






简要了解一下
数据库:一个数据库的服务器中包含多个数据库,一个数据库中有多张表,一个表中包含多个字段(字段和JavaBean的 属性是对应),表中存放是数据,一行数据和一个JavaBean实体对象是对应的。
SQL语言用来操作数据库,是非过程性的语言(一条语言,就对应一个返回的结果)。
目录
一、mysql下载安装
1.建议下载数据库的常用版本5.6 5.7 8.0
可以参考文章:Mysql下载安装教程(图文版)-优快云博客
2.打开sql:
1)如果配置了对应的环境变量,可以直接通过cmd进入;
2)没有配置,进入到下载mysql对应的文件夹中,打开bin目录,输入cmd能直接进入数据库:
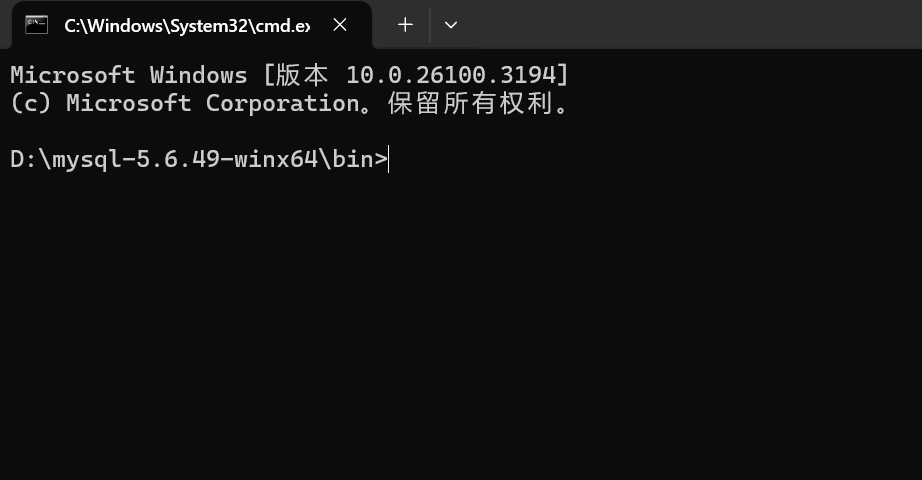
不管1)还是2)都需要输入mysql ‐u root ‐p , 回车 , 输入密码 ,成功进入MySQL的服务器。
3.如果找不到sql并且不确定自己有没有下载过:看看服务列表有没有mysql服务。
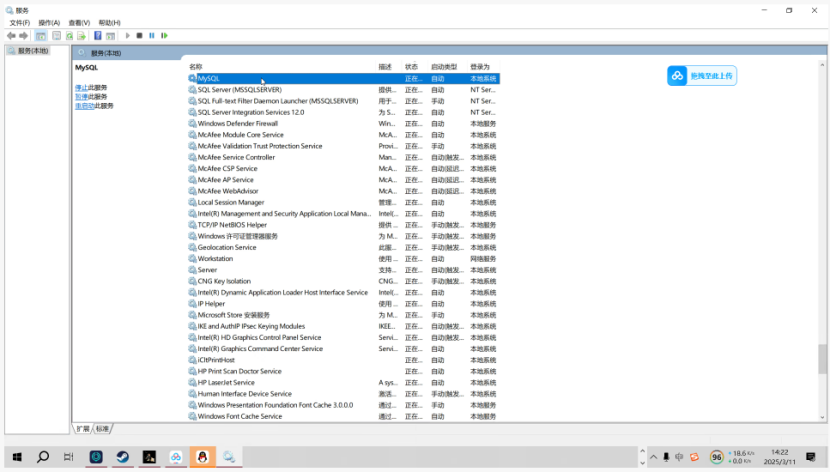
二、Mysql卸载
在服务中找到Mysql设置停止,根据mysql的安装目录删除,就卸载干净了。Mysql的所有信息数据都在他的安装文件夹下的data文件夹里,不会出现在其他磁盘或文件中。
三、SQL简单分类介绍
1.DDL 数据定义语言 :创建数据库 创建表 创建视图 创建索引 修改数据库 删除数据库 修改表 删除表——create ‐‐ 创建 alter ‐‐ 修改 drop ‐‐ 删除
2.DML 数据操作语言 :* 操作数据 插入数据(insert) 修改数据(update) 删除数据(delete)
3.DCL 数据控制语言 : if else while
4.DQL 数据查询语言 :从表中查询数据(select)
三、Mysql语句学习——重点!
1.数据库的增删改查
1.1创建数据库
基本语法:create database 数据库名称;
正宗语法:create database 数据库名称 character set 编码 collate 校对规则;
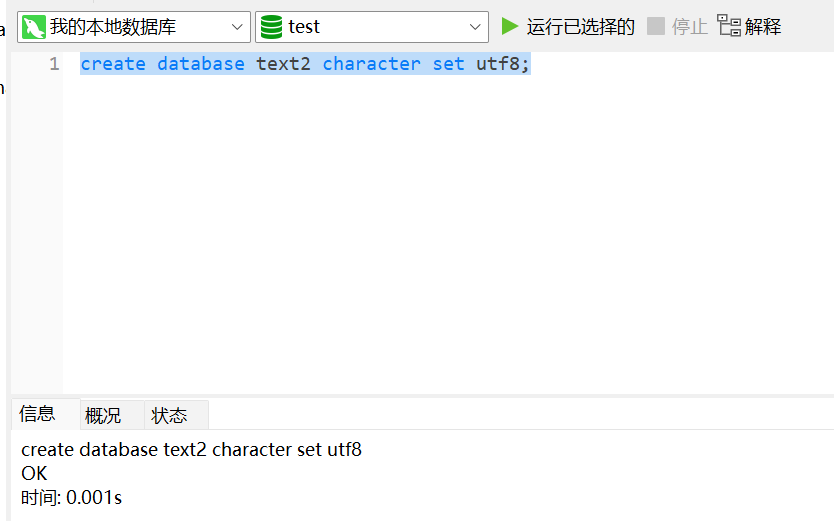
运行上述命令后:text2数据库就建立了-->
具体示例用法如下:
#创建一个名称为mydb1的数据库。
create database mydb1;
#创建一个使用utf8字符集的mydb2数据库。
create database mydb2 character set 'utf8';
#创建一个使用utf8字符集,并带校对规则的mydb3数据库。
create database mydb3 character set 'utf8' collate 'utf8_bin';1.2查看数据库
1.show databases; ‐‐ 查看所有的数据库
2.use 数据库名称;(*****) ‐‐ 使用数据库
3.show create database 数据库名称; ‐‐ 查询数据库的创建的信息
4.select database(); ‐‐ 查询当前正在使用的数据库对应的结果:
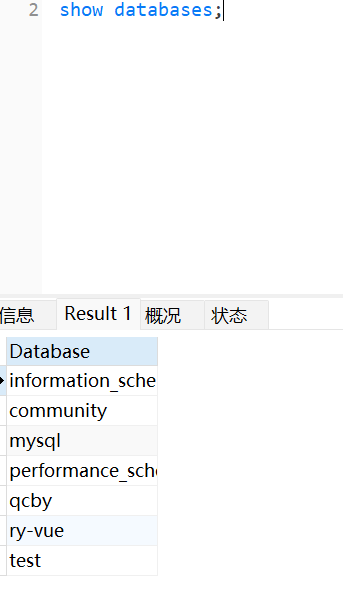
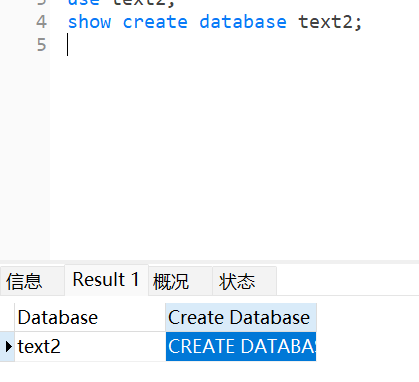
1.3删除数据库
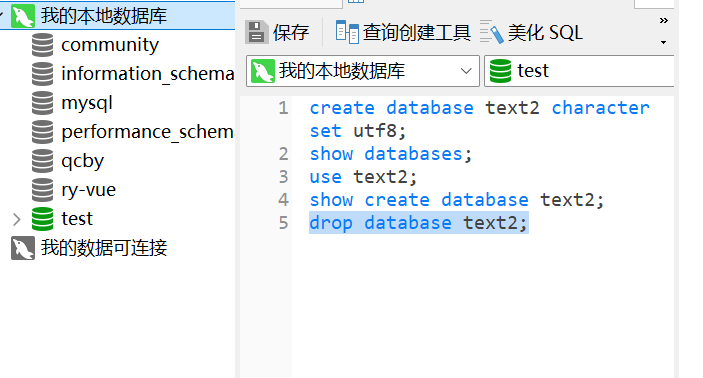
注意!删除公司数据库是违法的,这这个操作需谨慎!
drop database 数据库名称;删除text2:
1.4修改数据库
数据库修改只能修改三部分,分别是:数据库名称、校对规则以及编码规则。注意,修改应该是在text2数据库中进行修改。其他数据库中修改text2没有效果。
alter database 数据库名称 character set 'gbk' collate '校对规则';再次创建text2,编码为utf8,名称text2,进行修改。修改前: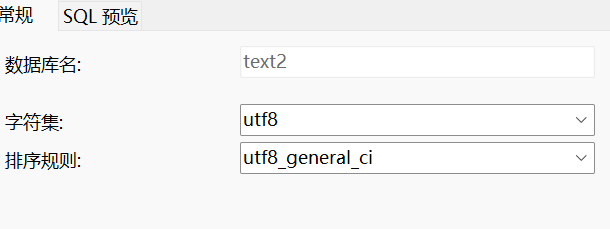
运行后: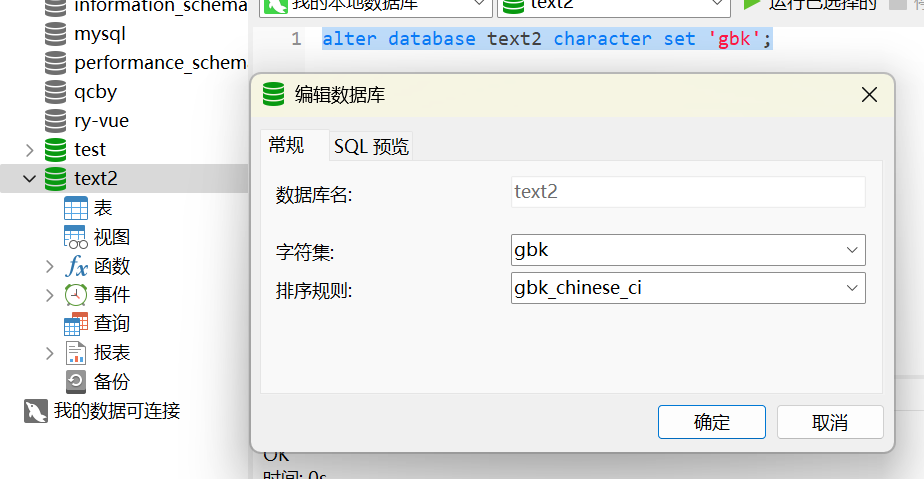
2.表的增删改查
2.1创建表
2.1.1语法
create table 表名称(
字段1 类型(长度) 约束,
字段2 类型(长度) 约束,
字段3 类型(长度) 约束
);约束分为四个约束:主键约束、非空约束、外键约束、唯一约束
1.约束的好处:保证数据的完整性。
2.主键约束(重要)代表记录的唯一标识。
*关键字:primary key 通过该关键字声明某一列为主键。
*唯一 值就不能相同
*非空 值也不能为空
*被引用 (和外键一起来使用)
3.唯一约束
*声明字段值是唯一的。使用关键字 unique
4.非空约束
*声明字段的值是不能空的。not null
2.1.2.注意:
创建表的时候,后面用小括号,后面分号。
编写字段,字段与字段之间使用逗号,最后一个子段不能使用逗号。
如果声明字符串数据的类型,长度是必须指定的。
如果不指定数据的长度,有默认值的。int类型的默认长度是11
2.1.3练习:
create table employee(
id int,
name varchar(30),
gender char(5),
birthday date,
entry_date date,
job varchar(50),
salary double,
resume text
);
2.2.查询表
#查看标签
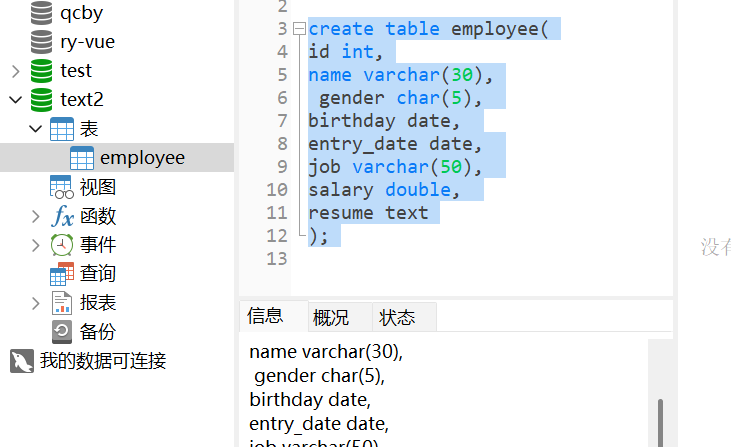
*desc 表名; ‐‐ 查询表的信息
*show tables; ‐‐ 查看当前数据库中所有的标签
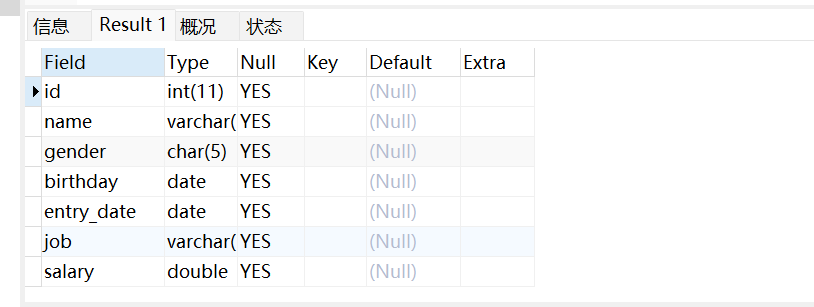
show create table 表名 ‐‐ 查看表的创建的信息输入: desc employee,如下:
2.3.修改表
*alter table 表名 add 新列名 类型(长度) 约束; ‐‐ 添加列
*alter table 表名 drop 列名; ‐‐ 删除列
*alter table 表名 modify 列名 类型(长度) 约束; ‐‐ 修改列的类型或者约束
*alter table 表名 change 旧列名 新列名 类型(长度) 约束; ‐‐ 修改列名
*rename table 表名 to 新表名; ‐‐ 修改表的名称
*alter table 表 名 character set utf8; ‐‐ 修改表的字符集
#实例
在上面员工表的基本上增加一个image列。
alter table employee add image varchar(50);
修改job列,使其长度为60。
alter table employee modify job varchar(60);
删除gender列。
alter table employee drop gender;
表名改为user。
rename table employee to user;
修改表的字符集为utf8
alter table user character set utf8;
列名name修改为username
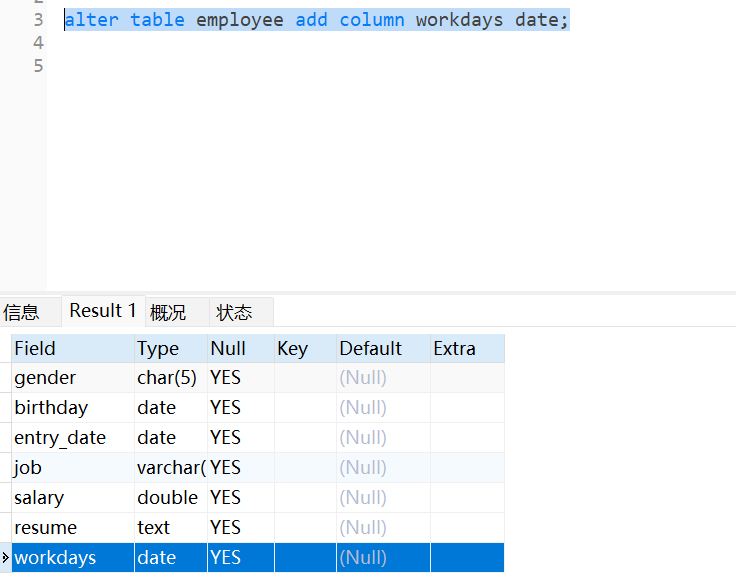
alter table user change name username varchar(30);简单选择一个语句示范: alter table employee add column workdays date;如下:
2.4.删除表
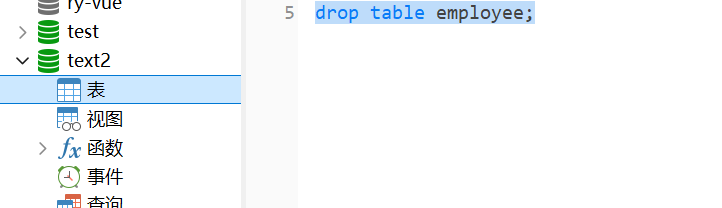
1.删除表语法:drop table 表名;
输入语句: drop table employee即删除成功
四、数据库的数据类型
1.verchar和char
- VARCHAR(用的比较多):长度是可变的。例子:name varchar (8),存入数据 hello,存入进去之后,name 字段长度自动变成了 5。
- CHAR:长度是不可变的。例子:name char (8) 存入数据 hello,用空格来补全剩余的位置。
- VARCHAR、char 都需要设置长度,没有默认长度。
2.大数据类型(不常用)
- BLOB:字节(电影、mp3)
3.TEXT:字符(文本的内容)
4.数值型(重点)6 个:TINYINT (byte)、SMALLINT (short)、INT、BIGINT (long)、FLOAT (单精度)、DOUBLE(多精度)
5.逻辑性 布尔类型
- 在 Java 中是 true 或者 false
- 在数据库 bit 类型(1 或者 0)
6.日期型(重点)
- DATE:只包含日期(年月日)
- TIME:只包含时间(时分秒)
- DATETIME:包含日期和时间。如果插入数据时,字符值为空,字段的值就是空了。
- TIMESTAMP:包含日期和时间。如果插入数据时,设置字段的值为空,默认获取当前系统时间,把时间保存到字段中。
五、数据的操作
1.插入数据insert
1.1 插入数据的语法:
*insert into 表名 (字段1,字段2,字段3) values (值1,值2,值3);
*insert into 表名 values (值1,值2,值3);
1.2.注意事项
*插入的数据与字段类型必须是相同的。
*数据的大小范围在字段范围内
*值与字段一一对应
*字符串或者日期类型数据需要使用单引号
1.3实战
创建一个user新表:
create table user(id int,name varchar(30),birthday date,
entry_date date, job varchar(50), salary double, face varchar(30), gender char(5));
insert into user values (1,'meimei','1956‐1‐1','1957‐1‐1','HR',5000,'meimeimei','xx'); insert into user values (2,'小凤','1996‐1‐1','2013‐1‐1','BOSS',15000,'mei','xx');
insert into user values (3,'聪聪','1993‐11‐11','2015‐09‐10','WORKER',500.0,'chou','yy');
insert into user values (4,'如花','1994‐1‐1','2013‐1‐1','BOSS',25000,'mei','xx'); insert into user values (5,'小苍','1991‐1‐1','2014‐1‐1','BOSS',15000,'mei','xx'); insert into user values (6,'小泽','1986‐1‐1','2013‐1‐1','BOSS',15000,'mei','xx');然后使用上述sql语句,得到填好信息的表如下: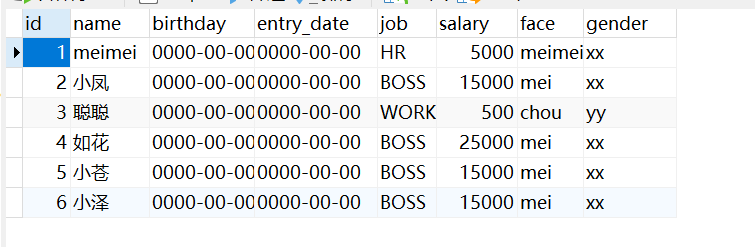
2.修改数据
2.1.语法
update 表名 set 字段1=值,字段2=值 where 条件;如果没有where条件语句,默认更新所有的数据。如果有where条件,默认更新符合条件的记录。
2.2.实战
#将所有员工薪水修改为5000元。
update user set salary = 5000;
#将姓名为’聪聪’的员工薪水修改为3000元。
update user set salary = 3000 where username = '聪聪';
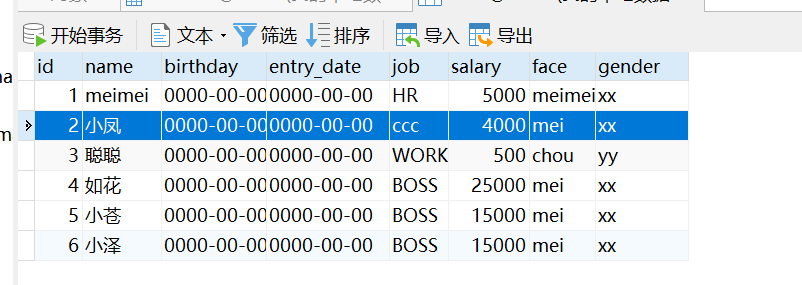
#将姓名为’小凤’的员工薪水修改为4000元,job改为ccc。
update user set salary = 4000,job = 'ccc' where username = '小凤';
#将如花的薪水在原有基础上增加1000元。
update user set salary = salary+1000 where username = '如花';以第三条为例:update user set salary = 4000,job='ccc' where name = '小凤';
3.删除数据
3.1.语法
delete from 表名 where 条件;.如果没有where条件,默认删除所有的数据。
truncate 表名;删除表中所有的数据。
delete from 表名; 也可以删除所有数据。
*区别: truncate先把你整个表删除掉,默默创建一个空的表(和原来的表结构是一样的)。
*delete from 表名 一行一行的删除。(使用它)
*事物的概念:事物提交和事物回滚。
3.2实战
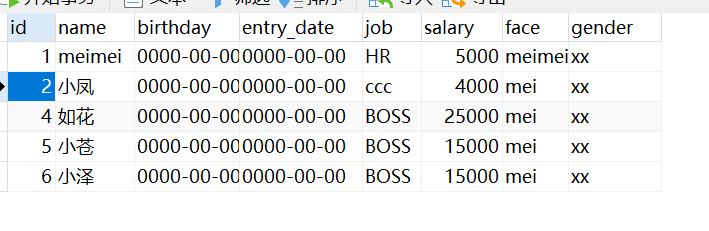
#删除表中名称为’聪聪’的记录。
delete from user where username = '聪聪';
#删除表中所有记录。
delete from user; drop table user;
以第一条为例:delete from user where name = '聪聪';
 4.查询数据
4.查询数据
4.1语法
*select * from 表名; *表示所有字段
*select 字段1,字段2,字段3 from 表名;
*DISTINCT ‐‐ 去除重复的数据(面试)
select distinct english from stu;
4.2实战
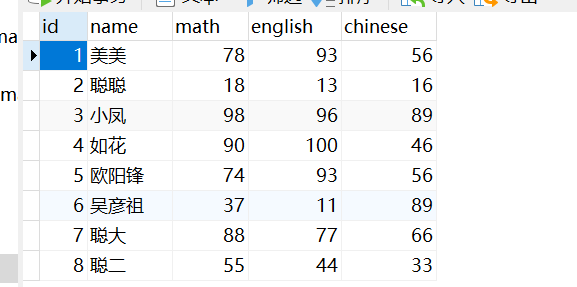
create table stu( id int,
name varchar(30), math int,
english int, chinese int
);
insert into stu values (1,'美美',78,93,56); insert into stu values (2,'聪聪',18,13,16); insert into stu values (3,'小凤',98,96,89); insert into stu values (4,'如花',90,100,46); insert into stu values (5,'欧阳锋',74,93,56); insert into stu values (6,'吴彦祖',37,11,89); insert into stu values (7,'聪大',88,77,66); insert into stu values (8,'聪二',55,44,33);建立一个新表进行查询:
4.3 查询语句中使用运算和别名
#在所有学生分数上加10分特长分。
select name,(math+10) m,(english+10) e,(chinese+10) c from stu;
#统计每个学生的总分。
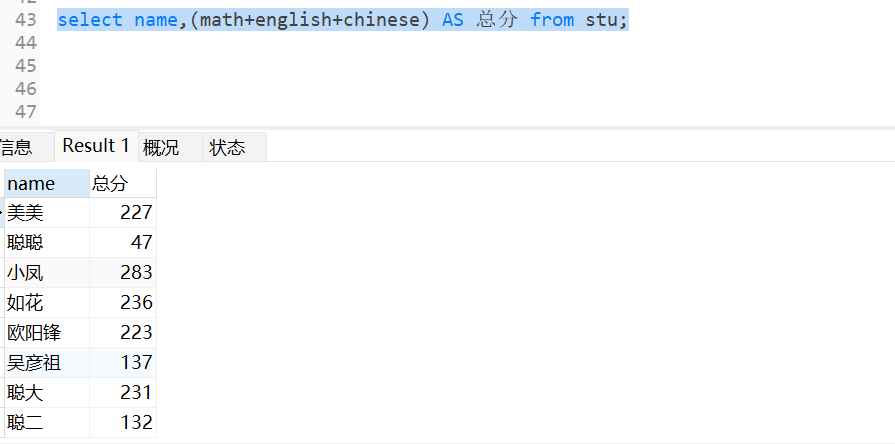
select name,(math+english+chinese) AS 总分 from stu;
4.4 where 条件语句
4.4.1 使用 where 过滤语句
#查询姓名为聪聪的学生成绩
select name,math,chinese from stu where name = '聪聪';
#查询英语成绩大于90分的同学
select name,english from stu where english > 20;
#查询总分大于200分的所有同学
select name,math+english+chinese from stu where (math+english+chinese) > 200;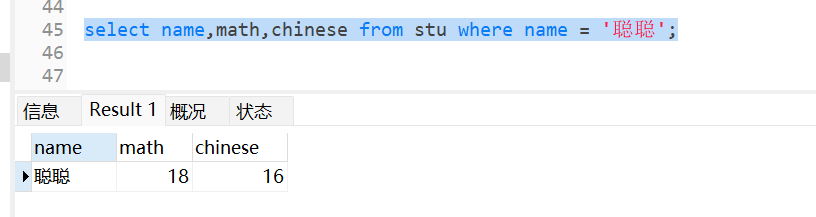
4.4.2where子句中出现的运算
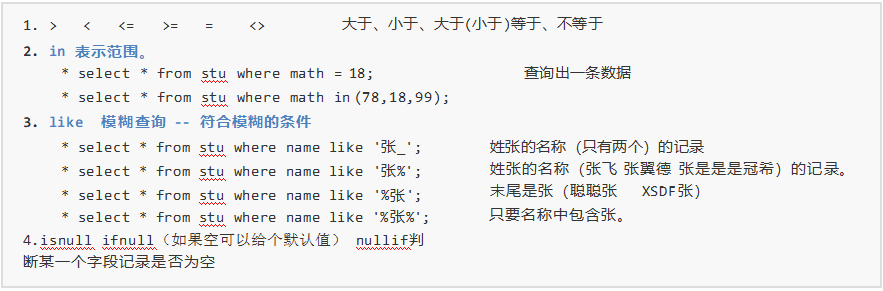
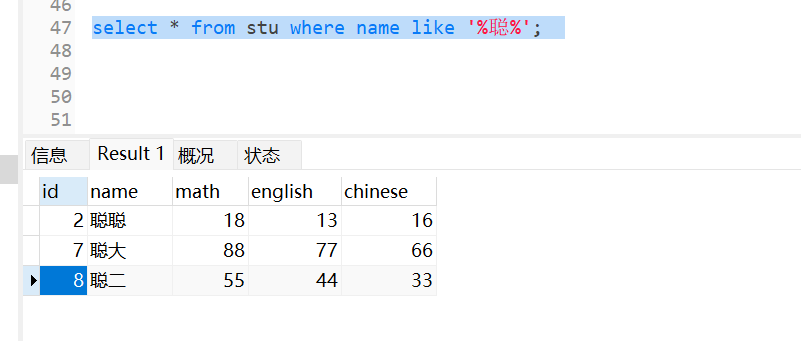
即select 列名(运算) from 表名(别名) where 条件(运算的符号);
isnull ifnull(如果空可以给个默认值) nullif判断某一个字段记录是否为空

4.4.3 order by 对查询的结果进行排序
排序的语法:select * from 表名 where 条件 order by 列名 升序/降序;
#升序和降序
order by 列名 asc;(升序,默认值)
order by 列名 desc;(降序)
#order by 子句必须出现在select语句的末尾。
#对数学成绩排序后输出。
select name,math from stu order by math desc;
#对总分排序按从高到低的顺序输出
select name,(math+english+chinese) as total from stu order by total desc;
#对姓聪的学生成绩按照英语进行降序排序,英语相同学员按照数学降序
select name,english,math from stu order by english desc,math desc;
#对姓聪的学生成绩排序输出
select name,(math+english+chinese) as total from stu where name like '聪%' order by total
desc;5.聚集函数
聚集函数:总计某一列数据总和。一列的个数。一列的平均数。一列中最大值和最小值。
聚集函数来操作列的。
5.1 常用函数
1.count 记数
2.sum 求和
3.avg
*语法:select avg(列名) from 表名;
4.max 求最大值
5.min 求最小值5.2实战
统计一个班级共有多少学生
select count(name) from stu;
统计数学成绩大于90的学生有多少个
select count(math) from stu where math >= 90;
统计总分大于220的人数有多少
select count(*) from stu where math + english+chinese > 200;
统计一个班级数学总成绩?
select sum(math) from stu;
统计一个班级语文、英语、数学各科的总成绩
select sum(math),sum(english),sum(chinese) from stu;
统计一个班级语文、英语、数学的成绩总和
select sum(ifnull(math,0)+english+chinese) from stu;
select sum(math) + sum(english) + sum(chinese) from stu;
* 编写一条更新语句
update stu set math = null where id = 2;
求一个班级数学平均分
select avg(ifnull(math,0)) from stu;
求一个班级总分平均分
select avg(ifnull(math,0)+english+chinese) from stu;
求班级英语最高分和最低分
select max(english) from stu; select min(english) from stu;第一个为例: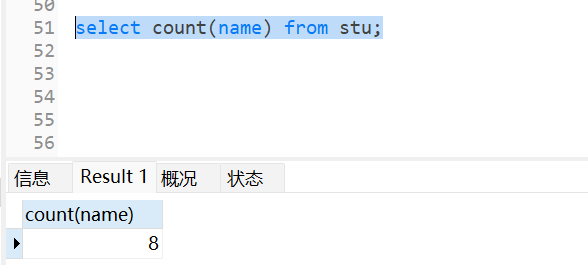
6.数据分组——使用group by 字段 进行分组
先建立一个新表:
create database day16; use day16;
create table orders( id int,
product varchar(20), price float
);
insert into orders(id,product,price) values(1,'电视',900); insert into orders(id,product,price) values(2,'洗衣机',100); insert into orders(id,product,price) values(3,'洗衣粉',90); insert into orders(id,product,price) values(4,'电视',900); insert into orders(id,product,price) values(5,'洗衣粉',90); insert into orders(id,product,price) values(6,'洗衣粉',90);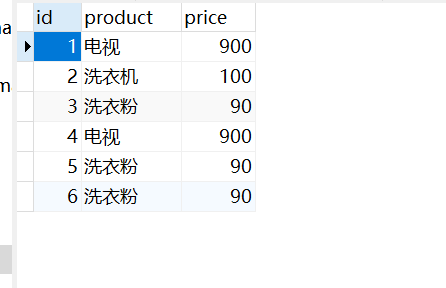
总结:
Having和where均可实现过滤,但在having可以使用聚集函数,where不能使用聚集函数,having通常跟在group by后,它作用于分组。
select ... from ... where ... group by ... having ... order by ...是 固定的顺序:如果没有上述的条件,把关键字去掉就ok。
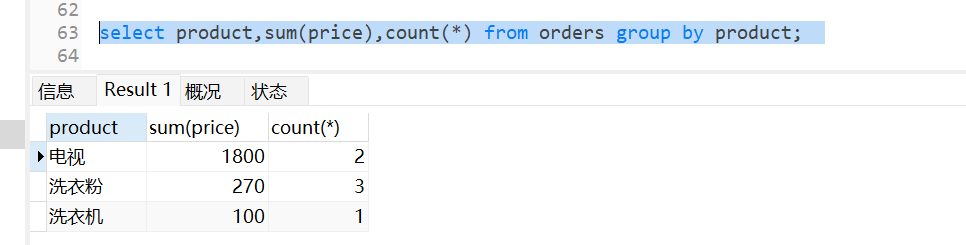
对订单表中商品归类后,显示每一类商品的总价
select product,sum(price),count(*) from orders group by product;
查询购买了几类商品,并且每类总价大于100的商品
select product from orders group by product having sum(price) > 100;
六、数据库修改密码
1.停止mysql服务:
services.msc 进入到服务界面
2.在cmd>输入一个命令:
mysqld ‐‐skip‐grant‐tables (开启一个mysql服务,不需要进行认证.)
3.新打开一个cmd窗口
mysql ‐u root ‐p 不需要输入密码.就可以进入.
4.输入命令 show databases;查看数据库,
5.输入命令 use mysql;使用mysql数据库。
6.修改密码的语句:
update user set authentication_string=password('root') WHERE user='root';
7.将两个窗口都关闭.
8.任务管理器中结束(mysqld)进程.
9.重启mysql服务
七、MySQL数据库备份和恢复
1.备份数据库表中的数据
命令:mysqldump ‐u 用户名 ‐p 数据库名 > 文件名.sql 回车后 再输入密码
2.恢复数据库(前提创建空的数据库,并且use)
命令:mysql –u 用户名 p 数据库名 < 文件名.sql 回车后 再输入密码
- 注意1:不是在数据库的登陆状态下
- 注意2:该命令后没有分号结束
- 注意3:注意 > 符号的方向
- 注意4:恢复数据库使用的命令是mysql,而不是mysqldump
八、单表的约束
1.代表记录的唯一的标识。
2.声明某一列作为主键*使用关键字 primary key
3.主键值的特点*唯一*非空*被引用
4.创建一张表,声明主键列
1 第一种--第一列加
create table person(
id int primary key, name varchar(30)
);
insert into person values (1,'聪聪'); insert into person values (2,'美美'); insert into person values (3,'小凤');
2 第二种---在末尾加
create table person( id int,
name varchar(30), primary key (id)
);
5.自增长
*可以去帮你维护主键的信息
*关键字:auto_increment
create table person(
id int primary key auto_increment, name varchar(30)
);
insert into person values (null,'聪聪'); insert into person values (null,'美美'); insert into person values (null,'小凤');
delete from person where id = 1;唯一和非空
- 唯一
- 非空
:声明值是唯一的
:声明值是不为空的
多表外键的约束
create table dept(
did int primary key auto_increment, dname varchar(30)
);
create table emp(
eid int primary key auto_increment, ename varchar(30),
sal double, dno int
);
insert into dept values (1,'研发部'); insert into dept values (2,'人事部');
insert into emp values (null,'聪聪',15000,1); insert into emp values (null,'邦邦',5000,1); insert into emp values (null,'美美',6000,2);
insert into emp values (null,'小凤',8000,2);
insert into emp values (null,'如花',8000,null);
问题:
*直接把研发部删除掉。delete from dept where did = 1; 能删除成功。
*在现实生活中,不合理。如果你避免问题的发生,两个表之间设置关系。
1.引入外键的约束
2.添加外键
*正常的情况下(一个部门有多个员工,一个员工只能属于一个部门)
*设置员工标签的dno字段,作为外键,指向部门表的主键。
*修改员工的表,在员工添加外键。
* alter table emp add foreign key emp (dno) references dept (did);
3.直接添加外键
*在创建表的时候,指定外键
create table emp(
eid int primary key auto_increment, ename varchar(30),
sal double, dno int,
foreign key emp(dno) references dept (did)
);
3.直接删除部门,这回不行了。
delete from dept where did = 1;

















 908
908

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









