







 本文介绍了统计学习的基础知识,包括data的划分,数据预处理的步骤,如处理格式、缺失值和异常值,以及算法的分类,如有监督、无监督、半监督和强化学习。同时,提到了生成式对抗网络(GAN)及其在数据生成中的应用。
本文介绍了统计学习的基础知识,包括data的划分,数据预处理的步骤,如处理格式、缺失值和异常值,以及算法的分类,如有监督、无监督、半监督和强化学习。同时,提到了生成式对抗网络(GAN)及其在数据生成中的应用。
一、data的理解
我们把data分为训练集和测试集,其中训练集用于建立模型,通常要占data的80%;而测试集则是用于预测分析,观察拟合出的模型的效果。
二、数据预处理
1、处理数据文件格式;
2、观察数据是否有缺失值或异常值;
3、是否需要对数据做归一化等处理;
4、是否需要降维。
三、算法
1、有监督学习(有人的干预)
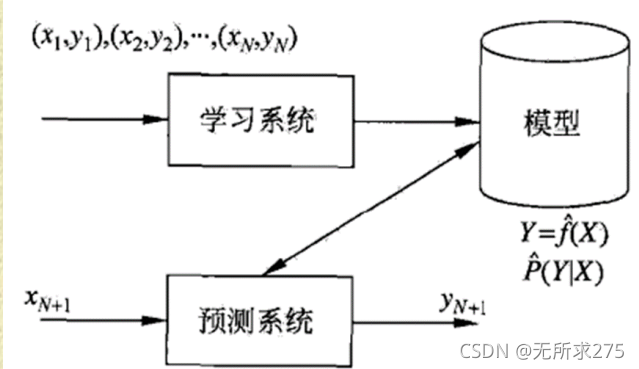
(x1,y1) …(xn,yn)中,y1,y2,…,yn等价于标签,即人为的分类,而xN+1、yN+1表示不带标签,类型未知。,其中argmax表示极大似然估计。
2、无监督学习(没有人的干预,容易造成误分类)
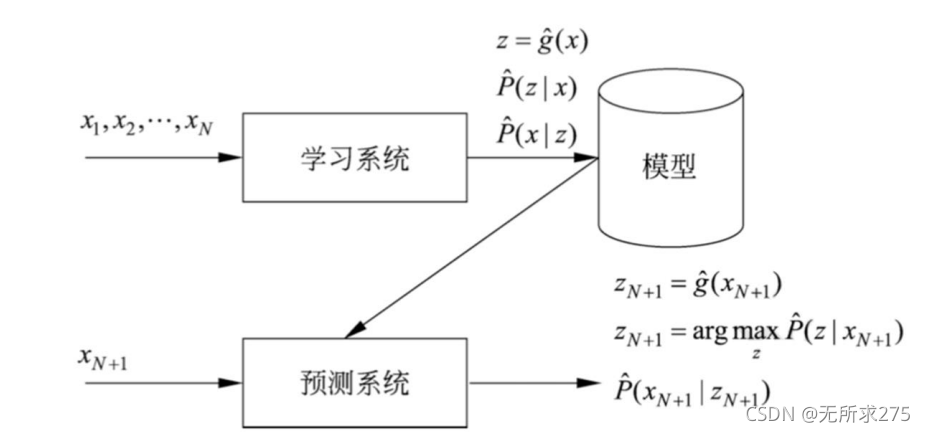
3、半监督学习(利用大量未标注数据信息辅助少量标注数据,具有较低成本)
4、强化学习(例如马尔可夫决策)
GAN:生成式对抗网络(GAN, Generative Adversarial Networks )是一种深度学习模型,是近年来复杂分布上无监督学习最具前景的方法之一。模型通过框架中(至少)两个模块:生成模型(Generative Model)和判别模型(Discriminative Model)的互相博弈学习产生相当好的输出。原始 GAN 理论中,并不要求 G 和 D 都是神经网络,只需要是能拟合相应生成和判别的函数即可。但实用中一般均使用深度神经网络作为 G 和 D 。一个优秀的GAN应用需要有良好的训练方法,否则可能由于神经网络模型的自由性而导致输出不理想。用于生产&获取数据。
四、统计学习的三要素
方法=模型+策略+算法

















 864
864

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









