







文章目录
并行与分布式 第4章 数据级并行:向量体系结构和GPU
4.1 什么叫数据级并行
我们将这些算法称为数据并行算法,是因为他们的并行源于对大型数据集的同时操作,而不是来自多个控制线程。
4.1.1 数据级并行与SPMD
一个SPMD程序如何运行在SISD(或MIMD)上?

4.1.2数据级并行——传统器件的问题
• 分析传统的标量CPU流水线可知,取址、译码等操作逻辑复杂,且开销不低
• 对于SPMD任务,无论是在SISD还是MIMD(多核)器件上运行,其取址、译码操作都是有冗余的
数据级并行——SIMD
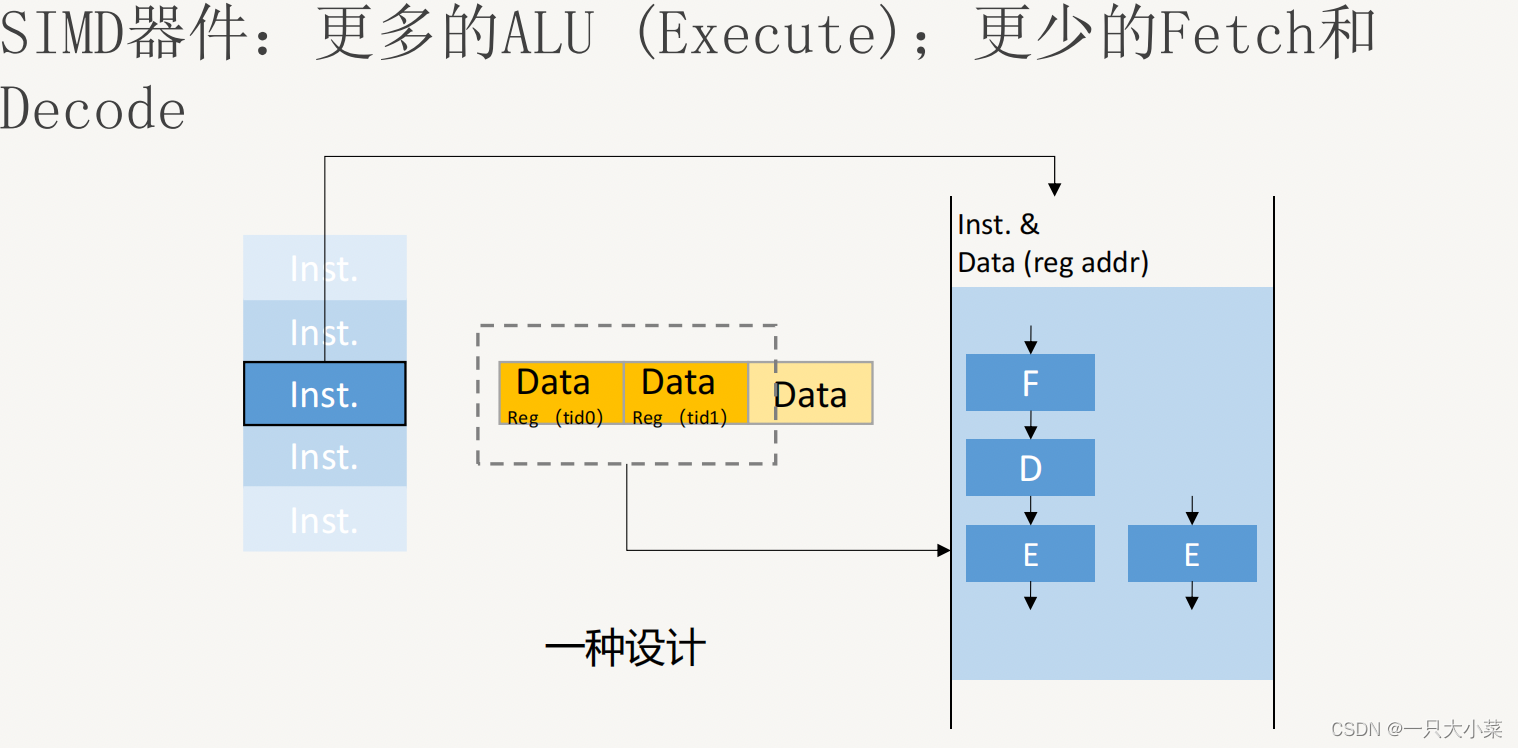
• 更少的Fetch和Decode(甚至其他流水部件)意味着什么?
—— 更少的器件,更低的能耗和时间开销
• 更多的ALU意味着什么?
——一次流水能处理更多数据,速度更快
• 增加数据寄存器的数量来一次存储更多数据,以减少存储器访问延迟
4.1.3 数据级并行——向量体系结构和GPU
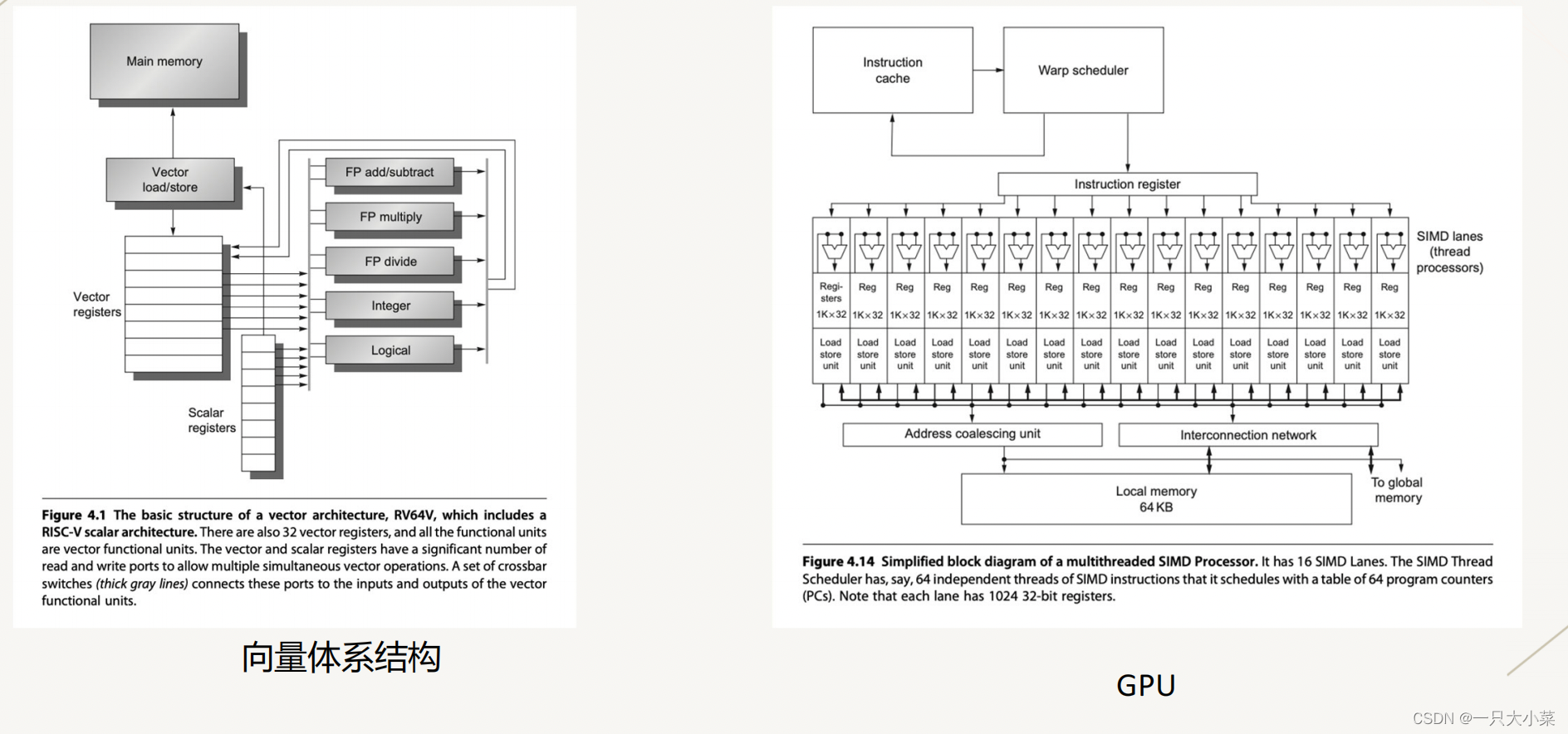
| 特点 | 向量体系结构 | GPU |
|---|---|---|
| 指令流水线深度 | 深 | 浅 |
| ALU宽度 | 窄 | 宽 |
| 控制流水线时间 | 能够掩盖不必要的流水线时间 | 流水线相对简单,直接处理更多数据 |
| 适用领域 | 特定领域的高性能计算 | 图形渲染、深度学习等并行计算任务 |
4.2 向量体系结构
4.2.1 向量以及计算方式
向量这种数据结构,以及向量的运算,和我们对SIMD的期待不谋而合
横向计算(以计算D=A×(B+C)为例)
向量计算是按行的方式从左到右横向地进行
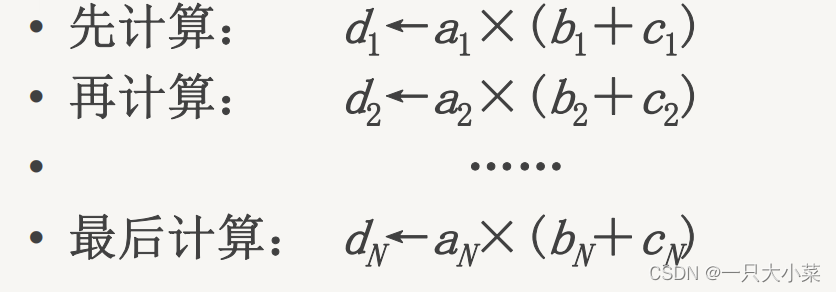
数据相关:N次 功能切换:2N次 不适合于向量处理机的并行处理。
纵向计算
向量计算是按列的方式从上到下纵向地进行

两条向量指令之间:数据相关:1次 功能切换:1次
. 纵横(分组)计算
刚刚的纵向计算方式优化了向量计算的硬件开销,但是每次计算都需要访问到向量中的全部元素考虑到当前计算机体系结构的存储结构往往是层次化的,指令操作数一般都会加载到寄存器中,而寄存器的数量一般不会太多(相比于可以无限增长的向量长度N来说)结合前面两种计算方式,我们可以使用分组计算的方法

每组内各用两条向量指令。 数据相关:1次 功能切换:2次
4.2.2 向量体系结构
- 向量体系结构应当具有很大的(相比传统标量体系结构)顺序寄存器堆 (Register File)(加载更多向量元素以支持纵向计算)
- 向量体系结构从内存中收集散落的数据,将其放入寄存器堆中,并对寄存器堆中的数据们进行操作,然后将这些结果放回内存(一次传输一组数据,LD/ST流水化)
- 一条指令能够对一个向量的数据进行操作,也就对向量中诸多独立数据元素进行了操作(纵向计算,功能单元流水化)
刚刚讨论的是向量计算在串行化中尽可能进行优化的结果
从并行的角度去考虑,增加功能单元(ALU)的数量也能大大提升向量的计算速度(多车道)
向量体系结构的一些优势
- 由于向量的Load与Store是深度流水线化的,大型寄存器堆充当了Buffer的作用,因此其能够掩盖访存延迟并充分利用内存带宽
- 乱序的超标量处理器往往具有复杂的设计,且乱序程度越高,其复杂性和功耗也会越高,在此方向发展很容易触及PowerWall将顺序的标量处理器扩展为向量处理器则不会带来复杂度和功耗的大幅升高,且开发者也能很容易适应和转换到向量指令
实例RISC-V & VECTOR EXTENSION
• RISC-V是一个免费且开源的基于精简指令集(RISC)的指令集架(ISA)
• RISC-V Vector Extension (RVV)顾名思义是RISC-V的向量扩展,本节全部内容基于 riscv-v-spec-1.0 规范
• RV64G:寄存器宽度为64的RISC-V(标量)架构,包括了RV64I(整型ISA)和F、D扩展(单、双精度浮点ISA)
• RV64V:一种兼容RV64G并包含64bit宽度RVV的(向量)架构
注意:无论寄存器宽度XLEN(传统意义上的字长)是32,64或是128位,在RISC-V中的一个字(word)永远是32位宽。这一点在之后的汇编指令中有体现
RV64结构概览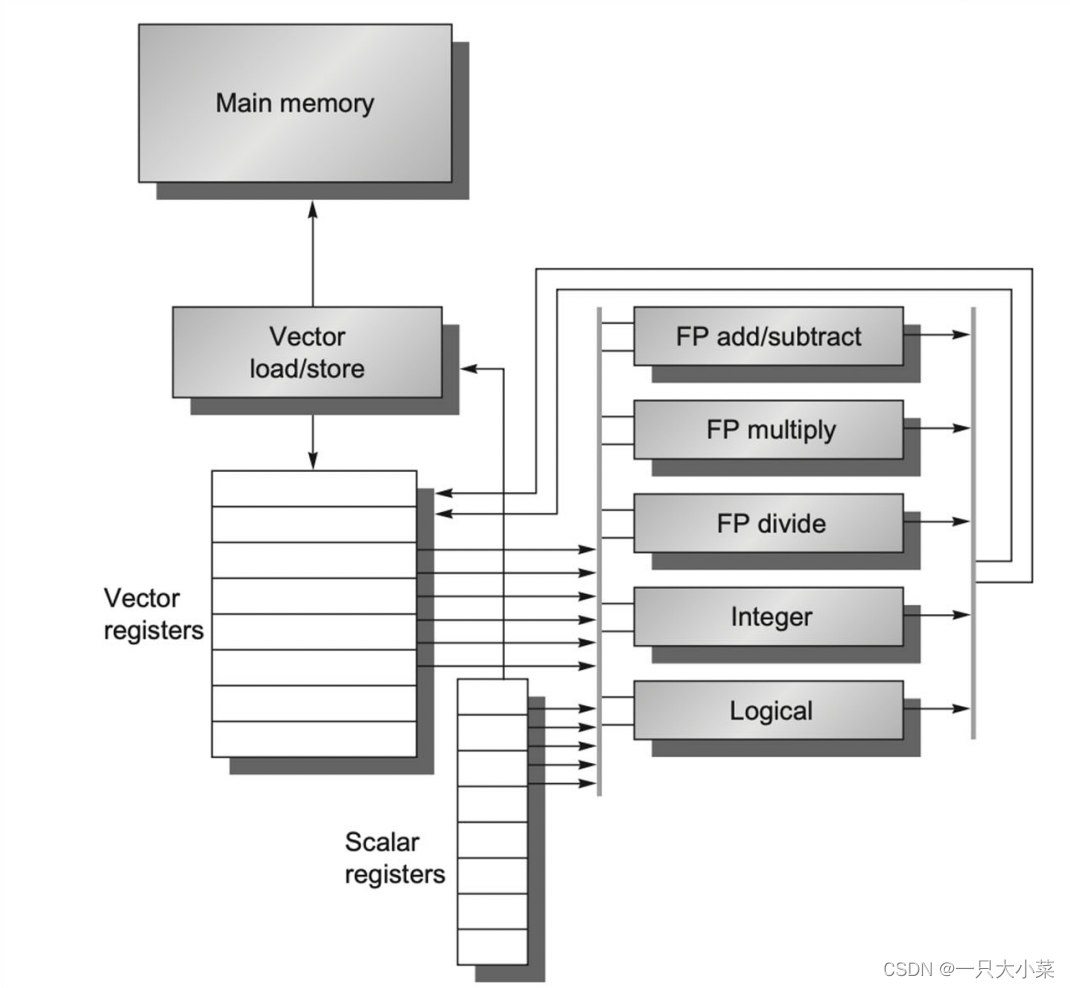
RV64V 向量寄存器
- RVV规定了32个向量寄存器(任何实现都应固定为32个),编号为 v0-v31
- 不同实现可以有不同的寄存器宽度,但RVV规定每个寄存器宽度VLEN小于2^16bit,这里取VLEN=64bit
- 寄存器组拥有充足的读写端口
RV64V标量寄存器
- 和标量RISC-V一样的32个通用整型寄存器(x0-x31)和32个浮点寄存器(f0-f31),寄存器宽度XLEN为64
- 标量寄存器可以为向量功能单元提供数据,也可以为向量load/store单元提供地址
- 当向量功能单元从标量寄存器读取标量值时,其输入会将该标量值锁存
RV64V 向量LOAD/STORE单元
- 假设一次访存时间为6 cycle
- 假设向量load/store完全流水化,即在初始延迟后,向量寄存器和内存的带宽为每时钟周期1字(XLEN)
- 该单元也可以对标量进行load/store
RV64V 功能单元
- 假设功能单元完全流水化,每个时钟周期可以开始一个新操作
- 需要一个控制单元检测结构冒险和数据冒险
从功能单元入手,提升向量处理器性能的方法
- 增加功能单元数量(多车道并行)
- 采用链接技术
下面我们着重探讨链接技术
RV64V 功能单元 链接技术
- 链接(chaining):将具有写后读的两条操作中,前一个功能单元的结果转发给第二个功能单元,这就使得第二个向量操作可以在其源操作数(来自第一个操作的结果向量)中任意元素变为可用时立即开始
- 像这样把功能单元链接起来流水处理,本质上是把流水线定向的思想引入到向量执行过程
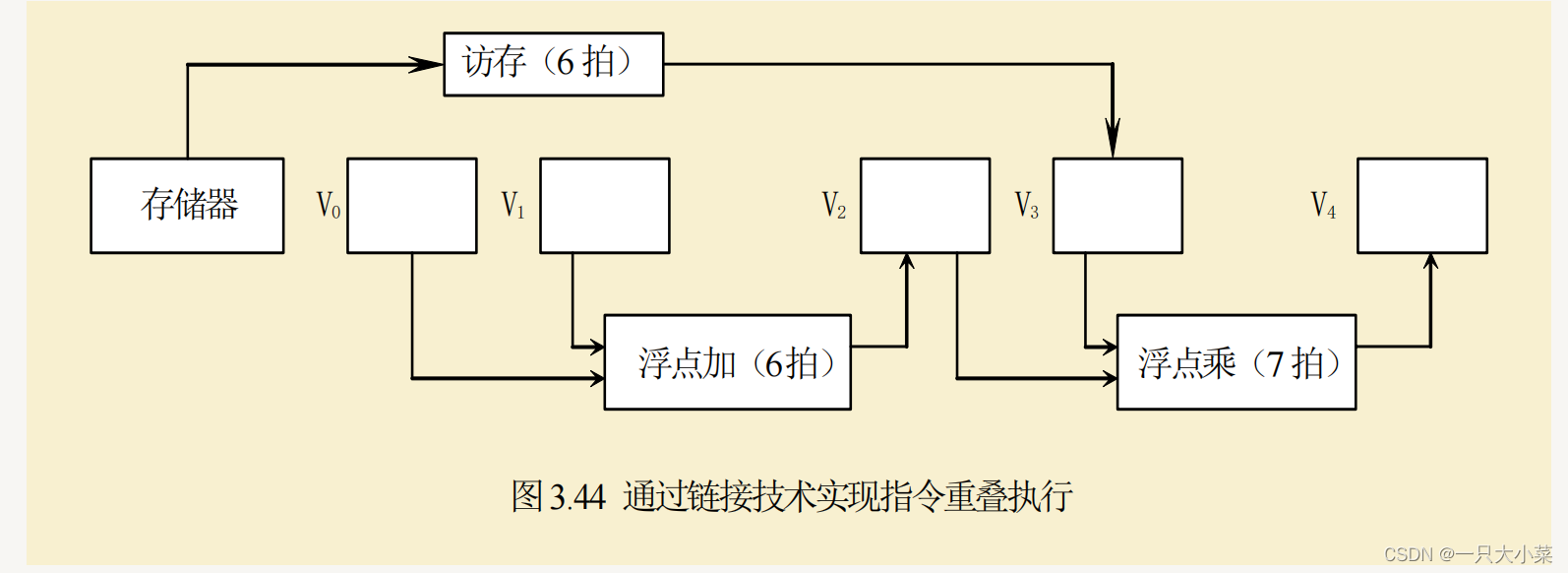
进行向量链接的要求
• 保证:无向量寄存器使用冲突和无功能部件使用冲突
• 只有在前一条指令的第一个结果元素送入结果向量寄存器的那一个时钟周期才可以进行链接。
• 当一条向量指令的两个源操作数分别是两条先行指令的结果寄存器时,要求先行的两条指令产生运算结果的时间必须相等,即要求有关功能部件的通过时间相等。
• 要进行链接执行的向量指令的向量长度必须相等,否则无法进行链接。
• 一般链接技术经常出现在向量分组的内部
4.2.3 向量运算的执行时间评估
在前面讲解链接技术时,我们使用了一种细致的时间计算方式,得到的时间往往是 k * 𝑁+𝑏 的形式,其中k、b为常量
一般来讲,在向量处理器上,向量长度N都要远远大于常数b,因此我们应当着重关注式子的前一项 𝑘 * N
对于单车道的RV64V,我们认为执行一个编队的时间就是向量的长度N(单位为时钟周期)(双车道为N/2,以此类推,这里以单车道为例)
如果一串向量指令,含有m个编队,且处理的向量长度为N,则其在单车道处理器上执行的时间约为 m*N clock cycles

4.3 GPU结构
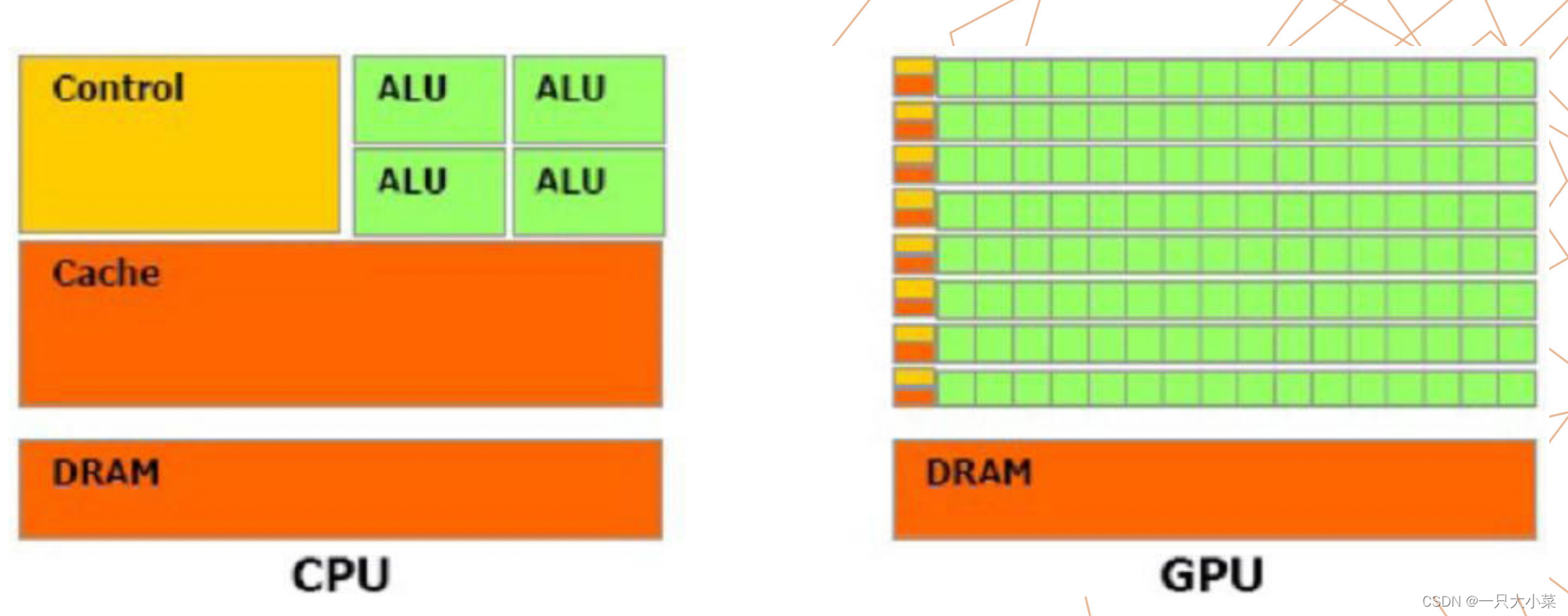
名词解释
| 缩写 | 全称 | 解释 |
|---|---|---|
| ALU | Arithmetic Logic Unit | 在计算中,算术逻辑单元(ALU)是一种组合数字电路,对整数二进制数执行算术和位运算。 |
| DRAM | Dynamic Random Access Memory | 动态随机存取存储器利用电容内存储电荷的多寡来代表一个二进制比特(bit)是1还是0的存储器件。 |
| GPGPU | General-purpose computing on graphics processing units | 通用图形处理器代表“图形处理单元上的通用计算”,利用GPU的能力来执行传统上由中央处理器(CPU)完成的任务。 |
| SM | Streaming Multi-Processor | 流处理簇是运行CUDA内核的GPU的一部分,每个SM包含共享内存、恒定缓存、纹理缓存和一级缓存等组件。 |
| FPU | Floating Point Unit | 浮点单元(FPU,俗称数学协处理器)是计算机系统的一部分,专门用于对浮点数进行运算。 |
| SFU | Special Function Unit | 特殊功能单元用于执行超越指令,如正弦、余弦、倒数和平方根。每个SFU每个线程、每个时钟执行一条指令。 |
| GPC | Graphics Processing Cluster | 图形处理集群是由若干流式多处理器组成的一个流式多处理器簇。 |
| ROP | Raster Operation Processor | 光栅运算处理器获取像素和纹理信息,并通过特定的矩阵和向量操作将其处理为最终像素或深度值,同时执行写入或读取值以及混合操作。 |
| PE | Processing Element | 处理元件是GPU中的子任务处理模块,可以表现为计算子任务或访存子任务。 |
| GTE | GigaThread Engine | 千兆线程引擎接受对GPU的调用,并根据内核创建任务实例。 |
| DTE | Data Transfer Engine | 数据传输引擎使用datamove PBS,在主机内存和设备内存之间传输数据。 |
| PBS | Push Buffer Streams | PBS是数据传输引擎使用的一种数据传输机制。 |
| KIS | Kernel Instruction Stream | KIS是内核指令流,用于描述GPU执行的内核指令序列。 |
| SP | Streaming Processor | 流处理器用于处理由CPU传输过来的数据,并将其转化为显示器可以识别的数字信号。 |
| PCIe | Peripheral Component Interconnect Express | PCIe是一种高速串行计算机扩展总线标准。 |
| SMEM | Shared Memory | 共享内存是多个程序可以同时访问的内存,用于在程序之间提供通信或避免冗余副本。 |
| SIMD | Single Instruction Multiple Data | 单指令多数据流能够复制多个操作数,并将它们打包在大型寄存器的一组指令集。 |
| SIMT | Single Instruction Multiple Threads | 单指令多线程是一种并行计算的执行模型,将单指令多数据与多线程相结合。 |
| LSU | Load-Store Unit | 加载存储单元是一个专门的执行单元,负责执行所有加载和存储指令,生成加载和存储操作的虚拟地址,并从内存加载数据或存储数据到内存。 |
| SI | Single Instruction | 单指令 |
| MT | Multi-Threaded | 多线程 |
| NVCC | NVIDIA CUDA Compiler | NVIDIA CUDA编译器驱动程序,用于隐藏CUDA编译的复杂细节。 |
| VDI | Virtual Desktop Infrastructure | 虚拟桌面基础设施是使用虚拟机提供和管理虚拟桌面的技术。 |
流水线(Pipeline) v.s. 并发(Concurrent)
- CPU擅长执行少量串行线程:
·快速顺序执行
· 低延迟的缓存内存访问 - GPU擅长执行许多并行线程:
·可扩展的并行执行
·高带宽的并行内存访问
SIMD VS SIMT
SIMD(Single Instruction Multiple Data)和SIMT(Single Instruction Multiple Threads)都是并行计算的执行模型,但在具体实现上有一些区别。
SIMD是一种并行计算模型,它能够同时对多个数据元素执行相同的指令。在SIMD中,一条指令被广播到一组数据元素上,然后这组数据元素同时执行相同的操作。SIMD通常用于向量处理器或SIMD指令集扩展,如Intel的SSE(Streaming SIMD Extensions)和ARM的NEON(Advanced SIMD)。
SIMT是一种在GPU上广泛使用的并行计算模型。在SIMT中,多个线程同时执行相同的指令,但每个线程可以处理不同的数据。这些线程被分组成线程块(thread block),并在GPU上的多个处理器上并行执行。SIMT执行模型允许不同线程在同一指令周期内执行不同的指令,但它们在执行过程中保持同步。这意味着在SIMT中,所有线程中的所有指令都是在锁步中执行的。
总结来说,SIMD是一种向量化的并行计算模型,通过在多个数据元素上执行相同的指令来提高计算性能。而SIMT是一种在GPU上广泛使用的并行计算模型,通过同时执行多个线程来实现并行计算,但每个线程可以处理不同的数据。
(GPU剩下的看PPT吧,全是图看不懂)


















 1094
1094

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









