 -Dlanguage=Python3 Modelica.g4这会生成:ModelicaLexer.py, ModelicaParser.py, ModelicaListener.py
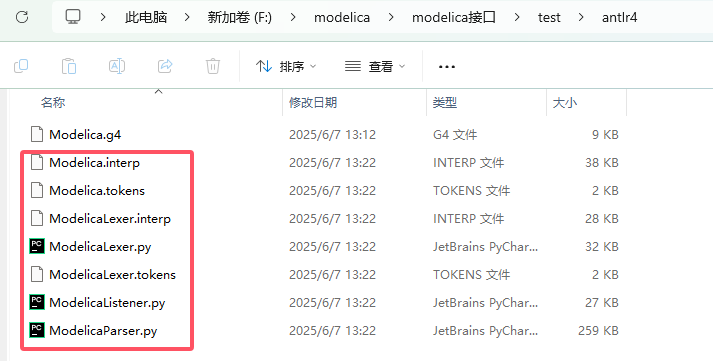
2.3 准备一些mo文件
自行准备
2.4 解析生成
这里仅生成组件参数
# 设定antlr4目录相对路径
antlr4_path = os.path.join(os.path.dirname(__file__), "antlr4")
sys.path.insert(0, antlr4_path) # 必须加入路径
from antlr4 import FileStream, CommonTokenStream, ParseTreeWalker
from antlr.ModelicaLexer import ModelicaLexer
from antlr.ModelicaParser import ModelicaParser
from antlr.ModelicaListener import ModelicaListener
def extract_info(mo_dir, output_dir):
"""
主函数:处理Modelica文件并将参数信息存储为JSON
"""
# 确保输出目录存在
os.makedirs(output_dir, exist_ok=True)
for fname in os.listdir(mo_dir):
if fname.endswith('.mo'):
file_name = os.path.splitext(fname)[0]
fpath = os.path.join(mo_dir, fname)
# 修复:添加 encoding='utf-8'
input_stream = FileStream(fpath, encoding='utf-8')
lexer = ModelicaLexer(input_stream)
stream = CommonTokenStream(lexer)
parser = ModelicaParser(stream)
tree = parser.stored_definition()
extractor = ParameterExtractor()
walker = ParseTreeWalker()
walker.walk(extractor, tree)
# 按类别组织参数
info = {}
for param in extractor.parameters:
# 创建参数的简化字典(移除空值)
param_data = {k: v for k, v in param.items() if v}
# 删除class属性
param_data.pop('class', None)
# 删除category属性
param_data.pop('category', None)
# 获取modifier属性值
modifier = param_data.get('modifier', '')
# 提取modifier中括号里的内容
info_match = re.search(r'\(([^)]*)\)', modifier)
param_data['info'] = info_match.group(1) if info_match else ""
# 提取等号右边内容作为value
# 去除括号及其中内容
no_bracket = re.sub(r'\([^)]*\)', '', modifier)
# 去除等号及后面所有内容
clean = re.sub(r'=', '', no_bracket)
param_data['value'] = clean
# 除去modifier
param_data.pop('modifier', None)
# 按类别存储
if param['category'] != 'top-level':
info.setdefault(param['category'], []).append(param_data)
# 写入JSON文件
output_path = os.path.join(output_dir, f"{file_name}_params.json")
with open(output_path, 'w', encoding='utf-8') as f:
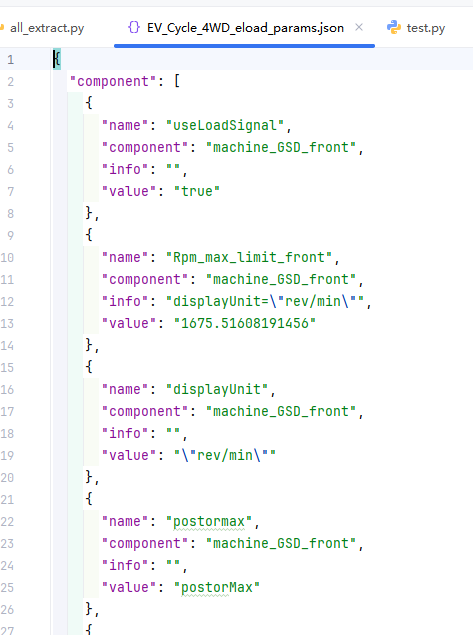
json.dump(info, f, indent=2, ensure_ascii=False)生成内容

















 718
718

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









