



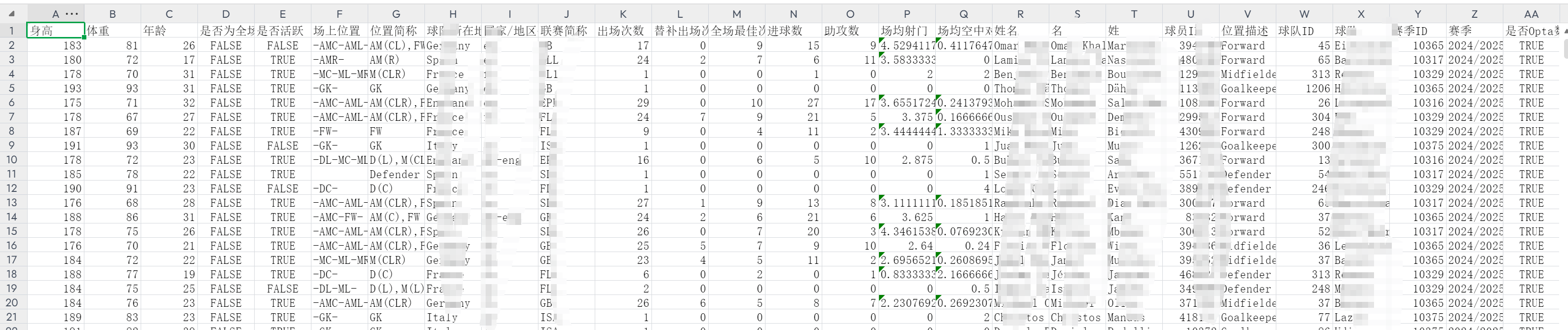
先看成功实现的效果!!
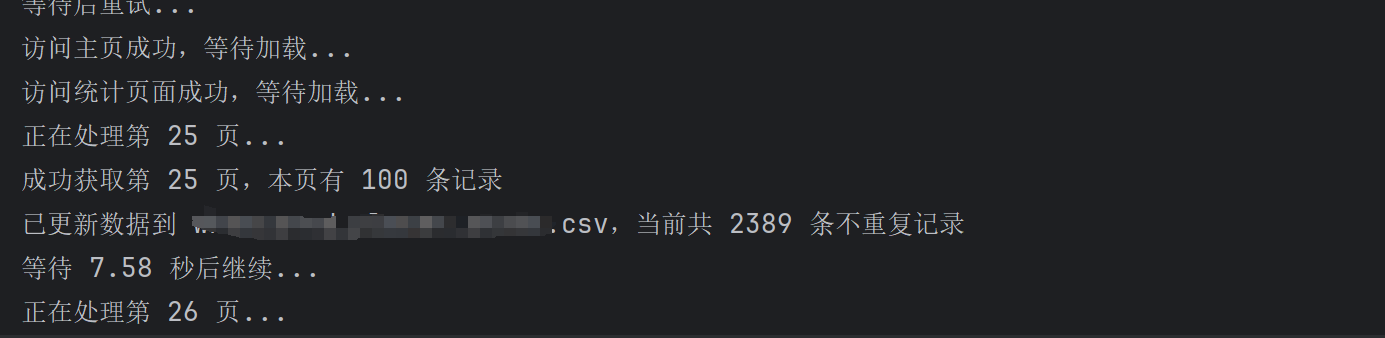
先大概说一下我在爬取这个网站时的经历,一开始我是打算直接通过接口爬取这个网站的数据,但是发现里面的接口和cookie都做了反爬机制。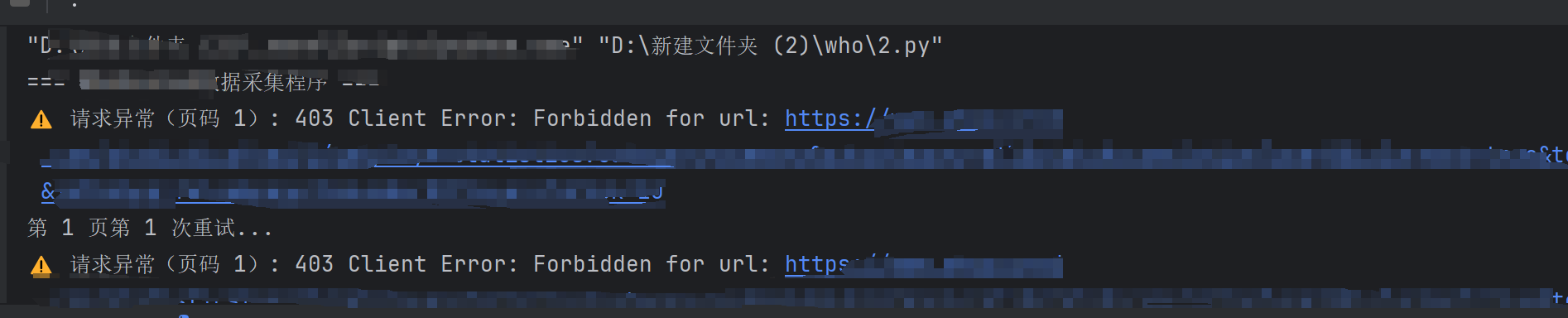
然后我配置了本地代理,想从多种方法绕过反爬机制,但是都没有用,最后是通过selenium模拟人为操作分页爬取,但是一开始有一个问题就是:始终爬的都是第一页的数据,后面通过校对每一页的数据进行验证,修改换页爬取的逻辑,但是又有一个问题,就是不知道是电脑问题还是驱动浏览器的问题,爬到20页的时候,报错提示浏览器崩溃了,然后最麻烦的一部分,就是定时关闭并重启浏览器,重启后再对当前关闭的断点进行继续爬取,通过这些慢慢优化才最终成功完成,代码结尾部分还有一些页面判断的逻辑没有完善,因为接口说的是200多页,但是实际只有二十多页,但是数据是完整的,应该是前端和后端的处理问题,所以后续完善的话会对当前页面没有数据的页面进行判断后关闭当前程序。
一、应用场景
本文介绍一种基于Selenium的通用型分页数据采集方案,适用于需要处理以下场景的数据采集任务:
- 基于Ajax动态加载的网页
- 需要登录或cookie验证的网站
- 分页结构复杂的接口调用
- 需要人机行为模拟的采集场景
二、核心功能
本爬虫框架实现以下关键功能:
- 智能分页控制:自动处理分页逻辑
- 断点续爬:异常中断后可从断点恢复
- 反检测机制:模拟人类操作特征
- 数据持久化:实时保存采集结果
- 异常重试:网络波动自动恢复
三、技术栈
- Selenium 4.0+
- ChromeDriver
- Pandas 数据存储
- WebDriver Manager 自动驱动管理
四、实现原理
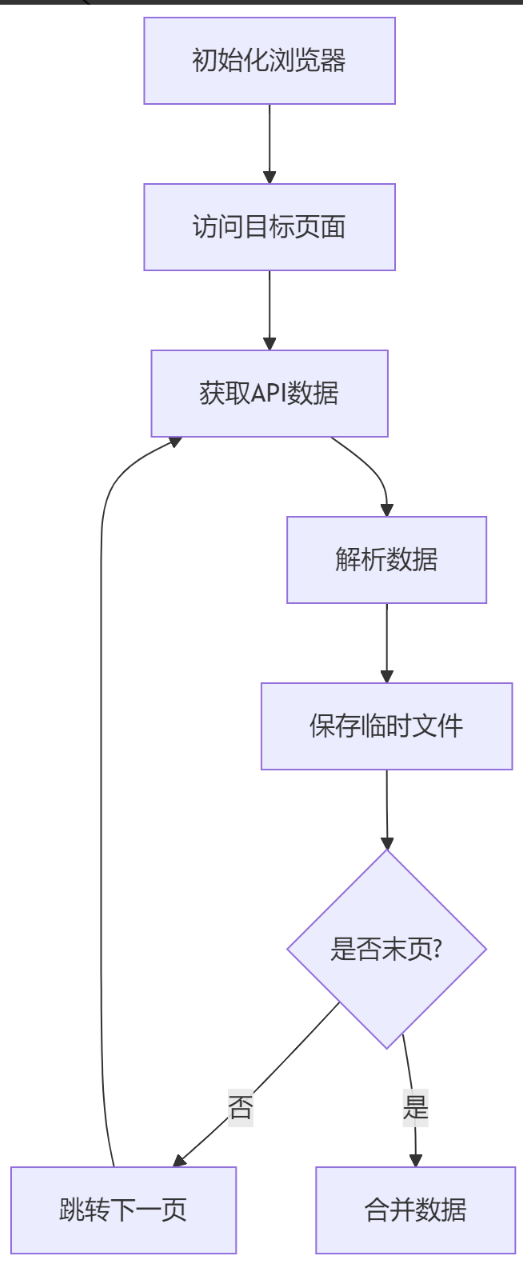
五、代码解析(核心部分)
1. 浏览器初始化配置
def init_driver():
options = Options()
options.add_argument("--disable-blink-features=AutomationControlled")
options.add_experimental_option("excludeSwitches", ["enable-automation"])
driver = webdriver.Chrome(
service=Service(ChromeDriverManager().install()),
options=options
)
# 隐藏自动化特征
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
"""
})
return driver
2. 分页采集逻辑
def pagination_crawl(start_page=1):
current_page = start_page
while current_page <= MAX_PAGES:
try:
data = get_page_data(current_page)
save_temp_data(data, current_page)
current_page += 1
random_sleep()
except Exception as e:
handle_error(e, current_page)
3. 智能等待机制
def random_sleep(base=3, variance=5):
"""随机等待函数"""
sleep_time = base + random.random() * variance
time.sleep(sleep_time)
# 每10页增加等待
if current_page % 10 == 0:
time.sleep(max(15, sleep_time*2))
六、完整代码(网站数据不方便透露,已隐藏,仅供参考学习)
import pandas as pd
import time
import random
import json
import os
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from webdriver_manager.chrome import ChromeDriverManager
def get_player_stats_with_selenium(page=1, max_pages=100, max_retries=3, output_file="player_stats.csv"):
"""通用分页数据采集函数"""
all_players = []
current_page = page
retry_count = 0
driver = None
# 检查已有数据文件
if os.path.exists(output_file):
try:
existing_df = pd.read_csv(output_file, encoding='utf-8-sig')
all_players = existing_df.to_dict('records')
print(f"已读取现有数据: {len(existing_df)} 条")
except Exception as e:
print(f"读取文件出错: {str(e)}")
while current_page <= max_pages:
try:
if driver is None:
# 浏览器配置
chrome_options = Options()
chrome_options.add_argument("--disable-gpu")
chrome_options.add_argument("--no-sandbox")
chrome_options.add_argument("--window-size=1920,1080")
chrome_options.add_experimental_option("excludeSwitches", ["enable-automation"])
# 初始化驱动
driver = webdriver.Chrome(
service=Service(ChromeDriverManager().install()),
options=chrome_options
)
# 隐藏自动化特征
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
"""
})
# 示例页面访问(需替换实际地址)
driver.get("https://example.com")
time.sleep(random.uniform(2, 4))
print(f"正在处理第 {current_page} 页...")
# 示例API请求(需替换实际地址)
api_url = f"https://api.example.com/data?page={current_page}"
# 获取数据
driver.get("https://example.com/api_entry")
time.sleep(1)
# 执行数据请求脚本
script = f"""
return new Promise((resolve, reject) => {{
const xhr = new XMLHttpRequest();
xhr.open('GET', '{api_url}', true);
xhr.onload = function() {{
if (xhr.status === 200) {{
resolve(xhr.responseText);
}} else {{
reject(new Error('请求失败'));
}}
}};
xhr.send(null);
}});
"""
response_text = driver.execute_script(script)
data = json.loads(response_text)
players = data.get('items', [])
if not players:
print(f"第 {current_page} 页无数据")
if retry_count < max_retries:
retry_count += 1
continue
else:
break
# 处理数据
retry_count = 0
all_players.extend(players)
print(f"已获取 {len(players)} 条数据")
# 实时保存
all_df = pd.DataFrame(all_players)
all_df = all_df.drop_duplicates(subset=['id'])
all_df = translate_fields(all_df)
all_df.to_csv(output_file, index=False, encoding='utf-8-sig')
# 临时备份
pd.DataFrame(players).to_csv(f"temp_page_{current_page}.csv", index=False)
current_page += 1
time.sleep(random.uniform(3, 6))
# 定期维护
if current_page % 10 == 0:
time.sleep(random.uniform(10, 15))
if current_page % 20 == 0:
driver.quit()
driver = None
except Exception as e:
print(f"页面处理异常: {str(e)}")
if driver:
driver.quit()
driver = None
time.sleep(random.uniform(10, 20))
if driver:
driver.quit()
return all_players
def translate_fields(df):
"""字段翻译示例"""
translation = {
'id': '唯一标识',
'name': '姓名',
'team': '所属团队',
'score': '评分',
'matches': '出场次数',
'goals': '进球数'
}
return df.rename(columns=translation)
def merge_temp_files(output_file="combined_data.csv"):
"""合并临时文件"""
temp_files = [f for f in os.listdir() if f.startswith("temp_page_")]
if not temp_files:
return False
dfs = []
for file in sorted(temp_files, key=lambda x: int(x.split('_')[-1].split('.')[0])):
try:
dfs.append(pd.read_csv(file, encoding='utf-8-sig'))
except Exception as e:
print(f"文件读取失败: {file}")
combined_df = pd.concat(dfs).drop_duplicates('id')
combined_df.to_csv(output_file, index=False)
return True
def main():
"""主控制流程"""
output = "final_data.csv"
if any(f.startswith("temp_page_") for f in os.listdir()):
choice = input("检测到临时文件,请选择操作 (1合并/2继续/3重置): ")
# 处理用户选择逻辑...
else:
get_player_stats_with_selenium(output_file=output)
if __name__ == "__main__":
main()
七、注意事项
- 遵守目标网站的robots.txt协议
- 控制请求频率(建议≥3秒/请求)
- 避免对目标网站造成负载压力
- 仅用于技术研究,禁止商业用途

















 839
839

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









