






1 - 问题
K8S 中的服务数量较多时,会有个别服务日志打印较多,从而导致 K8S-node 的磁盘水位线较高,导致该 Node 的 Pod 被驱逐,从而影响业务的稳定性。
2 - 思路
- 全局方案:
- 配置 K8S 的
ephemeral-storage限制 - 监控告警:这是老生常谈的问题,不过监控告警只能告知问题并不能解决。
- 配置 K8S 的
- 细颗粒度:
- 针对不同的服务,调整日志的配置
- 优化服务的参数配置,如 Jvm 的配置
3 - 配置 ephemeral-storage
我们常规配置都只配置了内存、CPU 的一个限制而往往忽略的磁盘存储的限制。
3.1 - 效果测试
可以使用以下的 Pod 来测试 ephemeral-storage 的效果
apiVersion: v1
kind: Pod
metadata:
name: test-ephemeral-storage
spec:
containers:
- name: test-container
image: "m.daocloud.io/docker.io/busybox:lastest"
command: ["sh", "-c", "while true; do dd if=/dev/zero of=/tmp/testfile bs=1M count=1000; sleep 1; done"]
resources:
limits:
ephemeral-storage: 100Mi
requests:
ephemeral-storage: 50Mi
当 Pod 的限制超出后,K8S 会驱逐该 Pod,类似于对 Cpu 的限制。


3.2 - 配置调整
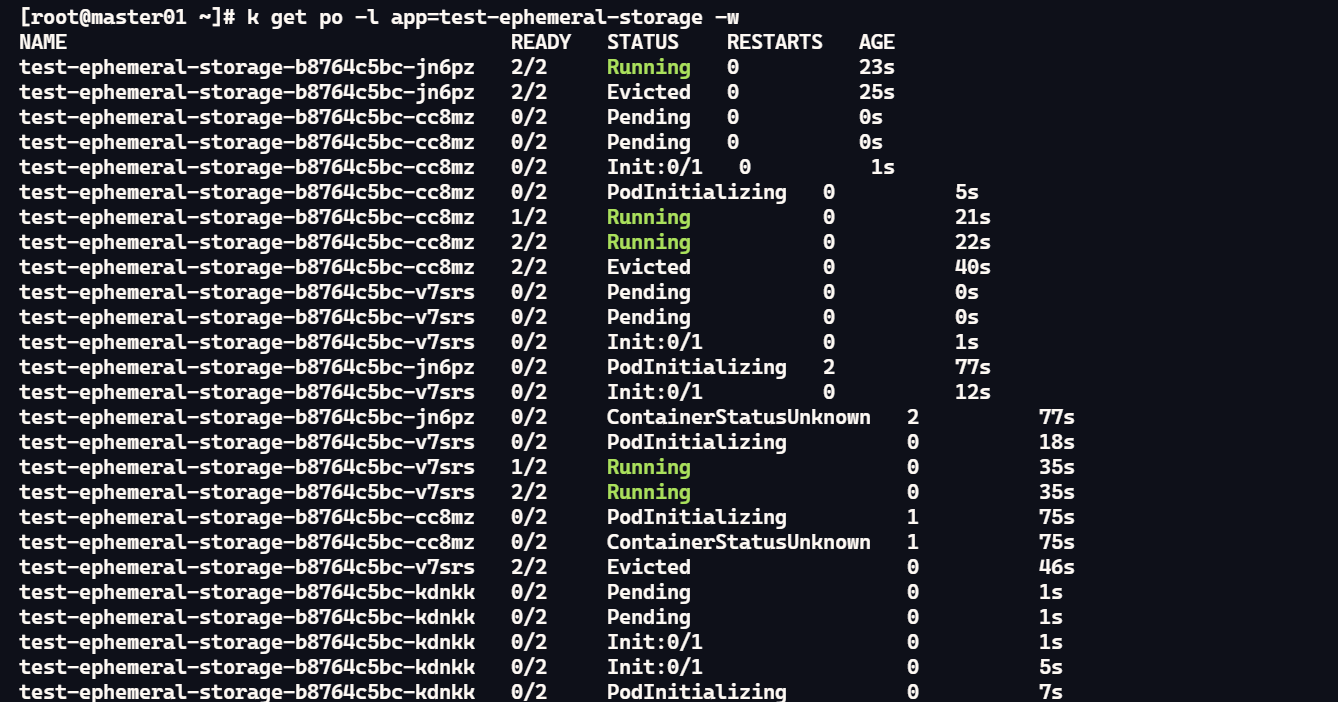
在上一步中我们确认了当磁盘超限的时候会进行驱逐,但是驱逐是我们的目的吗?显然不是,我们希望服务能够继续运行,而不是一直处于驱逐的状态。接下来我们调整下上面的 Pod 配置文件,调整为使用 deploy 控制器来控制他。
apiVersion: apps/v1
kind: Deployment
metadata:
name: test-ephemeral-storage
spec:
replicas: 1
selector:
matchLabels:
app: test-ephemeral-storage
template:
metadata:
labels:
app: test-ephemeral-storage
spec:
containers:
- name: test-container
image: "m.daocloud.io/docker.io/busybox:latest"
command: ["sh", "-c", "while true; do dd if=/dev/zero of=/tmp/testfile bs=1M count=1000; sleep 1; done"]
resources:
limits:
ephemeral-storage: 100Mi
requests:
ephemeral-storage: 50Mi
测试下现在的情况,控制器自己完成了重新调度。
4 - 新增 Jvm 参数
我们线上的服务大多数都是 Java 程序,由于接入了一些三方组件或者引入了一些 SDK,导致了一些日志的堆积,所以需要调整下这些配置参数
-Dons.client.logLevel=ERROR
-Drocketmq.client.logLevel=ERROR
-Dpinpoint.profiler.profiles.active=release
使用脚本快速添加,前置条件是要安装 yq 工具
关于yq命令的使用,大家有兴趣我可以单开一个文章结合下面的脚本讲解下简单的用法,很强大的yaml解析工具
项目地址:https://github.com/mikefarah/yq
#!/bin/bash
###
# @Author : Lihang
# @Email : lihang818@foxmail.com
# @Date : 2025-02-10 11:49:10
# @LastEditTime : 2025-02-10 15:15:29
# @Description : 新增configmap-jvm参数
###
# 1. 检查命名空间参数
if [[ -z "$1" ]]; then
echo "请提供命名空间" >&2
exit 1
fi
NAMESPACE="$1"
# 2. 定义要添加的JVM参数
new_options="-Dons.client.logLevel=ERROR -Drocketmq.client.logLevel=ERROR -Dpinpoint.profiler.profiles.active=release"
# 3. 初始化成功修改的 ConfigMap 名称数组
success_cm=()
# 4. 获取并处理 ConfigMap
config_maps=$(kubectl -n "$NAMESPACE" get cm -o yaml | yq eval '.items[]' -)
# 5. 过滤出包含 JAVA_OPTIONS 的 ConfigMap
echo "以下 ConfigMap 包含 JAVA_OPTIONS:"
filtered_cm_yamls=$(echo "$config_maps" | while read -r cm_yaml; do
cm_name=$(echo "$cm_yaml" | yq eval '.metadata.name' -)
java_options=$(echo "$cm_yaml" | yq eval '.data.JAVA_OPTIONS // ""' -)
if [[ -n "$java_options" ]]; then
echo "发现ConfigMap: $cm_name" >&2 # 打印到stderr,不影响filtered_cm_yamls的内容
echo "$cm_yaml" # 只输出YAML内容
fi
done)
# 6. 处理过滤后的 ConfigMap
while read -r cm_yaml; do
# 7. 提取 ConfigMap 名称和 JAVA_OPTIONS
cm_name=$(echo "$cm_yaml" | yq eval '.metadata.name' -)
java_options=$(echo "$cm_yaml" | yq eval '.data.JAVA_OPTIONS // ""' -)
# 8. 检查 JAVA_OPTIONS 是否需要更新
if [[ "$java_options" != *"-Dons.client.logLevel=ERROR"* ||
"$java_options" != *"-Drocketmq.client.logLevel=ERROR"* ||
"$java_options" != *"-Dpinpoint.profiler.profiles.active=release"* ]]; then
# 9. 构造新的 JAVA_OPTIONS 字符串
new_java_options="${java_options:+$java_options }$new_options"
# 10. 更新对应的 ConfigMap
if kubectl -n "$NAMESPACE" patch cm "$cm_name" --type='json' -p="[{'op': 'replace', 'path': '/data/JAVA_OPTIONS', 'value': '$new_java_options'}]"; then
echo "更新ConfigMap $cm_name 成功"
success_cm+=("$cm_name")
else
echo "更新ConfigMap $cm_name 失败" >&2
fi
else
echo "ConfigMap $cm_name 已包含所需参数,无需更新"
fi
done <<<"$filtered_cm_yamls"
# 11. 输出所有成功修改的 ConfigMap 名称
if [ ${#success_cm[@]} -gt 0 ]; then
echo "以下 ConfigMap 更新成功:"
for cm in "${success_cm[@]}"; do
echo "$cm"
done
else
echo "没有成功更新的 ConfigMap"
fi
5 - 问题处理
当 K8S-Node 节点出现的磁盘告警,应该如何检查呢?
先准备好下面这个别名,方便我们操作
alias ds='du -sh ./* | sort -rh | head'
然后,我们根据所学习的知识挨个检查一下这几个目录
哪里学习的呢,点击:Kubernets-Node 存储目录一探
- 日志目录:
/var/log/pods - 临时存储目录:
/var/lib/kubelet/pods - 容器运行时目录(以 docker 为例):
/var/lib/docker/
只需要挨个进入到这些目录定位下较大的文件即可,一般情况下都是日志文件较大引起的。
cd /var/lib/docker && ds
cd /var/lib/kubelet/pods && ds
cd /var/log/pods && ds
# 全盘扫描
find / -type f -size +500M 2>/dev/null | xargs ls -lh
这个时候有没有发现一个问题?
磁盘占用比较高的时候,如果我们执行上面这些命令,是否会对服务器产生很大的压力呢?这些命令对于服务器的压力是什么样的呢?底层实现是什么样的呢?
给我自己先挖个坑,后面来填。🐶

















 384
384

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









