







 本文深入探讨了Hive与MySQL在查询语句上的差异,包括HQL的执行顺序、复合类型数据查询、正则表达式、排序方式、表关联、视图、子查询、开窗函数、抽样查询以及Hive调优等方面。重点介绍了Hive的窗口函数、抽样查询策略以及HQL优化技巧,如避免多余操作、利用grouping sets和cube进行聚合优化。
本文深入探讨了Hive与MySQL在查询语句上的差异,包括HQL的执行顺序、复合类型数据查询、正则表达式、排序方式、表关联、视图、子查询、开窗函数、抽样查询以及Hive调优等方面。重点介绍了Hive的窗口函数、抽样查询策略以及HQL优化技巧,如避免多余操作、利用grouping sets和cube进行聚合优化。
本文主要内容
-
HQL查询语句与MySQL执行顺序的区别;
-
Hive复合类型的数据查询、正则查询以及Hive独有的排序方式;
-
Hive语句的表关联语法;
-
Hive子查询的限制;
-
Hive开窗函数的语法包含偏移函数、统计函数和排序函数;
-
Hive抽样查询的语法包含随机抽样、数据块抽样和分桶抽样;
-
Hive调优分为环境调优和HQL语句调优;
-
Hive总结与扩展explode函数和lateral 虚拟表的用法。
目录
3.7.4 聚合技巧—利用窗口函数grouping sets、cube
3.8.2 扩展函数explode和 lateral 虚拟表
第三节 查询语句
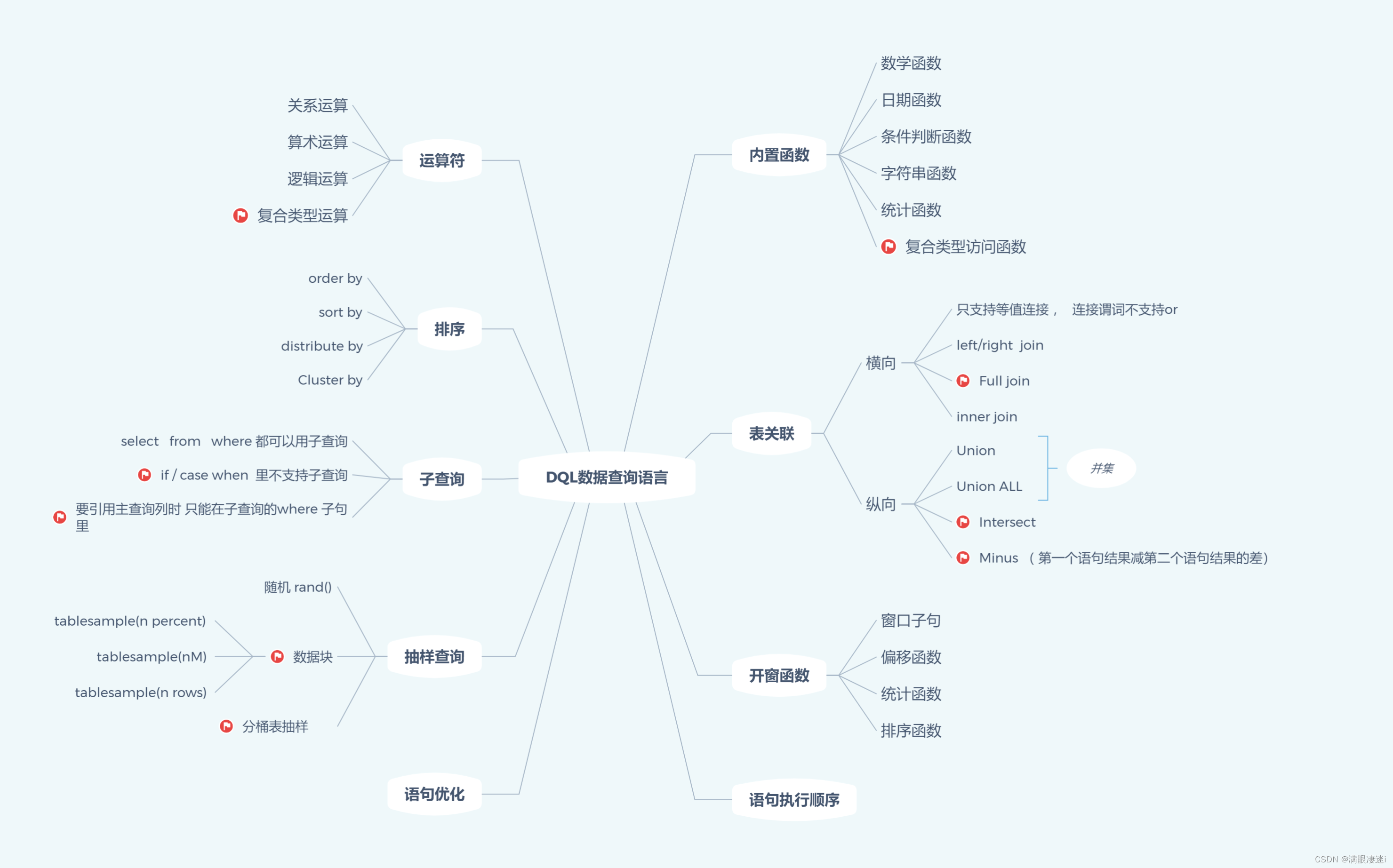
- 有红色标记的表示为与MySQL差异的用法
-
开窗函数很重要,考SQL语句基本必考开窗函数
-
专门服务复合类型的函数:explode——炸裂函数
-
Hive常用内置函数与运算符可查看文件
 https://download.youkuaiyun.com/download/weixin_61336263/85883422
https://download.youkuaiyun.com/download/weixin_61336263/85883422
3.1 Select 语句结构
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list]
[HAVING having_condition]
[CLUSTER BY col_list | [DISTRIBUTE BY col_list] [SORT BY col_list]][ORDER BY col_list]
[LIMIT number];
-
ORDER BY排序字段 和 limit 后字段 不能是计算字段
-
!!排序字段需要注意是数值类型还是字符串类型!!
3.1.1 HQL与MySQL语句执行顺序区别
- 差异原因:HDFS中的MapReduce分而治之,分而后合的工作原理所致。
1、HQL 语句执行顺序(explain可查看执行顺序):
from -->where --> select --> group by -->聚合函数--> having --> order by -->limit
-
Group by 后的 select 只能有 group by 的字段和聚合函数
2、MySQL语句执行顺序:
from-->where --> group by -->聚合函数--> having--> select --> order by -->limit
3、一个Hive任务会包含一个或多个stage(阶段),不同的stage间会存在着依赖关系。
-- 感兴趣可以复制到Hue查看运行顺序
explain
select gender, count(1) as renshu from emp_pt
where emp_no >10100
group by gender
having renshu > 1
order by renshu desc
limit 10;
3.1.2 复合类型的数据查询
- 语法1:数组(array) 引用方式: 列名[元素索引_以0开始]
--示例:访问数组中最后一个名字以W开头的
select * from emp
where emp_name[1] rlike "^W" -- [rlike "^W"] 正则表达: 等同于 [like "W%"]
/* 通配运算符形式:
1.like通配符运算和MySQL一样,选择条件可以包含字符或数字:'%'代表(任意个字符);'_'代表一个字符
2.rlike子句是Hive中这个功能的一个扩展,可以通过Java的正则表达式这个更强大的语言来指定匹配条件
*/
- 语法2:map 引用方式: 列名["Key"]
--示例: 访问Map中出生日期是在5几年
select * from emp
where emp_date["birth_date"] between to_date("1950-1-1") and to_date("1959-12-31")
--对于括号内的["1950-1-1"]和["1959-12-31"]的 字符串 需要用 to_date 转化成日期类型
- 语法3:结构体引用方式: 列名. 子列名
-- 示例:访问结构体中性别为男的员工
select * from emp
where other_info.gender="M"3.1.3 正则查询
-
rlike + 正则表达式
| 字符 | 说明 |
|---|---|
| \ | 将下一字符标记为特殊字符、文本、反向引用或八进制转义符。例如,"n"匹配字符"n"。"\n"匹配换行符。序列""匹配"","("匹配"("。 |
| ^ | 匹配输入字符串开始的位置。如果设置了 RegExp 对象的 Multiline 属性,^ 还会与"\n"或"\r"之后的位置匹配。 |
| $ | 匹配输入字符串结尾的位置。如果设置了 RegExp 对象的 Multiline 属性,$ 还会与"\n"或"\r"之前的位置匹配。 |
| * | 零次或多次匹配前面的字符或子表达式。例如,zo* 匹配"z"和"zoo"。* 等效于 {0,}。 |
| + | 一次或多次匹配前面的字符或子表达式。例如,"zo+"与"zo"和"zoo"匹配,但与"z"不匹配。+ 等效于 {1,}。 |
| ? | 零次或一次匹配前面的字符或子表达式。例如,"do(es)?"匹配"do"或"does"中的"do"。? 等效于 {0,1}。 |
| {n} | n 是非负整数。正好匹配 n 次。例如,"o{2}"与"Bob"中的"o"不匹配,但与"food"中的两个"o"匹配。 |
| {n,} | n 是非负整数。至少匹配 n 次。例如,"o{2,}"不匹配"Bob"中的"o",而匹配"foooood"中的所有 o。"o{1,}"等效于"o+"。"o{0,}"等效于"o*"。 |
| {n,m} | m 和 n 是非负整数,其中 n <= m。匹配至少 n 次,至多 m 次。例如,"o{1,3}"匹配"fooooood"中的头三个 o。'o{0,1}' 等效于 'o?'。注意:您不能将空格插入逗号和数字之间。 |
| ? | 当此字符紧随任何其他限定符(、+、?、{n}、{n,}、{n,m*})之后时,匹配模式是"非贪心的"。"非贪心的"模式匹配搜索到的、尽可能短的字符串,而默认的"贪心的"模式匹配搜索到的、尽可能长的字符串。例如,在字符串"oooo"中,"o+?"只匹配单个"o",而"o+"匹配所有"o"。 |
| . (点) | 匹配除"\r\n"之外的任何单个字符。若要匹配包括"\r\n"在内的任意字符,请使用诸如"[\s\S]"之类的模式。 |
| \d | 数字字符匹配。等效于 [0-9]。 |
| \D | 非数字字符匹配。 |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等 |
| \S | 匹配任何非空白字符。 |
| \w | 匹配任何字类字符,包括下划线。与"[A-Za-z0-9_]"等效。 |
| \W | 与任何非单词字符匹配。 |
3.1.4 排序
-
hive的排序:普通表,分区表,分桶表的用法一致。
| order by | sort by | distribute by | cluster by | |
|---|---|---|---|---|
| 作用 | order by会对输入做全局排序 | sort by 是单独在各自的reduce中进行排序 | 控制map中的输出在 reduce中是如何进行划分的 | 相当于distribute by和 sort by 合用 |
| 缺点 | 只有一个Reduce,当输入规模较大时,消耗较长的计算时间 | 不能保证全局有序 | 只是分,没有排 | 只能做升序 |
-
order by (全局排序asc ,desc)
不管reduce有多少个,都是只输出一个结果/文件。 - sort by(在每个reduce内排序)
-
若只在每个reduce里排完序后查看结果,那结果页又会将所有reduce整合,结果又变无序,所以需要将排序后的结果 输出到文件(按reduce分类)里查看,可以验证是否是你想象的那样
- 如果reduce不是指定的分类输,那排序的结果也无意义;
- 如果reduce是1,那和order by结果一样,也没什么意义;
- 如果是reduce是-1,会根据此Hive表的大小随机输出个数,所以sort by必须和Distribute by联合使用
set mapred.reduce.tasks; --查看当前reduce个数(默认-1为无限制)
set mapred.reduce.tasks = 2; --设置reduce个数
--数据排序后,要输出到文件里查看,每个reduce就是一个文件
INSERT OVERWRITE DIRECTORY '/user/admin/sortby' ROW FORMAT DELIMITED FIELDS
TERMINATED by '\t'
select * from emp_patition sort by emp 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











