






1)哨兵机制本质上是通过独立的进程来体现的,和之前的redis-server进程是完全不同的进程,redis-sentinel不负责存储数据,只是针对于其他的redis-server进程起到监控的效果,但是通常来说哨兵节点,也会搞一个集合,这本身是由多个哨兵节点构成的
2)主节点挂了,把选中的从节点,通过slave of no one自立山头,把其他的从节点,修改slave of 主节点的IP port连上新的主节点,告知客户端,修改客户端的配置,完成修改数据的操作,当之前挂了的的主节点修好了以后,就可以作为一个新的主节点挂到这组机器中,但是修复的过程中,至少需要半个小时,整个redis不能写?
1.监控:监控主节点和从节点的工作状态,及时发现某一个节点是不是挂了,哨兵本身会不断地进行检查Mater节点和从节点的工作状态
2.自动的故障转移:对于主节点如果要是挂了,就可以自动地挑选出一个主节点,保证整个redis主从还是可以进行读和写,全程不需要人工来干预,当一个主节点不能正常工作的时候,它会将失效主节点的中的其中一个从节点升级成新的主节点,并会让其他的失效master的其他从节点改为复制新的主节点,当客户端尝试重新连接失效的master,集群也会向客户端返回新的master的地址,使得集群可以使用新的master来代替失效的master
3.通知:自动通知客户端
Sentinel是基于心跳机制来实现检测服务状态,每隔1S钟会向集群中的每一个实例发送ping命令
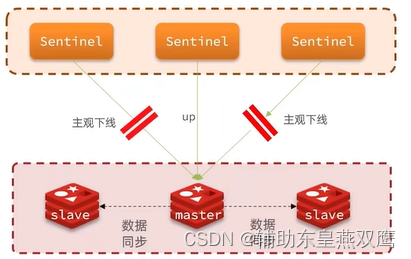
1)主观下线:如果某一个Sentinel发现某一个实例没有在规定时间内响应,那么说明是该实例主观下线,主观下线就是我个人认为你下线了,但是不一定真的下线了,因为这里是超时未响应,有可能网络阻塞没有及时得到结果,有可能是好的;
sdown主观不可用是单个sentinel自己主观检测的master的状态,从sentinel的角度来看,如果发送了ping心跳之后发现在一定时间内没有收到合法的回复,就达到了sdown的条件,默认是30s;
sentinel配置文件中的down-after-milliseconds设置了判断主观下线的时间长度
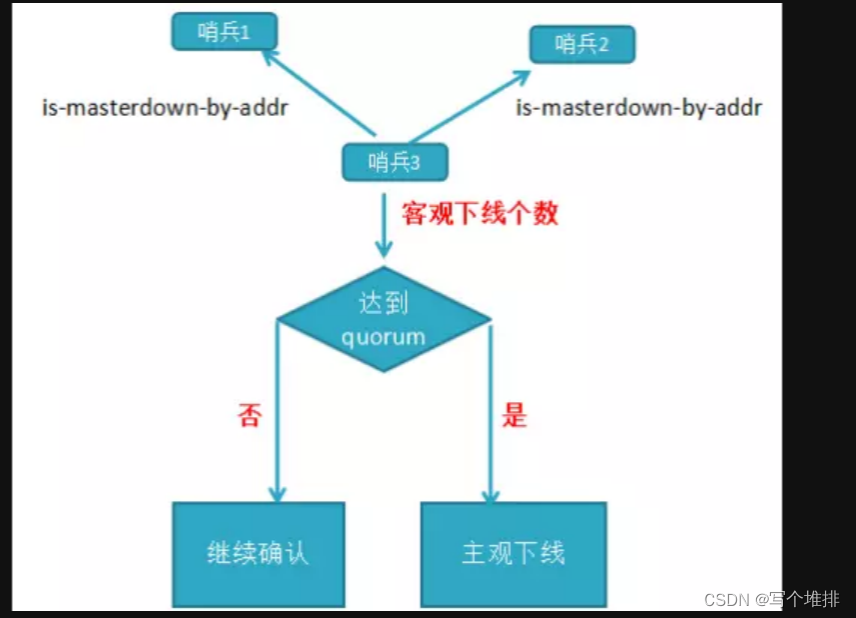
2)客观下线:如果超过指定数量的Sentinel(quorum)都认为该实例主观下线,那么该实例客观下线,quorum值最好超过Sentinel数量的一半,其实就是一个投票,认为是主观下线就是真的宕机,当主观下线的节点是主节点时,此时该哨兵节点会通过指令sentinel is-masterdown-by-addr寻求其它哨兵节点对主节点的判断,当超过quorum(法定人数)个数,此时哨兵节点则认为该主节点确实有问题,大部分哨兵节点都同意下线操作,也就是客观下线
odown需要一定数量的sentinel多个哨兵达成一定意见之后才能认为master客观上已经挂掉
3)哨兵是可以同时监控多个master的,一行一个
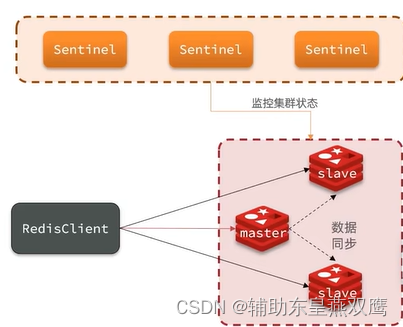


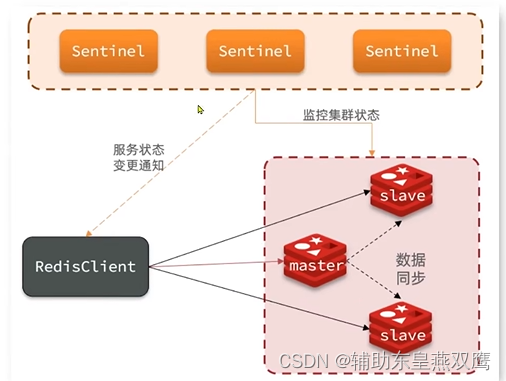
从上面来看,单独的redis sentinel进程提供了多个,并且这三个哨兵进程就会监控现有的redis master和slave,这些进程之间,会建立TCP长连接,通过这样的长连接就可以定期发送心跳包,借助上述的监控机制,就可以发现某一个主机是否挂了,如果是从节点挂了,没有关系,但是如果是主节点挂了,哨兵就需要发挥作用了
1)此时如果是一个哨兵节点发现主节点挂了,还不够,需要多个哨兵节点来共同确认这件事情,主要是为了防止误判
2)主节点确实是挂了,那么在这些哨兵节点中,就会推选出一个哨兵leader,由这个leader来负责从现有的从节点中,选取一个作为新的主节点
3)挑选出新的主节点以后,哨兵节点就会自动控制被选中的从节点,执行slave of no one命令,并且控制器其他从节点修改slave of到新的主节点上面
4)哨兵机制会自动地通知客户端程序,告知新的主节点是谁,并且后续客户端再来执行写操作,就会针对于新的主节点进行操作了
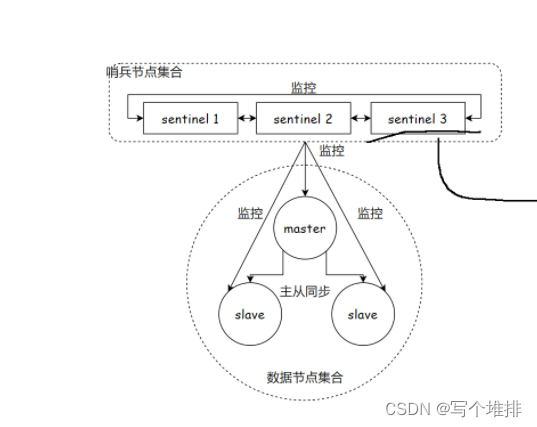
其实redis哨兵节点只有一个也是可以的
1)但是如果哨兵节点只有一个,它自身也是十分容易出现问题的,万一这个redis哨兵节点挂了,就无法进行自动的恢复过程了
2)出现误判的概率也是比较高的,毕竟网络传输数据时容易出现抖动或者是延迟或者是持续性丢包的,如果只有一个哨兵节点,出现上述问题后,影响就比较大,所以说在分布式系统中,应该避免使用单点
因为分布式一方面是为了高可用,不能说一个服务器出现了问题,影响到整体的使用,效率也就是为了引入更多的硬件资源,如果全部放到一个机器上面了,那么两个条件都没有达成
1.安装docker和docker compose,docker compose管理多个容器,docker中关键概念,容器,看作是一个轻量级的虚拟机
2.停止redis服务器:后续使用docker启动redis的时候,在docker里面可能占用宿主机的端口号
3.使用docker获取到redis的镜像,在docker中,镜像和容器相当于是可执行程序和进程之间的关系,镜像可以自己构建,也可以直接拿别人已经构建好的,dockerhup包含了很多其他大佬们构建好的镜像,也提供了官方提供好的镜像,直接拖下来就可以使用,可以基于这一个镜像来创建出多个容器,所以想要创建容器,必须先获取到镜像,镜像可以自己构建也可以拿别人构建好的,也提供了redis官方提供好的镜像,直接拖下来就可以使用;
4.docker pull redis:5.0.9,git pull是使用git从中央仓库拉取代码,docker pull是使用docker从中央仓库来拉取镜像,默认是从dockerhup,本身拉取到的镜像,里面就包含一个精简的linux操作系统,并且上面会安装redis
5.拉取到的镜像,里面包含一个精简的linux操作系统,并且在上面会安装redis,只要直接基于这个镜像创建出一个容器跑起来,此时redis服务器就直接搭好了;
6.基于docker搭建redis哨兵模式,docker compose由于此处涉及到redis-server,也有多个redis哨兵节点,每一个redis-server或者是每一个redis哨兵节点都是作为一个单独的服务器,1个主节点,2个从节点,3个哨兵节点
7.通过一个配置文件,把具体的要创建哪些容器,每一个容器运行时的各种参数,描述清楚,后续通过一个简单的命令,就可以批量的启动/停止这些容器了
1.创建三个容器,作为redis的数据节点,一个主节点,两个从节点,先启动
2.创建三个容器,作为redis的哨兵节点,后启动
在这里面也可以使用同一个yml文件来直接启动6个容器,如果是把这6个容器同时启动
2.1)在docker容器中可以理解成是一个轻量级的虚拟机,在这个体系里面,端口号和外面宿主机的端口号是两个体系,如果容器外面使用了5000端口,那么在容器内部也是可以使用5000端口,彼此之间不会冲突,有的时候希望在容器外部可以访问到容器内部的端口号,就可以把容器内部的端口映射成宿主机的端口
2.2)容器内部的端口,三个容器每一个容器内部的端口号都是自成一个小天地,容器1的6379和容器2的6379之间是不会有冲突的,可以把容器视为是两个主机,有的时候需要从容器外访问容器内部的端口,需要进行端口映射,把容器内部的端口映射到宿主机上,后续访问宿主机上面的某一个端口,就相当于是在访问对应的容器的对应端口了,站在宿主机的角度来说,访问上述几个端口的时候,需要有时候进行端口映射,访问上述几个端口的时候,也不知道是这个端口实际上是一个宿主机上的服务,还是一个容器内部的服务,只要能够正常使用即可
2.3)在command命令中,不必写主节点的IP,直接写主节点的容器名字,容器名字类似于域名一样,docker可以自动进行解析,就可以得到对应的IP
version: '3.7'---版本号固定 services: ---接下来我们要通过docker-compose来启动哪些服务器,每一个服务器都是一个服务 master: image: 'redis:5.0.9' container_name: redis-master restart: always--是否自动重启,异常情况终止是否自动重启 command: redis-server --appendonly yes---启动redis服务器使用的命令行选项 ports: - 6379:6379 --端口映射 slave1: image: 'redis:5.0.9' container_name: redis-slave1 restart: always command: redis-server --appendonly yes --slaveof redis-master 6379 ports: - 6380:6379 slave2: image: 'redis:5.0.9' container_name: redis-slave2 restart: always command: redis-server --appendonly yes --slaveof redis-master 6379 ports: - 6381:6379启动所有容器:docker-compose up -d
查看运行状态:docker ps -a
并可以通过redis-cli -p 6379 连接redis,通过info repication就可以看到拓扑结构

1)编排redis-sentinel节点,也可以把redis-sentinel放到上面的redis的同一个yml文件中进行编排,此处分成两组,主要是为了两方面:观察日志方便和确保redis主从节点启动之后才启动redis-sentinel,如果先启动redis-sentinel的话,可能会触发额外的选举过程,混淆视听
2)redis哨兵节点是单独的服务器进程
version: '3.3' services: sentinel1: image: 'redis:5.0.9' container_name: redis-sentinel-1 restart: always command: redis-sentinel /etc/redis/sentinel.conf volumes: - ./sentinel1.conf:/etc/redis/sentinel.conf ports: - 26379:26379 sentinel2: image: 'redis:5.0.9' container_name: redis-sentinel-2 restart: always command: redis-sentinel /etc/redis/sentinel.conf volumes: - ./sentinel2.conf:/etc/redis/sentinel.conf ports: - 26380:26379 sentinel3: image: 'redis:5.0.9' container_name: redis-sentinel-3 restart: always command: redis-sentinel /etc/redis/sentinel.conf volumes: - ./sentinel3.conf:/etc/redis/sentinel.conf ports: - 26381:26379bind 0.0.0.0 port 26379 sentinel monitor redis-master redis-master 6379 2 #告诉哨兵节点监控哪一个一个redis服务器,2表示法定票数,表示至少有两个哨兵节点认为redis主节点挂了,那么redis就挂了,防止哨兵节点在进行判定的时候网络抖动 sentinel down-after-milliseconds redis-master 1000 #心跳包的超时时间
1)此处这个redis哨兵节点不认识redis-master,redis-master相当于是域名,docker会进行域名解析,docker会将域名解析成对应主节点的IP地址,docker-compose一下子启动了N个容器,这N个容器都是处于同一个局域网中,每当我们使用docker-compose启动了N个容器,相当于是创建了一个局域网,然后就可以使这N个容器之间可以相互访问,三个redis-server书属于同一个局域网,三个哨兵节点又是一个局域网,默认情况下,这两个网络不是互通的
2)解决方案就可以使用docker-compose把此处的两组服务器给放到同一个局域网里面,通过docker network ls来列出当前docker的局域网
3)此处先启动了三个redis-server节点,就相当于是自动创建了第一个局域网,在启动后面的三个哨兵节点,就直接让这三个节点加入到上面的局域网中而不是创建新的局域网


1)哨兵节点存在的意义就是能够在redis主从结构出现问题的时候,比如说主节点挂了,此时哨兵节点就可以自动帮我们选出一个主节点来代替之前挂过的节点,保证整个redis仍然是可用状态
docker ps -a 列举出当前运行的redis进程
docker stop redis-master 停止对应的redis进程
docker-compose logs 查看对应节点运行的日志
docker-compose up -d 启动所有容器
2)sdown:主观下线,本哨兵节点认为该主节点挂了
odown:客观下线,好几个哨兵节点都认为该节点挂了,达成了一致,也就是客观票数,此时主节点挂了这个事情就被实锤了,此时就需要哨兵节点选出一个新的主节点,此时就需要提拔出一个新的主节点
一)哨兵重新选举主节点的流程:
1)主观下线:哨兵节点通过心跳包,判定redis服务器是否正常工作,如果心跳包没有如期而至,就认为redis服务器挂了,此时还不能排除网络抖动的和波动的影响,因此就只能是单方面认为这个redis节点挂了
哨兵节点每隔1s会对主节点和从节点,其他哨兵节点发送ping做心跳检测,当这些心跳检测时间超过down-down-after-milliseconds时,哨兵节点则认为该节点错误或下线,这叫主观下线;这可能会存在错误的判断
2)客观下线:多个哨兵节点都认为主节点挂了,认为挂了的哨兵节点数目达到法定票数,哨兵就认为这个主节点客观下线,当主观下线的节点是主节点的时候,此时哨兵会通过指令sentinel-is-masterdown-by-addr寻求其他哨兵节点对于主节点的判断,当超过quorum法定人员个数,此时哨兵节点则认为该主节点确实有问题,这样子就是客观下线
3)这时候要让多个哨兵节点,选出一个Leader节点,由这个leader节点负责选出一个从节点作为一个主节点
4)此时哨兵leader选取完毕,leader就需要挑选出一个从节点,来作为新的主节点
4.1)优先级:每一个redis数据节点,都会在配置文件中,有一个优先级的设置,slave-prioripty,优先级大的从节点就会优先胜出
4.2)offset越大,就胜出,offset从节点从主节点这边同步数据的进度,数值越大,说明从节点和主节点的内存状态就越接近
4.3)runID:每一个redis节点启动的时候随机生成的一段数字,大小全凭缘分了
5)把新的主节点指定好了以后,leader就会控制这个节点,执行slave no one命令,成为主节点,再来控制其他主节点,执行slave of让其他的这些从节点,认新的master作为主节点了
Redis 哨兵模式下,Master节点宕机后,进行故障转移的过程_+failover-state-wait-promotion-优快云博客
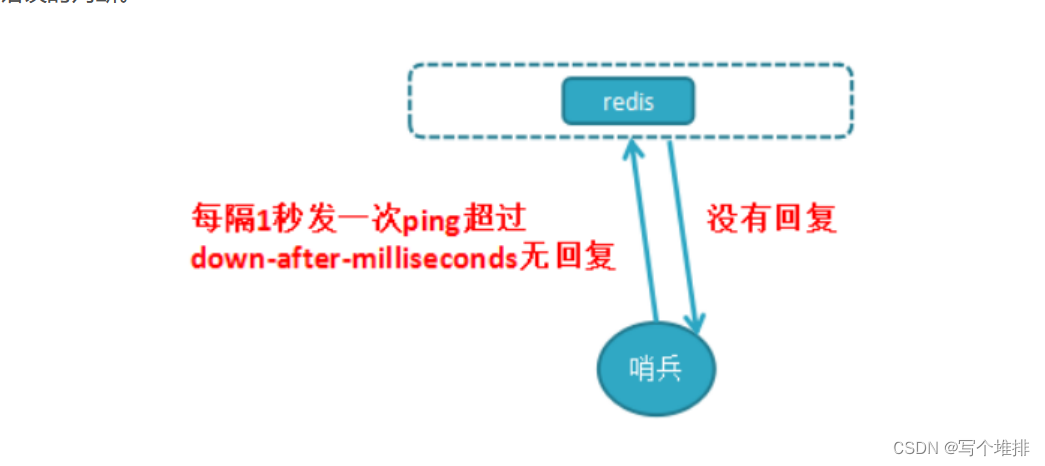


是否有可能出现非常严重的网络波动,导致所有的哨兵节点都无法连接上这个redis主节点被误判成挂了呢?
当然是有的,如果出现这种情况,怕是所有的用户的客户端也连不上redis主节点了,基本上这个主节点也无法正常工作了,挂了不一定是进程崩了,只要无法正常访问,都可以认为是挂了
这就非常类似于说在学校,A,B,C讨论说D有病了,谁能够代替D去给同学们上一课?
此时A站出来说,我来推进这个事情,此时A和B说好的
一定要注意这个选举的过程,不是由所有哨兵节点选举出新的主节点,而是先进行选取哨兵leader,再来由哨兵leader负责后续的主节点指定
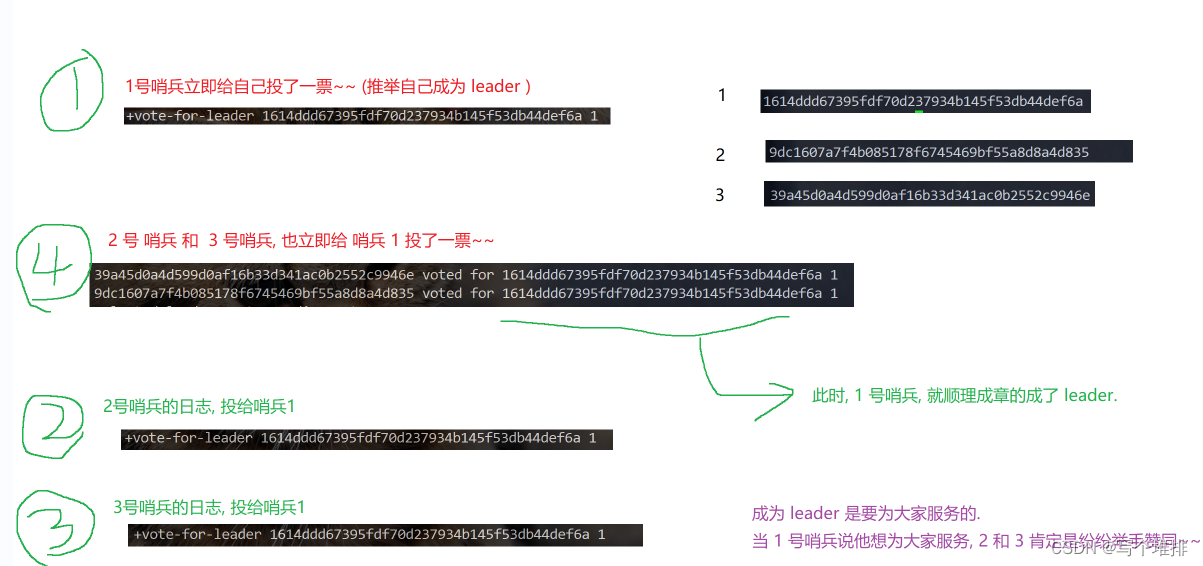
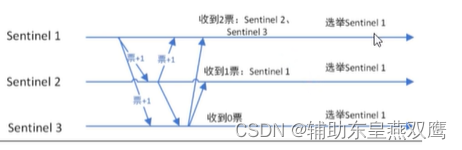
1)每一个哨兵手里面只有一票,当哨兵1第一个发现是客观下线以后,就立即给自己投了一票,并且告诉了2和3,我来负责这个事情,2,3反应慢了半拍,才发现是客观下线,2和3一看1愿意负责这个事情,就立即投了赞成票,当2和3当他们没有投出这个票的时候,收到拉票请求,此时就会投出去,如果发现有多个拉票请求,此时就会先投给先到达的
2)如果说总的票数超过了哨兵节点的一半,选举完成了,把哨兵个数设置成奇数个节点,就是为了方便投票,其实上述的投票过程,就是为了比较谁的反应小,谁的网络延时小
总结:
1)哨兵节点不能只有一个,否则哨兵节点挂了也会影响系统可用性
2)哨兵节点最好有奇数个,方便选取leader,得票更容易超过半数
3)哨兵节点本身并不会存储数据,仍然是主从节点 负责存储数据,哨兵节点可以使用一些配置不高的机器来进行部署,但是不能搞一个机器来部署三个哨兵
4)主从复制所解决的问题是为了提升可用性,但是不能解决极端情况下写丢失的问题,比如说现在主节点写入的数据信息还没有来得及同步给从节点,主节点就挂了
5)哨兵+主从不能提升数据的存储容量,当我们需要存储的数据接近或者是超过机器的物理内存,这样的结构就难以胜任了
二)哨兵的定时监控机制:
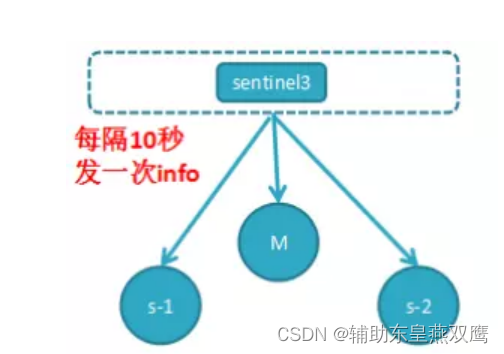
1)每一个哨兵节点每隔10s会向主节点和从节点发送info命令来进行获取到最拓扑结构图,哨兵模式只要配置好主节点的监控即可,通过向主节点发送info,来获取到从节点的信息,这样就可以做到当有新的从节点加入的时候可以很快地感知到
2)每个哨兵节点每隔2秒会向redis数据节点的指定频道上发送该哨兵节点对于主节点的判断以及当前哨兵节点的信息,同时每个哨兵节点也会订阅该频道,来了解其它哨兵节点的信息及对主节点的判断,其实就是通过消息publish和subscribe来完成的
3)每隔1秒每个哨兵会向主节点、从节点及其余哨兵节点发送一次ping命令做一次心跳检测,这个也是哨兵用来判断节点是否正常的重要依据
三)raft算法:
这个算法描述的是哨兵需要把剩余的slave节点中挑选出一个作为新的master,这个工作本质上是不需要所有的哨兵都进行参与,只需要选出一个代表,称之为是leader,由leader负责进行slave节点升级成master节点的提拔过程
1)每一个哨兵节点都会给其他的哨兵节点发送一个is-master-down-by-addr命令,征求判断并要求将自己设置为领导者,由领导者处理故障转移(S1->S2,S1->S3,S2->S1,S2->S3,
S3->S1,S3->S22)收到拉票请求的节点,会回复一个投票响应,相应的结果有两种可能,投票或者不投票
比如说S1给S2发送一个投票请求,S2就会给S1回应一个投票响应,到底S2给不给S1投票呢,完全取决于S2是否已经给别人投过票了,如果S2没有给其他人投过票,换而言之就是S1是第一个向S2拉票的,那么S2就会直接投S1否则就不投
3)一轮投票完成以后,发现得票数超过一半的节点,自动升级成leader,但是如果出现平票的情况,S1投给S2,S2投给S3,S3投给S1,那么就重新再投一次即可,这也就是说为什么哨兵节点设置成奇数个的原因,如果是偶数个,那么就增大了平票的概率带来不必要的开销
简而言之就是raft算法的核心就是先下手为强,谁率先发起了拉票请求,谁就有更大的概率成为leader,这里面的决定因素就是网络延时,本身网络延时就具有一定的随机性
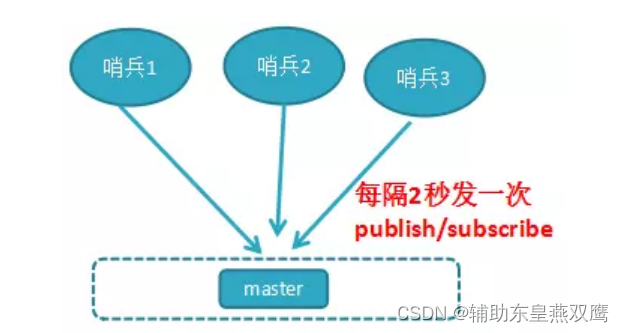
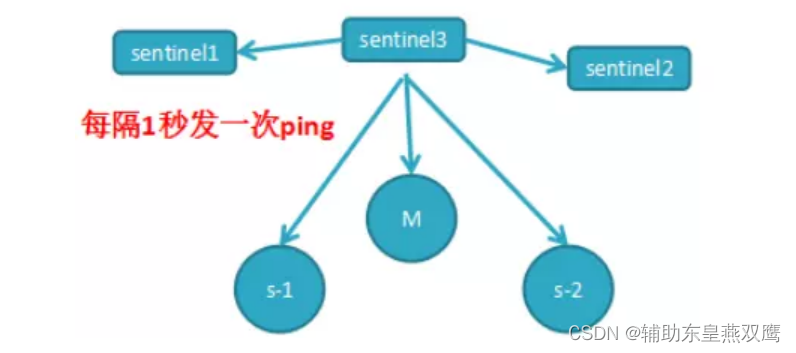
领导者哨兵选举流程:选举出领导者哨兵也就是兵王leader
1)首先每一个在线的哨兵节点都可以成为领导者,当他进行确认主节点进行下线的时候,会向其他哨兵发送is-master-down-by-addr命令征求判断并要求将自己设置成领导者,并且有领导者进行故障转移
2)当其他哨兵进行收到这个命令的时候,可以同意或者拒绝他成为领导者
3)如果哨兵发现自己的票数大于等于num(sentinels)/2+1将成为领导者,如果没有超过,那么继续选举
4)监视主节点的所有哨兵都有可能成为领导者,选举使用的算法是Raft算法,Raft算法的思想就是先到先得,即在一轮选举当中,哨兵A向哨兵B发送自己想要成为领导者的申请,如果B没有同意过其他哨兵,则会同意A哨兵成为领导者;
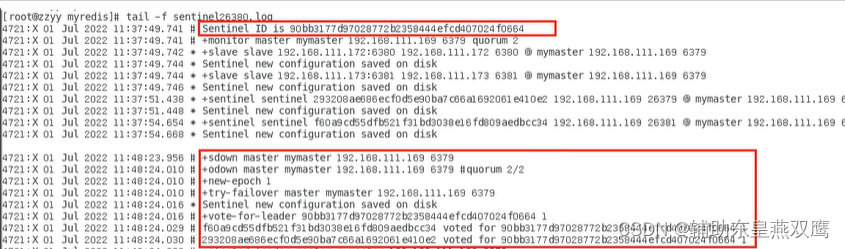
1)new-epoch开始进行一轮新的投票
2)try-failover master mymaster Ip地址尝试进行新一轮的故障转移
3)vote-for-leader有当前节点选举出新的兵王
4)下面表示两个哨兵节点的ID,voted-for,都尝试给当前的节点进行投票,当前节点也就是0664,于是0664成为兵王
5)swith-master是交换主节点,+slave是设置两个从节点,重新设置从节点信息

搭建哨兵集群:
1)计划搭建一个三节点组成的Sentinel集群,来进行监管之前的Redis主从集群
2)这三个Sentinel的集群是搭建在同一台linux服务器的,所以他们的IP地址都是相同的
3)创建3个文件夹为s1和s2和s3,我们还需要进行准备三份不同的配置文件和目录,配置文件所在的目录就是工作目录
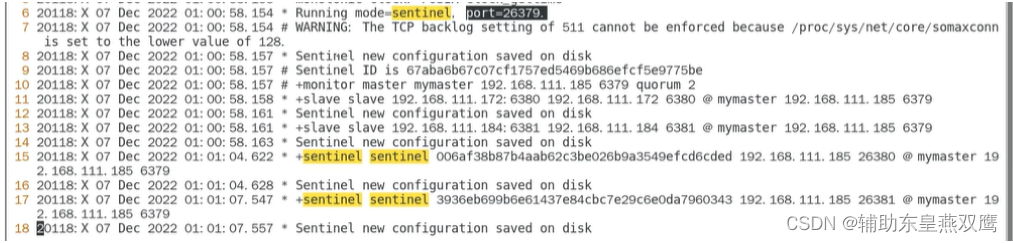
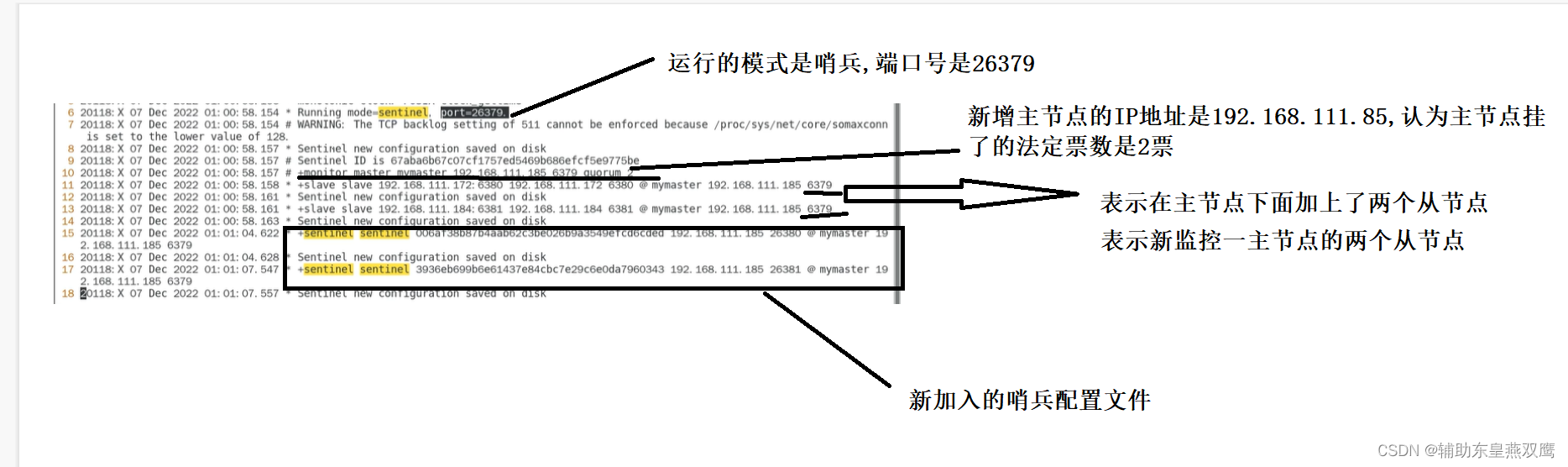
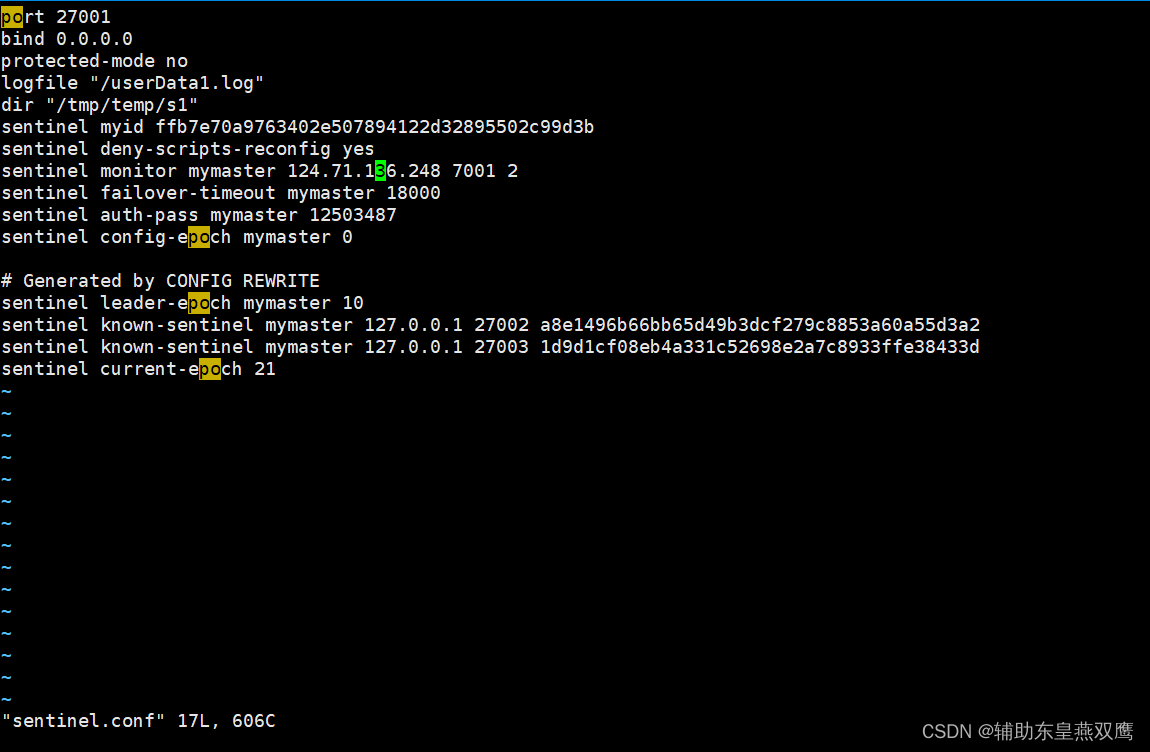
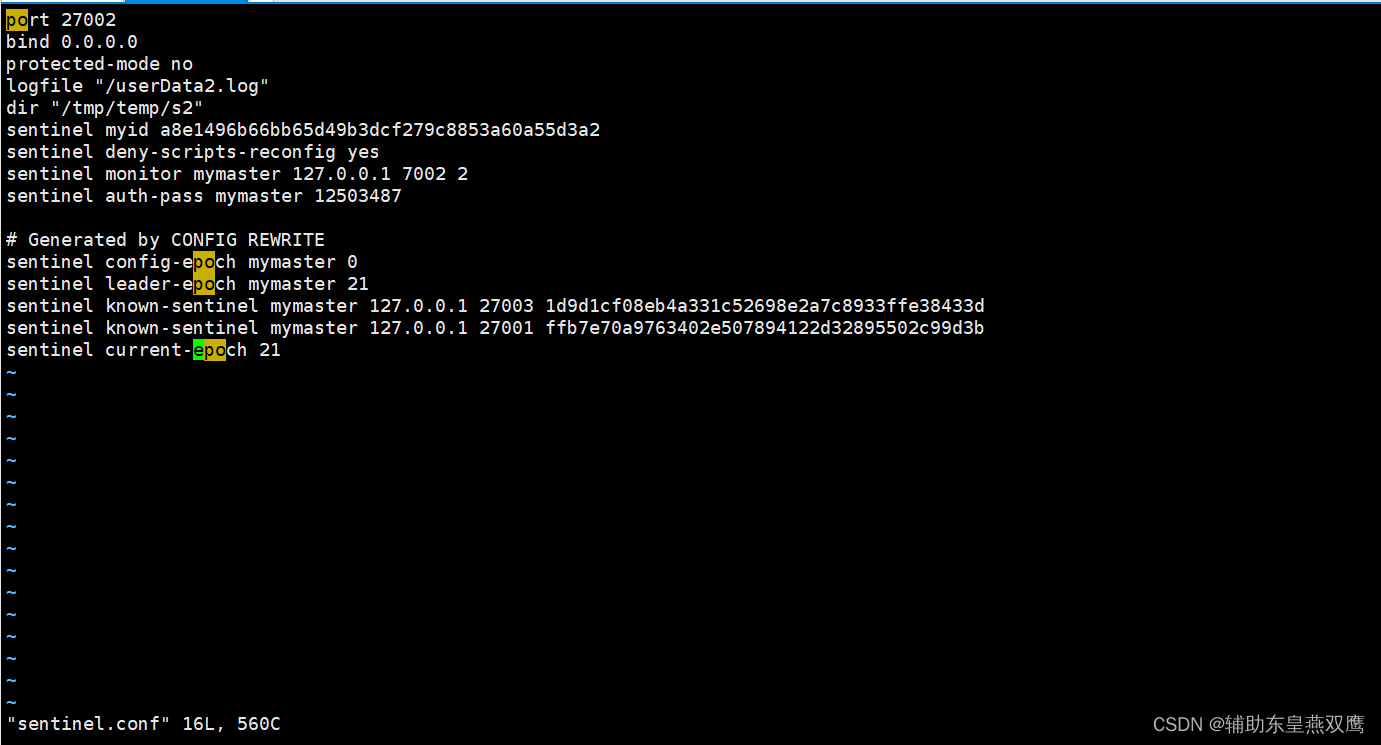
4)我们先在s1目录下面创建一个sentinel.conf文件,来添加以下的内容
port 端口号(也就是Sentinel的端口号,多个Sentinel有不同的端口号) bind 0.0.0.0 protected-mode no logfile "/userData1.log" #sentinel的工作目录 dir "/tmp/temp/s1" sentinel auth-pass mymaster 12503487 #上面的信息是master进行设置了密码,通过这个密码来和master做连接 设置哨兵sentinel 连接主从的密码 注意必须为主从设置一样的验证密码 sentinel monitor mymaster 127.0.0.1 7001 2 #声明监控信息,mymaster是集群的名称,先监控master,监控master从master可以得到从节点的信息 #虽然你声明的是master,但是你监控的是整个集群 #后面的2表示quorum的值,也就是说超过quorum数量的sentinal认为该节点主观下线,那么该节点客观下线 quorum表示最少有几个哨兵认可客观下线同意故障迁移的法定票数 #就是master真的下线 sentinel down-after-milliseconds mymaster 30000 哨兵主观上认为主节点下线时间 sentinel failover-timeout mymaster 180000
相关的配置文件的信息:
1)sentinel down-after-milliseconds+主节点的名字+指定的毫秒数,表示指定多少毫秒之后,主节点没有进行应答哨兵,此时哨兵主观上认为主节点下线
2)sentinel failover-timeout 主节点的名字+指定的毫秒数,故障转移的超时时间,当进行故障转移的时候,如果超过指定的毫秒数,那么此次转移失败,如果master迟迟上不来,选举成功,转移失败

5)启动sentinel
redis-sentinel /tmp/temp/s1/sentinal.conf
三个主从节点的内容会在运行期间被sentinel动态的修改,当主从模式进行替换之后,主节点的配置文件和从节点的配置文件都会发生改变,况且主节点的redis.conf中会新增一行slaveof的配置,随之sentinel.conf的监控目标也会随之发生改变
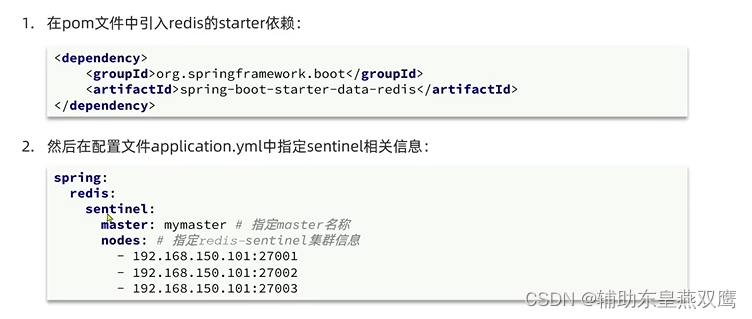
StringRedisTemplate的哨兵模式:
1)在sentinel集群监控下的Redis主从集群,其节点会因为自动故障转移而发生变化,Redis的客户端必须要感知这种变化,及时更新连接信息,Spring中的RedisTemplate底层利用了letture实现了节点的自动感知和切换;
2)有密码还要配置密码
@Bean public LettuceClientConfigurationBuilderCustomizer clientConfiguration(){ return new LettuceClientConfigurationBuilderCustomizer() { @Override public void customize(LettuceClientConfiguration.LettuceClientConfigurationBuilder clientConfigurationBuilder) { clientConfigurationBuilder.readFrom(ReadFrom.REPLICA_PREFERRED); } }; }这里面的ReadForm是配置Redis的读取策略,是一个枚举,包括下面的选择:
1)MASTER:从主节点来进行读取
2)MASTER_PREFERRED:优先从master节点来进行读取,master节点不可以使用的时候才会读取从节点
3)REPLICA:从slave节点来进行读取
4)REPLIA_PREFERRED:优先从slave节点来进行读取,所有的slave节点不可以使用的时候才会读取master节点;


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









