







本项目基于卷积神经网络(CNN)实现手写数字识别,采用Python和TensorFlow框架训练并优化模型。数据集选用MNIST,包含60000张训练图片和10000张测试图片,每张图片均为28×28像素的灰度图像。实验结果表明,模型在测试集上达到了99.06%的准确率。随后,模型被用于手写数字图片的预测,并成功识别实际手写输入。该研究表明,深度学习方法在数字识别任务中表现优异,可进一步推广至更复杂的图像识别应用,如车牌识别、验证码解析等。未来可通过数据增强、迁移学习等方式提升模型泛化能力,使其更适用于多种现实场景。
1、项目背景
随着人工智能和深度学习技术的发展,数字识别已经成为计算机视觉领域中的一个重要应用。利用深度学习模型,尤其是卷积神经网络(CNN),能够实现高效且准确的数字识别。本项目的目标是通过卷积神经网络对手写数字进行分类识别,评估模型性能,并应用于手写数字的实际识别。
2、数据集介绍
本项目使用了MNIST数据集。MNIST(Modified National Institute of Standards and Technology)数据集是一个经典的手写数字图像数据集,广泛用于图像识别的研究。数据集包含 70000 张灰度图像,分别用于训练(60000 张)和测试(10000 张)。每张图像的尺寸为 28x28 像素,表示一个手写数字(0 到 9)。每个图像均已标注了相应的数字标签。
3、数据预处理
在模型训练前,需要对数据进行预处理:
形状调整:由于卷积神经网络要求输入数据具有明确的形状,将输入图像的形状调整为 (28, 28, 1),即每张图像的大小为 28x28 像素,且每个像素点有一个通道(灰度图像)。
归一化:为了加速训练过程并提高模型收敛速度,图像像素值(原本在 0 到 255 之间)被缩放到 0 到 1 之间。这样,模型能够更快地进行训练,并避免过高的数值导致梯度消失。
标签处理:标签值(即数字 0-9)已经是整数形式,直接使用即可。
4、模型构建
使用卷积神经网络(CNN)来构建数字识别模型。CNN 是一种特别适用于图像处理的神经网络,它能够自动提取图像中的特征,并对图像进行分类。
模型架构
第一层:一个卷积层,使用 32 个 3x3 的卷积核,激活函数为 ReLU(Rectified Linear Unit)。该层能够从图像中提取基本的视觉特征,如边缘、角点等。
第二层:最大池化层,池化窗口为 2x2,用于减少特征图的尺寸并提取最显著的特征。
第三层:另一个卷积层,使用 64 个 3x3 的卷积核,激活函数同样为 ReLU。
第四层:最大池化层,进一步减少特征图的尺寸。
第五层:第三个卷积层,使用 64 个 3x3 的卷积核,提取更复杂的特征。
第六层:Flatten 层,将三维的特征图展平成一维,准备进入全连接层。
第七层:一个全连接层,包含 64 个神经元,激活函数为 ReLU,用于将提取的特征转换为最终的分类结果。
第八层:输出层,包含 10 个神经元,使用 softmax 激活函数进行分类,输出 0 到 9 之间的概率值。
5、模型训练与评估
训练过程

模型使用Adam优化器进行训练,损失函数采用sparse_categorical_crossentropy,因为这是一个多类分类问题。训练数据集的样本数为 60000 个,测试数据集包含 10000 个样本。进行了 5 轮训练,并且每轮训练都使用了验证集来评估模型的性能。
训练结果
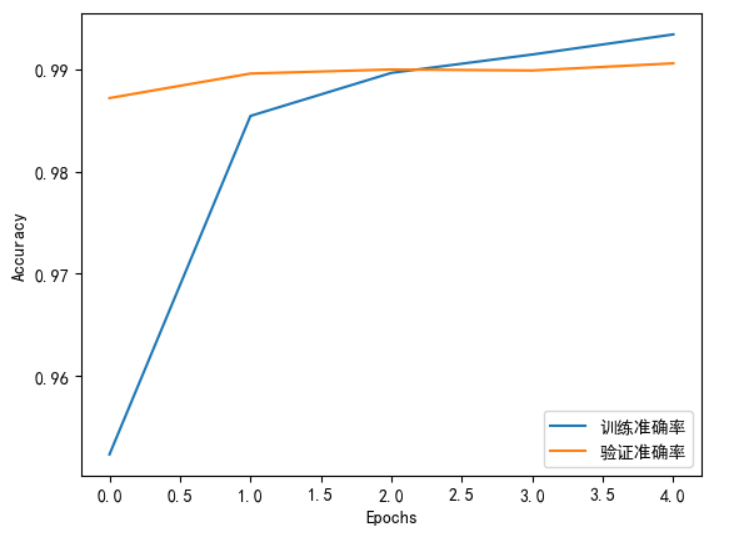
在训练过程中,模型的损失逐渐下降,准确率不断提高。具体来说:
第 1 轮:训练准确率为 95.23%,验证准确率为 98.72%。
第 2 轮:训练准确率为 98.55%,验证准确率为 98.96%。
第 3 轮:训练准确率为 98.97%,验证准确率为 99.00%。
第 4 轮:训练准确率为 99.15%,验证准确率为 98.99%。
第 5 轮:训练准确率为 99.34%,验证准确率为 99.06%。
最终模型在测试集上的准确率达到了 99.06%。
6、结果分析
通过对训练过程中的损失和准确率曲线的观察,可以看出,模型的训练效果非常好。验证集准确率几乎达到了训练集准确率,说明模型没有过拟合,且具有很好的泛化能力。
模型在测试集上的准确率为 99.06%,这表明该模型能够有效地识别 MNIST 数据集中的数字。通过分析训练过程中损失的逐步下降,可以确认模型在不断优化,适应了数据的特征
7、手写数字识别
在完成模型的训练和评估后,使用该模型对一张手写数字图片进行预测。图片经过适当的预处理,包括灰度转换、尺寸调整、颜色反转和归一化。模型成功地预测出手写数字的类别。
结果展示:

展示了测试图像及其对应的预测结果。对于每一张测试图像,模型能够准确地预测出图像中的数字。
8、结论与展望
结论:
本项目通过卷积神经网络对 MNIST 数据集进行了手写数字的识别,最终模型在测试集上取得了 99.06% 的准确率。训练过程中的损失和准确率曲线表明模型能够有效地学习到数据中的模式,并且具有很好的泛化能力。
展望
虽然当前模型已经能够准确识别 MNIST 数据集中的数字,但在实际应用中,手写数字的识别可能会面临更多挑战。例如,数字的书写风格、图像质量等因素可能会影响识别的准确性。未来的工作可以考虑:增强数据集:通过数据增强技术(如旋转、缩放等)生成更多样本,以提高模型的鲁棒性。使用更复杂的模型:例如,ResNet 或其他先进的网络架构,可能会进一步提升性能。迁移学习:利用在其他数据集上训练好的模型,减少训练时间并提升准确度。
通过进一步改进模型架构和训练方法,数字识别的准确性和应用范围有望得到显著提升。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









